秋招面试专栏推荐 :深度学习算法工程师面试问题总结【百面算法工程师】——点击即可跳转
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡
专栏目录: 《YOLOv5入门 + 改进涨点》专栏介绍 & 专栏目录 |目前已有70+篇内容,内含各种Head检测头、损失函数Loss、Backbone、Neck、NMS等创新点改进
本文介绍了UniRepLKNet 提出的Dilated Reparam Block (DRB) 模块,通过并行连接扩张卷积层来增强大核卷积层,从而有效捕捉稀疏模式并提高性能。DRB 的应用不仅限于图像识别,还可以扩展到其他模态,例如音频、视频、点云和时间序列数据,展现出通用的多模态感知能力。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修改,并将修改后的完整代码放在文章的最后,方便大家一键运行,小白也可轻松上手实践。以帮助您更好地学习深度学习目标检测YOLO系列的挑战。
专栏地址: YOLOv5改进+入门——持续更新各种有效涨点方法 点击即可跳转
目录
1. 原理
2. 将C3_DRB添加到yolov8网络中
2.1 C3_DRB 代码实现
2.2 新增yaml文件
2.3 注册模块
2.4 执行程序
3. 完整代码分享
4. GFLOPs
5. 进阶
6. 总结
1. 原理

论文地址:UniRepLKNet: A Universal Perception Large-Kernel ConvNet for Audio, Video, Point Cloud, Time-Series and Image Recognition——点击即可跳转
官方代码: 官方代码仓库——点击即可跳转
扩张重参数块 (DRB) 是 UniRepLKNet 模型中引入的一项关键架构创新,它利用大核卷积来提高各种任务的性能。以下是其主要原理的总结:
具有不同扩张率的并行卷积:
-
DRB 采用大核卷积层,并通过具有不同扩张率的并行小核卷积进行增强。扩张卷积允许模型捕获数据中的局部和远距离模式。扩张率有效地扩展了小核卷积的接受域,而不会显着增加参数数量。
结构重参数化:
-
在训练期间,大核卷积和并行小核扩张卷积的输出被组合在一起。训练后,这些多个卷积层被重新参数化为单个大核卷积层。这样做是为了确保在推理过程中,模型每个 DRB 仅使用一个卷积运算,从而降低计算成本,同时保持训练期间从不同接受场获得的好处。
等效核变换:
-
捕获稀疏模式的扩张卷积层被转换为具有等效更大稀疏核的非扩张卷积。这是通过在卷积核中插入零条目来实现的,允许扩张卷积有效地合并到大核卷积中。
效率和灵活性:
-
该设计允许灵活地选择并行卷积的内核大小和扩张率。它确保卷积运算高效,并且网络可以用更少的层实现较大的有效接受场 (ERF),从而节省计算资源,同时仍能捕获复杂模式。
这种方法使 UniRepLKNet 能够有效地平衡对大感受野的需求和计算效率,从而提高不同任务的性能,特别是在大核卷积有益的领域。
2. 将C3_DRB添加到yolov8网络中
2.1 C3_DRB 代码实现
关键步骤一: 将下面的代码粘贴到\yolov5\models\common.py中
from timm.layers import DropPath, to_2tuple
import torch.utils.checkpoint as checkpoint
class GRNwithNHWC(nn.Module):
""" GRN (Global Response Normalization) layer
Originally proposed in ConvNeXt V2 (https://arxiv.org/abs/2301.00808)
This implementation is more efficient than the original (https://github.com/facebookresearch/ConvNeXt-V2)
We assume the inputs to this layer are (N, H, W, C)
"""
def __init__(self, dim, use_bias=True):
super().__init__()
self.use_bias = use_bias
self.gamma = nn.Parameter(torch.zeros(1, 1, 1, dim))
if self.use_bias:
self.beta = nn.Parameter(torch.zeros(1, 1, 1, dim))
def forward(self, x):
Gx = torch.norm(x, p=2, dim=(1, 2), keepdim=True)
Nx = Gx / (Gx.mean(dim=-1, keepdim=True) + 1e-6)
if self.use_bias:
return (self.gamma * Nx + 1) * x + self.beta
else:
return (self.gamma * Nx + 1) * x
def get_conv2d(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias,
attempt_use_lk_impl=True):
kernel_size = to_2tuple(kernel_size)
if padding is None:
padding = (kernel_size[0] // 2, kernel_size[1] // 2)
else:
padding = to_2tuple(padding)
need_large_impl = kernel_size[0] == kernel_size[1] and kernel_size[0] > 5 and padding == (kernel_size[0] // 2, kernel_size[1] // 2)
return nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=bias)
def get_bn(dim, use_sync_bn=False):
if use_sync_bn:
return nn.SyncBatchNorm(dim)
else:
return nn.BatchNorm2d(dim)
class SEBlock(nn.Module):
"""
Squeeze-and-Excitation Block proposed in SENet (https://arxiv.org/abs/1709.01507)
We assume the inputs to this layer are (N, C, H, W)
"""
def __init__(self, input_channels, internal_neurons):
super(SEBlock, self).__init__()
self.down = nn.Conv2d(in_channels=input_channels, out_channels=internal_neurons,
kernel_size=1, stride=1, bias=True)
self.up = nn.Conv2d(in_channels=internal_neurons, out_channels=input_channels,
kernel_size=1, stride=1, bias=True)
self.input_channels = input_channels
self.nonlinear = nn.ReLU(inplace=True)
def forward(self, inputs):
x = F.adaptive_avg_pool2d(inputs, output_size=(1, 1))
x = self.down(x)
x = self.nonlinear(x)
x = self.up(x)
x = F.sigmoid(x)
return inputs * x.view(-1, self.input_channels, 1, 1)
def fuse_bn(conv, bn):
conv_bias = 0 if conv.bias is None else conv.bias
std = (bn.running_var + bn.eps).sqrt()
return conv.weight * (bn.weight / std).reshape(-1, 1, 1, 1), bn.bias + (conv_bias - bn.running_mean) * bn.weight / std
def convert_dilated_to_nondilated(kernel, dilate_rate):
identity_kernel = torch.ones((1, 1, 1, 1)).to(kernel.device)
if kernel.size(1) == 1:
# This is a DW kernel
dilated = F.conv_transpose2d(kernel, identity_kernel, stride=dilate_rate)
return dilated
else:
# This is a dense or group-wise (but not DW) kernel
slices = []
for i in range(kernel.size(1)):
dilated = F.conv_transpose2d(kernel[:,i:i+1,:,:], identity_kernel, stride=dilate_rate)
slices.append(dilated)
return torch.cat(slices, dim=1)
def merge_dilated_into_large_kernel(large_kernel, dilated_kernel, dilated_r):
large_k = large_kernel.size(2)
dilated_k = dilated_kernel.size(2)
equivalent_kernel_size = dilated_r * (dilated_k - 1) + 1
equivalent_kernel = convert_dilated_to_nondilated(dilated_kernel, dilated_r)
rows_to_pad = large_k // 2 - equivalent_kernel_size // 2
merged_kernel = large_kernel + F.pad(equivalent_kernel, [rows_to_pad] * 4)
return merged_kernel
class NCHWtoNHWC(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return x.permute(0, 2, 3, 1)
class NHWCtoNCHW(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return x.permute(0, 3, 1, 2)
class DilatedReparamBlock(nn.Module):
"""
Dilated Reparam Block proposed in UniRepLKNet (https://github.com/AILab-CVC/UniRepLKNet)
We assume the inputs to this block are (N, C, H, W)
"""
def __init__(self, channels, kernel_size, deploy=False, use_sync_bn=False, attempt_use_lk_impl=True):
super().__init__()
self.lk_origin = get_conv2d(channels, channels, kernel_size, stride=1,
padding=kernel_size//2, dilation=1, groups=channels, bias=deploy,
attempt_use_lk_impl=attempt_use_lk_impl)
self.attempt_use_lk_impl = attempt_use_lk_impl
# Default settings. We did not tune them carefully. Different settings may work better.
if kernel_size == 17:
self.kernel_sizes = [5, 9, 3, 3, 3]
self.dilates = [1, 2, 4, 5, 7]
elif kernel_size == 15:
self.kernel_sizes = [5, 7, 3, 3, 3]
self.dilates = [1, 2, 3, 5, 7]
elif kernel_size == 13:
self.kernel_sizes = [5, 7, 3, 3, 3]
self.dilates = [1, 2, 3, 4, 5]
elif kernel_size == 11:
self.kernel_sizes = [5, 5, 3, 3, 3]
self.dilates = [1, 2, 3, 4, 5]
elif kernel_size == 9:
self.kernel_sizes = [5, 5, 3, 3]
self.dilates = [1, 2, 3, 4]
elif kernel_size == 7:
self.kernel_sizes = [5, 3, 3]
self.dilates = [1, 2, 3]
elif kernel_size == 5:
self.kernel_sizes = [3, 3]
self.dilates = [1, 2]
else:
raise ValueError('Dilated Reparam Block requires kernel_size >= 5')
if not deploy:
self.origin_bn = get_bn(channels, use_sync_bn)
for k, r in zip(self.kernel_sizes, self.dilates):
self.__setattr__('dil_conv_k{}_{}'.format(k, r),
nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=k, stride=1,
padding=(r * (k - 1) + 1) // 2, dilation=r, groups=channels,
bias=False))
self.__setattr__('dil_bn_k{}_{}'.format(k, r), get_bn(channels, use_sync_bn=use_sync_bn))
def forward(self, x):
if not hasattr(self, 'origin_bn'): # deploy mode
return self.lk_origin(x)
out = self.origin_bn(self.lk_origin(x))
for k, r in zip(self.kernel_sizes, self.dilates):
conv = self.__getattr__('dil_conv_k{}_{}'.format(k, r))
bn = self.__getattr__('dil_bn_k{}_{}'.format(k, r))
out = out + bn(conv(x))
return out
def switch_to_deploy(self):
if hasattr(self, 'origin_bn'):
origin_k, origin_b = fuse_bn(self.lk_origin, self.origin_bn)
for k, r in zip(self.kernel_sizes, self.dilates):
conv = self.__getattr__('dil_conv_k{}_{}'.format(k, r))
bn = self.__getattr__('dil_bn_k{}_{}'.format(k, r))
branch_k, branch_b = fuse_bn(conv, bn)
origin_k = merge_dilated_into_large_kernel(origin_k, branch_k, r)
origin_b += branch_b
merged_conv = get_conv2d(origin_k.size(0), origin_k.size(0), origin_k.size(2), stride=1,
padding=origin_k.size(2)//2, dilation=1, groups=origin_k.size(0), bias=True,
attempt_use_lk_impl=self.attempt_use_lk_impl)
merged_conv.weight.data = origin_k
merged_conv.bias.data = origin_b
self.lk_origin = merged_conv
self.__delattr__('origin_bn')
for k, r in zip(self.kernel_sizes, self.dilates):
self.__delattr__('dil_conv_k{}_{}'.format(k, r))
self.__delattr__('dil_bn_k{}_{}'.format(k, r))
class UniRepLKNetBlock(nn.Module):
def __init__(self,
dim,
kernel_size,
drop_path=0.,
layer_scale_init_value=1e-6,
deploy=False,
attempt_use_lk_impl=True,
with_cp=False,
use_sync_bn=False,
ffn_factor=4):
super().__init__()
self.with_cp = with_cp
# if deploy:
# print('------------------------------- Note: deploy mode')
# if self.with_cp:
# print('****** note with_cp = True, reduce memory consumption but may slow down training ******')
self.need_contiguous = (not deploy) or kernel_size >= 7
if kernel_size == 0:
self.dwconv = nn.Identity()
self.norm = nn.Identity()
elif deploy:
self.dwconv = get_conv2d(dim, dim, kernel_size=kernel_size, stride=1, padding=kernel_size // 2,
dilation=1, groups=dim, bias=True,
attempt_use_lk_impl=attempt_use_lk_impl)
self.norm = nn.Identity()
elif kernel_size >= 7:
self.dwconv = DilatedReparamBlock(dim, kernel_size, deploy=deploy,
use_sync_bn=use_sync_bn,
attempt_use_lk_impl=attempt_use_lk_impl)
self.norm = get_bn(dim, use_sync_bn=use_sync_bn)
elif kernel_size == 1:
self.dwconv = nn.Conv2d(dim, dim, kernel_size=kernel_size, stride=1, padding=kernel_size // 2,
dilation=1, groups=1, bias=deploy)
self.norm = get_bn(dim, use_sync_bn=use_sync_bn)
else:
assert kernel_size in [3, 5]
self.dwconv = nn.Conv2d(dim, dim, kernel_size=kernel_size, stride=1, padding=kernel_size // 2,
dilation=1, groups=dim, bias=deploy)
self.norm = get_bn(dim, use_sync_bn=use_sync_bn)
self.se = SEBlock(dim, dim // 4)
ffn_dim = int(ffn_factor * dim)
self.pwconv1 = nn.Sequential(
NCHWtoNHWC(),
nn.Linear(dim, ffn_dim))
self.act = nn.Sequential(
nn.GELU(),
GRNwithNHWC(ffn_dim, use_bias=not deploy))
if deploy:
self.pwconv2 = nn.Sequential(
nn.Linear(ffn_dim, dim),
NHWCtoNCHW())
else:
self.pwconv2 = nn.Sequential(
nn.Linear(ffn_dim, dim, bias=False),
NHWCtoNCHW(),
get_bn(dim, use_sync_bn=use_sync_bn))
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones(dim),
requires_grad=True) if (not deploy) and layer_scale_init_value is not None \
and layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, inputs):
def _f(x):
if self.need_contiguous:
x = x.contiguous()
y = self.se(self.norm(self.dwconv(x)))
y = self.pwconv2(self.act(self.pwconv1(y)))
if self.gamma is not None:
y = self.gamma.view(1, -1, 1, 1) * y
return self.drop_path(y) + x
if self.with_cp and inputs.requires_grad:
return checkpoint.checkpoint(_f, inputs)
else:
return _f(inputs)
def switch_to_deploy(self):
if hasattr(self.dwconv, 'switch_to_deploy'):
self.dwconv.switch_to_deploy()
if hasattr(self.norm, 'running_var') and hasattr(self.dwconv, 'lk_origin'):
std = (self.norm.running_var + self.norm.eps).sqrt()
self.dwconv.lk_origin.weight.data *= (self.norm.weight / std).view(-1, 1, 1, 1)
self.dwconv.lk_origin.bias.data = self.norm.bias + (self.dwconv.lk_origin.bias - self.norm.running_mean) * self.norm.weight / std
self.norm = nn.Identity()
if self.gamma is not None:
final_scale = self.gamma.data
self.gamma = None
else:
final_scale = 1
if self.act[1].use_bias and len(self.pwconv2) == 3:
grn_bias = self.act[1].beta.data
self.act[1].__delattr__('beta')
self.act[1].use_bias = False
linear = self.pwconv2[0]
grn_bias_projected_bias = (linear.weight.data @ grn_bias.view(-1, 1)).squeeze()
bn = self.pwconv2[2]
std = (bn.running_var + bn.eps).sqrt()
new_linear = nn.Linear(linear.in_features, linear.out_features, bias=True)
new_linear.weight.data = linear.weight * (bn.weight / std * final_scale).view(-1, 1)
linear_bias = 0 if linear.bias is None else linear.bias.data
linear_bias += grn_bias_projected_bias
new_linear.bias.data = (bn.bias + (linear_bias - bn.running_mean) * bn.weight / std) * final_scale
self.pwconv2 = nn.Sequential(new_linear, self.pwconv2[1])
class C3_UniRepLKNetBlock(C3):
def __init__(self, c1, c2, n=1, k=7, shortcut=False, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
self.m = nn.Sequential(*(UniRepLKNetBlock(c_, k) for _ in range(n)))
class Bottleneck_DRB(Bottleneck):
"""Standard bottleneck with DilatedReparamBlock."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, groups, kernels, expand
super().__init__(c1, c2, shortcut, g, k, e)
c_ = int(c2 * e) # hidden channels
self.cv2 = DilatedReparamBlock(c2, 7)
class C3_DRB(C3):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
self.m = nn.Sequential(*(Bottleneck_DRB(c_, c_, shortcut, g, k=(1, 3), e=1.0) for _ in range(n)))在处理图像时,Dilated Reparam Block(DRB)的主流程包括以下几个关键步骤:
-
输入图像处理:输入的图像首先通过一个大的卷积核(large kernel convolution)来提取初步的特征。这种大卷积核有助于捕捉到更大范围的上下文信息。
-
扩张卷积操作:然后,图像特征被送入多个并行的扩张卷积层(dilated convolutions)。这些卷积层的扩张率不同,目的是在保持计算效率的同时扩大感受野,从而提取多尺度的特征信息。
-
特征融合:扩张卷积层的输出与初始的大卷积核输出进行融合。这种融合的目的是结合多尺度特征,增强模型对各种空间结构的感知能力。
-
结构重参数化:在训练过程中,这些并行的卷积层是独立存在的。然而,在推理阶段,通过结构重参数化技术,这些并行卷积层被合并为一个等效的大核卷积层,从而简化模型结构,减少推理时的计算负担。
-
输出特征图:最终处理后的特征图被送入后续的网络层或任务特定的头部(如分类、分割等),以执行特定的视觉任务。
这种流程使得DRB在保持模型复杂特征捕捉能力的同时,能够高效地处理大规模图像数据 。

2.2 新增yaml文件
关键步骤二:在下/yolov5/models下新建文件 yolov5_C3_DRB.yaml并将下面代码复制进去
- 目标检测yaml文件
# Ultralytics YOLOv5 🚀, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10, 13, 16, 30, 33, 23] # P3/8
- [30, 61, 62, 45, 59, 119] # P4/16
- [116, 90, 156, 198, 373, 326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3_DRB, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3_DRB, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3_DRB, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3_DRB, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head: [
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
- 语义分割yaml文件
# Ultralytics YOLOv5 🚀, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10, 13, 16, 30, 33, 23] # P3/8
- [30, 61, 62, 45, 59, 119] # P4/16
- [116, 90, 156, 198, 373, 326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3_DRB, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3_DRB, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3_DRB, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3_DRB, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head: [
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Segment, [nc, anchors, 32, 256]], # Detect(P3, P4, P5)
]
温馨提示:本文只是对yolov5基础上添加模块,如果要对yolov5n/l/m/x进行添加则只需要指定对应的depth_multiple 和 width_multiple。
# YOLOv5n
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
# YOLOv5s
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# YOLOv5l
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# YOLOv5m
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
# YOLOv5x
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple2.3 注册模块
关键步骤三:在yolo.py的parse_model函数替换添加C3_DRB

2.4 执行程序
在train.py中,将cfg的参数路径设置为yolov5_C3_DRB.yaml的路径
建议大家写绝对路径,确保一定能找到

🚀运行程序,如果出现下面的内容则说明添加成功🚀
from n params module arguments
0 -1 1 7040 models.common.Conv [3, 64, 6, 2, 2]
1 -1 1 73984 models.common.Conv [64, 128, 3, 2]
2 -1 3 65152 models.common.C3_DRB [128, 128, 3]
3 -1 1 295424 models.common.Conv [128, 256, 3, 2]
4 -1 6 308736 models.common.C3_DRB [256, 256, 6]
5 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
6 -1 9 1351168 models.common.C3_DRB [512, 512, 9]
7 -1 1 4720640 models.common.Conv [512, 1024, 3, 2]
8 -1 3 3044352 models.common.C3_DRB [1024, 1024, 3]
9 -1 1 2624512 models.common.SPPF [1024, 1024, 5]
10 -1 1 525312 models.common.Conv [1024, 512, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 3 2757632 models.common.C3 [1024, 512, 3, False]
14 -1 1 131584 models.common.Conv [512, 256, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 3 690688 models.common.C3 [512, 256, 3, False]
18 -1 1 590336 models.common.Conv [256, 256, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 3 2495488 models.common.C3 [512, 512, 3, False]
21 -1 1 2360320 models.common.Conv [512, 512, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 3 9971712 models.common.C3 [1024, 1024, 3, False]
24 [17, 20, 23] 1 457725 Detect [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [256, 512, 1024]]
YOLOv5_C3_DRB summary: 494 layers, 33652477 parameters, 33652477 gradients, 72.9 GFLOPs3. 完整代码分享
https://pan.baidu.com/s/1c1n-AlVgfNsf2NbsVNRJQw?pwd=pyxs提取码: pyxs
4. GFLOPs
关于GFLOPs的计算方式可以查看:百面算法工程师 | 卷积基础知识——Convolution
未改进的GFLOPs
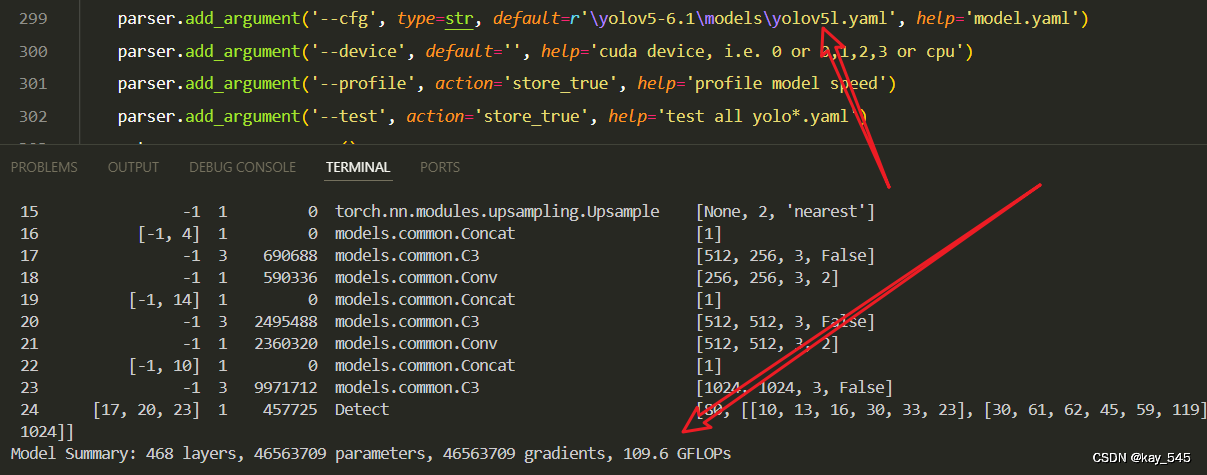
改进后的GFLOPs

5. 进阶
可以结合损失函数或者卷积模块进行多重改进
YOLOv5改进 | 损失函数 | EIoU、SIoU、WIoU、DIoU、FocuSIoU等多种损失函数——点击即可跳转
6. 总结
Dilated Reparam Block(DRB)的主要原理是在大核卷积层的基础上,通过并行的小核卷积层(具有不同的扩张率)来增强模型的感受野和特征捕捉能力。这些扩张卷积层能够捕捉到数据中的稀疏模式,涵盖更广泛的空间范围,同时不显著增加参数数量。训练时,大核卷积和并行的小核扩张卷积的输出会被组合起来。通过结构重参数化技术,训练结束后这些并行卷积层会被合并为一个单一的大核卷积层,以降低推理时的计算成本。为了实现这一点,扩张卷积会通过插入零条目转换为一个等效的、具有稀疏大核的非扩张卷积层。这种设计在保持强大感受野的同时,确保了卷积操作的计算效率,使得网络能够高效地提取复杂的空间模式,从而在多个任务中提升性能。












![[Linux#44][线程] CP模型2.0 | 信号量接口 | 基于环形队列](https://img-blog.csdnimg.cn/img_convert/ab5df940328dad56696d2d86fff6d43f.jpeg)