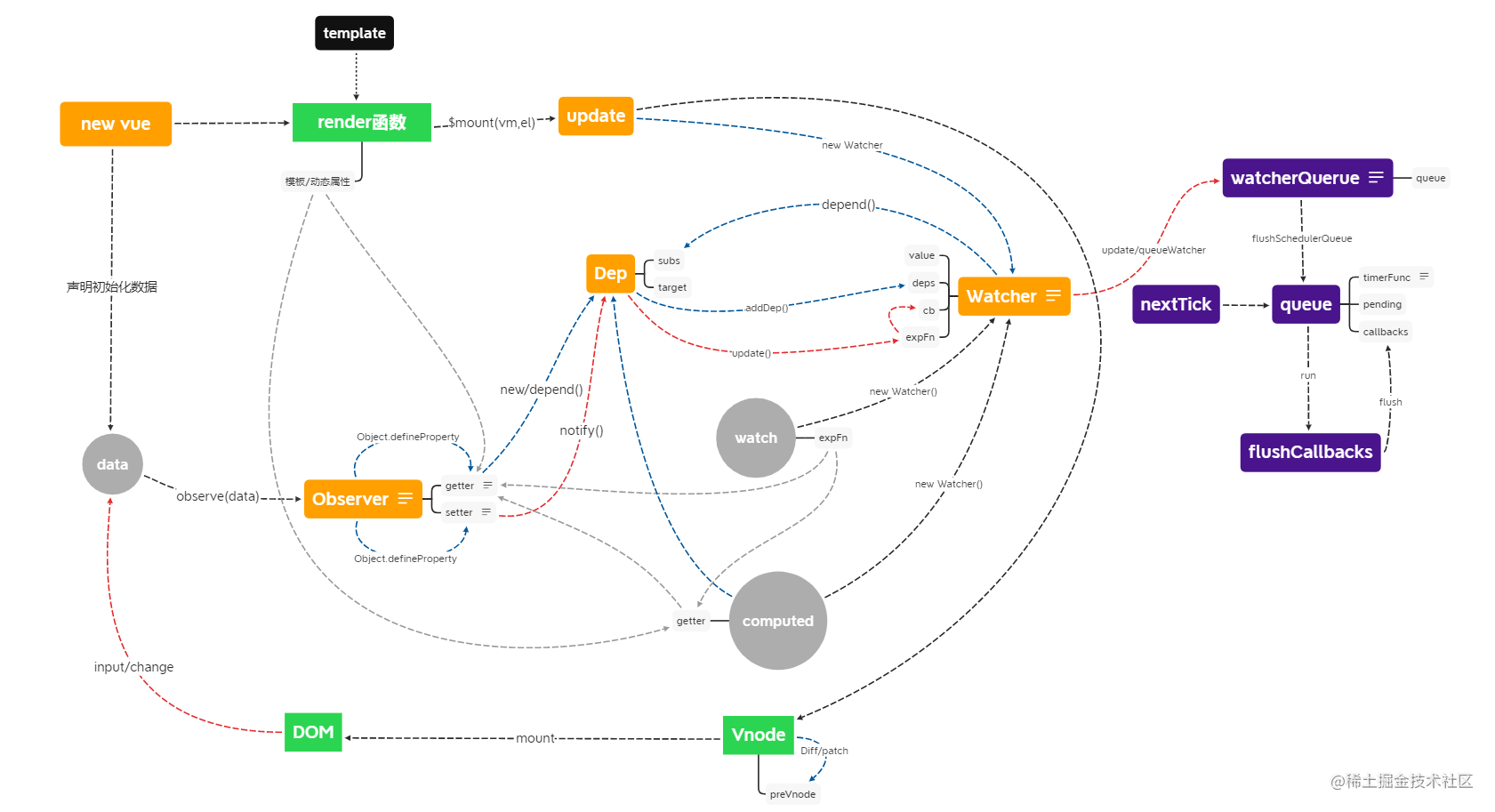
目录
一、用法精讲
391、pandas.Series.hist方法
391-1、语法
391-2、参数
391-3、功能
391-4、返回值
391-5、说明
391-6、用法
391-6-1、数据准备
391-6-2、代码示例
391-6-3、结果输出
392、pandas.Series.to_pickle方法
392-1、语法
392-2、参数
392-3、功能
392-4、返回值
392-5、说明
392-6、用法
392-6-1、数据准备
392-6-2、代码示例
392-6-3、结果输出
393、pandas.Series.to_csv方法
393-1、语法
393-2、参数
393-3、功能
393-4、返回值
393-5、说明
393-6、用法
393-6-1、数据准备
393-6-2、代码示例
393-6-3、结果输出
394、pandas.Series.to_dict方法
394-1、语法
394-2、参数
394-3、功能
394-4、返回值
394-5、说明
394-6、用法
394-6-1、数据准备
394-6-2、代码示例
394-6-3、结果输出
395、pandas.Series.to_excel方法
395-1、语法
395-2、参数
395-3、功能
395-4、返回值
395-5、说明
395-6、用法
395-6-1、数据准备
395-6-2、代码示例
395-6-3、结果输出
二、推荐阅读
1、Python筑基之旅
2、Python函数之旅
3、Python算法之旅
4、Python魔法之旅
5、博客个人主页



一、用法精讲
391、pandas.Series.hist方法
391-1、语法
# 391、pandas.Series.hist方法
pandas.Series.hist(by=None, ax=None, grid=True, xlabelsize=None, xrot=None, ylabelsize=None, yrot=None, figsize=None, bins=10, backend=None, legend=False, **kwargs)
Draw histogram of the input series using matplotlib.
Parameters:
by
object, optional
If passed, then used to form histograms for separate groups.
ax
matplotlib axis object
If not passed, uses gca().
grid
bool, default True
Whether to show axis grid lines.
xlabelsize
int, default None
If specified changes the x-axis label size.
xrot
float, default None
Rotation of x axis labels.
ylabelsize
int, default None
If specified changes the y-axis label size.
yrot
float, default None
Rotation of y axis labels.
figsize
tuple, default None
Figure size in inches by default.
bins
int or sequence, default 10
Number of histogram bins to be used. If an integer is given, bins + 1 bin edges are calculated and returned. If bins is a sequence, gives bin edges, including left edge of first bin and right edge of last bin. In this case, bins is returned unmodified.
backend
str, default None
Backend to use instead of the backend specified in the option plotting.backend. For instance, ‘matplotlib’. Alternatively, to specify the plotting.backend for the whole session, set pd.options.plotting.backend.
legend
bool, default False
Whether to show the legend.
**kwargs
To be passed to the actual plotting function.
Returns:
matplotlib.AxesSubplot
A histogram plot.391-2、参数
391-2-1、by(可选,默认值为None):用于分组直方图的绘制,可以传入一个用于分组的变量,比如一个列名,如果指定了by参数,直方图会按照指定的组进行分开绘制。
391-2-2、ax(可选,默认值为None):一个matplotlib的Axes对象,如果指定了ax,那么直方图会绘制在这个Axes对象上,如果不指定,pandas会自动创建一个新的Axes对象。
391-2-3、grid(可选,默认值为True):控制是否在图中显示网格线,默认情况下是显示的,可以设置为False来隐藏网格线。
391-2-4、xlabelsize(可选,默认值为None):控制x轴标签的字体大小,如果没有指定,将使用默认的字体大小。
391-2-5、xrot(可选,默认值为None):控制x轴标签的旋转角度,以度数为单位,可以用来调整标签的显示方式。
391-2-6、ylabelsize(可选,默认值为None):控制y轴标签的字体大小,如果没有指定,将使用默认的字体大小。
391-2-7、yrot(可选,默认值为None):控制y轴标签的旋转角度,以度数为单位,可以用来调整标签的显示方式。
391-2-8、figsize(可选,默认值为None):设置图表的大小,传入一个元组,形如(宽度, 高度),单位为英寸,如果不指定,使用matplotlib的默认大小。
391-2-9、bins(可选,默认值为10):设置直方图的柱子数量(即区间数),可以传入一个整数来指定柱子数,或者传入一个序列(如list或array)来自定义柱子的边界。
391-2-10、backend(可选,默认值为None):指定使用哪个绘图后端,可以传入一个字符串指定matplotlib或其他可用的后端,如果不指定,则使用pandas默认的绘图后端。
391-2-11、legend(可选,默认值为False):控制是否显示图例,如果数据进行了分组,且legend设置为True,那么图例会显示分组的名称。
391-2-12、**kwargs(可选):其他可选参数,可以传递给matplotlib的hist方法来定制图表的其他属性。例如,可以传递color来指定直方图的颜色。
391-3、功能
用于对一个Series对象的数据进行直方图绘制,直方图是显示数据分布的一种图表,可以帮助我们理解数据的集中趋势、分布范围以及是否存在异常值。
391-4、返回值
返回一个matplotlib.axes.Axes对象,如果图表进行了分组,那么返回的是一个包含多个Axes对象的numpy数组。
391-5、说明
使用场景:
391-5-1、探索性数据分析(EDA):在数据分析的初始阶段,直方图是一种常用的工具,用于了解单个变量的分布情况,通过直方图,可以快速识别数据的集中趋势、离散程度、偏度、峰度等特征。例如,分析一列数据的分布是否为正态分布,或者数据是否存在偏斜。
391-5-2、识别异常值:直方图可以帮助发现异常值或极端值,这些异常值通常会出现在直方图的两端,且远离其他数据。例如,在金融数据分析中,可以通过直方图识别交易量中的异常峰值。
391-5-3、比较不同子集的分布:当你有一个数据集按某个类别变量分组时,可以使用by参数来对各组数据绘制直方图,并比较它们的分布差异。例如,比较男性和女性的收入分布,或不同年龄段的支出分布。
391-5-4、评估数据的平滑性:直方图可以帮助评估数据的平滑性及频率分布,这在统计建模前非常有用,如果数据的分布较为平滑,那么后续建模(如回归分析)可能更加有效。
391-5-5、调整模型参数:在机器学习和统计建模中,通过直方图可以查看特征变量的分布,以决定是否需要进行数据变换(如对数变换、标准化)或调整模型的参数。例如,正态分布的数据通常会更适合线性模型,而高度偏斜的数据可能需要进行转换。
391-5-6、多样本数据的可视化:当你有多个样本数据时,直方图可以帮助你可视化不同样本的分布,了解各个样本之间的差异。例如,比较不同城市的空气质量指数分布。
391-5-7、简单的数据呈现:在向非技术人员展示数据时,直方图是一种直观的工具,用来解释数据的基本特征和趋势。例如,在报告中展示公司各部门的工作时长分布。
391-5-8、数据预处理:在数据预处理阶段,通过绘制直方图可以检查数据是否存在错误或异常值,从而决定是否需要清洗或转换数据。例如,检查输入数据是否存在不合理的零值或负值。
391-6、用法
391-6-1、数据准备
无391-6-2、代码示例
# 391、pandas.Series.hist方法
# 391-1、探索性数据分析(EDA)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
# 配置字体,确保中文字符正常显示
matplotlib.rcParams['font.sans-serif'] = ['Microsoft YaHei']
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示问题
# 生成一个随机数据集,假设是正态分布
data = np.random.normal(loc=0, scale=1, size=1000)
series = pd.Series(data)
# 绘制直方图
series.hist(bins=30, edgecolor='black')
plt.title('Normal Distribution')
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.show()
# 391-2、识别异常值
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
# 配置字体,确保中文字符正常显示
matplotlib.rcParams['font.sans-serif'] = ['Microsoft YaHei']
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示问题
# 生成一个包含异常值的数据集
data_with_outliers = np.append(np.random.normal(loc=0, scale=1, size=980), [10, 12, 15, -10, -12])
series = pd.Series(data_with_outliers)
# 绘制直方图
series.hist(bins=30, edgecolor='black')
plt.title('Histogram with Outliers')
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.show()
# 391-3、比较不同子集的分布
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
# 配置字体,确保中文字符正常显示
matplotlib.rcParams['font.sans-serif'] = ['Microsoft YaHei']
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示问题
# 生成一个分类数据集
df = pd.DataFrame({
'Category': np.random.choice(['A', 'B'], size=1000),
'Values': np.random.normal(loc=0, scale=1, size=1000)
})
# 按照类别绘制直方图
df.hist(column='Values', by='Category', bins=30, edgecolor='black', figsize=(10, 5))
plt.suptitle('Distribution by Category')
plt.show()
# 391-4、评估数据的平滑性
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
# 配置字体,确保中文字符正常显示
matplotlib.rcParams['font.sans-serif'] = ['Microsoft YaHei']
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示问题
# 生成一个稍微偏斜的数据集
data = np.random.exponential(scale=1, size=1000)
series = pd.Series(data)
# 绘制直方图
series.hist(bins=30, edgecolor='black')
plt.title('Exponential Distribution')
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.show()
# 391-5、调整模型参数
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
# 配置字体,确保中文字符正常显示
matplotlib.rcParams['font.sans-serif'] = ['Microsoft YaHei']
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示问题
# 生成一个高度偏斜的数据集
data = np.random.chisquare(df=2, size=1000)
series = pd.Series(data)
# 绘制直方图
series.hist(bins=30, edgecolor='black')
plt.title('Chi-square Distribution')
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.show()
# 对数据进行对数变换后重新绘制直方图
series_log = np.log(series + 1)
series_log.hist(bins=30, edgecolor='black')
plt.title('Log-Transformed Chi-square Distribution')
plt.xlabel('Log(Value + 1)')
plt.ylabel('Frequency')
plt.show()
# 391-6、多样本数据的可视化
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
# 配置字体,确保中文字符正常显示
matplotlib.rcParams['font.sans-serif'] = ['Microsoft YaHei']
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示问题
# 生成多个样本数据集
sample1 = np.random.normal(loc=0, scale=1, size=1000)
sample2 = np.random.normal(loc=2, scale=1.5, size=1000)
# 创建数据框
df = pd.DataFrame({'Sample 1': sample1, 'Sample 2': sample2})
# 绘制直方图
df.plot.hist(subplots=True, bins=30, edgecolor='black', alpha=0.5, figsize=(10, 5))
plt.suptitle('Comparison of Two Samples')
plt.show()
# 391-7、简单的数据呈现
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
# 配置字体,确保中文字符正常显示
matplotlib.rcParams['font.sans-serif'] = ['Microsoft YaHei']
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示问题
# 假设有一个数据集记录了各部门的工作时长
work_hours = pd.Series([40, 42, 38, 41, 45, 50, 30, 35, 39, 48, 52, 37])
# 绘制直方图
work_hours.hist(bins=5, edgecolor='black')
plt.title('Work Hours Distribution')
plt.xlabel('Hours')
plt.ylabel('Frequency')
plt.show()
# 391-8、数据预处理
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
# 配置字体,确保中文字符正常显示
matplotlib.rcParams['font.sans-serif'] = ['Microsoft YaHei']
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示问题
# 生成一个包含潜在错误值的数据集
data_with_errors = np.append(np.random.normal(loc=50, scale=10, size=980), [0, -10, 1000])
series = pd.Series(data_with_errors)
# 绘制直方图
series.hist(bins=30, edgecolor='black')
plt.title('Data with Potential Errors')
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.show()
# 通过直方图查看后,可以进一步处理这些异常值
# 例如,将低于10或高于100的值视为错误并替换
series_cleaned = series[(series >= 10) & (series <= 100)]
series_cleaned.hist(bins=30, edgecolor='black')
plt.title('Cleaned Data')
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.show()391-6-3、结果输出
# 391、pandas.Series.hist方法
# 391-1、探索性数据分析(EDA)
# 见图1
# 391-2、识别异常值
# 见图2
# 391-3、比较不同子集的分布
# 见图3
# 391-4、评估数据的平滑性
# 见图4
# 391-5、调整模型参数
# 见图5
# 391-6、多样本数据的可视化
# 见图6
# 391-7、简单的数据呈现
# 见图7
# 391-8、数据预处理
# 见图8图1:

图2:

图3:

图4:

图5:


图6:

图7:

图8:


392、pandas.Series.to_pickle方法
392-1、语法
# 392、pandas.Series.to_pickle方法
pandas.Series.to_pickle(path, *, compression='infer', protocol=5, storage_options=None)
Pickle (serialize) object to file.
Parameters:
pathstr, path object, or file-like object
String, path object (implementing os.PathLike[str]), or file-like object implementing a binary write() function. File path where the pickled object will be stored.
compressionstr or dict, default ‘infer’
For on-the-fly compression of the output data. If ‘infer’ and ‘path’ is path-like, then detect compression from the following extensions: ‘.gz’, ‘.bz2’, ‘.zip’, ‘.xz’, ‘.zst’, ‘.tar’, ‘.tar.gz’, ‘.tar.xz’ or ‘.tar.bz2’ (otherwise no compression). Set to None for no compression. Can also be a dict with key 'method' set to one of {'zip', 'gzip', 'bz2', 'zstd', 'xz', 'tar'} and other key-value pairs are forwarded to zipfile.ZipFile, gzip.GzipFile, bz2.BZ2File, zstandard.ZstdCompressor, lzma.LZMAFile or tarfile.TarFile, respectively. As an example, the following could be passed for faster compression and to create a reproducible gzip archive: compression={'method': 'gzip', 'compresslevel': 1, 'mtime': 1}.
New in version 1.5.0: Added support for .tar files.
protocolint
Int which indicates which protocol should be used by the pickler, default HIGHEST_PROTOCOL (see [1] paragraph 12.1.2). The possible values are 0, 1, 2, 3, 4, 5. A negative value for the protocol parameter is equivalent to setting its value to HIGHEST_PROTOCOL.
[1]
https://docs.python.org/3/library/pickle.html.
storage_optionsdict, optional
Extra options that make sense for a particular storage connection, e.g. host, port, username, password, etc. For HTTP(S) URLs the key-value pairs are forwarded to urllib.request.Request as header options. For other URLs (e.g. starting with “s3://”, and “gcs://”) the key-value pairs are forwarded to fsspec.open. Please see fsspec and urllib for more details, and for more examples on storage options refer here.392-2、参数
392-2-1、path(必须):字符串,指定保存pickle文件的位置,可以是一个本地文件路径(例如'data.pkl'),也可以是URL(例如's3://bucket_name/data.pkl')。
392-2-2、compression(可选,默认值为'infer'):字符串或字典,指定压缩方式,如果是字典,则可以包含method和compresslevel(压缩级别)的键,字典允许对压缩进行更细粒度的控制。可以是以下字符串之一:
- 'infer':基于文件扩展名推断压缩方式,例如
.gz或.bz2。 - 'gzip'或'gz':使用gzip压缩。
- 'bz2':使用bzip2压缩。
- 'zip':使用zip压缩。
- 'xz'或'lzma':使用lzma压缩。
392-2-3、protocol(可选,默认值为5):整数,指定Pickle协议版本,不同的版本可能具有不同的性能特性,Python 3.8开始默认使用协议版本5。
392-2-4、storage_options(可选,默认值为None):字典,含有用于指定额外的存储选项的键值对,例如当path是远程URL时用到的存储选项,选项的支持与所使用的存储连接器相关。
392-3、功能
将Pandas Series序列化为一个pickle文件,该文件可以在以后通过pandas.read_pickle()方法读取,Pickle是Python原生的序列化格式,它能够高效地保存和恢复Python对象。
392-4、返回值
没有返回值,它的作用是将Series对象保存到指定路径。
392-5、说明
无
392-6、用法
392-6-1、数据准备
无392-6-2、代码示例
# 392、pandas.Series.to_pickle方法
# 392-1、保存为本地pickle文件
import pandas as pd
# 创建一个示例 Series
data = pd.Series([1, 2, 3, 4, 5])
# 保存到本地路径
data.to_pickle("data.pkl")
# 392-2、使用压缩保存
import pandas as pd
# 创建一个示例Series
data = pd.Series([1, 2, 3, 4, 5])
# 使用 gzip 压缩保存
data.to_pickle("data_compressed.pkl.gz", compression='gzip')
# 392-3、使用压缩保存并指定压缩选项
import pandas as pd
# 创建一个示例Series
data = pd.Series([1, 2, 3, 4, 5])
# 使用gzip压缩保存并指定压缩级别
data.to_pickle("data_compressed_level1.pkl.gz", compression={'method': 'gzip', 'compresslevel': 1})392-6-3、结果输出

393、pandas.Series.to_csv方法
393-1、语法
# 393、pandas.Series.to_csv方法
pandas.Series.to_csv(path_or_buf=None, *, sep=',', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None, compression='infer', quoting=None, quotechar='"', lineterminator=None, chunksize=None, date_format=None, doublequote=True, escapechar=None, decimal='.', errors='strict', storage_options=None)
Write object to a comma-separated values (csv) file.
Parameters:
path_or_bufstr, path object, file-like object, or None, default None
String, path object (implementing os.PathLike[str]), or file-like object implementing a write() function. If None, the result is returned as a string. If a non-binary file object is passed, it should be opened with newline=’’, disabling universal newlines. If a binary file object is passed, mode might need to contain a ‘b’.
sepstr, default ‘,’
String of length 1. Field delimiter for the output file.
na_repstr, default ‘’
Missing data representation.
float_formatstr, Callable, default None
Format string for floating point numbers. If a Callable is given, it takes precedence over other numeric formatting parameters, like decimal.
columnssequence, optional
Columns to write.
headerbool or list of str, default True
Write out the column names. If a list of strings is given it is assumed to be aliases for the column names.
indexbool, default True
Write row names (index).
index_labelstr or sequence, or False, default None
Column label for index column(s) if desired. If None is given, and header and index are True, then the index names are used. A sequence should be given if the object uses MultiIndex. If False do not print fields for index names. Use index_label=False for easier importing in R.
mode{‘w’, ‘x’, ‘a’}, default ‘w’
Forwarded to either open(mode=) or fsspec.open(mode=) to control the file opening. Typical values include:
‘w’, truncate the file first.
‘x’, exclusive creation, failing if the file already exists.
‘a’, append to the end of file if it exists.
encodingstr, optional
A string representing the encoding to use in the output file, defaults to ‘utf-8’. encoding is not supported if path_or_buf is a non-binary file object.
compressionstr or dict, default ‘infer’
For on-the-fly compression of the output data. If ‘infer’ and ‘path_or_buf’ is path-like, then detect compression from the following extensions: ‘.gz’, ‘.bz2’, ‘.zip’, ‘.xz’, ‘.zst’, ‘.tar’, ‘.tar.gz’, ‘.tar.xz’ or ‘.tar.bz2’ (otherwise no compression). Set to None for no compression. Can also be a dict with key 'method' set to one of {'zip', 'gzip', 'bz2', 'zstd', 'xz', 'tar'} and other key-value pairs are forwarded to zipfile.ZipFile, gzip.GzipFile, bz2.BZ2File, zstandard.ZstdCompressor, lzma.LZMAFile or tarfile.TarFile, respectively. As an example, the following could be passed for faster compression and to create a reproducible gzip archive: compression={'method': 'gzip', 'compresslevel': 1, 'mtime': 1}.
New in version 1.5.0: Added support for .tar files.
May be a dict with key ‘method’ as compression mode and other entries as additional compression options if compression mode is ‘zip’.
Passing compression options as keys in dict is supported for compression modes ‘gzip’, ‘bz2’, ‘zstd’, and ‘zip’.
quotingoptional constant from csv module
Defaults to csv.QUOTE_MINIMAL. If you have set a float_format then floats are converted to strings and thus csv.QUOTE_NONNUMERIC will treat them as non-numeric.
quotecharstr, default ‘"’
String of length 1. Character used to quote fields.
lineterminatorstr, optional
The newline character or character sequence to use in the output file. Defaults to os.linesep, which depends on the OS in which this method is called (’\n’ for linux, ‘\r\n’ for Windows, i.e.).
Changed in version 1.5.0: Previously was line_terminator, changed for consistency with read_csv and the standard library ‘csv’ module.
chunksizeint or None
Rows to write at a time.
date_formatstr, default None
Format string for datetime objects.
doublequotebool, default True
Control quoting of quotechar inside a field.
escapecharstr, default None
String of length 1. Character used to escape sep and quotechar when appropriate.
decimalstr, default ‘.’
Character recognized as decimal separator. E.g. use ‘,’ for European data.
errorsstr, default ‘strict’
Specifies how encoding and decoding errors are to be handled. See the errors argument for open() for a full list of options.
storage_optionsdict, optional
Extra options that make sense for a particular storage connection, e.g. host, port, username, password, etc. For HTTP(S) URLs the key-value pairs are forwarded to urllib.request.Request as header options. For other URLs (e.g. starting with “s3://”, and “gcs://”) the key-value pairs are forwarded to fsspec.open. Please see fsspec and urllib for more details, and for more examples on storage options refer here.
Returns:
None or str
If path_or_buf is None, returns the resulting csv format as a string. Otherwise returns None.393-2、参数
393-2-1、path_or_buf(可选,默认值为None):字符串或带路径文件对象,文件路径或对象,如果未提供路径,结果将作为字符串返回。
393-2-2、sep(可选,默认值为','):字符串,字段分隔符。
393-2-3、na_rep(可选,默认值为''):字符串,NaN值的表示形式。
393-2-4、float_format(可选,默认值为None):字符串,浮点数格式。例如'%.2f'表示保留两位小数。
393-2-5、columns(可选,默认值为None):指定列名,这在Series中通常不使用,因为Series本身没有列。
393-2-6、header(可选,默认值为True):布尔值,是否写出列名(总是False因为Series没有列名)。
393-2-7、index(可选,默认值为True):布尔值,是否写出行标签。
393-2-8、index_label(可选,默认值为None):字符串或序列或None,行标签的名称,如果为None,则使用现有行名称;如果为False,则不写出行标签的名称。
393-2-9、mode(可选,默认值为'w'):字符串,文件打开模式,使用'w'表示写入模式,使用'a'表示追加模式。
393-2-10、encoding(可选,默认值为None):字符串,文件编码。
393-2-11、compression(可选,默认值为'infer'):字符串或字典,压缩方式包含:如'gzip'、'bz2'、'zip'及'xz'。
393-2-12、quoting(可选,默认值为None):控制何时应该引用值。
393-2-13、quotechar(可选,默认值为'"'):字符串,用于引号的字符。
393-2-14、lineterminator(可选,默认值为None):字符串,行终止符(通常为'\n')。
393-2-15、chunksize(可选,默认值为None):整数或None,若非None,则分批写入数据。
393-2-16、date_format(可选,默认值为None):字符串,日期格式。
393-2-17、doublequote(可选,默认值为True):布尔值,控制在字段中如何处理引号字符。
393-2-18、escapechar(可选,默认值为None):字符串,用于字符转义的字符。
393-2-19、decimal(可选,默认值为'.'):字符串,备选的小数符号。
393-2-20、errors(可选,默认值为'strict'):字符串,指定在数据转换期间的错误处理行为。
393-2-21、storage_options(可选,默认值为None):字典,额外的文件系统选项。
393-3、功能
将Pandas的Series对象导出为一个CSV格式的文件或字符串,你可以指定文件路径以将数据保存到文件系统,也可以不指定路径以得到字符串形式的输出。
393-4、返回值
393-4-1、如果指定了path_or_buf:将数据写入指定的文件或对象,无返回值。
393-4-2、如果未指定path_or_buf:返回包含CSV数据的字符串。
393-5、说明
无
393-6、用法
393-6-1、数据准备
无393-6-2、代码示例
# 393、pandas.Series.to_csv方法
import pandas as pd
data = pd.Series([1.0, 2.5, 3.2, None, 5.0])
csv_string = data.to_csv(sep=';', na_rep='N/A', float_format='%.2f')
print(csv_string)393-6-3、结果输出
# 393、pandas.Series.to_csv方法
# ;0
# 0;1.00
# 1;2.50
# 2;3.20
# 3;N/A
# 4;5.00394、pandas.Series.to_dict方法
394-1、语法
# 394、pandas.Series.to_dict方法
pandas.Series.to_dict(*, into=<class 'dict'>)
Convert Series to {label -> value} dict or dict-like object.
Parameters:
into
class, default dict
The collections.abc.MutableMapping subclass to use as the return object. Can be the actual class or an empty instance of the mapping type you want. If you want a collections.defaultdict, you must pass it initialized.
Returns:
collections.abc.MutableMapping
Key-value representation of Series.394-2、参数
394-2-1、into(可选,默认值为<class 'dict'>):指定转换后的目标字典类型,默认情况下转换为标准的Python字典,你可传其他映射类型(如collections.OrderedDict或collections.defaultdict)来指定不同的字典类型。
394-3、功能
将Series对象的索引和值转化为字典,其中Series的索引作为字典的键和值作为字典的值。
394-4、返回值
返回一个字典,其中Series对象的索引作为键,Series对象的值作为字典的值。
394-5、说明
无
394-6、用法
394-6-1、数据准备
无394-6-2、代码示例
# 394、pandas.Series.to_dict方法
import pandas as pd
from collections import OrderedDict
# 创建一个示例Series
s = pd.Series([1, 2, 3], index=['a', 'b', 'c'])
# 默认转换为标准字典
default_dict = s.to_dict()
print("默认字典:", default_dict)
# 转换为有序字典
ordered_dict = s.to_dict(into=OrderedDict)
print("有序字典:", ordered_dict)394-6-3、结果输出
# 394、pandas.Series.to_dict方法
# 默认字典: {'a': 1, 'b': 2, 'c': 3}
# 有序字典: OrderedDict([('a', 1), ('b', 2), ('c', 3)])395、pandas.Series.to_excel方法
395-1、语法
# 395、pandas.Series.to_excel方法
pandas.Series.to_excel(excel_writer, *, sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, inf_rep='inf', freeze_panes=None, storage_options=None, engine_kwargs=None)
Write object to an Excel sheet.
To write a single object to an Excel .xlsx file it is only necessary to specify a target file name. To write to multiple sheets it is necessary to create an ExcelWriter object with a target file name, and specify a sheet in the file to write to.
Multiple sheets may be written to by specifying unique sheet_name. With all data written to the file it is necessary to save the changes. Note that creating an ExcelWriter object with a file name that already exists will result in the contents of the existing file being erased.
Parameters:
excel_writerpath-like, file-like, or ExcelWriter object
File path or existing ExcelWriter.
sheet_namestr, default ‘Sheet1’
Name of sheet which will contain DataFrame.
na_repstr, default ‘’
Missing data representation.
float_formatstr, optional
Format string for floating point numbers. For example float_format="%.2f" will format 0.1234 to 0.12.
columnssequence or list of str, optional
Columns to write.
headerbool or list of str, default True
Write out the column names. If a list of string is given it is assumed to be aliases for the column names.
indexbool, default True
Write row names (index).
index_labelstr or sequence, optional
Column label for index column(s) if desired. If not specified, and header and index are True, then the index names are used. A sequence should be given if the DataFrame uses MultiIndex.
startrowint, default 0
Upper left cell row to dump data frame.
startcolint, default 0
Upper left cell column to dump data frame.
enginestr, optional
Write engine to use, ‘openpyxl’ or ‘xlsxwriter’. You can also set this via the options io.excel.xlsx.writer or io.excel.xlsm.writer.
merge_cellsbool, default True
Write MultiIndex and Hierarchical Rows as merged cells.
inf_repstr, default ‘inf’
Representation for infinity (there is no native representation for infinity in Excel).
freeze_panestuple of int (length 2), optional
Specifies the one-based bottommost row and rightmost column that is to be frozen.
storage_optionsdict, optional
Extra options that make sense for a particular storage connection, e.g. host, port, username, password, etc. For HTTP(S) URLs the key-value pairs are forwarded to urllib.request.Request as header options. For other URLs (e.g. starting with “s3://”, and “gcs://”) the key-value pairs are forwarded to fsspec.open. Please see fsspec and urllib for more details, and for more examples on storage options refer here.
New in version 1.2.0.
engine_kwargsdict, optional
Arbitrary keyword arguments passed to excel engine.395-2、参数
395-2-1、excel_writer(必须):文件路径字符串或ExcelWriter对象,表示要写入的Excel文件位置或已经打开的ExcelWriter。
395-2-2、sheet_name(可选,默认值为'Sheet1'):字符串,指定要写入数据的工作表名称。
395-2-3、na_rep(可选,默认值为''):字符串,缺失值(NA/NaN)在Excel文件中的表示形式。
395-2-4、float_format(可选,默认值为None):字符串,用于格式化浮点数的格式字符串。例如: "%.2f" 表示保留两位小数。
395-2-5、columns(可选,默认值为None):列表或None,指定要写入的列。如果为None,则写入所有列。
395-2-6、header(可选,默认值为True):布尔值或字符串列表,如果为True,则写入列标签,如果提供一个字符串列表,这些字符串将作为列标签。
395-2-7、index(可选,默认值为True):布尔值,如果为True,则写入索引。
395-2-8、index_label(可选,默认值为None):字符串或序列,指定索引列的标签,如果为None且index为True,则使用索引名称(如果可用)。
395-2-9、startrow(可选,默认值为0):整数,写入数据时的起始行。
395-2-10、startcol(可选,默认值为0):整数,写入数据时的起始列。
395-2-11、engine(可选,默认值为None):字符串,写入Excel文件所使用的引擎,如果为None,pandas会尝试根据文件扩展名自动检测。
395-2-12、merge_cells(可选,默认值为True):布尔值,是否合并空白单元格。
395-2-13、inf_rep(可选,默认值为'inf'):字符串,无穷大(inf)在Excel文件中的表示形式。
395-2-14、freeze_panes(可选,默认值为None):元组或None,冻结窗口的分隔线。
395-2-15、storage_options(可选,默认值为None):字典,与文件系统连接相关的额外选项。
395-2-16、engine_kwargs(可选,默认值为None):字典,传递给引擎的附加关键字参数。
395-3、功能
将pandas.Series数据导出到Excel文件中,以便进行数据的持久化存储、共享或进一步的分析。
395-4、返回值
该方法不返回任何值。方法执行后,Series数据会写入指定的Excel文件中。
395-5、说明
无
395-6、用法
395-6-1、数据准备
无395-6-2、代码示例
# 395、pandas.Series.to_excel方法
import pandas as pd
import datetime
# 示例库存数据
inventory = pd.Series([120, 150, 90, 200], index=['Product A', 'Product B', 'Product C', 'Product D'])
# 生成当前日期的文件名
current_date = datetime.datetime.now().strftime("%Y-%m-%d")
file_name = f"inventory_report_{current_date}.xlsx"
# 导出到Excel文件
inventory.to_excel(file_name, sheet_name="Inventory")395-6-3、结果输出