目录
- 简介
- 计算需求
-
- 参数与数据集的权衡
- 计算成本的工程意义
- 内存需求
-
- 推理
-
- 模型权重
- 总推理内存
- 训练
-
- 模型参数
- 优化器状态
- 梯度
- 激活值和批大小
- 总训练内存
- 分布式训练
-
- 分片优化器
- 3D 并行
- 分片优化器 + 3D 并行
- 参考
简介
许多关于Transformer语言模型的基本且重要的信息都可以用相当简单的方式计算出来。不幸的是,这些计算公式在NLP社区中并不广为人知。本文档的目的是收集这些公式,以及相关的知识,包括它们的来源和重要性。
**注意:**本文主要关注训练成本,而训练成本主要受VRAM的限制。有关推理成本的类似讨论,重点关注延迟,请查看Kipply撰写的这篇优秀的博客文章。
计算需求
计算训练Transformer模型成本的基本公式如下:
C ≈ τ T = 6 P D C\approx\tau T = 6PD C≈τT=6PD
其中:
- C C C 是训练Transformer模型所需的总计算量,以浮点运算次数表示
- C = C forward + C backward C=C_{\text{forward}}+C_{\text{backward}} C=Cforward+Cbackward
- C forward ≈ 2 P D C_{\text{forward}}\approx2PD Cforward≈2PD
- C backward ≈ 4 P D C_{\text{backward}}\approx4PD Cbackward≈4PD
- τ \tau τ 是硬件设置的总吞吐量( τ = ( GPU数量 ) × ( 实际FLOPs / GPU ) \tau=(\text{GPU数量}) \times (\text{实际FLOPs}/\text{GPU}) τ=(GPU数量)×(实际FLOPs/GPU)),以FLOPs为单位
- T T T 是训练模型所花费的时间,以秒为单位
- P P P 是Transformer模型中的参数数量
- D D D 是数据集大小,以token为单位
这些公式在 OpenAI’s scaling laws paper and DeepMind’s scaling laws paper中提出并经过实验验证。有关更多信息,请参阅每篇论文。
值得一提的是,我们需要讨论一下 C C C 的单位。 C C C 是总计算量的度量,但可以用许多单位来衡量,例如:
- FLOP-s,单位为 [ 浮点运算次数 秒 ] × [ 秒 ] [\frac{\text{浮点运算次数}}{\text{秒}}] \times [\text{秒}] [秒浮点运算次数]×[秒]
- GPU-hours,单位为 [ GPU数量 ] × [ 小时 ] [\text{GPU数量}]\times[\text{小时}] [GPU数量]×[小时]
- 缩放定律论文倾向于以PetaFLOP-days为单位报告值,即 1 0 15 × 24 × 3600 10^{15}\times24\times3600 1015×24×3600 次浮点运算
需要牢记的一个有用区别是 实际FLOPs \text{实际FLOPs} 实际FLOPs 的概念。虽然GPU加速器白皮书通常会宣传其理论FLOPs,但在实践中永远无法达到这些值(尤其是在分布式环境中!)。一些常见的分布式训练环境中报告的 实际FLOPs \text{实际FLOPs} 实际FLOPs 值在下面的计算成本部分报告。
请注意,参考了 这篇关于LLM训练成本的精彩博客文章 中使用的吞吐量-时间版本的成本公式。
参数与数据集的权衡
尽管严格来说,您可以根据需要训练任意数量token的Transformer,但训练的token数量会极大地影响计算成本和最终模型性能,因此在两者之间取得适当的平衡非常重要。
让我们先从最主要的问题开始:“计算最优”语言模型。通常被称为“Chinchilla缩放定律”,以论文中提出当前关于参数数量观点的模型系列命名,计算最优语言模型的参数数量和数据集大小满足近似值 D = 20 P D=20P D=20P。这在一个非常具体的意义上是最优的:在使用 1,000 个 GPU 1 小时和 1 个 GPU 1,000 小时的成本相同的资源机制下,如果您的目标是在最大化性能的同时最小化训练模型的 GPU 小时成本,则应使用上述公式。
**我们不建议训练token数量少于 200B 的 LLM。**尽管这对许多模型来说是“Chinchilla最优”的,但生成的模型通常质量很差。对于几乎所有应用,我们建议确定您的用例可接受的推理成本,并尽可能多地训练最大模型,以在该推理成本下尽可能多地训练token。
计算成本的工程意义
Transformer 的计算成本通常以 GPU-hours或者 FLOP-seconds为单位列出。
- GPT-NeoX 使用普通注意力机制在 A100 上实现了 150 TFLOP/s/A100 的吞吐量,使用 Flash 注意力机制则达到了 180 TFLOP/s/A100。这与其他高度优化的库在规模上是一致的,例如 Megatron-DS 报告在 A100 上的吞吐量在 137 到 163 TFLOP/s/A100 之间。
- 作为一般经验法则,您应该始终能够在 A100 上实现大约 120 TFLOP/s 的吞吐量。如果您看到低于 115 TFLOP/s/A100,则可能是您的模型或硬件配置有问题。
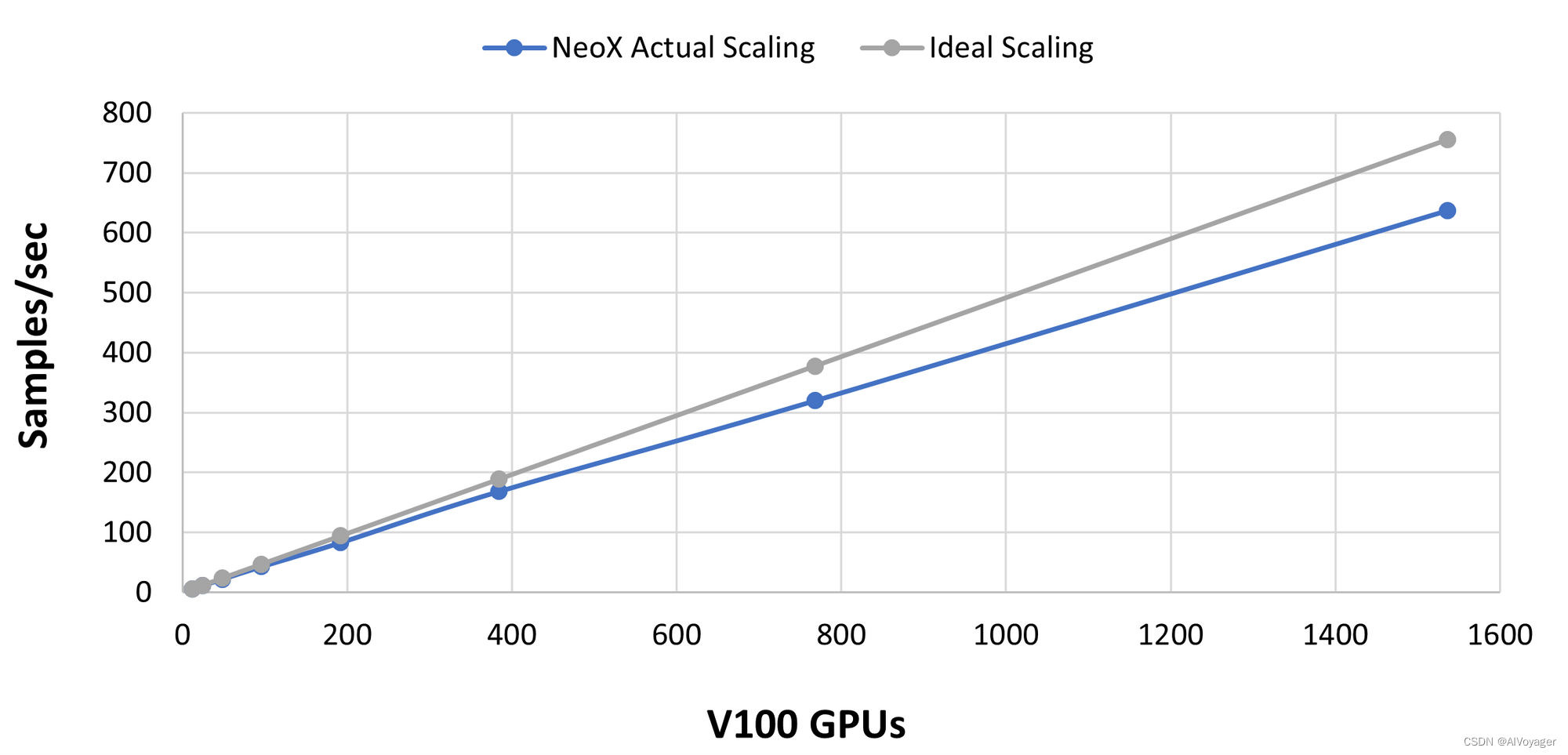
- 使用高质量的互连技术(如 InfiniBand),您可以在数据并行维度上实现线性或亚线性扩展(即,增加数据并行度应该会使整体吞吐量几乎线性增加)。下面是在橡树岭国家实验室的 Summit 超级计算机上测试 GPT-NeoX 库的图表。请注意,x 轴是 V100,而本文中的大多数数值示例都是针对 A100 的。
内存需求
Transformer 通常根据其参数大小来描述。但是,在确定哪些模型可以适合给定的计算资源集时,您需要知道模型将占用多少字节的空间。这可以告诉您,您的本地 GPU 可以容纳多大的模型进行推理,或者您可以在集群中使用一定数量的加速器内存训练多大的模型。
推理
模型权重
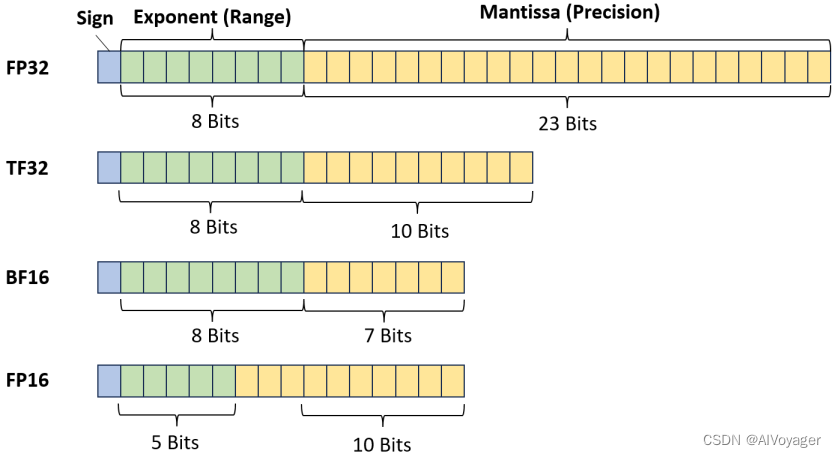
大多数 Transformer 都是以混合精度训练的,fp16 + fp32 或 bf16 + fp32。这减少了训练模型所需的内存量,也减少了运行推理所需的内存量。我们可以将语言模型从 fp32 转换为 fp16 甚至 int8,而不会造成明显的性能损失。这些数字指的是单个参数所需的位数(bits)。由于一个字节中有 8 位(bits),我们将此数字除以 8,即可得出每个参数需要多少字节。
- 在 int8 中, memory model = ( 1 字节 / 参数 ) ⋅ ( 参数数量 ) \text{memory}_{\text{model}}=(1 \text{ 字节} /\text{参数})\cdot ( \text{参数数量}) memorymodel=(1 字节/参数)⋅(参数数量)
- 在 fp16 和 bf16 中, memory model = ( 2 字节 / 参数 ) ⋅ ( 参数数量 ) \text{memory}_{\text{model}}=(2 \text{ 字节} /\text{参数})\cdot ( \text{参数数量})











![[创业之路-138] :产品需求、产品研发、产品生产、库存管理、品控、售后全流程 - 时序图](https://i-blog.csdnimg.cn/direct/f75522281bd047fd9d565f5feaf71bab.png)







