况可能很快就会发生变化。
从定义上讲,LLM 需要大量数据,而且所使用的数据集越来越大。根据缩放定律[2],要提高性能,必须同时增加参数数量和训练标记数量(后者被认为是最重要的因素)。
这些数据集包含人类产生的数据,但一些研究表明,这是一种有限的资源。人类产生的数据规模也不及我们,因为我们通过 LLM 培训增加了数据消耗。一项最近发表的研究认为,我们无法支持未来十年的扩展 [3]。
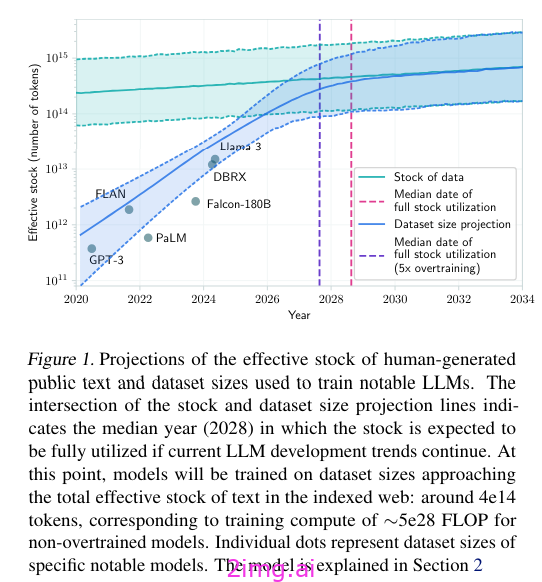
图片来源:[3]
随着 ChatGPT 和开源模型的出现,人工智能模型生成的文本量正在不断增长。例如,最近发表的一项研究 [1] 表明,随着低成本机器翻译 (MT) 的出现,网络上的内容通常可以使用 MT 算法快速翻译成多种语言。
机器生成的多向并行翻译不仅占据了可用机器翻译的资源较少的语言的网页翻译内容总量,还构成了这些语言网页内容总量的很大一部分。 —来源
然而,这会导致几个问题:
- 这些翻译的内容存在一些偏见,并且主题分布不同(质量低下,并且表明它们只是为了产生广告收入)。
- 翻译的语言越多,平均质量越低
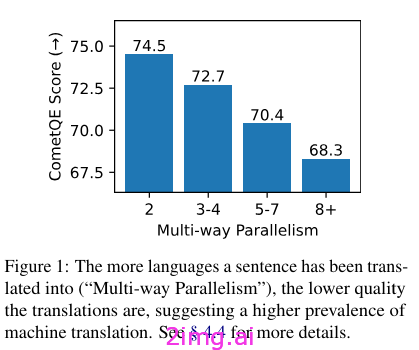
图片来源:[1]
人工智能产生的文本数量在各个领域(互联网、科学文章、学校学生)都在增加,而且越来越难以识别 [4–6]。如果未来的模型是用从网络上抓取的文本进行训练的,那么它们将不可避免地用前辈产生的数据进行训练。
当使用 AI 生成的文本训练模型时会发生什么?如果大多数文本都是由 ChatGPT 生成的,会发生什么?
根据《自然》杂志最近发表的一篇文章,这会导致模型崩溃 [7]。模型崩溃是一个退化过程,其性能下降,产生错误并变得无用。从统计学的角度来看,这分为两个阶段:
- 早期模型崩溃,模型开始丢失有关分布尾部的信息。
- 后期模型崩溃,模型收敛到与原始分布完全不同的分布,因此不再产生任何有用的东西。
之前已经证明,模型无法在自训练循环中进行训练(在使用真实数据进行第一次迭代后,模型将使用自生成数据进行训练)。使用模型本身生成的数据会导致系统崩溃。
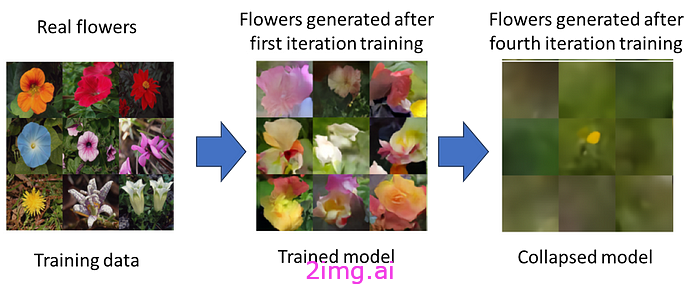
模型崩塌。图片改编自:[8]
如上所示,模型首先开始偏离训练数据,忘记原始数据和代表性不足的类别的元素(早期崩溃),然后无法产生有意义的数据(晚期崩溃)。
因此,研究表明,不断从生成的数据(或被生成的数据毒害的数据)中学习会导致模型崩溃。因此,一些作者警告说,互联网上生成的数据爆炸式增长可能会导致崩溃:
模型崩溃警告称,生成模型的民主化访问可能会污染训练未来生成模型迭代所需的数据。——来源,[9]
然而,到目前为止,我们既没有用文本模型对问题进行严格的描述,也没有发现导致这种崩溃的原因。在本研究中 [7],当存在 AI 生成的数据时,三种错误会导致崩溃:
- 统计近似误差。初始数据是有限的,但是一旦训练数据趋于无穷大,数据就会分散,因此在进一步训练的每一步中,信息都会开始丢失。
- 函数表达力误差。Transformer 具有表达力限制,因此在近似初始分布时会出现一些误差。
- 函数近似误差。这种误差来自于学习过程,作为随机梯度下降的结构偏差。
上述每个因素都会导致模型崩溃,并且其影响会随着代代推移而不断加剧。
在本文中,作者 [7] 采用预先训练的模型并对数据集进行微调。这是 LLM 的常见用途(尤其是因为从头开始训练模型的成本太高)。作者测试的是如果这个微调数据集是由另一个微调模型生成的,会发生什么。作者从 HuggingFace 中获取一个模型,使用 wikitext2 数据集对其进行微调,在测试集上对其进行评估,然后使用它来生成数据,从而生成一个人工数据集。然后在人工数据集上对模型进行迭代训练。
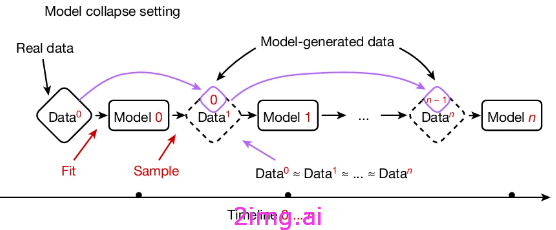
图片来自[7],许可证:此处
通过对模型进行 5 个 epoch 的训练,我们发现模型的性能逐渐下降,生成的样本中逐渐出现了一条长尾,这些样本是其他模型生成样本引入的误差的产物。
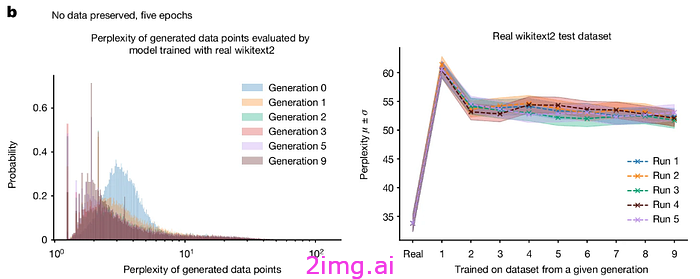
图片来自[7],许可证:此处
作者指出,通过保留原始数据集中一定比例的数据,可以减少这种退化。在生成的数据上训练的模型可以学习一些原始任务,但错误率会更高(困惑度增加表明)。对于作者来说,随着困惑度较低的样本在几代中积累,模型开始崩溃(因此产生复合效应)。继续循环,这种影响将导致模型最终崩溃。
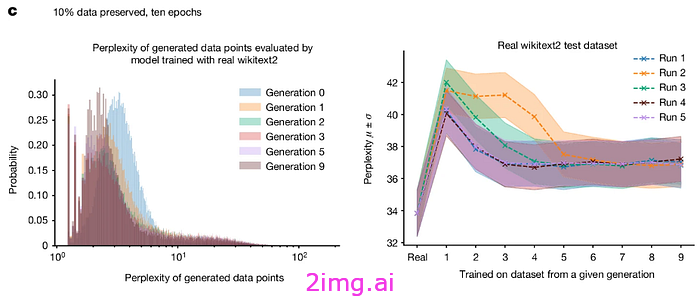
图片来自[7],许可证:此处
在检查下,模型开始生成原始模型以更高可能性生成的那些示例。这种效果与以下事实相一致:在训练过程中,如果不重复(从那些较稀有的知识开始),模型就会丢失部分知识。在模型看到一个示例后,该示例的知识会最大化,但随后该知识就会逐渐消失 [10]。因此,继续训练模型会首先开始丢失稀有知识,并且只产生具有最大可能性的示例。

图片来源:[10]
当使用数据集中 AI 生成的内容训练模型时,它会学会只生成众所周知的概念、短语和语调。同时,它会忘记数据集中不太常见的想法和概念。从长远来看,这会导致模型崩溃。
模型崩溃对于未来的法学硕士意味着什么?
长期对语言模型进行毒害攻击并非新鲜事。例如,我们看到点击、内容和网络喷子农场的出现,这是一种人类“语言模型”,其作用是误导社交网络和搜索算法。——来源
目前,此类内容的产生主要影响的是搜索引擎。大多数此类内容的产生都是为了在搜索引擎中获得较高的排名,并通过展示获利。谷歌试图通过在其算法中为这些网站分配较低的价值来限制这种现象。但这并不能解决问题,因为人们找到了新的方法来避免这些对策。
通常,训练 LLM 的数据集是自动获取的,并且生成的许多数据也可能位于信誉良好的网站上。这意味着将来这些数据可能会大量进入训练集。模型崩溃不仅会影响性能,还会影响算法的公平性。模型会很快忘记代表性不足的知识(甚至在看到对性能的明显影响之前),这意味着会对少数群体和边缘群体产生影响。
水印不是解决方案。首先,水印可以去除(它与生成的图像一起显示)。其次,检测生成文本的模型并不那么准确,很容易被欺骗。第三,公司不会分享有关其水印的信息(以免方便竞争对手训练模型)。最后,使用开源模型,许多生成的文本无论如何都不会有水印。
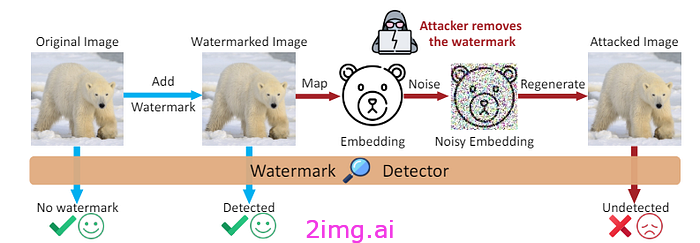
去除隐形水印。图片来源:[11]
那些正在训练模型或在大量生成文本出现之前保存数据的公司比竞争对手更具优势。一般来说,数据质量至关重要,拥有由真人生成的数据对于拥有这些数据的人来说是一笔巨大的财富。或者,需要协调一致的努力才能确定文本的来源。