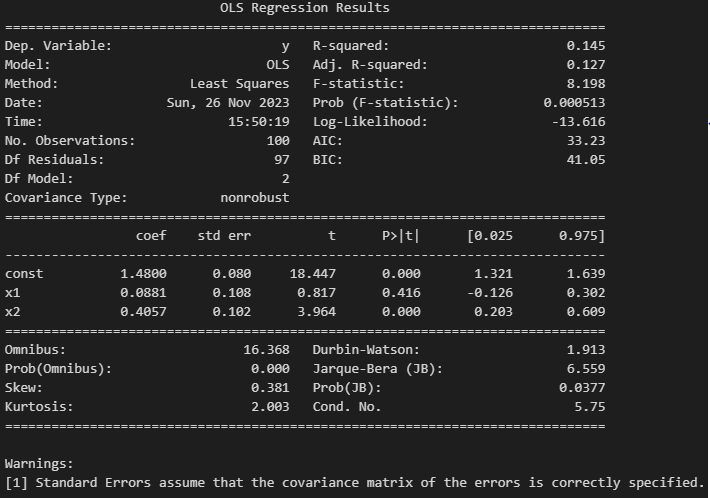
1、需求
老项目,实时数据还是用mysql去存储的,而且又没有定时去清理数据的程序。目前这些实时数据只需保留近半年的即可。

其他几张实时表数据量没有这么夸张。
我随即用
delete from table_name where id < 39000000 limit 10000但是几亿条记录用这个方法太慢了。
2、方案
虽然之前也处理过类似问题,但还是随手问了一下AI,有无更优解。
在MySQL中删除一个大表(例如含有几亿条记录)中的数据时,需要特别注意操作的性能和对系统的影响。如果您的目标是删除半年前的数据,您可以采用以下几种策略来高效地完成这项任务:
1. 使用 DELETE 语句分批删除
一种常见的方法是使用 DELETE 语句,并通过分批删除数据来减轻数据库的压力。这可以通过在 DELETE 语句中添加 LIMIT 子句来实现。
示例 SQL 语句
1-- 定义每批删除的数量
2SET @batch_size = 100000; -- 每次删除 10 万条记录
3SET @counter = 0;
4
5-- 确定半年前的日期
6SET @six_months_ago = DATE_SUB(CURDATE(), INTERVAL 6 MONTH);
7
8-- 分批删除数据
9REPEAT
10 DELETE FROM your_table
11 WHERE time < @six_months_ago
12 LIMIT @batch_size;
13 SET @counter = @counter + 1;
14UNTIL @counter = 0 END REPEAT;2. 使用 INPLACE ALTER TABLE
对于InnoDB表,可以使用 ALTER TABLE 来删除数据,这通常比 DELETE 更快。然而,此方法要求您能够确定删除的行不会被引用(例如通过外键)。此外,这种方法可能不是所有版本的MySQL都支持。
示例 SQL 语句
1-- 确定半年前的日期
2SET @six_months_ago = DATE_SUB(CURDATE(), INTERVAL 6 MONTH);
3
4-- 创建一个临时表,只包含需要保留的数据
5CREATE TABLE temp_table AS SELECT * FROM your_table WHERE time >= @six_months_ago;
6
7-- 删除原始表
8DROP TABLE your_table;
9
10-- 重命名临时表为原始表的名字
11RENAME TABLE temp_table TO your_table;3. 使用 TRUNCATE TABLE 和重新插入数据
如果您可以接受删除所有数据并重新插入数据,那么可以使用 TRUNCATE TABLE 来清空整个表,然后只插入最近六个月的数据。这种方法适用于那些可以承受完全清空表的场景。
1-- 确定半年前的日期
2SET @six_months_ago = DATE_SUB(CURDATE(), INTERVAL 6 MONTH);
3
4-- 清空表
5TRUNCATE TABLE your_table;
6
7-- 重新插入最近六个月的数据
8INSERT INTO your_table
9SELECT * FROM your_table
10WHERE time >= @six_months_ago;注意事项
- 备份数据:在执行任何大规模删除操作之前,一定要做好数据备份以防万一。
- 监控性能:在执行删除操作时,应密切监控MySQL服务器的性能指标,如CPU使用率、磁盘I/O等。
- 禁用外键检查:如果表上有外键约束,可以暂时禁用外键检查。
- 禁用自动提交:在开始删除操作之前,可以关闭自动提交,然后在删除完成后手动提交事务。
示例 SQL 脚本
以下是一个完整的SQL脚本示例,使用分批删除的方式删除半年前的数据:
1-- 设置变量
2SET @batch_size = 100000; -- 每次删除 10 万条记录
3SET @counter = 0;
4
5-- 确定半年前的日期
6SET @six_months_ago = DATE_SUB(CURDATE(), INTERVAL 6 MONTH);
7
8-- 分批删除数据
9REPEAT
10 DELETE FROM your_table
11 WHERE time < @six_months_ago
12 LIMIT @batch_size;
13 SET @counter = @counter + 1;
14UNTIL @counter = 0 END REPEAT;总结
选择哪种方法取决于您的具体需求和资源。如果数据量非常大,建议先在一个较小的数据集上测试所选方法的性能,然后再应用到整个表。此外,在执行此类操作时,最好在业务低峰期进行,以减少对应用程序的影响。
看来也没有更好的办法,还是这些老办法。
3、实战
先新建一张copy的表。
注意:新建表的自增索引ID,还是会从1开始的。
CREATE TABLE new_table_name LIKE existing_table_name;接下来二个方案
1、实时数据不能停的,先改名,把名称互换。等数据插入一波,再启动迁移。主要是为了插入一波后自增索引自动调整。避免冲突
RENAME TABLE temp TO users;2、实时数据能停的,那么就先停掉。再名称互换,再改动自增索引起点值。这时候其实可以开启插入程序了。
3.1转移
一张表近半年的数据是从390000000差不多开始。那么就好处理了

几千万条数据也是比较快的。
另一张表更大,有近1-2个亿的数据,那么我是2kw-3kw 批量一次,也就半小时。即可完成。










![[ACL 2024] Revisiting Knowledge Distillation for Autoregressive Language Models](https://i-blog.csdnimg.cn/direct/4da5c1c555904ab9835e9150bf61edb2.png#pic_center)