第四篇 AI概念及理论知识
文章目录
- 第四篇 AI概念及理论知识
- 1.人工智能与机器学习
- 1.1 机器学习
- 1.2 模型和拟合
- 1.3 线性回归模型
- 1.3.1 实现简单线性回归
- 1.3.2 简单线性回归代码解析
- 1.3.3 Sklearn实现房价预测模型
- 1.3.4 Sklearn房价预测代码解析
- 2.深度学习及神经网络
- 2.1 深度学习
- 2.1.1 人工神经元
- 2.1.2 激活函数
- 2.1.3 实现人工神经元模型
- 2.2 感知机
- 2.2.1 感知机模型
- 2.2.2 鸢尾花二分类问题
- 2.2.3 实现感知机模型
- 2.3 多层神经网络
- 2.3.1 XOR问题
- 2.3.2 多层网络组成
- 2.4 参数的传播方向
- 2.5 前向传播和反向传播
- 2.6 损失函数
- 3.深度学习框架Pytorch入门
- 3.1 深度学习框架简介
- 3.2 深度学习框架-pytorch
- 3.3 求解服饰图像多分类问题
- 3.3.1 多分类问题介绍
- 3.3.2 程序流程框图
- 3.3.3 程序源码解析
- 4.基础算子及卷积神经网络
- 4.1 基础算子
- 4.2 卷积神经网络
- 4.3 卷积算子
- 4.3.1 为什么需要卷积?
- 4.3.2 图像卷积
- 4.3.3 卷积与互相关
- 4.3.4 卷积处理图像
- 4.3.5 卷积提取图像特征
- 4.3.6 一维卷积和二维卷积
- 4.4 池化层
- 4.4.1 最大池化与均值池化
- 4.4.2 卷积网络中的最大池化
- 4.5 RELU 激励层
- 4.5.1 线性整流激活函数
- 4.5.2 卷积网络中的RELU层
- 4.6 全连接层
- 4.6.1 全连接层核心公式
- 4.6.2 卷积网络中的全连接层
- 4.6.3 分布式特征映射
- 4.7 训练与超参数
- 5.模型及部署
- 5.1 模型
- 5.2 模型的部署
- 6.边缘部署
- 6.1 部署硬件GPU/FPGA/ASIC
- 6.1.1 图形处理单元GPU
- 6.1.2 现场可编程门阵列FPGA
- 6.1.3 专用集成电路ASIC
- 6.2 嵌入式模型部署
- 6.3 嵌入式AI芯片
- 6.4 边缘部署流程
- 6.4.1 模型转换
- 6.4.2 量化压缩
- 6.4.3 打包封装
- 6.4.4 端侧推理
1.人工智能与机器学习
人工智能是研究开发用于模拟和扩展人的智能的理论、方法、技术及应用系统的一门技术科学。
机器学习是基于大量数据而成,让计算机像人类一样学习和行动的科学,通过以观察和现实世界互动的形式向他们提供数据和信息,以自主的方式改善他们的学习。机器学习包括深度学习、强化学习、传统机器学习等。

深度学习是模拟人脑所构成的,支持从大量数据中学习,学习这些样本数据中的内在规律和表示层次。
强化学习是构建一个智能体,在一个复杂的环境下去最大可能获得奖励,通过感知环境所处的状态对动作的反应来指导获取更好的动作,从而获得最大的收益。
传统机器学习是从一些观测(训练)样本出发,使用统计学、线性代数、优化算法等数学方法,从已有数据中学习并构建预测模型,进而用于对未知数据的预测和分类。
1.1 机器学习
那么如何达到我们定义中像人类学习和行动呢,下面以一个线性回归的例子讲解什么是机器学习。
在X-Y坐标上给定一些样点值,求解一条直线,求该直线可以表示样点值的趋势。这是最基础的线性回归问题,回归分析中,只用一个自变量和一个因变量,且两者的关系可以用一条直线近似表示。

该直线可以看成y=ax函数,其中a代表直线的斜率。如果是依靠我们大致绘制的直线,并测量其a,这样只需要提供x值即可推测出y值。
但这仅局限于数量很少的样点,如果大量的样点数据,依靠人脑是绘制的趋势直线是不准确的。
假设我们设计一个程序求解样点的趋势线,先定义趋势线公式为y=ax,然后如下操作:
-
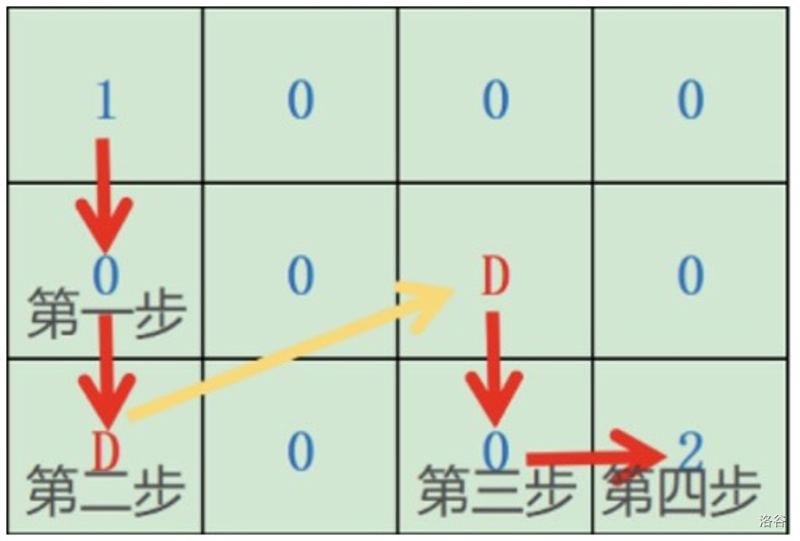
先随机选取a的值,将样本点的x值代入求出y’值,差值e=(y’-y)^2。如此计算所有样本点的差值,所有差值相加得到总误差E_1 。
-
再将a的值增大或减小:a = a + delta,这个增大或减小的区间值称为步长值。重新计算总误差E_2。
-
对比 E_1和E_2 的值,如果 E_2小于 E_1 ,则代表总误差减小,步长方向正确。如果 E_2大于 E_1 ,则代表总误差增大,步长方向错误,需要修改步长方向: delta = - delta。
-
从步骤2继续循环,直到误差变化不再降低为止。
在这个循环过程中,如果误差比较大,可以加大delta值以减少循环次数;如果误差已经比较小了,可以减小delta值以提高精度。

例如:假设a_1=a_0+步长值,再将所有的样本点重新计算得出新的误差 E_2。对比 E_1和E_2 的值,如果 E_2小于 E_1 ,则代表总误差减小,步长方向正确。如果 E_2大于 E_1 ,则代表总误差增大,步长方向错误,需要修改步长方向。

例如:假设原来的步长值为-0.6,在下次迭代时将 ,
a
2
=
a
1
+
1
=
a
0
−
0.6
+
1
=
a
0
+
0.4
a_2=a_1+1 = a_0-0.6+1=a_0+0.4
a2=a1+1=a0−0.6+1=a0+0.4
此时步长值=+1 ,使原始的a值增加,然后继续迭代。如果在新迭代后,总误差E值降低了,则证明步长方向修改正确。再按照一定的步长与刚刚a值的方向迭代下去,直到总误差值E不再降低为止,此时得到的a就是对所以已知样本点的最佳拟合函数f(x)=ax的参数。

根据误差的变化趋势决定参数的调整方向,力度(误差越大步长值越大,反之则越小)从而获取最低误差的方式就被称为梯度下降法。
**问:**为什么叫做梯度下降法呢?
**答:**我们在线性回归模型中我们需要根据误差来确定步长的调整,计算的方式是均方误差函数(损失函数),公式为:
C
o
s
t
损失函数
:
∑
i
=
1
n
(
y
‘
−
y
i
)
2
n
或者
∑
i
=
1
n
(
y
‘
−
y
i
)
2
2
n
Cost损失函数:\frac{\sum_{i=1}^n (y^`- y^i)^2}{n} 或者\frac{\sum_{i=1}^n (y^`- y^i)^2}{2n}
Cost损失函数:n∑i=1n(y‘−yi)2或者2n∑i=1n(y‘−yi)2
那么我们肯定是想计算出该均方误差公式的最小值,那么想要求得函数最小值,在数学方法中,我们就会想到求导,并求二阶偏导函数的驻点。下面展示均方误差函数J(w)求偏导后的结果:
∂
J
(
w
)
∂
w
=
[
∑
i
=
1
n
(
y
‘
−
y
i
)
2
2
n
]
′
=
∑
i
=
1
n
(
w
x
i
−
y
i
)
n
x
i
\frac{\partial J(w)}{\partial w}=[\frac{\sum_{i=1}^n (y^`- y^i)^2}{2n}]'\\ =\frac{\sum_{i=1}^n (wx^i - y^i)}{n}x^i
∂w∂J(w)=[2n∑i=1n(y‘−yi)2]′=n∑i=1n(wxi−yi)xi
权重w的迭代过程是以负梯度的方向(减少误差的方向)来决定每次迭代时权重w的变化方向,从而使每次迭代后目标函数(误差函数)的值逐渐减小。
w
=
w
−
α
∗
∂
J
(
w
)
∂
w
其中
α
为学习率,
∂
J
(
w
)
∂
w
为误差函数的偏导数
w=w-\alpha *\frac{\partial J(w)}{\partial w}\\ 其中\alpha为学习率,\frac{\partial J(w)}{\partial w}为误差函数的偏导数
w=w−α∗∂w∂J(w)其中α为学习率,∂w∂J(w)为误差函数的偏导数
每次迭代都会修改权重w值,使其以α学习速率沿着偏导数的反方向进行移动。
均方误差函数是一个二次函数。它实际的函数图像可能是如图所示的一个抛物线。图中的损失值Cost就是误差值。假设我们在初始a值的点时,我们的损失值很大,我们想要降低损失值,需要沿着函数的梯度方向(函数的方向)往下走,直到找到损失值的最低点(即找到最低的误差值)。

如果是计算大量样本点的时候,可以知道整个迭代过程中运算量是很大,计算机需要不断的在大量样本点中运算、分析、试错、调整、重新计算,这个过程称为训练。线性回归求解训练过程如图所示:

如图所示的回归分析中,训练的目的就是在大量样本点中找出描述样本点之间规律的函数的参数。上述基本线性模型的整个过程称为机器学习。
1.2 模型和拟合
通过前面的线性回归学习我们知道,建立的模型需要与数据集对应,简单的数据集需要对应简单的模型,复杂的数据集需要对应复杂的模型。以求回归问题为例,求下面两个数据集的回归线:

通过观察上面两个数据集可以发现,我们可以发现样本数据集1可以通过建立简单的y=ax+b的线性模型求得该样本的回归线;样本数据集2数据集较为复杂,如果直接使用简单的y=ax+b的线性模型,无法拟合出样本数据集2的回归线,我们称为不拟合,此时需要建立一个更为复杂的模型,如y=ax^2等,对样本数据集进行回归拟合。

从上图可以看出,模型的复杂度需要和数据集的复杂程序对应,如果复杂数据使用简单模型可能会出现不拟合的情况。

如果机器学习的结果拟合度不够高,结果相差很大,称为不拟合。可以加入高次项。但如果加入了过多的高次幂项,可能会导致正确率不升反降,此现象称为过度拟合。过拟合为得到高精度的拟合结果,而使模型变得过度复杂,导致模型参数不合理、表现力、预测力变差。

1.3 线性回归模型
1.3.1 实现简单线性回归
假设提供一些样本点数据,样本点数据为:[1, 3.5], [2, 4.7], [3, 5.3], [4, 7.1],[5, 9.6],[6, 13.5], [7, 16.2], [8, 19.4],[9, 23.2], [10, 33.8],该样本点在图像中的位置如下图所示:

预先构建一个直线函数y=wx,其中w为权重,不考虑偏置值。使用该直线绘制这样本点的线性回归直线,其中权重更新公式如下所示:
权重更新公式
:
w
=
w
−
α
1
m
×
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
x
j
i
损失函数
:
c
o
s
t
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
2
权重更新公式:w=w-\alpha \frac{1}{m} \times \sum_{i=1}^m (h_\theta(x^i) - y^i)x_j^i\\ 损失函数:cost=\frac{1}{2m} \sum_{i=1}^m (h_\theta(x^i) - y^i)^2
权重更新公式:w=w−αm1×i=1∑m(hθ(xi)−yi)xji损失函数:cost=2m1i=1∑m(hθ(xi)−yi)2
下面基于这些样本点我们来构建一个python程序实现,对样本点进行线性回归预测。下面展示代码的流程框图:

代码流程为:
1. 导入numpy包,该包是数组处理包,提供了处理 n 维数组的工具,即提供矩阵运算能力。
2. 导入matplotlib包,该包可支持Python 的 2D 可视化绘图库,可创建静态、动画和交互式可视化图像。
3. 调用求解权重函数,计算直线函数y=wx中的w值。
1. 判断是否达到迭代次数。
2. 使用权重值w,代入x值计算预测值h
3. 计算预测值h和真实值y的差值
4. 求解梯度值
5. 更新权重值w
6. 计算损失值
7. 当没有达到迭代次数,继续返回步骤2。当达到迭代次数,则返回权重值。
4. 使用新权重值预测数据。
5. 将样本点和回归直线绘制到坐标轴上。
1.3.2 简单线性回归代码解析
导入拓展包,支持矩阵运算和可视化
导入numpy包,该包数组处理包,提供了处理 n 维数组的工具,即提供矩阵运算能力。
导入matplotlib包,该包可支持Python 的 2D 可视化绘图库,可创建静态、动画和交互式可视化图像。
import numpy as np
import matplotlib.pyplot as plt
初始化样本点数据
使用多维数组存储样本点数据,并获得该数组的行数和列数
#样本点数据
x = np.array([[1, 3.5], [2, 4.7], [3, 5.3], [4, 7.1],[5, 9.6],
[6, 13.5], [7, 16.2], [8, 19.4],[9, 23.2], [10, 33.8]])
m, n = np.shape(x) #获得样本点数据的行数和列数 m:行数 10 n:列数 2
print("x样本点数据的行数m和列数n:",m,n)
获得样本点的x值和y值
创建一个10行2列的多维数组,并将其置为0。将每一行的第一列存储样本点数据的x值,存储结果保存在x_data中。
将样本点数据的y值,存储在y_data中。
x_data = np.zeros((m, n)) #新建10行2列矩阵,并将值都置为0
x_data[:, :-1] = x[:, :-1] #获取样本点数据中除最后一列之外的所有行和所有列,即样本点数据中的x
y_data = x[:, -1] #获取样本点数据中所有行和最后一列,-1代表最后一列,即样本点数据中的y
初始化权重值
创建一个权重矩阵,矩阵为[1,0]。
m, n = np.shape(x_data) #获得样本点数据中的x行数和列数 m:行数 10 n:列数 2
theta = np.array([1,0]).reshape(2) #创建一个权重矩阵,初始化权重为[1,0]
定义权重函数
由于我们定义的直线的函数为y=wx,其中w为权重。该函数主要用于求解权重w值,其中实现了权重更新公式和损失函数,如下所示的两个公式:
权重更新公式
:
w
=
w
−
α
1
m
×
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
x
j
i
损失函数
:
c
o
s
t
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
2
权重更新公式:w=w-\alpha \frac{1}{m} \times \sum_{i=1}^m (h_\theta(x^i) - y^i)x_j^i\\ 损失函数:cost=\frac{1}{2m} \sum_{i=1}^m (h_\theta(x^i) - y^i)^2
权重更新公式:w=w−αm1×i=1∑m(hθ(xi)−yi)xji损失函数:cost=2m1i=1∑m(hθ(xi)−yi)2
#求解权重函数
#iter:迭代次数 x:横坐标 y:纵坐标 w:权重 alpha:学习率
def gradientDescent(iter, x, y, w, alpha):
x_train = x.transpose() #交换矩阵的两个维度
for i in range(0, iter):
pre = np.dot(x, w) #矩阵乘法
loss = (pre - y) #预测值和真实值的差值
#权重更新公式
gradient = np.dot(x_train, loss) / m #求解梯度
w = w - alpha * gradient #更新权重
#使用损失函数求解损失值
cost = (1.0 / (2 * m)) * np.sum(np.square((np.dot(x, w)) - y))
print("第{}次梯度下降损失值为: {}".format(i,round(cost,2)))
return w
1.交换矩阵的两个维度
x_train = x.transpose()
∣ 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 10 0 ∣ 交换矩阵的两个维度,转置矩阵结果为 ∣ 1 2 3 4 5 6 7 8 9 10 0 0 0 0 0 0 0 0 0 0 ∣ \left|\begin{matrix} 1 & 0\\ 2 & 0\\ 3 & 0\\ 4 & 0\\ 5 & 0\\ 6 & 0\\ 7 & 0\\ 8 & 0\\ 9 & 0\\ 10 & 0\\ \end{matrix} \right| 交换矩阵的两个维度,转置矩阵结果为\left|\begin{matrix} 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 & 10\\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ \end{matrix} \right| 123456789100000000000 交换矩阵的两个维度,转置矩阵结果为 102030405060708090100
2.计算预测值
pre = np.dot(x, w) #矩阵乘法
假设是第一次进行计算,那么x为样本点的x值,w权重为[1,1],计算方式为:
∣
1
0
2
0
3
0
4
0
5
0
6
0
7
0
8
0
9
0
10
0
∣
∗
∣
1
0
∣
=
∣
1
2
3
4
5
6
7
8
9
10
∣
\left|\begin{matrix} 1 & 0\\ 2 & 0\\ 3 & 0\\ 4 & 0\\ 5 & 0\\ 6 & 0\\ 7 & 0\\ 8 & 0\\ 9 & 0\\ 10 & 0\\ \end{matrix} \right|*\left|\begin{matrix} 1\\ 0 \end{matrix} \right|=\left|\begin{matrix} 1\\ 2\\ 3\\ 4\\ 5\\ 6\\ 7\\ 8\\ 9\\ 10\\ \end{matrix} \right|
123456789100000000000
∗
10
=
12345678910
3.计算差值
差值等于预测值减真实值,计算权重更新公式中的h(x)-y部分。公式如下所示:
权重更新公式
:
w
=
w
−
α
1
m
×
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
x
j
i
l
o
s
s
=
(
h
θ
(
x
i
)
−
y
i
)
权重更新公式:w=w-\alpha \frac{1}{m} \times \sum_{i=1}^m (h_\theta(x^i) - y^i)x_j^i \\ loss = (h_\theta(x^i) - y^i)
权重更新公式:w=w−αm1×i=1∑m(hθ(xi)−yi)xjiloss=(hθ(xi)−yi)
loss = (pre - y) #预测值和真实值的差值
计算过程如下所示:
l
o
s
s
=
∣
1
2
3
4
5
6
7
8
9
10
∣
−
∣
3.5
4.7
5.3
7.1
9.6
13.5
16.2
19.4
23.2
33.8
∣
=
∣
−
2.5
−
2.7
−
2.3
−
3.1
−
4.6
−
7.5
−
9.2
−
11.4
−
14.2
−
23.8
∣
loss=\left|\begin{matrix} 1\\ 2\\ 3\\ 4\\ 5\\ 6\\ 7\\ 8\\ 9\\ 10\\ \end{matrix} \right|- \left|\begin{matrix} 3.5\\ 4.7\\ 5.3\\ 7.1\\ 9.6\\ 13.5\\ 16.2\\ 19.4\\ 23.2\\ 33.8\\ \end{matrix} \right|= \left|\begin{matrix} -2.5\\ -2.7\\ -2.3\\ -3.1\\ -4.6\\ -7.5\\ -9.2\\ -11.4\\ -14.2\\ -23.8\\ \end{matrix} \right|
loss=
12345678910
−
3.54.75.37.19.613.516.219.423.233.8
=
−2.5−2.7−2.3−3.1−4.6−7.5−9.2−11.4−14.2−23.8
4.权重更新
计算梯度值,即将差值 乘 样本点的x值,再除以样本点的个数,公式如下所示:
权重更新公式
:
w
=
w
−
α
1
m
×
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
x
j
i
梯度值:
g
r
a
d
i
e
n
t
=
1
m
×
l
o
s
s
⋅
x
j
i
权重更新公式:w=w-\alpha \frac{1}{m} \times \sum_{i=1}^m (h_\theta(x^i) - y^i)x_j^i \\ 梯度值:gradient=\frac{1}{m} \times loss \cdot x_j^i
权重更新公式:w=w−αm1×i=1∑m(hθ(xi)−yi)xji梯度值:gradient=m1×loss⋅xji
gradient = np.dot(x_train, loss) / m #求解梯度
计算过程如下所示:
g
r
a
d
i
e
n
t
=
∣
1
2
3
4
5
6
7
8
9
10
0
0
0
0
0
0
0
0
0
0
∣
∗
∣
−
2.5
−
2.7
−
2.3
−
3.1
−
4.6
−
7.5
−
9.2
−
11.4
−
14.2
−
23.8
∣
÷
10
=
∣
−
616.6
0
∣
÷
10
=
∣
−
61.66
0
∣
gradient =\left|\begin{matrix} 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 & 10\\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ \end{matrix} \right|*\left|\begin{matrix} -2.5\\ -2.7\\ -2.3\\ -3.1\\ -4.6\\ -7.5\\ -9.2\\ -11.4\\ -14.2\\ -23.8\\ \end{matrix} \right| \div 10 = \left|\begin{matrix} -616.6\\ 0\\ \end{matrix} \right| \div 10=\left|\begin{matrix} -61.66\\ 0\\ \end{matrix} \right|
gradient=
102030405060708090100
∗
−2.5−2.7−2.3−3.1−4.6−7.5−9.2−11.4−14.2−23.8
÷10=
−616.60
÷10=
−61.660
计算新权重
新权重 等于 原权重 减 梯度值 乘 学习率,计算公式如下图所示:
权重更新公式
:
w
=
w
−
α
1
m
×
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
x
j
i
权重计算公式:
w
=
w
−
α
×
g
r
a
d
i
e
n
t
权重更新公式:w=w-\alpha \frac{1}{m} \times \sum_{i=1}^m (h_\theta(x^i) - y^i)x_j^i \\ 权重计算公式:w = w - \alpha \times gradient
权重更新公式:w=w−αm1×i=1∑m(hθ(xi)−yi)xji权重计算公式:w=w−α×gradient
w = w - alpha * gradient #更新权重
计算过程如下所示:
w
=
∣
1
0
∣
−
0.01
⋅
∣
−
61.66
0
∣
=
∣
1.6166
0
∣
w=\left|\begin{matrix} 1\\ 0\\ \end{matrix} \right| - 0.01\cdot \left|\begin{matrix} -61.66\\ 0\\ \end{matrix} \right| = \left|\begin{matrix} 1.6166\\ 0\\ \end{matrix} \right|
w=
10
−0.01⋅
−61.660
=
1.61660
5.计算损失值
损失函数公式为:
损失函数
:
c
o
s
t
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
2
损失函数:cost=\frac{1}{2m} \sum_{i=1}^m (h_\theta(x^i) - y^i)^2
损失函数:cost=2m1i=1∑m(hθ(xi)−yi)2
cost = (1.0 / (2 * m)) * np.sum(np.square((np.dot(x, w)) - y))
这段程序直接完整实现了损失函数,程序较为复杂,我们直接把该程序从里到外拆开来看。
从括号最里层来看:
np.dot(x, w)
该程序作用是将权重与样本点的x值 相乘 求得预测值。代码实现公式部分为:
h
θ
(
x
i
)
=
∣
1
0
2
0
3
0
4
0
5
0
6
0
7
0
8
0
9
0
10
0
∣
∗
∣
1.6166
0
∣
=
∣
1.6166
3.2332
4.8498
6.4664
8.083
9.6996
11.3162
12.9328
14.5494
16.166
∣
h_\theta(x^i) =\left|\begin{matrix} 1 & 0\\ 2 & 0\\ 3 & 0\\ 4 & 0\\ 5 & 0\\ 6 & 0\\ 7 & 0\\ 8 & 0\\ 9 & 0\\ 10 & 0\\ \end{matrix} \right|* \left|\begin{matrix} 1.6166\\ 0\\ \end{matrix} \right| = \left|\begin{matrix} 1.6166 \\ 3.2332 \\ 4.8498 \\ 6.4664 \\ 8.083 \\ 9.6996 \\ 11.3162 \\ 12.9328 \\ 14.5494 \\ 16. 166\\ \end{matrix} \right|
hθ(xi)=
123456789100000000000
∗
1.61660
=
1.61663.23324.84986.46648.0839.699611.316212.932814.549416.166
(np.dot(x, w)) - y)
该程序作用是求预测值和真实值的差值。代码实现公式部分为:
(
h
θ
(
x
i
)
−
y
i
)
=
∣
1.6166
3.2332
4.8498
6.4664
8.083
9.6996
11.3162
12.9328
14.5494
16.166
∣
−
∣
3.5
4.7
5.3
7.1
9.6
13.5
16.2
19.4
23.2
33.8
∣
=
∣
−
1.8834
−
1.4668
−
0.4502
−
0.6336
−
1.517
−
3.8004
−
4.8838
−
6.4672
−
8.6506
−
17.634
∣
(h_\theta(x^i) - y^i) = \left|\begin{matrix} 1.6166 \\ 3.2332 \\ 4.8498 \\ 6.4664 \\ 8.083 \\ 9.6996 \\ 11.3162 \\ 12.9328 \\ 14.5494 \\ 16. 166\\ \end{matrix} \right|-\left|\begin{matrix} 3.5\\ 4.7\\ 5.3\\ 7.1\\ 9.6\\ 13.5\\ 16.2\\ 19.4\\ 23.2\\ 33.8\\ \end{matrix} \right|= \left|\begin{matrix} -1.8834 \\-1.4668 \\ -0.4502 \\ -0.6336 \\-1.517\\ -3.8004\\ -4.8838 \\ -6.4672\\ -8.6506 \\-17.634 \end{matrix} \right|
(hθ(xi)−yi)=
1.61663.23324.84986.46648.0839.699611.316212.932814.549416.166
−
3.54.75.37.19.613.516.219.423.233.8
=
−1.8834−1.4668−0.4502−0.6336−1.517−3.8004−4.8838−6.4672−8.6506−17.634
np.square((np.dot(x, w)) - y)
该程序作用是针对差值进行求平方的操作。代码实现公式部分为:
(
h
θ
(
x
i
)
−
y
i
)
2
=
∣
−
1.8834
−
1.4668
−
0.4502
−
0.6336
−
1.517
−
3.8004
−
4.8838
−
6.4672
−
8.6506
−
17.634
∣
2
=
∣
3.54719556
2.15150224
0.20268004
0.40144896
2.30128900
14.4430402
23.85150244
41.8246758
74.8328804
310.957956
∣
(h_\theta(x^i) - y^i)^2 =\left|\begin{matrix} -1.8834 \\-1.4668 \\ -0.4502 \\ -0.6336 \\-1.517\\ -3.8004\\ -4.8838 \\ -6.4672\\ -8.6506 \\-17.634 \end{matrix} \right|^2 =\left|\begin{matrix} 3.54719556 \\ 2.15150224 \\0 .20268004 \\0.40144896\\ 2.30128900 \\14.4430402\\ 23.85150244 \\41.8246758\\ 74.8328804 \\310.957956\end{matrix} \right|
(hθ(xi)−yi)2=
−1.8834−1.4668−0.4502−0.6336−1.517−3.8004−4.8838−6.4672−8.6506−17.634
2=
3.547195562.151502240.202680040.401448962.3012890014.443040223.8515024441.824675874.8328804310.957956
np.sum(np.square((np.dot(x, w)) - y))
3.54719556 + 2.15150224 + 0.20268004 + 0.40144896 + 2.30128900 + 14.4430402 + 23.85150244 + 41.8246758 + 74.8328804 + 310.957956 = 474.514170 3.54719556 + 2.15150224 + 0.20268004 +0.40144896+\\ 2.30128900 +14.4430402+ 23.85150244 +41.8246758+ 74.8328804 +310.957956 =474.514170 3.54719556+2.15150224+0.20268004+0.40144896+2.30128900+14.4430402+23.85150244+41.8246758+74.8328804+310.957956=474.514170
该程序作用是将括号内的矩阵元素进行求和,即将矩阵中的每一个元素进行相加求和,最终得到一个数。
(1.0 / (2 * m)) * np.sum(np.square((np.dot(x, w)) - y))
该程序主要实现公式前面的1/2m与后面的计算出来的数进行相乘,代码实现公式部分为:
1
2
m
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
2
=
1
2
∗
10
∗
474.514170
=
1
20
∗
474.514170
=
23.7257085
\frac{1}{2m} \sum_{i=1}^m (h_\theta(x^i) - y^i)^2 =\frac{1}{2*10}*474.514170 =\frac{1}{20}*474.514170= 23.7257085
2m1i=1∑m(hθ(xi)−yi)2=2∗101∗474.514170=201∗474.514170=23.7257085
获得新权重
调用求解权重函数后,获得新权重。使用新权重计算预测值,打印输出新权重的值。
result = gradientDescent(1000, x_data, y_data, theta, 0.01) #调用求解权重函数
y_pre = np.dot(x_data, result) #使用新权重求解预测值
print("线性回归模型 w: ", result)
绘制可视化图像
使用matplotlib包中的plt工具绘制坐标系,并将样本点的值绘制在坐标系中,使用绿色的点进行表示;绘制线性回归直线在坐标系中,使用红色的线进行表示;使用一个窗口显示绘制的图像。
plt.scatter(x[:, 0], x[:, 1], color='g',label ="Points") #在XY坐标轴上绘制样本点,样本点的颜色为绿色,标签值为Points
plt.plot(x[:, 0], y_pre, color='r',label ="Linear Regression") #在XY坐标轴上绘制线性回归直线,颜色为红色
plt.xlabel('x') #横坐标的标签
plt.ylabel('y') #纵坐标的标签
plt.legend() #给图像加图例,将样本点和直线的标签值增加到图像中
plt.show() #显示所有打开的图形,即打开一个窗口显示图片
总结
该程序主要带大家了解使用python中的numpy库进行求解线性回归问题,手动实现一个最简单的线性回归模型,了解在机器学习中的训练、损失函数、梯度等概念,同时学习如何在python程序中实现矩阵进行加减乘除操作。大家如果对公式不太理解,可查看线性回归梯度下降公式推导。
1.3.3 Sklearn实现房价预测模型
这里参考经典的波士顿房价预测问题,假设你是一个房产经理人,现在你需要根据手上拥有的房产数据回答客户的问题,客户会提出想购买的房屋面积,你需要根据房屋面积给客户进行报价。
想要解决这个问题,我们需要建立的一个回归模型,并使用房产数据进行训练,训练出的模型可以根据当前地区的房屋面积预测平均价格。这里收集了本地的房地产市场数据,使用开源的机器学习库Scikit-learn,对数据进行回归模型的训练,将训练结果进行线性回归和预测。
下面展示100个房地产数据样本的散点图,横坐标为房屋面积,纵坐标为房屋价格。

使用表格的形式将房地产数据样本存储在HousePrice.csv表格文件下,使用pandas读取表格文件下的样本数据,使用Scikit-learn库中内置的线性回归建立模型,并使用HousePrice.csv文件中的数据进行训练,训练完成之后,将回归直线绘制在房地产数据样本的散点图上。程序流程图如下所示:

代码流程为:
1. 导入numpy包,该包是数组处理包,提供了处理 n 维数组的工具,即提供矩阵运算能力。
2. 导入matplotlib包,该包可支持Python 的 2D 可视化绘图库,可创建静态、动画和交互式可视化图像。
3. 导入pandas包,该包是数据分析支持库,提供强大的数据处理和分析工具,可支持数据的导入、清洗、转换和分析。
4. 导入sklearn包,该包是开源机器学习库,它基于NumPy、SciPy和matplotlib,支持各种机器学习模型,包括分类、回归、聚类和降维等。
5. 使用pandas库读取csv文件,获取表格文件中房产样本数据,包括房屋面积和售价。
6. 拆分数据集,将1/4的数据集划分为测试数据集,剩下3/4的数据集划分为训练数据集,用于构建线性回归模型。
7. 使用sklearn内置的LinearRegression函数构建线性回归模型,将训练数据集作为参数传入,并进行训练得到线性模型的权重值和偏置值,即函数y=wx+b中的w和b。
8. 使用训练得到的线性模型传入测试数据集中的数据进行预测,得到预测值。
9. 使用matplotlib的工具将样本点和回归直线绘制到坐标轴上。
1.3.4 Sklearn房价预测代码解析
导入拓展包,支持矩阵运算、可视化、
-
导入numpy包,该包数组处理包,提供了处理 n 维数组的工具,即提供矩阵运算能力。
-
导入matplotlib包,该包可支持Python 的 2D 可视化绘图库,可创建静态、动画和交互式可视化图像。
-
导入pandas包,该包是数据分析支持库,提供强大的数据处理和分析工具,可支持数据的导入、清洗、转换和分析。我们主要使用该包用于读取文件中的房产数据。
-
导入sklearn包,该包是开源机器学习库,它基于NumPy、SciPy和matplotlib,支持各种机器学习模型,包括分类、回归、聚类和降维等。我们主要是使用该包中预先定义好的线性回归模型,帮助我们拆分数据集,并训练文件中的房产数据。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
读取数据文件中的样本
使用pandas库中read_csv函数读取数据集文件,该函数读取文件后会返回一个reader对象,该对象遍历csv文件的每一行,并返回每一行作为一个列表。
使用pandas库iloc函数读取数据的某行或者某列,将数据集中的除了第一列的所有数据,将所有数据转换为numpy数据,并存放在X中;将数据集中的最后一列的的所有数据,将所有数据转换为numpy数据,并存放在Y中;
dataset = pd.read_csv('HousePrice.csv') #读取csv文件,即读取数据集文件
X = dataset.iloc[ : , : 1 ].values #获取样本点数据中的所有行和除了第1列,即样本点数据中的x
Y = dataset.iloc[ : , 1 ].values #获取样本点数据中所有行和第1列,1代表第一列,即样本点数据中的y
拆分数据集
使用sklearn库中train_test_split函数可以将样本数据拆分为训练数据集和测试数据集,X为输入数据,Y为结果数据,test_size = 1/4为拆分四分之一的数据出来作为测试数据集。
#将数据集拆分为训练数据集X_train,Y_train和测试数据集X_test,Y_test
X_train, X_test, Y_train, Y_test = train_test_split( X, Y, test_size = 1/4)
使用sklearn创建线性回归模型
使用sklearn库中LinearRegression函数创建一个普通最小二乘法的线性回归,使用fit方法传入训练数据集,拟合线性模型,其中权重更新和损失函数的公式与上一小节我们手动构建的线性回归是一致的。公式如下所示:
权重更新公式
:
w
=
w
−
α
1
m
×
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
x
j
i
损失函数
:
c
o
s
t
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
2
权重更新公式:w=w-\alpha \frac{1}{m} \times \sum_{i=1}^m (h_\theta(x^i) - y^i)x_j^i\\ 损失函数:cost=\frac{1}{2m} \sum_{i=1}^m (h_\theta(x^i) - y^i)^2
权重更新公式:w=w−αm1×i=1∑m(hθ(xi)−yi)xji损失函数:cost=2m1i=1∑m(hθ(xi)−yi)2
model = LinearRegression() #创建线性回归模型
model = model.fit(X_train, Y_train) #训练拟合线性模型
print("****************************")
print("House Price Prediction Done!")
print("model Regression coefficient:",model.coef_) #打印输出权重
print("model Regression intercep",model.intercept_) #打印输出偏置
使用训练后的模型预测新数据
将测试集中的数据传入训练后的线性回归模型进行预测,并打印真实数据和预测数据。
Y_pred = model.predict(X_test) #模型预测
print("测试集中的真实值:",Y_test)
print("测试集中的预测值:",Y_pred)
绘制可视化图
使用matplotlib包中的plt工具绘制坐标系,并将样本点的值绘制在坐标系中,使用绿色的点进行表示;绘制线性回归直线在坐标系中,使用红色的线进行表示;使用一个窗口显示绘制的图像。
plt.scatter(X , Y, color = 'green') #在坐标轴上绘制样本点,颜色为绿色
plt.plot(X , model.predict(X), color ='red') #在坐标轴上绘制回归直线,颜色为为红色
plt.xlabel('Size/m^2') #横坐标的标签
plt.ylabel('Price/w') #纵坐标的标签
plt.show() #显示所有打开的图形,即打开一个窗口显示图片
总结
该程序主要是使用pandas库读取数据集表格文件,读取出房产样本数据后,使用Sklearn库中的回归算法建立模型文件,将房产样本数据传入后训练生成符合房产数据集的线性回归模型。我们使用预先定义好的线性回归模型就可以不用从头开始实现数学公式,可以快速的帮助我们解决线性回归问题,只需要关注训练后的模型是否符合自己的目标。
2.深度学习及神经网络
2.1 深度学习
深度学习是通过预先处理大量的标记数据,找到其内在规律和表示层次。典型的深度学习模型就是神经网络,神经网络中最基本的组成是神经元模型。
在生物神经网络中,每个神经元与与其他神经元相连,神经元之间的联系通过外部的激励信号做变化,每个神经元有可以接受多个激励信号从而呈现兴奋和抑制的状态,所以人脑在处理各种信息的结果是由各个神经元状态决定的。如下图所示,一个神经元接受到的外部电信号,可以呈现出兴奋和抑制两种状态。

2.1.1 人工神经元
人工神经元是根据生物神经元模拟出来的模型,在这个模型中,神经元可以接受n个从其他神经元传递过来的输入信号,输入信号通过带权重ω连接到神经元,将神经元的总输入值与阈值θ 进行比较,最后通过激活函数处理输出

其中x_i为输入信号, ω_i为神经元连接权重, ∑为输入的总信号和, θ为阈值, y为激活函数。如果要使下一个神经元接受到信号,则接收到的各个信号一定要大于某一个阈值θ才能输出信号 ,该阈值有神经元本身决定。
2.1.2 激活函数
激活函数(Activation Function)是一种在人工神经网络中的函数,旨在帮助网络学习数据中的复杂模式。
在神经元中,输入的input经过一系列加权求和后作用于另一个函数,这个函数就是这里的激活函数。
下图中为一个神经单元,该单元先不考虑阈值,展示一个神经元可以使用不同的激活函数来实现不同的任务。

疑问:为什么这里的神经元阈值消失了?
答:神经网络中的阈值函数,一般也可称为激活函数。
可以先理解为把阈值和激活函数捆绑在一起称为一个函数。
神经网络中的激活函数就是为了增加非线性,激活函数选择了一个阈值,即当大于某个值就被激活,小于等于则输出0。其实这么做也符合人类直觉,对于脑细胞而言,应该也是存在某个阈值,该细胞就会被激活,或者变得敏感。
下面以一个阶跃函数为例,这个函数可以理解为:当输入没有超过阈值点时,所有的输出都为0。当输入大于阈值点是,就输出为5。

下面展示一个简单的激活函数,该激活函数称为Sigmoid函数,它能够把输入的连续实值变换为0和1之间的输出,特别的,如果是非常大的负数,那么输出就是0;如果是非常大的正数,输出就是1。

可以从上图看到, Sigmoid激活函数可以将输入的所有实数压缩在[0,1]范围内。所以Sigmoid函数也可以理解为压缩激活函数。
下面假设一个神经元使用Sigmoid激活函数的示意图。

神经元计算过程为:
1.输入数据x_1 、x_2 、…、x_n进行求和操作,得到net值。
2.将net值传输Sigmoid激活函数,计算得到y值。
3.将y值作为神经元的输出。
2.1.3 实现人工神经元模型
我们已经学习了一个拥有sigmod激活函数的神经元的结构及组成,那么下面我们编写一个python程序,使用numpy库实现一个神经元模型。该模型结构如下所示,该神经元接受10个输入信号x,权重w,偏置b。

程序流程图

python代码实现:
import numpy as np #导入numpy库
def sigmoid(x):
return 1 / (1 + np.exp(-x)) #实现sigmod函数公式
class Neuron:
def __init__(self, weights, bias):
self.weights = weights #各输入的权重值
self.bias = bias #偏置值
def forward(self, inputs):
# 对输入进行加权求和,并增加偏置
total = np.dot(self.weights, inputs) + self.bias
return sigmoid(total) #返回sigmod激活函数输出的结果
x = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) #输入数据
weights = np.array([0.9, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.1, 0]) #权重参数
bias = 2 #偏置值
n = Neuron(weights, bias) #传入权重和偏置值
print(n.forward(x)) #打印神经元模型输出结果
2.2 感知机
2.2.1 感知机模型
感知机(Perceptron)是一种简单的二元线性分类器,简单的来说就是可以将两个简单的样本进行分类。它和我们提到的神经元模型类似,也是由两层神经元组成,感知机也是通过输入层接受外界信号或其他神经元传递的信号,传递给输出层,输出层就是我们一开始介绍的M-P神经元(人工神经元)。
如下图所示,下图为一个接受两个输入信号的,输出一个信号的感知机。

感知机和人工神经元一样可以接受多个输入信号,输出一个信号。但是对于感知机来说,输出的信号只会是0或1。
感知机与含Sigmoid激活函数的神经元不同的是,感知机使用的激活函数是符号(sign)函数,如下所示:

如果对于接受两个输入信号的,输出一个信号的感知机来说,激活函数可以为:

其中ω_1, ω_2为权重值; x_1, x_1为输入信号;b为偏置值;f(x)为输出信号。
**注意:**增加偏置这个参数,可以提高神经网络的拟合能力,提升模型的精度,网络的自由度更大。
2.2.2 鸢尾花二分类问题
二分类问题可能是应用最广泛的机器学习问题,它指的是所有数据的标签就只有两种,正面或者负面。
现在我们使用感知机算法来处理一个经典的鸢尾花分类问题,在一个鸢尾花数据集中有两种鸢尾花,分别是山鸢尾和变色鸢尾,如下图所示:

那么现在准备山鸢尾和变色鸢尾的数据集,数据集中保存了两种鸢尾花的Sepal(萼片)长度/宽度和Petal(花瓣)长度宽度。下面以萼片长度为横坐标X,花瓣长度为纵坐标Y,绘制两种鸢尾花数据样本在坐标系中的表示,如图所示:

上图中红色样本代表山鸢尾样本,蓝色样本代表变色鸢尾样本。那么现在我就想找到一条直线可以划分红色样本点(负样本)和蓝色样本点(正样本),这就是一个二分类问题。
2.2.3 实现感知机模型
假设直线函数为y=ωx+b,现在我们要找到合适的ω和b值,获得可以将正负样本完全区分开来的直线函数。我们通过感知机模型找到模型中的权重和偏置值从而找到该直线函数的ω和b值。下面我们设计python程序实现感知机模型,程序框图如下所示:

python程序代码:
1.导入依赖库,如numpy、pandas、matplotlib等;
2.使用pandas库读取鸢尾花数据集 ;
3.获得数据集中获得萼片长度和花瓣长度作为输入数据X。
4.以萼片长度为x横坐标,花瓣长度为y纵坐标,在坐标系上绘制鸢尾花数据集样本点。

5.获得鸢尾花数据集中的类别名,将类别名为山鸢尾设置为-1,将类别名为变色鸢尾设置为1。
6.创建感知机模型传入学习率和迭代次数。
7.拟合感知机模型,获得权重和偏置。
8.绘制迭代过程中分类错误的变化。

9.在坐标系中绘制分类直线函数。

在开始代码解析前我们需要先对权重更新和偏置更新进行说明,下面为权重和偏置的更新公式。
权重更新公式:
w
=
w
+
α
(
y
i
−
h
θ
(
x
i
)
)
x
j
i
偏置更新公式:
b
=
b
+
α
(
y
i
−
h
θ
(
x
i
)
)
权重更新公式:w=w + \alpha (y^i-h_\theta(x^i))x_j^i\\ 偏置更新公式:b = b + \alpha(y^i-h_\theta(x^i))
权重更新公式:w=w+α(yi−hθ(xi))xji偏置更新公式:b=b+α(yi−hθ(xi))
假设我们分类目标分别是正类(1)和负类(0),假设我们使用感知机进行分类时,假设原来的某点的正确类别是正类,y=1,算法将它判断为负类,即y=0,如下图所示:

可以看到上图中的蓝色样本点分类错误了,以这个蓝色点为例我们就可以知道,该点的:
x
1
w
1
+
x
2
w
2
+
b
<
0
x_1w_1+x_2w_2+b<0
x1w1+x2w2+b<0
感知机输出的值为0,所以才会将蓝色点分为负类(0),蓝色点正确的类别是正类(1),那么我们进行更新应该是将权重和偏置增加使得其感知机输出的值大于0才能正确分类。所以我们就有
w
=
w
+
α
(
y
i
−
h
θ
(
x
i
)
)
x
j
i
w=w + \alpha (y^i-h_\theta(x^i))x_j^i\\
w=w+α(yi−hθ(xi))xji
更新后的权重,使得像原来的分类错误的负值向正值走。
下面我们来详细解析感知机解决鸢尾花二分类代码。
# 导入依赖库
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
# 创建感知机对象
class Perceptron(object):
#启动学习速率和迭代次数。
def __init__(self, Learn_Rate=0.5, Iterations=10):
self.learn_rate = Learn_Rate #学习率
self.Iterations = Iterations #迭代次数
self.errors = []
self.weights = np.zeros(1 + x.shape[1]) #初始化偏置和权重 [0,0,0]
# 确定模型训练的拟合方法。
def fit(self, x, y):
self.weights = np.zeros(1 + x.shape[1]) #获得初始化权重
for i in range(self.Iterations): #循环迭代
error = 0
#xi:输入参数
#target:真实值
#zip(x, y)将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存。
for xi, target in zip(x, y):
loss = (target - self.predict(xi)) # 计算差值=(真实值-预测值)
self.weights[1:] += self.learn_rate * loss * xi #更新权重
self.weights[0] += self.learn_rate * loss #更新偏置
error += int(self.learn_rate * loss != 0) #记录分类错误数
self.errors.append(error) #向error列表末尾添加元素
print("echo:{},error:{}".format(i,error))
return self.weights[1:],self.weights[0]
# 网络输入法,用于将给定的矩阵输入及其相应的权重相加
def net_input(self, x):
return np.dot(x, self.weights[1:]) + self.weights[0]
# 预测数据输入分类的预测方法
def predict(self, x):
return np.where(self.net_input(x) >= 0.0, 1, 0) #相当于感知机的激活函数
# 数据检索和准备
print("Loading dataset...")
y = pd.read_csv("./iris.data", header=None) #读取鸢尾花数据集
#数据集变量:萼片长度、萼片宽度、花瓣长度、花瓣宽度、类别名
x = y.iloc[0:100, [0, 2]].values #获得萼片长度和花瓣长度
plt.scatter(x[:50, 0], x[:50, 1], color='red',label ="Iris-setosa") #绘制山鸢尾样本点
plt.scatter(x[50:100, 0], x[50:100, 1], color='blue', label = "Iris-versicolor") #绘制变色鸢尾样本点
plt.xlabel('sepal_length') #增加x轴标签
plt.ylabel('petal_length') #增加y轴标签
plt.legend() #给图像加图例,将样本点和直线的标签值增加到图像中
print("Load dataset Succeed!!!")
plt.show() #显示所有打开的图形,即打开一个窗口显示图片
y = y.iloc[0:100, 4].values #获得鸢尾花的类别名
y = np.where(y == 'Iris-setosa', 0, 1) #当y等于Iris-setosa成立时where方法返回-1,当条件不成立时where返回1
# 模型训练和评估
Classifier = Perceptron(Learn_Rate=0.01, Iterations=10) #创建感知机模型传入学习率和迭代次数
print("Start fitting network...")
w,b = Classifier.fit(x, y) #拟合模型
print("fitting network succeed!!!")
print("weights:{},b:{}".format(w,b))
plt.plot(range(1, len(Classifier.errors) + 1), Classifier.errors, marker='o') #绘制迭代过程中分类错误数变化
plt.xlabel('Epochs')
plt.ylabel('Number of misclassifications')
plt.show()
#绘制分类直线函数
plt.scatter(x[:50, 0], x[:50, 1], color='red',label ="Iris-setosa") #绘制山鸢尾样本点
plt.scatter(x[50:100, 0], x[50:100, 1], color='blue', label = "Iris-versicolor") #绘制变色鸢尾样本点
plt.plot(x[:, 0], (w[0]*x[:, 0] + b)/(-w[1]),color='green') #绘制分类直线 w0*x0+w1*x1+b=0 => x1=(w0*x0+b)/(w1)
plt.xlabel('sepal_length') #增加x轴标签
plt.ylabel('sepal_width') #增加y轴标签
plt.legend()
plt.show()
2.3 多层神经网络
2.3.1 XOR问题
在学习多层神经网络前,我们为什么要学习多层神经网络?

单层单节点神经网络可以去拟合一条直线y=ax+b,可分别求解线性回归问题和二分类线性可分问题。
如果求解的问题,不能通过一条直线就去解决,那么单层单节点神经网络就不适用了。例如经典的XOR问题:
假设需要对下面红蓝样本点进行分类,红蓝样本数据的分布如下所示:

通过观察上图可以发现,我们无法通过如上一小节一样建立感知机模型,绘制一条直线将上图中的红蓝样本数据进行分类。由于无论分类直线位于哪个位置,都无法解决此种分类问题。如下所示:

那么我们该如何解决这种XOR问题(异或问题)?我们需要引入拟合能力更强的多层神经网络,去解决一些非线性的问题,可以使用多层感知机来解决此类问题(组合多个简单函数,从而实现更复杂的任务)。
下面展示建立怎么样的多层感知机模型,我们先将红蓝样本以坐标系中象限的方式划分红蓝样本:

我们可以发现红色样本点在第1象限和第3象限中,蓝色样本点在第2象限和第4象限中,那么可知红色样本的x值和y值相乘结果为正,蓝色样本的x值和y值相乘结果为负。那么我们可以设计如下多层感知机模型。

绿色的感知机分类器,主要是判断样本是位于y轴的正区间还是负区间。
紫色的感知机分类器,主要是判断样本是位于x轴的正区间还是负区间。
从上面这两个感知机分类器中获得分类器结果后,对比两个结果是否一致,一致为正样本,不一致为负样本。
将预测结果为正的类,分类为正样本;将预测结果为负的类,分类为负样本。

通过上图可以看到,红色样本点2和3的结果都是正,蓝色样本点1和4的结果都是负。那么就可以说明我们使用多层神经网络就可以解决XOR问题。
2.3.2 多层网络组成
多层神经网络是含中间层的人工神经网络。那么什么是中间层呢?下面以一个两层输入层,一个输出层的神经网络展示:

如上图所示,在输入层和输出层有一个中间层网络,下面分别介绍各个在这个网络结构中的作用:
输入层:将数据输入到网络中,不做处理直接输入隐含层。
隐含层(隐层):对输入层输出的数据进行求和操作,并使用激活函数对输入总数据进行操作。
输出层:将隐含层输出的数据进行求和操作,求和后直接输出。
注意:在多层神经网络中,输出层可以包含激活函数也可以不包含激活函数。
常见的多层神经网络下图所示,每层神经元与下一层完全相连,神经元之间不允许同层相连,也不允许跨层相连,也可以称为全连接神经网络。

多层神经网络采用一种单向多层结构。其中每一层包含若干个神经元。在此种神经网络中,各神经元可以接收前一层神经元的信号,并产生输出到下一层。第0层叫输入层,最后一层叫输出层,其他中间层叫做隐含层(或隐藏层、隐层)。隐层可以是一层,也可以是多层。
2.4 参数的传播方向
当我们知道这些神经元的构成后,我们还需要知道参数是如何传播的?传播方向是什么样的?我们应该怎么去更新对应的权重值?
我们训练的意义就是为了找到合适的权重值等参数,所以参数传播的方向是十分重要的。
参数的传播方向:前向传播、反向传播

2.5 前向传播和反向传播
前向传播是指在神经网络中沿着输入层到输出层的顺序,将上一层的输出作为下一层的输入,并计算下一层的输出,依次计算到输出层为止。这里举一个简单的例子,便于大家理解。假设输入信号有x_1,x_2,x_3。神经网络结构如下图所示:

通过上图可以看出节点f_1 (x)与输入信号x_1,x_2,x_3 相连,节点f_5 (x)和f_6 (x)分别与节点f_1 (x)、 f_2 (x) 、f_3 (x)、 f_4 (x)相连。
输入数据x_1,x_2,x_3的通过隐含层节点后f_1 (x)…f_6 (x),最后到输出层y_1输出。
反向传播算法也称为误差逆传播算法(error BackPropagation),简称BP算法**。现在很多神经网络都用BP算法,特别多用于多层前反馈神经网络,所以一般BP网络则是指BP算法的**多层前反馈神经网络。
假定数据集为D={(x_1,x_2 ) ,(x_3,x_4),…,(x_n,x_n+1)} ,这里我以最简单的模型举例,以1层输入层,1层隐含层h_1,h_2,1层输出层y_1,激活函数a_1,a_2,a_3 。在前面我们已经对神经网络有了初步了解,输入层是不对输入的信号进行处理的,只有隐含层和输出层有激活函数,输出激活值。
在前面我们已经对神经网络有了初步了解,输入层是不对输入的信号进行处理的,只有隐含层和输出层有激活函数,输出激活值。

对于隐含层:

对于输出层:

上述过程就为正向传播,我们这里使用平方差损失函数衡量预测结果,对于误差值有:

通过梯度下降法和链式法则,求解梯度。
对于输出层,求解梯度值:

更新权重值和偏置值为:


对于隐含层

更新权重和偏置值为:

对于隐含层其他的也是类似的,这里就不举例了。
所谓反向传播就是将正向传播计算的结果,反向传回给初始化参数,从而改变权重值,再次训练后再查看预期值是否符合预期结果,如果不符合则继续改变权重,直至获得的权重训练的结果满足预期目标。
反向传播的步骤如下:
1.初始化权重ω和偏置值b等初始化参数
2.正向传播,计算每个神经元的输出
3.通过损失函数计算误差值
4.通过梯度下降法和链式法则求解每个神经元的梯度
5.更新网络参数。
通过上述步骤可以看出,反向传播的作用主要是更新权重,使训练拟合的模型性能更加优秀。
2.6 损失函数
前面我们讨论了我们需要通过训练不断去更新权重值,那么这里就有一个问题,我们如何去判断我们得到的权重是符合我们数据的网络要求的?
这里就需要引入一个判断标准,去判断我们更新的网络模型可以正确的预测目标。
这个判断标准叫做损失函数,损失函数是度量模型的预测值f(x)与真实值Y的差异程度的运算函数,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。可以用来评价模型的预测值和真实值不一样的程度。

通过损失函数计算出来的值叫做损失值,损失值是预测值和真实值的差值。损失值越小,通常模型的性能越好。如上图所示,我们经过不断迭代,就是为了找出损失值的最低点。
由于不同的模型也需要不同的损失函数。常用的损失函数有绝对值误差, 平方差、log对数损失函数等。
下面展示一下常见的两种损失函数,绝对值误差损失函数、log对数损失函数的函数图像。

下面介绍什么是绝对值误差函数?它是基于y轴对称的函数,其表达式为:

它描述了目标值和预测值的差值的绝对值之和,表示预测值的平均误差程度,且不考虑方向问题。
假设现在以求解线性回归问题(求解样本点趋势线)为例,我们通过预测得到的某一样本点为(1,2),实际的样本点为(1,4)。
L
1
=
∣
4
−
2
∣
=
2
L_1=|4-2 |=2
L1=∣4−2∣=2
上述公式是求解一个样本点的绝对值误差,即(实际值的平方-预测值的平方)的绝对值。
L
=
(
L
1
+
L
2
+
…
+
L
n
)
/
n
L=(L_1+L_2+…+L_n)/n
L=(L1+L2+…+Ln)/n
将所有的预测样本点和实际的样本点进行上述操作获取绝对值误差,并将所有的绝对值误差进行求和操作后再除以样本点总数,即可获取总绝对值误差。
3.深度学习框架Pytorch入门
3.1 深度学习框架简介
什么是深度学习框架?
在深度学习初始阶段,每个深度学习研究者都需要写大量的重复代码。为了提高工作效率,这些研究者就将这些代码写成了一个框架放到网上让所有研究者一起使用。接着,网上就出现了不同的框架。随着时间的推移,最为好用的几个框架被大量的人使用从而流行了起来。
深度学习框架是一种界面、库或工具,它使我们在无需深入了解底层算法的细节的情况下,能够更容易、更快速地构建深度学习模型。深度学习框架利用预先构建和优化好的组件集合定义模型,为模型的实现提供了一种清晰而简洁的方法。深度学习框图如下所示:

下面举两个例子来解释深度学习框架。
例子1:深度学习框架就是库,目前市面上有很多不同牌子的库,库里面就一套积木。这套积木里面包含很多组件,如:模型、算法等。也就是说这些积木已经把底层的数学公式帮你实现了,你无需从零开始实现数学公式的复杂运算,只需要关心怎么设计积木搭建城建符合你数据集的积木。目前就有很多牌子的积木,如Pytorch、TensorFlow、Caffe等。
这套积木里面包含:预定义模型、反向传播算法、梯度下降等预先定义的函数,供开发者可以自由搭建成符合自己数据集的神经网络。

例子2:假设数据集就是食材,我们需要对食材进行加工,需要用到锅、铲子、刀等厨具。这里我们就需要去选择不同品牌的厨具,当然我们厨具里面有很多工具,你只需要自己搭配厨具使用,不需要从头开始磨刀/炼钢(不需要从零开始实现数学公式)。假设你要做的菜是糖醋排骨,那么不同牌子提供的厨具套装里面,都可以实现你这道菜,那可以使用Pytorch牌厨具套装做成,你也可以使用TensorFlow牌厨具套装做成。

为什么要使用深度学习框架?
因为使用深度学习框架可以降低入门的门槛,你可以不用从复杂的神经网络开始编写代码,也不需要去手动实现梯度下降、前向传播、反向传播等,你可以依据预先定义好的模型的基础上增加自己的模型、搭建自己的网络层、选择自己需要的分类器。简而言之,使用深度学习框架这个库就是加快搭建神经网络的速度,直接使用其预先定义好的API,即可实现自己的神经网络模型的搭建。

深度学习框架对比

3.2 深度学习框架-pytorch
由于Pytorch的生态建设较好同时底层细节较好,下面主要使用Pytorch来对深度学习框架进行讲解快速入门程序。打开Pytorch网址:https://pytorch.org/

打开官方Pytorch快速入门的链接:https://pytorch.org/tutorials/beginner/basics/quickstart_tutorial.html

3.3 求解服饰图像多分类问题
3.3.1 多分类问题介绍
快速入门程序是求解多分类问题,从网上下载的FashionMNIST数据集,该数据集包含黑白图像有:
t-shirt(T恤),trouser(牛仔裤),pullover(套衫),dress(裙子),coat(外套),sandal(凉鞋),shirt(衬衫),sneaker(运动鞋),bag(包),ankle boot(短靴)。
多分类问题目的是:建立一个模型可以实现下面图像的分类。

3.3.2 程序流程框图
程序流程图如下所示:

3.3.3 程序源码解析
程序源码解析:
1.引入pytorch包
import torch #引入pytorch包,该包中包含tensor(多维矩阵)的数据结构以及对应的数学运算
from torch import nn #引入pytorch中的nn包,该包预先定义网络层,例如卷积层、池化层、激活函数及损失函数等。
from torch.utils.data import DataLoader #该包主要用于加载数据集和对数据集进行划分。
from torchvision import datasets #该包主要用于引入数据集模块,该模块中包预定义有常见的数据集,同时可用于构建自定义的数据集。
from torchvision.transforms import ToTensor #该包主要用于将PIL图像或者numpy中N维数组类型的对象 转换为 tensor ,并且支持缩放对应值。
2.下载训练数据集
# Download training data from open datasets.下载训练数据集
training_data = datasets.FashionMNIST(
root=“data”, #数据集存放路径,当前目录下的data文件夹下
train=True, #表示该数据集为训练数据集
download=True, #是否需要网络下载
transform=ToTensor(), #将下载的数据集快速切换为pytorch可使用的tensor(多维矩阵)
)

3.下载测试数据集
# Download test data from open datasets.
test_data = datasets.FashionMNIST(
root="data", #数据集存放路径,当前目录下的data文件夹下
train=False, #表示该数据集为测试数据集
download=True, #是否需要网络下载
transform=ToTensor(), #将下载的数据集快速切换为pytorch可使用的tensor(多维矩阵)
)

4.加载数据集
batch_size = 64 #设置批次大小(批次:每次读取的数量)
# Create data loaders.
train_dataloader = DataLoader(training_data, batch_size=batch_size) #加载训练集
test_dataloader = DataLoader(test_data, batch_size=batch_size) #加载测试集
#每次以迭代器的方式返回一批64个数据和标签。
for X, y in test_dataloader:
print(f"Shape of X [N, C, H, W]: {X.shape}") #X为转换后的tensor数据
print(f"Shape of y: {y.shape} {y.dtype}") # y为标签, y.dtype表示数据元素的数据类型
break
X [N, C, H, W]: batchsize,channel,height,weight。batchsize是我们设置的批次大小64,也就是一次取64张图像;channel为1表示通道数,灰度图为1,彩色图为3;高度和宽度则是单张图像的大小28*28像素。
5.指定加载设备
# Get cpu, gpu or mps device for training.
device = (
“cuda”
if torch.cuda.is_available() #判断系统是否支持CUDA
else “mps”
if torch.backends.mps.is_available() #判断系统是否支持MPS
else "cpu"
)
print(f"Using {device} device")
CUDA 是 NVIDIA 发明的一种并行计算平台和编程模型。它通过利用图形处理器 (GPU) 的处理能力,可大幅提升计算性能。
多进程服务(MPS)是另一种二进制兼容的实现CUDA应用程序编程接口,透明地支持协作式多进程CUDA应用程序
6.定义模型
创建pytorch模型,为了定义一个模型,创建一个从nn.Module继承的类,在NeuralNetwork类中使用__init__函数定义了网络层,使用forward函数定义指定数据如何通过网络。
# Define model
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
#参数传播方向:前向传播
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork().to(device)
print(model)
nn.Flatten():将连续的维度范围展平为张量。
nn.Sequential:有序容器,神经网络模块将按照在传入构造器的顺序依次被添加到计算图中执行,同时以神经网络模块为元素的有序字典也可以作为传入参数。

6.1 Linear层研究
Linear是线性层;ReLU是激活函数。Linear的函数定义为:
torch.nn.Linear(
in_features, #每次输入的样本大小
out_features, #每次输出的样本大小
bias=True, #如果设置为False,该层附加偏置。默认值:True
device=None,
dtype=None
)
Linear线性层是将输入执行一次线性变换,函数定义为:
y
=
x
A
T
+
b
y=xA^T+b
y=xAT+b
其中x为输入,A^T 为权重,A^T为A的转置矩阵,b为偏置.
import torch
from torch import nn
model = nn.Linear(2,1) #输入特征数为2,输出特征数为1
print(model)
input = torch.Tensor([[100,200],[300,400]]) #输入一个2×2的矩阵
print(input)
print(input.size())
output = model(input)
print(output)
print(output.size())
for param in model.parameters():
print(param)
该段程序的运行结果:
Linear(in_features=2, out_features=1, bias=True)
tensor([[100., 200.], [300., 400.]])
torch.Size([2, 2])
tensor([[47.2638], [99.8806]], grad_fn=<AddmmBackward0>)
torch.Size([2, 1])
Parameter containing:
tensor([[0.0527, 0.2103]], requires_grad=True)
Parameter containing:
tensor([-0.0788], requires_grad=True)
其中model是通过torch.nn创建的线性层模块,input是通过torch.Tensor创建的2×2矩阵, output是input矩阵通过线性层后的结果矩阵。
由打印信息可知,创建的model函数输入特征数为2,输出特征数为1。偏置设置为True,即使用偏置值。输入矩阵input为[(100&200@300&400)],输出矩阵output为[(47.2638@99.8806)],权重矩阵A为[8(0.0527&0.2103)],偏置值为-[0.0788]
Linear层数学推导:

其中b原本为-[0.0788],由于广播机制,变换为b=[(-0.0788@-0.0788)]
最后计算的y值为[(47.2512@99.8512)],与程序计算出来的[(47.2638@99.8806)]
是存在一定的误差,这就是计算机利用二进制表示小数,在进行矩阵运算时,尾数存储时会出现舍入的情况,类似于我们小时候学习的四舍五入,舍入的情况会导致二进制的保存值大于真实值或小于真实值,这就会导致计算机在计算浮点数产生误差的原因。
7.损失函数和优化器
为了训练模型,还需要增加一个损失函数和一个优化器对象,优化器对象可以保存当前状态,并根据计算出的梯度更新参数。损失函数使用交叉熵损失函数,优化器使用的是torch.optim.SGD随机梯度下降。
loss_fn = nn.CrossEntropyLoss() #损失函数使用交叉熵损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3) #神经网络优化器,主要是为了优化我们的神经网络,使他在我们的训练过程中快起来,节省神经网络训练的时间。
交叉熵损失函数是用来衡量目标值和预测值之间的差距,在深度学习中常用于解决多分类问题。

随机梯度下降用于在反向传播中更新模型中的梯度值。梯度值如图中红色箭头所示。
torch.optim.SGD()是随机梯度下降函数,传入的参数为:保存有权重和偏置的参数量model.parameters(), 学习率lr。梯度下降一般分为批量梯度下降和随机梯度下降,其中批量梯度下降是在更新参数时使用所有样本来更新梯度,随机梯度是在求解梯度时没有使用全部的样本,而是仅随机选取一个样本来求解梯度。
批量梯度下降:

随机梯度下降:

如何理解上述两个公式:
1.批量梯度下降:每次都要计算所有实际样本与预测样本的误差值。
2.随机梯度下降:每次随机选取一个实际样本与预测样本计算误差值。

8.定义训练函数
在训练循环中,模型对训练的数据集进行预测,使用反向传播预测误差并更新模型的参数,同时根据测试数据集检查模型的性能确保训练的方向正确。
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) #数据集的长度
model.train() #设置模型为训练模式
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device) #指定数据加载到指定设备中
# Compute prediction error
pred = model(X) #利用模型求解预测值
loss = loss_fn(pred, y) #求解预测值和真实值的损失函数
# Backpropagation
loss.backward() #反向传播计算当前梯度
optimizer.step() #根据梯度更新网络参数
optimizer.zero_grad() #梯度清零
if batch % 100 == 0:
# loss.item()是提取损失值的高精度值, (batch + 1) * len(X) 是计算当前训练的数据位置
loss, current = loss.item(), (batch + 1) * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
9.定义测试函数
测试函数中不去反向计算梯度,只使用模型去求解预测损失值,并且计算其模型损失值和精度。
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset) #数据集的长度
num_batches = len(dataloader) #批次大小
model.eval() #设置模型为测试模式
test_loss, correct = 0, 0
with torch.no_grad(): #不计算反向梯度
for X, y in dataloader:
X, y = X.to(device), y.to(device) #指定数据加载到指定设备中
pred = model(X) #利用模型求解预测值
test_loss += loss_fn(pred, y).item() #计算模型损失
correct += (pred.argmax(1) == y).type(torch.float).sum().item() #计算模型精度
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
10.训练模型
我们设置的迭代次数为5次,每调用训练模型的函数一次,就调用测试模型函数去测试模型的精度和损失值。当迭代完成五次后,保存迭代后的模型文件为‘model.pth’
epochs = 5 #设置迭代次数
for t in range(epochs):
print(f“Epoch {t+1}\n-------------------------------”)
train(train_dataloader, model, loss_fn, optimizer) #调用训练模型函数
test(test_dataloader, model, loss_fn) #调用测试模型函数
print("Done!")
通过上述运行结果可以发现在不断的迭代后,精度在不断提升,损失在不断下降。这说明外面对模型的优化方式是可行的。
torch.save(model.state_dict(), “model.pth”) #保存模型,保存为当前目录中的model.pth
print("Saved PyTorch Model State to model.pth")
模型训练过程示意图

11.Pytorch使用训练好的模型进行测试
加载刚刚训练完成的模型文件,将模型设置为测试模式,使用模型加载测试集中的图像,返回的结果与真实值比较,查看是否一致。
model = NeuralNetwork().to(device)
model.load_state_dict(torch.load("model.pth"))
classes = [
“T-shirt/top”,
“Trouser”,
“Pullover”,
“Dress”,
“Coat”,
“Sandal”,
“Shirt”,
“Sneaker”,
“Bag”,
“Ankle boot”,
]
model.eval() #设置模型为测试模式
x, y = test_data[0][0], test_data[0][1] #设置测试数据和标签值
with torch.no_grad():
x = x.to(device) #指定数据加载到指定设备中
pred = model(x) # #利用模型求解预测值
predicted, actual = classes[pred[0].argmax(0)], classes[y] #查看预测值和真实值
print(f'Predicted: "{predicted}", Actual: "{actual}"')
Pytorch训练测试模型完整流程示意图

4.基础算子及卷积神经网络
4.1 基础算子
函数的定义域为一个数集,值域也为一个数集,即函数是数值到数值的映射。
泛函的定义域为函数集,值域为是实数集,即泛函是函数到数值的映射。
算子的定义域为函数集,值域为函数集,即算子是函数到函数的映射。
在深度学习是由一个个计算单元组成的,这些计算单元我们称为算子(Operator),**算子在神经网络中表示对应层的计算逻辑。**例如:在深度学习中对tensor(矩阵)的操作,如线性运算,加权求和等数学函数计算。
对于激活函数,如sigmoid函数、符合函数等,我们称为用作激活函数的算子。
下面演示一些基础的算子,帮助理解算子是什么?
例如微分算子,是使函数y处理变成y^′,其表达式为:
D
(
y
)
=
y
′
D(y)=y^′
D(y)=y′
这表示对函数y求了一次导,同理可以将D(y)微分算子再求一次导:
D
(
D
(
y
)
)
=
y
′
′
D(D(y))=y^′′
D(D(y))=y′′
由此归纳总结出:
D
n
(
y
)
=
y
(
(
n
)
)
D^n (y)=y^((n))
Dn(y)=y((n))
其中n表示对函数y求导了n次。

下面以求和算子进行举例说明算子在神经网络中是如何运用的,在之前我们学习到了神经元会接收n个输入x_i,进行一些数学运算,再产生一个输出y。

如上图所示,求和算子就是接收n个输入后,将每个输入乘以其权值后相加,相加后的值为总输入,将总输入作为参数X传给激活函数,公式为:X=∑_(i=1)^n[x_1+x_2+…+x_n ],经过激活函数输出Y。
4.2 卷积神经网络
神经网络有许多算子构成的网络框架,典型的神经网络如下图的卷积神经网络,其中至少有一层是由卷积算子构成的网络

卷积神经网络(Convolutional Neural Networks)是人工神经网络的一种特殊类型,在其至少一层中使用称为卷积的数学运算代替通用矩阵乘法。它们专门设计用于处理像素数据,并用于图像识别和处理。

一个卷积神经网络主要由以下5层组成:
•数据输入层/ Input layer
•卷积计算层/ CONV layer
•池化层 / Pooling layer
•ReLU激励层 / ReLU layer
•全连接层 / FC layer
4.3 卷积算子
4.3.1 为什么需要卷积?
在机器学习中输入都是以高维数据为主,在之前我们使用简单的线性学习器,如下图所示:

上述是各个维度线性可分的情况,我们可以通过简单的直线或者将样本进行分类。但如果样本的分布出现如下图所示的情况,样本变成了线性不可分了。

下图可以看出来在2维中我们不能使用一条直线将红蓝样本分类,但我们还是想两个样本进行分类,所以我们将样本映射到3维上,如上图中3维所示,原本在2维上不可分的样本,在3维就可以使用一个平面将样本分开,所以我们通过一个映射函数将样本从n维映射到n+1维或者更高维度,使得原本线性不可分的问题变成线性可分,以解决样本分类。

所以我们为了去求解分类问题,我们如何去升维呢?
假设H为特征空间,如果存在一个从低维空间X和高维空间H的映射,映射过程记为∅(x),则有:

使得对所有的x,y∈X,函数K(x,y)满足条件

其中函数K(x,y)被称为核函数,∅(x)称为x的映射函数,∅(y)称为y的映射函数,∅(x)∙∅(y)是∅(x)和∅(y)的内积。

将原始空间中的向量作为输入向量,并返回特征空间(转换后的数据空间,可能是高维)中向量的点积的函数称为核函数。
核函数就是为了找到样本的分割函数而产生的能使样本从低维空间映射到高维空间,使得原本在低维空间中不可分的数据在高维中可分。

4.3.2 图像卷积
对于图像的卷积,则输入是二维的图像I,核函数为K,因为m,n的取值范围相对较小,在许多神经网络库中还会实现一个互相关函数为:

在许多机器学习库中的互相关函数也称为卷积。所以我们知道卷积过程就是图像乘核函数。
卷积完成后可以在高维空间将图像中的像素样本变成可分的,即提取特征值。

卷积层(conv)是使用卷积核(核函数)来提取图像的特征信息并将其输入到神经网络中,我们可以通过重复的卷积操作来获得图像的在不同层次的特征,从而减少源图像中各种噪声的污染。如图所示,卷积中运算过程由二维数字矩阵卷积核对原图像进行卷积,具体步骤为:
1.在图像的某个位置覆盖卷积核;
2.将卷积核中的值与图像中的对应像素矩阵的值相乘;
3.将步骤2的乘积结果相加,得到的和为输出图像中的目标像素值;
4.对图像的全部位置重复上述操作。

4.3.3 卷积与互相关
我们从上一小节学习到图像的卷积过程就是源图像与核函数对应像素值相乘,并将乘积结果进行累加。可以发现其实这个操作直观上来看更像加权求和的感觉,那么为什么叫做卷积呢?目前图像卷积是根据卷积的思想而来的相关运算,所以在神经网络中会实现互相关函数。
那么这里的**“互”**是谁和谁相关呢?我们以3×3的卷积核来看,原图像经过一个卷积核之后,输出一个值,那么这个值就是源图像中“中间像素”与周围一圈像素的关系。也就是说,卷积核帮助我们找这两者的关系,分别为两种:另一种是周围像素对中间像素的关系影响;另一种是中间像素与周围像素的关系影响。所以卷积实际上是分为两种操作,分别是:
- 考虑周围像素如何对当前中间像素点产生影响的。
- 当前中间像素点对周围像素的试探和选择。

4.3.4 卷积处理图像
那么下面我们来看看哪一种是我们前面用于提取特征值的操作。
周围像素对中间像素的影响:我们以图像模糊为例,带大家了解周围像素如何对中间像素产生影响的。我们使用OpenCV库的实现一个简单的均值模糊。
#导入opencv模块
import cv2 as cv
#读取当前目录图像,支持 bmp、jpg、png、tiff 等常用格式
img = cv.imread("test.jpg")
#创建一个input窗口用于显示图像
cv.namedWindow("input")
#在input窗口中展示输入图像
cv.imshow("input",img)
#图像均值模糊处理,使用3*3的卷积核处理,处理结果图像存储在blur
blur = cv.blur(img, (3,3), 0)
#创建一个Output窗口用于显示图像
cv.namedWindow("Output")
#在Output窗口中展示输入图像
cv.imshow("Output",blur)
#创建的窗口持续显示,直至按下键盘中任意键
cv.waitKey(0)
#释放窗口
cv.destroyAllWindows()
输入和经过均值模糊处理后的图像,如下所示:

可以通过两张图片看出来,经过均值模糊后的图像与原图像对比更加模糊了,减小了噪声。那么这个均值模糊也是和我们前面说的一样,原图像经过一个卷积核进行处理,处理后的图像输出即为卷积后的图像。下面我们来看一下均值模糊是如何实现这一个模糊过程的。
我们这里就不以公式的角度理解均值模糊,我们根据图像像素值的角度来看。首先我们需要清楚,图像模糊的本质是处理图像中与周围差异较大的点,将其像素值调整为与周围点像素值近似的值。
均值模糊:每一个像素点都取周边像素的平均值后,如果中间值大于平均值,就降低中间值;如果中间值小于平均值,就升高中间值。在数值上就表现出平滑的效果,在图像中就表现为模糊的效果。

如果用坐标的形式表示中间像素和周围像素,可如下所示:

所以程序中均值模糊中的卷积操作是:
1.在图像的某个位置覆盖卷积核,归一化卷积核为
k
=
1
9
∣
1
1
1
1
1
1
1
1
1
∣
k =\frac{1}{9}\left|\begin{matrix} 1 & 1 & 1\\ 1 & 1 & 1\\ 1 & 1 & 1\\ \end{matrix} \right|
k=91
111111111
2.将卷积核中的值与图像中的对应像素矩阵的值相乘;
3.将步骤2的乘积结果相加,得到的值为输出图像中的目标像素值;
4.对图像的全部位置重复上述操作。
那么下面我们通过放大输入图像和经过均值模糊的输出图像,来看一下均值模糊的计算过程。

我们通过上图知道输入图像黄色框中的RGB值和输出图像黄色框中的RGB值,两个黄色框是图像中的同一位置。计算过程如下:
-
为更好的展示过程,我们单独计算RGB通道,那么卷积核覆盖位置的原图像RGB值分别为:
R = ∣ 146 132 118 130 119 112 124 115 111 ∣ , G = ∣ 75 60 49 59 47 43 53 43 42 ∣ , B = ∣ 57 45 33 41 32 27 35 28 26 ∣ R=\left|\begin{matrix} 146 & 132 & 118\\ 130 & 119 & 112\\ 124 & 115 & 111\\ \end{matrix} \right|,G=\left|\begin{matrix} 75 & 60 & 49\\ 59 & 47 & 43\\ 53 & 43 & 42\\ \end{matrix} \right|,B=\left|\begin{matrix} 57 & 45 & 33\\ 41 & 32 & 27\\ 35 & 28 & 26\\ \end{matrix} \right| R= 146130124132119115118112111 ,G= 755953604743494342 ,B= 574135453228332726 -
将RGB三通道的值分别与卷积核k相乘
R 1 = R ∗ k = ∣ 146 132 118 130 119 112 124 115 111 ∣ ∗ 1 9 ∣ 1 1 1 1 1 1 1 1 1 ∣ = 1 9 ∣ 146 132 118 130 119 112 124 115 111 ∣ , G 1 = G ∗ k = ∣ 75 60 49 59 47 43 53 43 42 ∣ ∗ 1 9 ∣ 1 1 1 1 1 1 1 1 1 ∣ = 1 9 ∣ 75 60 49 59 47 43 53 43 42 ∣ , B 1 = B ∗ k = ∣ 57 45 33 41 32 27 35 28 26 ∣ ∗ 1 9 ∣ 1 1 1 1 1 1 1 1 1 ∣ = 1 9 ∣ 57 45 33 41 32 27 35 28 26 ∣ R_1=R*k=\left|\begin{matrix} 146 & 132 & 118\\ 130 & 119 & 112\\ 124 & 115 & 111\\ \end{matrix} \right|*\frac{1}{9}\left|\begin{matrix} 1 & 1 & 1\\ 1 & 1 & 1\\ 1 & 1 & 1\\ \end{matrix} \right|=\frac{1}{9}\left|\begin{matrix} 146 & 132 & 118\\ 130 & 119 & 112\\ 124 & 115 & 111\\ \end{matrix} \right|, \\G_1=G*k=\left|\begin{matrix} 75 & 60 & 49\\ 59 & 47 & 43\\ 53 & 43 & 42\\ \end{matrix} \right|*\frac{1}{9}\left|\begin{matrix} 1 & 1 & 1\\ 1 & 1 & 1\\ 1 & 1 & 1\\ \end{matrix} \right|=\frac{1}{9}\left|\begin{matrix} 75 & 60 & 49\\ 59 & 47 & 43\\ 53 & 43 & 42\\ \end{matrix} \right|, \\B_1=B*k=\left|\begin{matrix} 57 & 45 & 33\\ 41 & 32 & 27\\ 35 & 28 & 26\\ \end{matrix} \right|*\frac{1}{9}\left|\begin{matrix} 1 & 1 & 1\\ 1 & 1 & 1\\ 1 & 1 & 1\\ \end{matrix} \right|=\frac{1}{9}\left|\begin{matrix} 57 & 45 & 33\\ 41 & 32 & 27\\ 35 & 28 & 26\\ \end{matrix} \right| R1=R∗k= 146130124132119115118112111 ∗91 111111111 =91 146130124132119115118112111 ,G1=G∗k= 755953604743494342 ∗91 111111111 =91 755953604743494342 ,B1=B∗k= 574135453228332726 ∗91 111111111 =91 574135453228332726
- 再将乘积结果相加,得到的值为输出图像中的目标像素值
R 2 = 1 9 ( 146 + 132 + 118 + 130 + 119 + 112 + 124 + 115 + 111 ) = 123 G 2 = 1 9 ( 75 + 60 + 49 + 59 + 47 + 43 + 53 + 43 + 42 ) = 52 B 2 = 1 9 ( 57 + 45 + 33 + 41 + 32 + 27 + 35 + 28 + 26 ) = 36 R_2=\frac{1}{9}(146+132+118+130+119+112+124+115+111)=123\\ G_2=\frac{1}{9}(75+60+49+59+47+43+53+43+42)=52\\ B_2=\frac{1}{9}(57+45+33+41+32+27+35+28+26)=36 R2=91(146+132+118+130+119+112+124+115+111)=123G2=91(75+60+49+59+47+43+53+43+42)=52B2=91(57+45+33+41+32+27+35+28+26)=36
- 目标像素RGB值为:
R G B = ∣ 123 52 36 ∣ RGB=\left|\begin{matrix} 123\\ 52\\ 36\\ \end{matrix} \right| RGB= 1235236
我们对比图像中显示的RGB和我们计算出来的一致。所以卷积在图像处理中操作可以用于考虑周围像素对中间像素的影响,根据周围像素的值来计算计算中间像素的值,从而实现图像模糊的效果,降低图像噪点。
4.3.5 卷积提取图像特征
前面我们学习了考虑周围像素对中间像素的影响的卷积可以去实现一些对图像的处理,那么卷积又是如何实现特征提取的呢?
以下示例来源国外作者Charles Crouspeyre的《卷积神经网络是如何工作的?》
假设我现在需要识别下面黑白图像中的是X还是O,由于图像中的X和O处于不同位置,如果通过我们人眼是可以判断出对应图像里的是X和O的。

如果电脑去判断两张X图像,其中X的位置不同,如果使用传统的方法比较图像中的元素值,可以电脑就可以得出,两张图像不一致,且无法判断图像中有X。

所以我们需要使用卷积神经网络来对这些图像处理,就可以知道传入的图像是X还是O,那么卷积神经网络中的卷积是如何处理这些图像的?
在开始前我们先观察这两张图像中有哪些相同特征,我们可以看到他们两个有些局部特征是相同的,如下图中红黄蓝框所示:

可以看到这些局部特征是有相似的,下面根据这些局部特征,我们创建三个3*3的卷积核,如下所示:

可以看到这个特征可以和图像X中特征对应上,如下图所示:

那么现在我使用第一个卷积核来进行卷积操作,计算如下图中绿框位置,卷积后的值输出在下图中右边黄色框中。

继续使用与上图相同的卷积核,计算下图中绿框位置,卷积后的结果输出在下图中右边黄色框中。

计算完成后得到卷积后的图像矩阵图下图所示:

我们可以看到一个现象,经过这个卷积核之后会,卷积结果图像得到的特征是一条从左上到右下的对角线,他与图像中X的从左到右向下的对角线相匹配,所以我们可以看到在结果图像中所有高的值,都在这条对角线上,这条对角线与卷积核的匹配比其他地方与卷积核的匹配的匹配更好。
那么下面我们分别来看三个卷积核后的卷积结果,如下图所示:



用中间的X卷积核和从斜向上的卷积核,经过卷积后得到特征出现的位置和我们期望的特征是一致的,也就是说可以提取到原图像中X的特征值。那么在神经网络中使用一堆卷积核对图像进行处理并提取特征,这就称为卷积层。

通过上图我们又可以看出一个规律,假设输入图像为X,卷积核为w,偏置为b,那么卷积输出的结果为Y,则有:
Y
=
X
⋆
w
+
b
,其中
⋆
为卷积操作
Y=X\star w + b,其中\star为卷积操作
Y=X⋆w+b,其中⋆为卷积操作
上述式子中卷积核W和偏置b是可学习的参数,即:可通过训练改变的参数。
4.3.6 一维卷积和二维卷积
我们已经知道卷积的作用,那么如何使用pytorch深度学习框架来实现卷积操作?
一维卷积实现
下面是使用pytorch实现的一个例子,展示一维的tensor经过一维卷积后的结果矩阵。
import torch
from torch import nn
#设置卷积函数,输入通道为1,输出通道为1,核函数大小为3,步长为3,偏置为0
conv1 = nn.Conv1d(in_channels=1,out_channels=1,kernel_size=3,stride=3,bias=0)
input = torch.Tensor([[1,2,3,4,5,6,7,8,9]])
print(input)
nn.init.constant_(conv1.weight, 1)#核函数参数设置为1
print(conv1)
output = conv1(input)
print(output)
输出结果:
输出信息为:
tensor([[1., 2., 3., 4., 5., 6., 7., 8., 9.]])
Conv1d(1, 1, kernel_size=(3,), stride=(3,), bias=False)
tensor([[ 6., 15., 24.]], grad_fn=<SqueezeBackward1>)

二维卷积实现
下面是使用pytorch实现的一个例子,展示二维的tensor经过二维卷积后的结果矩阵。
import torch
from torch import nn
#设置卷积函数,输入通道为1,输出通道为1,核函数大小为3,步长为1,偏置为0
conv2 = nn.Conv2d(in_channels=1,out_channels=1,kernel_size=3,stride=1,bias=0)
input = torch.Tensor([[[1,1,0,0,1,1],[0,0,1,0,1,0],[0,1,1,1,0,0],[0,1,0,0,1,1],[1,0,1,1,0,0],[1,1,1,0,0,1]]])
print(input)
nn.init.constant_(conv2.weight, 1)#核函数参数设置为1
print(conv2)
output = conv2(input)
print(output)
输出结果:
tensor([[[1., 1., 0., 0., 1., 1.],
[0., 0., 1., 0., 1., 0.],
[0., 1., 1., 1., 0., 0.],
[0., 1., 0., 0., 1., 1.],
[1., 0., 1., 1., 0., 0.],
[1., 1., 1., 0., 0., 1.]]])
Conv2d(1, 1, kernel_size=(3, 3), stride=(1, 1), bias=False)
tensor([[[5., 5., 5., 4.],
[4., 5., 5., 4.],
[5., 6., 5., 4.],
[6., 5., 4., 4.]]], grad_fn=<SqueezeBackward1>)
二维卷积实现过程

4.4 池化层
4.4.1 最大池化与均值池化
池化层(pooling)又称为下采样层,池化层的卷积核只是对应位置的最大值和平均值。池化与卷积操作不同主要表现在矩阵运算规律的差异。其主要功能是保持特征不变性,包括平移、旋转和尺度。利用池化进行特征降维,降低了卷积层对冗余信息的敏感性,提取了重要特征值。
池化层的每一次操作都是对输入图像数据,利用一个固定形状窗口中的元素的计算输出,其中该运算有最大池化和平均池化。
最大池化是在二维中的最大池化,窗口从输入数组的左上角开始,按照从左到右和从上到下的顺序向下滑动。当最大池化窗口滑动到某个位置时,窗口中输入子数组的最大值是输出数组中相应位置的元素。
均值池化是池化特征图的局部感受,当池化平均窗口滑动到某个位置并返回其集合平均时,窗口中输入子数组的平均值是输出数组中相应位置的元素。池化操作过程如图所示。


4.4.2 卷积网络中的最大池化
我们回到3.3.5中的例子,我们已经经过卷积之后提取到原图像中X的特征值,如下图所示:

那么下面我们对着卷积提取的特征图像进行最大池化(Max Pooling)操作,如下图所示:

可以看到经过最大池化后我们得到了一个更小的图像,但是图像中仍然保存这卷积提取的特征值在特征图像的对角线上。也就是我们将原本7*7的特征图像,降维为4*4的特征图像,大小只有原来的一半。
小思考:如果我们的图像比较大,分辨率比较高,那么卷积操作提取特征之后,图像尺寸还是很大,那么这很不利于我们部署在一些嵌入式设备中,这种图像像素缩小,还能保存特征的方式是十分有用的。
如果你想寻找图像中的特征,它可能会向左一点或者向右一点,或者旋转一点,但特征依然可以被提取,可以对所有的经过卷积的图像进行最大池化,可获得卷积之后的更小的特征图像。


4.5 RELU 激励层
4.5.1 线性整流激活函数
RELU激励层,也称非线性激活层。 RELU激励层使用线性整流激活函数,该函数可以保留大于0的值,即保留特征比较好的值,将特征小于0的值舍去。
下面展示线性整流函数(Rectified Linear Unit)的函数公式:

relu函数图像为:

ReLU激活函数的主要优点是:
•卷积层和深度学习:它们是卷积层和深度学习模型训练中最常用的激活函数,可以使网络有非线性表达,增加网络拟合能力。
•计算简单:整流函数实现起来很简单,只需要一个max()函数。
•代表性稀疏性:整流器函数的一个重要优点是它能够输出一个真正的零值。
4.5.2 卷积网络中的RELU层
RELU函数由于其导数在正区间且恒为1,可以避免梯度的随着网络层数的增加而消失的问题,所以我们在网络层的任意位置都可以使用它作为激活函数。我们回到4.3.5中的例子,我们已经经过卷积之后提取到原图像中X的特征值,我们对卷积提取的特征值使用RELU激活函数处理,如下图所示:

通过上图我们看到RELU激活函数就是遍历图像中的所有负值的像素,将所有负值都变为0。当经过一次激活函数后会得到一个原来十分相似的图像。对所有图像都经过RELU激活函数处理后,即为RELU层

下面我们将卷积层、RELU层、池化层叠加使用,可得到如下所示结构:

我们用过上图了解到,图像输入卷积后,输出的卷积结果,传给RELU层进行处理,RELU层输出的结果,传给Pooling层进行池化操作,最后输出。多层网络的规律就是一个层的输出作为下一个层的输入。那么下面我们再次对网络进行堆叠,建立更多层的卷积层、RELU层、池化层,如下所示,对网络层进行深度堆叠。

当然,如果您的图像尺寸比较大,你还可以进行堆叠,堆叠成一个更多层的网络。每次图像经过卷积层之后都会获得特征图像,随着卷积层和池化层的层数增加,特征图像也会变得越来越小。
4.6 全连接层
4.6.1 全连接层核心公式
全连接层(full connection)是把每个结点连接到上层的所有结点,以合成从前端层提取的特征,并接受图片特征值的输入,进行训练,训练完成后就可对输入的特征值进行分类。
全连接的核心公式为:
f
(
x
)
=
W
∙
x
+
b
f(x)=W∙x+b
f(x)=W∙x+b
其中:x为全连接层的输入矩阵,W为权重系数,b为偏置。
4.6.2 卷积网络中的全连接层
在卷积神经网络中,经过了卷积层、RELU层、池化层的特征提取后,最后一层网络需要使用到全连接层。以4.5.2中经过深度堆叠后的特征图像,经过全连接过程如下所示:

将现在经过多次过滤且尺寸大大减小的图像特征,分解出来并重新排列,放入一个列表中,对结果进行计算。可以把全连接形象的理解为,特征值中的每一个值就是一个人,原来特征值是排成方阵形式的,现在将他们一个一个拎出来,排成一排。让每一个人去对类别X和O进行投票,每个人都可以对X和O进行投票。
当我们输入图像含X时,每一个人为类别X的获得更多的票数,也就是说他们更倾向于这张图像是X图像。
当我们输入图像含O时,每一个人为类别O的获得更多的票数,也就是说他们更倾向于这张图像是O图像。
如果我们通过训练得到了全连接中合适的权重和偏置,如果我们的网络得到了一个新的输入图像,那么此时就会根据卷积池化RELU得到的结果,再次进行投票,如下所示:

我们再次对X和O进行投票,最终我们可以通过观察那个票数高,来判断输入的图像是X还是O。
当然,我们也可以像卷积、池化、RELU一样,可以叠加很多层,类似于下图所示:

所以我们的卷积神经网络可以设计成下图这样,经过卷积、池化、RELU后经过两层的全连接层,最终投票输出X和O的概率。

4.6.3 分布式特征映射
全连接层利用分布式特征表示将特征值映射到样本标记空间中,具体步骤简图如下所示:
(全连接层是把特征表示整合到一起,输出为一个值)
假设下面以一个检测人脸和猫的网络的简图,其中就演示了全连接神经网络,就是特征整合成一个值,这个值越大就证明检测的图像中有人脸或有猫,不论其在图像中的位置。

全连接层在整个网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数等操作是将原始数据映射到隐层特征空间的话(特征提取+选择的过程),全连接层则起到将学到的特征表示映射到样本的标记空间的作用。换句话说,就是把特征整合到一起(高度提纯特征),方便交给最后的分类器或者回归。
4.7 训练与超参数
我们了解了卷积神经网络中的卷积层、池化层、全连接层,下面我们来看他们在整个卷积神经网络中的作用。

前面我们讨论了卷积神经网络中的卷积、池化、RELU、全连接是如何提取特征,并把特征输出出来。这就需要有合适的权重和偏置值等需要通过训练找到合适参数。那么训练是如何更新参数的呢?这里就需要用到前面我们学习了的反向传播算法,反向传播就是利用全连接层最后输出的预测结果,计算误差来确定网络的调整和变化程度。
E
r
r
o
r
=
(
p
r
e
d
i
c
t
v
a
l
u
e
)
−
(
a
c
t
u
a
l
v
a
l
u
e
)
误差
=
(
预测值
)
−
(
真实值
)
Error = (predict\quad value) -(actual\quad value)\\ 误差 = (预测值) - (真实值)
Error=(predictvalue)−(actualvalue)误差=(预测值)−(真实值)
例如,我们如果得到的3.6.3中的预测概率X和O分别是0.93和0.35,我们已知正确值X和O应为1和0,那么我们就有以下表格:
| predict value | actual value | Error | |
|---|---|---|---|
| X | 0.93 | 1 | 0.07 |
| O | 0.35 | 0 | 0.35 |
| Total | 0.42 |
使用梯度下降法获得最低误差,如下所示:

在不断训练中去调整卷积核、全连接权重等参数,看看误差如何变化,调整的量取决于有多大的误差;误差越大调整越大,误差越小调整的越小。就像小球在山上找下山的路一样,小球想沿着这个斜坡走下去,也就是沿着梯度找到最底部,因为最底部是误差最小的时候。
超参数是在网络开始学习过程之前设置值的参数,我们来看一下卷积神经网络中的超参数有哪些:
-
卷积层Convolution
- 卷积核的数量
- 卷积核大小
-
池化层Pooling
- 池化窗口尺寸
- 池化步长
-
全连接层Fully Connected
- 隐藏层神经元数量
下面展示一个卷积神经网络的交互式节点连接可视化网站:https://adamharley.com/nn_vis/

5.模型及部署
5.1 模型
我们有了网络结构,那么这里就需要继续引入一个概念 模型 。
什么是模型?在人工智能中,模型本质就是一个函数。而这个函数是通过我们大量的数据给到机器中,机器通过不断的迭代找出一个满足我们提供的数据的函数,可以根据这个函数去预测新数据所对应的结果。通过上面介绍的几种基本的算法,就是在数据的基础上创建机器学习的模型的过程。

模型=参数+架构+算法。
参数是什么?在上文我们已经提及,我们在神经网络中从输入层传输到隐含层的权重、偏置都算是参数,这就是模型中可训练的参数。

架构是什么?创建了两个不同架构的神经网络,相同的数据集使用不同的架构也会产生不同的预测函数,所以架构也构成模型的重要组成。

算法是什么?我们创建的模型里存储的目标函数,那么怎么去求解该目标函数的方法就称为算法。就例如在解决机器学习过程中的损失函数的求解就有:最小二乘法、牛顿法、阻尼牛顿法等。激活函数的选择:Sigmoid函数、双曲正切激活函数、ReLU激活函数等。这些就是需要选择符合你数据集的的算法。

5.2 模型的部署
模型的部署分为云端部署和边缘部署。
云端部署主要是在中心服务器中训练的引擎库,边缘部署是在主机设备中进行数据的处理和模型推理,生成模型后打包进SDK包中,编译后集成到嵌入式设备里。
在前几年的时候,嵌入式设备只能利用CPU执行简单的AI任务或者将数据发送到云端服务器,使用云端服务器接收到申请后,将数据使用服务器端的模型进行推理,推理结果返回给嵌入式设备进行进一步处理。
随着芯片技术的发展,嵌入式设备的算力增加使得可以将模型部署到嵌入式设备中,不需要将数据发送到云端来运行模型;嵌入式设备采集数据,直接运行模型进行推理,再将推理结果返回用作某项任务的一部分。采集的数据也可暂时存储到设备中,后者发送到云端进行存储。
嵌入式AI中数据的采集和分析推理都在本地,可以降低数据传输的成本和保证数据的安全以及推理决策的实时性。所以为了保证实时性我们的模型需要在指定设备中推理运行。
6.边缘部署
6.1 部署硬件GPU/FPGA/ASIC
随着人工智能的发展,21世纪开始,对算力的需求也越来越高。人工智能的体系分为基础层,技术层和应用层,其中最底层的就是基础层的算法处理芯片,需要使用它来提高最基础的算力,传统通用CPU处理器算力不足,主要来源于GPU/FPGA/ASIC等AI芯片所提供的算力,下面我们就针对这三种不同的AI芯片进行讨论。
6.1.1 图形处理单元GPU
**图形处理单元(GPU)**其实是从中央处理器(CPU)演变而来的,原本是专为3D图形渲染的并行计算而设计的。在计算机早期,CPU是需要负责图形应用程序所需要的计算的,例如渲染2D和3D图像,动画视频等,但随着图形密集型应用程序的增多,给CPU带来了很多压力,导致整个计算机的性能下降,为了帮助CPU减轻压力,把图像相关的应用程序转移出来,所以GPU就应运而生,专门用于快速并行的执行图形相关的计算。
GPU通常包括多个处理器,每个处理器有一个共享内存,外加多个处理器和对应的寄存器,支持大规模并行处理,每个内核都专注于高效计算。CPU可以认为是整个系统的监工,协调通用的计算任务,而GPU执行的是更专业的任务(通常为数学任务)。CPU和GPU的架构简图如下所示:

注意:越靠近核心的缓存速度越快
在一些嵌入式设备中也有独立的GPU,也可以流畅的渲染3D图形和视频,例如手机,机顶盒。广告机等设备,GPU可以快速的在显示屏上呈现内容。现代GPU已经适应比最初设计的图形任务范围更广的任务,因为目前GPU比过去更具有编程性,目前GPU还能用于机器学习/训练深度学习神经网络/图像识别/视频游戏/视频编辑内容创造等工作。下面我们来展示GPU是如何工作的,为什么GPU可以加速图形和神经网络任务?
在学习GPU如何工作前,我们需要知道并行计算是什么?并行计算是一种计算类型,其中特定的计算被分解成可以同时执行的独立的较小的计算,最后将计算结果重新组合或者同步。也就是说将原来一个比较大的运算任务分解成多个任务进行运算,任务的数量取决于核心的数,在硬件核心上的单元就是GPU中的处理器单元,在GPU中通常有数千个核心进行运算。

如果计算可以支持并行计算的任务,我们就可以使用并行编程方法和GPU加速我们的计算。
下面我们以GPU渲染3D模型为例,3D模型可以可以由许多小三角形组成,如下图所示:

你可以想象一下,如果想让这个兔子像视频一样变得能动,那么就需要为每个小三角形的三个角的坐标值进行计算,假设每个角都使用X,Y,Z坐标来表示,如下图所示制作三角形来组成模型就需要制作三个顶点的坐标值,当然如果你的模型是由一个个正方形组成亦是如此,可能是由四个顶点组成。我们这一小节主要针对三角形构成的模型进行讨论,三角形的三个顶点可以在各个三角形之间共享,那么如果你的模型有1000个三角形,那么可能就不需要3000个顶点来组成模型。

回到我们的一开始说的,如果我们需要让这个兔子动起来,我们就需要将这一个个三角形进行平移/旋转/缩放等操作,这些操作统称为变换。
在现实3D图形中,使用数学的方式表达XYZ坐标的最佳方式就是使用向量的方式进行表达,如果想对向量进行变换操作,最简单的方式就是使用矩阵运算的方式,将原来的坐标乘一个3*3的矩阵,例如:

你可以看到矩阵的每行都有不同的属性值,你只需要使用特定的预先定义好的矩阵进行相乘后即可对这个小三角形进行平移/缩放/旋转等操作,所以要使得能很轻易的让那么多个小三角形进行变换,那么GPU需要十分擅长矩阵运算,并且支持大量的矩阵运算。

从上图中,我们看到我们需要将这些矩阵数据加载到内存中,加载后,GPU会同时访问内存并运输大量的矩阵块数据。核心在处理当前矩阵块数据时,它从系统内存中获取了更多的块,所以GPU永远不会空闲。GPU获取了一块矩阵块后会交给GPU计算完成完成还需要使用着色器对每个小三角形都填充颜色,当然这个由GPU渲染器来完成的。

如果对于是大矩阵的运算,GPU则会取一部分一部分的取出大矩阵的数据进行计算,我们就以两个大矩阵相乘的例子来看GPU是如何进行计算优化的。假设存在两个4*4的矩阵A和B,将矩阵A和矩阵B相乘,乘积结果使用C进行保存。如下所示:

我们可以将这个4*4矩阵分块,拆分成2*2的块矩阵,那么乘积结果C就等于两个2*2的块矩阵相乘,最终计算出矩阵块的乘积结果。我们就重点来看C矩阵是如何在GPU上实现并行计算的。我们就3个核心的GPU为例,如下图所示:

我们先来计算C11的块矩阵元素,我们可以将子矩阵块A11,B11从L2缓存中取出,放到L1缓存中,SM-1核心对获取的数据进行运算,将乘积结果放到共享内存SMEM中,将A12和A21从L2缓存中取出,放到L1缓存中,SM核心对获取的数据进行运算,将乘积结果放到共享内存中。最后从共享内存中取出两个乘积结果进行求和就可以得出完整C11。同时我们可以使用其他SM核心并行的计算这些子矩阵块,最终计算完矩阵中的不同的块矩阵的数据,从而得到整个C矩阵的数据。
我们用更多的内存带宽将数据块从系统内存提取到GPU中的缓存中,使用多处理器来并行的处理。那么对于大矩阵块的乘法,我们就需要知道一些超参数,也就是我们怎么每次取的块大小是多少?需要使用多少个核心进行处理,以及使用哪一个核心进行处理?

CUDA就可以负责确定这些超参数,同时如果我们需要使用GPU对我们的矩阵运算进行加速,使用CUDA即可完成。
CUDA是 NVIDIA 专为图形处理单元 (GPU) 上的通用计算开发的并行计算平台和编程模型。借助 CUDA,开发者能够利用 GPU 的强大性能显著加速计算应用。
在经 GPU 加速的应用中,工作负载的串行部分在 CPU 上运行,且 CPU 已针对单线程性能进行优化,而应用的计算密集型部分则以并行方式在数千个 GPU 核心上运行。使用 CUDA 时,开发者使用主流语言(如 C、C++、Fortran、Python 和 MATLAB)进行编程,并通过扩展程序以几个基本关键字的形式来表示并行性。
那么回到我们的问题为什么在深度学习中我们经常需要使用GPU设备呢?
因为在神经网络中进行的许多计算可以很轻易的分解为多个彼此独立的较小计算任务。例如我们前面学习的卷积运算:

我们通过前面学习的卷积过程就可以知道,我们每次运算都是独立于其他计算的,所以我们可以发现每次卷积计算都不会依赖其他计算的结果,因此所有这些独立的卷积计算都可以在GPU上并行的运算,并且整个输出通道可以在整个计算完成后生成,所以我们就可以使用并行计算方法在GPU上加速卷积运算。

6.1.2 现场可编程门阵列FPGA
现场可编程门阵列 (FPGA) 是一种半导体集成电路,它基于通过可编程 互连 连接的可配置逻辑块 (CLB) 矩阵。FPGA 可以在制造后根据所需的应用或功能要求进行重新编程。FPGA中芯片的逻辑单元是可以通过编程的方式改变,同时逻辑单元的连接也是可以改变的。
FPGA的基本结构包括可编程输入输出单元,可配置逻辑块,数字时钟管理模块,嵌入式块RAM,布线资源,内嵌专用硬核,底层内嵌功能单元。编程语言有VHDL/Verilog等。
下面我以一个简单的神经网络为例,带大家来看FPGA上是如何加速神经网络的,如下图所示:

下面根据这个神经网络中来设计一个逻辑电路,那么我们先编写一个框图,展示神经网络的参数,如下所示

可以看到我们主要是实现隐藏层和输出层的四个神经元,那么我们来看如果FPGA中如何实现单个神经元的逻辑电路如下所示:

对于一个神经元,我们有三个输入信号x_1,x_2,x_3,输入信号的的权重w_1,w_2,w_3,对它们两个进行相乘;将乘积结果相加起来,并且加上偏置值。将最终的输入信号和传入ROM中,我们在ROM(只读存储器)中存储了sigmoid激活函数,经过ROM中的激活函数处理后输出最终的值。我们就根据原来的神经元模型在FPGA上使用VHDL设计对应的逻辑电路。那么对于神经网络,FPGA的逻辑电路就可以设计成这样,我们将神经网络的结构映射成硬件的结构。如下图所示:

下面我们来看一下FPGA的优缺点。
优点:
-
加速深度学习推理: FPGA可以通过硬件加速深度学习推理任务,提高模型的性能和效率。深度学习模型通常需要大量的计算资源,FPGA的并行计算能力使其成为加速推理任务的理想选择。
-
**灵活性和可编程性:**FPGA具有可编程性,允许用户根据特定需求设计和实现定制化的硬件加速器。这种灵活性使得FPGA适用于各种不同的人工智能应用,包括图像识别、语音处理和自然语言处理等。
-
低功耗: 相对于传统的通用处理器,FPGA通常具有较低的功耗。这对于在嵌入式系统和移动设备等资源受限的环境中使用人工智能技术是非常重要的。
-
实时处理: FPGA可以提供实时性能,适用于需要即时响应的应用,如自动驾驶、智能摄像头和物联网设备等。
-
加速算法和模型优化: 利用FPGA的并行性和硬件加速能力,可以对人工智能算法和模型进行优化,加速训练和推理过程,提高整体性能。
缺点:
-
复杂性: FPGA的设计和编程相对复杂,需要专业的硬件设计和编程技能。
-
成本: FPGA通常相对昂贵,尤其是高性能和大规模的FPGA。这可能成为一些项目和应用采用FPGA的障碍,尤其是在预算受限的情况下。
-
功耗波动: 虽然相对于某些通用处理器,FPGA具有较低的功耗,但在某些情况下,由于FPGA的可编程性和灵活性,其功耗可能难以精确估计,导致功耗波动。
-
相对固定的硬件资源: FPGA的硬件资源是有限的,并且通常是相对固定的。这可能导致在处理某些大规模或复杂的人工智能任务时,资源不足的问题。
-
**编译使用:**工具链的质量参差不齐,一次编译的时间较长。
6.1.3 专用集成电路ASIC
专用集成电路是为特定任务或应用定制设计的集成电路 (IC)。与FPGA板不同,FPGA板在制造后可以进行编程以满足各种用例要求,而ASIC设计是在设计过程的早期进行定制的,以满足特定需求。两种主要的ASIC设计方法是门阵列和全定制。ASIC由IC设计人员根据特定的电路需求,设计专用的逻辑电路,在设计完成后生成设计网表,交给芯片制造厂家流片。在流片之后,内部逻辑电路就固定了,芯片的功能也就固定的。通常ASIC芯片可用于通信(通信芯片)/汽车电子(电机芯片)/航天航空(导航/飞行控制芯片)等。
在深度学习领域,ASIC专门针对深度学习任务的集成电路被称为硬件加速器,可提高深度神经网络的推理和训练速度,并在相同时间内降低功耗。深度学习ASIC的电路结构和功能经过专门优化,以满足深度学习任务的计算需求。这种硬件优化可以提供高度并行计算、特定网络架构的支持以及其他深度学习运算的硬件加速。
ASIC中最有标志性的就是Google TPU,它是由谷歌设计的专用硬件加速器,用于机器学习和深度学习任务。TPU的设计目标是提供高性能和高效能的硬件,以加速谷歌云平台上的机器学习工作负载。并且其对TensorFlow框架具有很好的兼容性,使得在TensorFlow上训练和部署模型时能够充分发挥TPU的性能优势。
目前国内外在做ASIC的厂商有:国外的谷歌/英伟达/英特尔/AMD等,国内的华为/全志/瑞芯微/地平线/寒武纪/嘉楠/比特大陆/芯原等。
在深度学习的ASIC设计中,一些硬件加速器采用了类似于脉动阵列(systolic array)的结构,以实现高度并行的计算。它就是利用多个小型计算核心并行执行矩阵乘法等操作,以提高性能。对于这种ASIC的计算单元主要是由计算单元PE阵列组成,通常以规则的二维或三维排列,形成一个紧凑的网格结构。这有助于实现高度的并行计算。如下图所示:

下面我以一个两个矩阵相乘的例子来看,脉动阵列是如何对矩阵运算进行加速的。
C
=
A
∗
B
=
[
a
11
a
12
a
13
a
21
a
22
a
23
a
31
a
32
a
33
]
∗
[
b
11
b
12
b
13
b
21
b
22
b
23
b
31
b
32
b
33
]
C
11
=
a
11
∗
b
11
+
a
12
∗
b
21
+
a
13
∗
b
31
C
12
=
a
11
∗
b
12
+
a
12
∗
b
22
+
a
13
∗
b
32
C
13
=
a
11
∗
b
13
+
a
12
∗
b
23
+
a
13
∗
b
33
.
.
.
C
33
=
a
31
∗
b
13
+
a
32
∗
b
32
+
a
33
∗
b
33
C
=
A
∗
B
=
[
c
11
c
12
c
13
c
21
c
22
c
23
c
31
c
32
c
33
]
C=A*B= \left[\begin{matrix} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \\ a_{31} & a_{32} & a_{33} \\ \end{matrix} \right] * \left[\begin{matrix} b_{11} & b_{12} & b_{13}\\ b_{21} & b_{22} & b_{23} \\ b_{31} & b_{32} & b_{33} \\ \end{matrix} \right] \\ C_{11}= a_{11}* b_{11} + a_{12}*b_{21} + a_{13}*b_{31}\\ C_{12}= a_{11}* b_{12} + a_{12}*b_{22} + a_{13}*b_{32}\\ C_{13}= a_{11}* b_{13} + a_{12}*b_{23} + a_{13}*b_{33}\\ ...\\ C_{33}= a_{31}* b_{13} + a_{32}*b_{32} + a_{33}*b_{33}\\ C=A*B=\left[\begin{matrix} c_{11} & c_{12} & c_{13}\\ c_{21} & c_{22} & c_{23} \\ c_{31} & c_{32} & c_{33} \\ \end{matrix} \right]
C=A∗B=
a11a21a31a12a22a32a13a23a33
∗
b11b21b31b12b22b32b13b23b33
C11=a11∗b11+a12∗b21+a13∗b31C12=a11∗b12+a12∗b22+a13∗b32C13=a11∗b13+a12∗b23+a13∗b33...C33=a31∗b13+a32∗b32+a33∗b33C=A∗B=
c11c21c31c12c22c32c13c23c33
我们先来看我们如果需要进行两个矩阵乘法,需要进行多少次运算,可以看到我们求出一个矩阵C中的一个元素c11需要进行5次乘法和加法运算,矩阵C中总共有9个元素需要求,那么总共需要45次运算。那么如果使用ASIC芯片,并且使用脉动阵列中的计算单元来看一下是如何优化矩阵乘法。如下图所示:


下面我们对上图中的展示上图中脉动阵列的计算流程进行说明:
-
将A矩阵放在计算单元PE阵列中,将B矩阵放在输入的位置。
-
将输入数据往右移一列,将矩阵B的数据传入计算单元PE阵列中,与计算单元中的元素作乘法运算。
-
将输入数据再往右移一列,再次进行矩阵乘法运算。将上一次计算的结果往下移一行,对计算单元的元素进行加法计算。
-
重复将数据往右移计算乘积结果,往下移计算加法结果,直到将所有数据计算完成。
我们可以看到如果使用脉动阵列的方式进行矩阵乘法运算,我们可以快速减少计算步骤和所需时间。我们经过上述方法可以将整个输出矩阵C的结果放到输出里面了。可以看到我们的矩阵A的尺寸和脉动阵列的尺寸是一致的,才能保证进行乘法运算的结果正常运算,那么对于一般的矩阵乘法(尺寸可能和阵列不一致),可以通过分块或者填充来匹配阵列的尺寸大小。
对于sigmod/RELU等激活函数,脉动阵列无法实现的功能,可以使用其他硬件单元来实现。
6.2 嵌入式模型部署
从零到最后嵌入式模型部署流程是准备数据集、数据预处理、数据标注、选择算法、训练、调整参数、生成模型、边缘部署。
①准备数据集包括文本数据、图像数据、音频数据等,图像数据中有包括数字数据集、人脸数据集、人形数据集、道路数据集等。
②数据预处理,主要是为了检查、修正、删除在数据集中不适用于模型的数据。常见的方法是:特征缩放、缺失值处理、异常值处理、数据转换等。
③数据标注,对于图像数据,对目标物体进行画框,导出其在图像中的位置。对于音频数据,对时间轴上标注出音标或者特定词等。
④选择算法,我们需要根据数据集来选择算法如:文本的检测算法、分类算法等;图像的目标检测算法、人脸检测算法、人形检测算法等,音频的语音识别算法、语音合成算法等。
⑤训练后生成模型,评估模型后修改模型或参数,直至模型达到最优的效果。
⑥模型部署,使用AI芯片中的神经网络处理单元进行模型的推理。
6.3 嵌入式AI芯片
目前主流的嵌入式AI芯片做法都是将AI模块嵌入到定制的SOC中,允许芯片架构针对特定的计算应用进行优化。一般都是多个核心放在单个SOC上,现实中很多AI芯片的做法都是多核异构,即采用多个核心,且不同架构。
嘉楠公司的K510含有三核 RISC-V 处理器和KPU通用神经网络引擎;
全志公司的V853含有Arm Cortex-A7@1GHz 、E907@600MHz和NPU神经网络处理器;
英伟达公司的jetson nano含有四核Arm Cortex-A57主核、28核Maxwell架构GPU图形处理单元;
下图为嘉楠K510芯片架构图,可以从红框中为该芯片为CPU+ASIC架构。

下图为全志V853芯片架构图,可以从红框中为该芯片为CPU+ASIC架构。

6.4 边缘部署流程
边缘部署的流程包括模型转换、量化压缩、打包封装。
6.4.1 模型转换
模型转换是由于我们训练和推理的设备不一致,用于连接不同框架的模型。由于目前许多开源算法都要自己的模型格式,主流的做法是将原本的模型转换成onnx或Caffe的格式,再转换成AI芯片所要求的格式。
例如对于yolov5目标检测算法,嘉楠公司的K510的模型格式转换流程为:pt->onnx->kmodel ;
全志公司的V853芯片的模型格式转换流程为:pt->onnx->nbg。
英伟达公司的jetson nano的模型格式转换流程为:pt->onnx->tensorRT 。
其中pt格式是pytorch的模型格式,onnx格式是开放神经网络交换格式,用于表达深度学习的模型标准,可使模型在不同框架之间进行转移。Kmodel格式是嘉楠公司的KPU所用的文件格式。nbg为芯原公司的NPU所用的文件格式。 tensorRT为英伟达公司所用的文件格式。

6.4.2 量化压缩
为了缩小模型,我们常使用量化压缩,它是由于在卷积神经网络中为了追求更好的精度,常会采用浮点float-32,这导致参数量、计算量、占用内存都会变得很大,为了减小模型存储和内存占用、压缩参数、提高速度使得可以部署到资源较少的嵌入式设备中,需要转换成int整型。

减小了模型所占用到的资源,模型的精度也会下降,但如果要使量化后的模型可以落地使用就需要将量化后的精度损失降低到可接受范围内,同时还需要保证部署后的速度、资源占用率和能耗。

非对称模式是不以0为中心点,以所有参数的中间值为中心点,将整个模型中的所有参数等比例映射到0-255范围内。
对称模式是以0为中心点,将整个模型中的所有参数等比例映射到0-255范围内。
参考资料:神经网络量化白皮书
6.4.3 打包封装
打包封装是指将模型文件、模型的前处理和后处理、模型推理等打包供嵌入式设备中的应用程序使用。
在了解前处理和后处理之前,我们来回顾一下模型的输入内容和输出内容。

模型的输入是以声音/图像/文本,进行模型推理后,输出的数据也是由模型本身确定的输出的数据内容,输出内容可以是函数的参数、tensor特征向量、格式化文本。
6.4.4 端侧推理
①前处理是指由于模型的输入是由模型本身确定的,有些会以多维矩阵(Tensor)的数据作为输入,但嵌入式设备采集的数据一般为图像格式、音频格式和文本格式等,如果想将数据推入模型中进行推理需要根据模型的输入要求,将采集数据的格式转换为多维矩阵,或不进行处理直接将数据输入模型。
②模型推理是`指将转换后的多维矩阵在转换成特定格式的模型上运行,输出的多维矩阵可以满足精度、性能等需求。例如英伟达公司的jetson nano转换后的模型使用TensorRT引擎进行推理;嘉楠公司的K510转换后的模型使用nncase框架进行推理。全志公司的V853转换后的模型使用芯原VIPLite引擎进行推理。
③后处理是指将推理后的处理结果(参数/多维矩阵/格式化文本)进行处理或者解码,转化为嵌入式设备输出给外设的图像特征、音频特征或文本特征等。