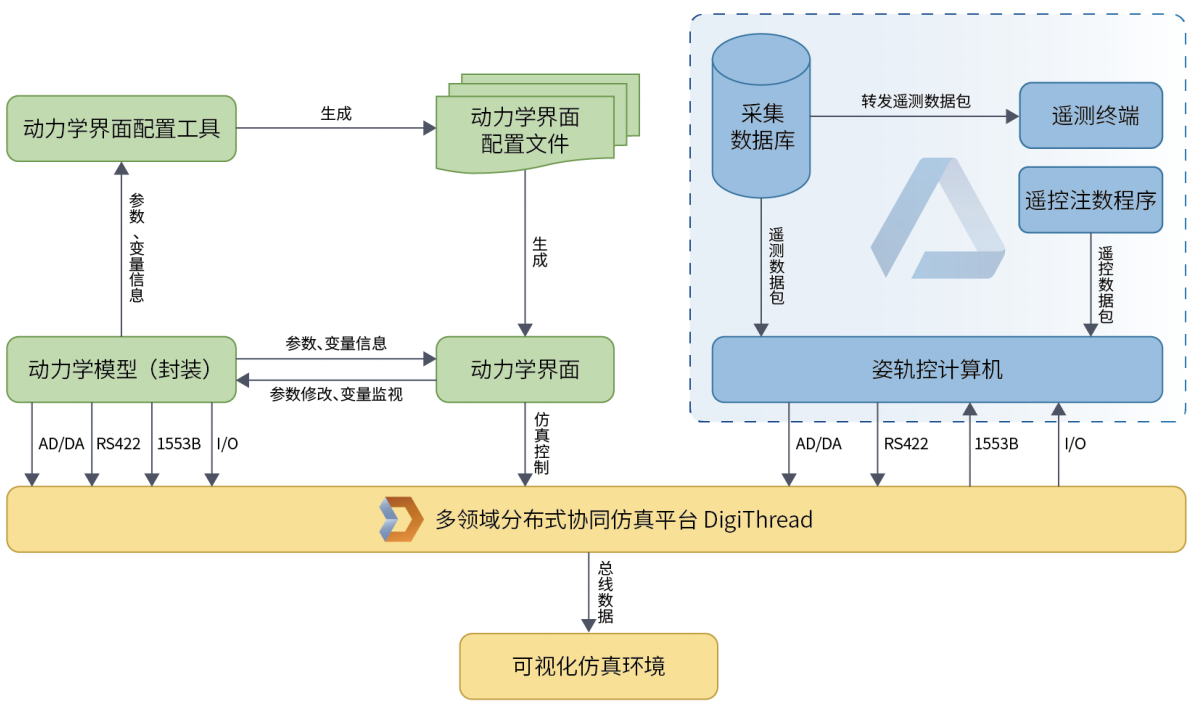
目录
一、AUC性能测试
1、什么是AUC
2、什么是AUC-ROC曲线
1)TPR、FPR
• TPR:真实值为1,预测值为1的概率
• FPR:真实值为0,预测值为1的概率
2)如何绘制图示曲线
3、最理想的AUC-ROC曲线图
4、案例实现
运行结果展示:
二、回归树
1、什么是回归树
2、特点
3、案例
1)计算最优切分点
2)计算损失值
• 以切分点为1.5计算损失值
• 以其余点为切分点分别计算损失值:
3)二维数据的决策树划分
4、库、参数解析
1.criterion
2.splitter
3.max_depth
4. min_samples_split
5. min_samples_leaf
6. max_leaf_nodes
7、一些方法:
5、代码实现
一、AUC性能测试
1、什么是AUC
AUC(Area Under Curve)是一种常用的性能指标,用于评估分类模型的性能。在机器学习中,AUC通常是用来评估二分类模型(如逻辑回归、支持向量机等)的预测质量。
在机器学习中,性能测量是一项基本任务,因此,当涉及到分类问题时,问哦们可以依靠AUC-ROC曲线,当我们需要检查可视化多类分类问题的性能时,我们使用AUC(曲线下的面积)ROC(接收接收器工作特性)曲线,他是检查任何分类模型性能的最重要评估指标之一。
2、什么是AUC-ROC曲线
ROC曲线是一个将真阳性率(True Positive Rate,TPR)(也称为灵敏度)对假阳性率(False Positive Rate,FPR)(也称为1-特异度)进行绘制的曲线。真阳性率是指在正样本中被正确预测为正样本的比例,假阳性率是指在负样本中被错误预测为正样本的比例。
AUC代表了ROC曲线下的面积,其取值范围在[0,1]之间。AUC越大,代表模型性能越好。当AUC等于1时,表示模型完美预测正负样本,而当AUC等于0.5时,代表模型的预测能力与随机猜测无异。
AUC-ROC曲线图如下所示(AUC是曲线所围面积,ROC为这个曲线):

1)TPR、FPR
如上图可知AUC-ROC曲线的横纵坐标对应的值为FPR和TPR,那么这两个值是什么呢,看下图:
• TPR:真实值为1,预测值为1的概率

相当于如下混淆矩阵对应召回率:

• FPR:真实值为0,预测值为1的概率

相当于如下概率,即真实值为0,预测错了的概率

2)如何绘制图示曲线
有了上述 tpr 和 fpr 的计算方法,我们就可以找到对应的点,那么如果去更改这个模型的阈值,是不是又会有一新的 tpr 和 fpr 值,所以这个曲线就是通过tpr、fpr以及阈值去共同构建的。
3、最理想的AUC-ROC曲线图
如下图所示,即不管 fpr真实值为0,预测错了的概率为多少,tpr 真实值为1,预测对了的概率全是1,此时AUC对应的面积为1

4、案例实现
同样是上节课所说的电信客户流失那份数据,对上节课代码进行优化后的状态
import pandas as pd
datas = pd.read_excel("电信客户流失数据.xlsx") # 导入数据
data = datas.iloc[:,:-1] # 取出特征数据以及标签数据
target = datas.iloc[:,-1]
# 数据切分测试集训练集
from sklearn.model_selection import train_test_split
data_train,data_test,target_train,target_test = train_test_split(data,target,test_size=0.2,random_state=42)
# 定义决策树
from sklearn import tree
# 建立决策树模型,并对其进行训练
dtr = tree.DecisionTreeClassifier(criterion='gini' , max_depth=8 , random_state=42) # 设置计算方式为gini系数计算,最大层数为8层,随机种子设置为42
dtr.fit(data_train,target_train) # 对训练集数据进行训练
# 预测数据
train_predicted = dtr.predict(data_train)
# 对测试集 打印分类报告
from sklearn import metrics
print(metrics.classification_report(target_train,train_predicted))
# 对原始数据测试,并打印报告
predict = dtr.predict(data)
print(metrics.classification_report(target, predict))
# 对随机切分的数据打印报告
predict1 = dtr.predict(data_test)
print(metrics.classification_report(target_test,predict1))
# AUC值计算
y_pred_proba = dtr.predict_proba(data_test) # 打印各类别概率
a = y_pred_proba[:,1] # 取出类别为1的一列
auc_result = metrics.roc_auc_score(target_test,a) # 输入参数测试集标签、测试集概率,计算AUC值
# 绘制AUC-ROC曲线
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve
# 计算不同预阈值情况下的fpr tpr thresholds为阈值
fpr,tpr,thresholds = roc_curve(target_test,a) # 输入参数测试集标签和概率,计算fpr、tpr、阈值
plt.figure() # 创建一个画布
plt.plot(fpr,tpr,color='darkorange',lw=2,label=f'ROC curve{auc_result:0.2f}') # x轴为fpr,y轴为tpr,图像颜色为深橘色,线宽度为2,提示标签为后面对应的字符串
plt.plot([0,1],[0,1]) # x轴y轴范围
plt.xlim([0.0,1.0]) # 刻度
plt.ylim([0.0,1.05])
plt.xlabel("False Positive Rate") # 提示信息
plt.ylabel('True Positive Rate')
plt.title("Receiver Operating Characteristic") # 标题信息
plt.legend()
plt.show()运行结果展示:


此时预测的结果正确率为0.7,比上节课的高,但是还不够,还需要对其进行优化,看接下来的讲解。
二、回归树
1、什么是回归树
用于解决回归问题的决策树模型。它是一种基于树结构的非参数模型,能够将输入特征空间划分为多个不同的区域,并为每个区域分配一个对应的输出值。
回归树的建模过程从根节点开始,选择一个最佳的特征和切分点,将数据划分为两个子集。然后,递归地对每个子集进行相同的划分操作,直到达到预设的停止条件。在每个叶节点上,使用该节点中的数据样本的平均值作为预测值。
2、特点
-
非参数性:回归树是一种非参数模型,它不对数据的分布做出特定的假设。这使得回归树能够更灵活地适应不同类型的数据。
-
可解释性:回归树生成的模型易于理解和解释。通过观察树的结构和叶节点的取值,可以直观地理解模型在不同特征值上的划分和预测。
-
鲁棒性:回归树对异常值和缺失值具有较好的鲁棒性。由于回归树是基于样本的平均值进行预测,个别异常值对模型的影响较小。
-
非线性建模能力:回归树可以自适应地捕捉数据中的复杂非线性关系。通过多层划分,回归树可以对特征空间进行细致的划分,从而较好地拟合非线性模式。
-
高效性:在预测阶段,回归树的计算成本相对较低。它只需要根据输入特征的取值进行简单的比较操作,即可得到预测结果。
-
必须是二叉树
3、案例
有如下数据:

1)计算最优切分点

2)计算损失值
公式:

有了上述切分点,此时变要对其计算损失值,这里的c为平均值,c1为计算前一部分平均值,c2为计算后一部分损失值,y为标签的值
• 以切分点为1.5计算损失值
当s=1.5时,将数据分为两个部分:
第一部分:(1,5.56)
第二部分:(2,5.7)、(3,5.91)、(4,6.4)…(10,9.05)
所以可以得出切分点为 1.5 损失值 Loss
C1=5.56
C2=1/9(5.7+5.91+6.4+6.8+7.05+8.9+8.7+9+9.05)=7.5
• 以其余点为切分点分别计算损失值:
可以得到如下数据:

可以看出,s=6.5 时,loss的值最小,所以第一个划分点 s = 6.5,画出如下结果:

由此依次对另外部分数据单独再继续求损失值,可得到如下结果,然后在对比求得下面的划分点,

因为输的深度限制为2层,(根节点不算第一层)所以得到以下图形:

最后一层叶子节点的值为每一部分的平均值
3)二维数据的决策树划分
例如有如下数据:


可以发现此时1.2最小,所以取 x1=1 为第一个切分点,和上述一致,小于1为一个分支,大于1为一个分支,此时得到下列图形,然后再对各项再重复上述步骤即可得到下一层数据

4、库、参数解析
class sklearn.tree.DecisionTreeRegressor(criterion=’mse’, splitter=’best’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, presort=False)[source]1.criterion
节点分裂依据。默认:mse,可选择·mae(平均绝对误差)->使用绝对值
2.splitter
默认best表示以最优的方式切分节点
3.max_depth
树的最大深度。过深的树可能导致过拟合,通过交叉验证来进行选择
4. min_samples_split
默认值是2. 分裂一个内部节点需要的最小样本数,含义与分类相同
5. min_samples_leaf
默认值是1,叶子节点最少样本数,含义与分类相同
6. max_leaf_nodes
设置最多的叶子节点个数,达到要求就停止分裂,控制过拟合,设置此参数之后max_depth失效
7、一些方法:
- apply : 返回预测每个样本的叶子的索引
- decision_path: 返回树中的决策路径
- get_depth: 获取树的深度
- get_n_leaves: 获取树的叶子节点数
- get_params: 获取此估计器的参数,即前面配置的全部参数信息
- score: 得到决策树的评判标准R2
5、代码实现
多元线性回归文件内容如下:

import pandas as pd
from sklearn import tree
# 使用pandas导入csv文件
data = pd.read_csv("多元线性回归.csv",encoding='gbk')
x = data.iloc[:,:-1] # 选择特征数据集和标签集
y = data.iloc[:,-1]
# 导入模型并对其进行训练
reg = tree.DecisionTreeRegressor()
reg = reg.fit(x,y)
# 对原始数据进行预测
y_pr = reg.predict(x)
print(y_pr)
# 这里的score求的是R方的值,二维的用R方,多元的用调整R方 ,求概率 ,回归是线性的,分类是离散的
score = reg.score(x,y)
print(score)输出结果为:

由于数据量特别少,所以测试出来百分之99的概率被四舍五入成了100%