一、案例文件
同样使用上节课的银行贷款案例,其文件内容大致如下:(共28万多条,31列)


现在要继续接着上节课的内容对模型进行优化
二、下采样流程
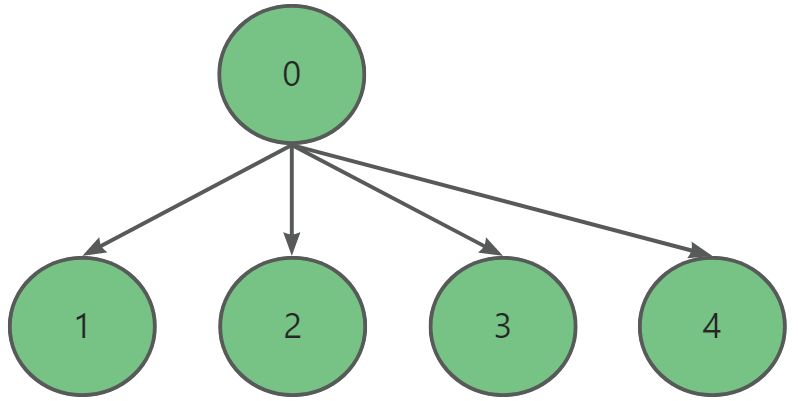
1、流程图示

2、具体流程介绍
1)切分原数据集
大量数据的文件data,其中有28万多条数据类别为0类的和480多条数据类别为1类的,对这28万多条数据随机取出和类别为1的数目相同条数的数据
data1 = a.sample(len(b)) # 使用sample方法,从a数据集中切出长度等于b的数据,将得到的数据赋值给data12)合并数据集
将取出的480条数据和原先类别为1的数据合并,得到一个小数据集data_c,共480x2条数据
# 使用pandas中的concat合并两个数据集
data = pd.concat([train_1,train_2])3)切分合并的数据集
对这960条数据随机取样取出其中的百分之20当做测试集test,百分之80当做训练集train
4)k折交叉运算
再对这个训练集进行k折交叉验证得到最优的C值,然后在建立模型,导入最优C值,再对这个训练集train进行训练
c = [0.01,0.1,1,10,100]
for i in c:
model = LogisticRegression(C=i)
score = c(model,x_train,y_train,cv=8,scoring='recall') # 使用模型model对数据集进行8折交叉运算
print(score)
5)导入数据进行测试
把小数据集分出来的百分之20的测试集导入模型,对其进行预测,来观察其召回率以及精确率情况,小数据集测完再去对将原始数据随机取出百分之20的数据当做测试集,再输入模型对其预测
model = LogisticRegression(C=best_c) # 导入上个步骤求得的最优C值
lr.fit(x_train,y_train) # 对数据进行训练6)修改阈值
此时发现概率可能还是不高,那么再使用一种方法,也就是修改阈值的方法对其进行处理,取阈值为0.1-0.9这个阶段,分别测试其召回率,最后就可以得到最优模型,完成训练。
4、什么是k折交叉验证
k折交叉验证是一种常用的模型评估方法。它将数据集分成k个子集,每次使用其中的k-1个子集作为训练集,剩下的1个子集作为验证集,然后对模型进行训练和评估。这个过程重复k次,每次使用不同的子集作为验证集。最终,将k次评估的结果平均得到模型的性能指标,如准确率、精确度、召回率等。
5、什么是修改阈值
修改阈值是指在特定的系统或算法中,调整阈值的数值以达到不同的效果或目标。
阈值是一个临界点,用于判断某个输入值是否满足某种条件或达到某个标准。在很多应用中,阈值的设定对结果的准确性和可靠性至关重要。通常情况下,阈值的设定是根据具体需求和应用场景进行的。
三、完整代码实现
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from pylab import mpl
# 可视化混淆矩阵,网上都是包装好的,可以直接复制使用
def cm_plot(y, yp):
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm = confusion_matrix(y, yp)
plt.matshow(cm, cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x, y], xy=(y, x), horizontalalignment='center',verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
data = pd.read_csv(r'./creditcard.csv')
data.head() # 默认输出前5行,这里用来提示防止忘记代码了
# 设置字体,用来显示中文
mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei']
mpl.rcParams['axes.unicode_minus'] = False
# 同级class列中每个类型的数据个数,(这里的样本极度不均衡)
labels_count = pd.value_counts(data['Class'])
# 可视化上述分类数据的个数
plt.title("正负例样本数")
plt.xlabel('类别')
plt.ylabel('频数')
labels_count.plot(kind='bar')
plt.show()
# 将Amount列的数据进行Z标准化,因为其余列的值有负值,所以不能使用0-1归一化
# 导入库的用法
from sklearn.preprocessing import StandardScaler
# z标准化
scaler = StandardScaler() # 这是一个类,专门用来处理z标准化,适合处理大量数据的类,还有一种叫scale,适合对小部分数据进行z标准化
a = data[['Amount']] # 取出Amount整列数据
data['Amount'] = scaler.fit_transform(data[['Amount']]) # 对Amount整列数据进行z标准化后将其传入原data内,覆盖原来的列
# 删除无用的列,Time列,axis=1表示列,axis=0表示行,然后再传入data文件
data = data.drop(['Time'],axis=1)
x_big = data.drop('Class',axis=1)
y_big = data.Class
# 处理小数据集
positive_eg = data[data['Class'] == 0] # 分别取出列中数据等于1的0的,分别赋值
negative_eg = data[data['Class'] == 1]
np.random.seed(seed=4) # 随机种子
positive_eg = positive_eg.sample(len(negative_eg)) # 使用sample函数取出等长度条数的数据
data_c = pd.concat([positive_eg,negative_eg]) # 使用pandas中的concat合并两个数据集
print(data_c)
# 显示中文
mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei']
mpl.rcParams['axes.unicode_minus'] = False
from sklearn.model_selection import train_test_split
# 删除列Class后的数据赋值给 x,然后再将Class单独取出赋值给y
x = data_c.drop('Class',axis=1) # 对小数据集分类,特征数据集x以及标签
y = data_c.Class
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3,random_state=0) # 对小数据集进行随机取样,取出30%当做测试集,剩下的70%当做训练集
x_train_bid,x_test_big,y_train_big,y_test_big = train_test_split(x_big,y_big,test_size=0.3,random_state=0) # 对大数据集(原始数据)进行随机取样,取出30%当做测试集,剩下的70%当做训练集
from sklearn.linear_model import LogisticRegression # 导入逻辑回归模型
from sklearn.model_selection import cross_val_score # 用来进行k折交叉验证
scores = [] # 定义一个空列表,用来存放后面更改正则化强度后的每个C值计算结果对应的score值
c_param_range = [0.01,0.1,1,10,100] # 循环更改的C值
for i in c_param_range:
lr = LogisticRegression(C=i,penalty='l2',solver='lbfgs',max_iter=1000) # 建立模型,循环更改其参数
score = cross_val_score(lr,x_train,y_train,cv=8,scoring='recall') # 使用上述模型对数据集进行k折交叉验证
score_mean = sum(score)/len(score) # 计算不同C值对应概率平均值
scores.append(score_mean)
print(score_mean)
best_c = c_param_range[np.argmax(scores)] # 取出最大概率对应的最优C值
lr = LogisticRegression(C=best_c,penalty='l2',max_iter=1000) # 将最优C值导入模型,正式对其训练
lr.fit(x_train,y_train) # 倒入训练数据集
from sklearn import metrics # 用来查看分类报告
train_predict = lr.predict(x_train) # 导入测试集进行预测
print(metrics.classification_report(y_train,train_predict)) # 打印分类报告
cm_plot(y_train,train_predict).show() # 可视化混淆矩阵
test_predict = lr.predict(x_test) # 对测试集进行测试
print(metrics.classification_report(y_test,test_predict)) # 打印分类报告
cm_plot(y_test,test_predict).show() # 可视化混淆矩阵
test_predict_big = lr.predict(x_test_big) # 对原始数据测试集进行测试
print(metrics.classification_report(y_test_big,test_predict_big))
train_predict_big = lr.predict(x_train_bid) # 对原始数据的训练集进行测试
print(metrics.classification_report(y_train_big,train_predict_big))
thresholds = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9] # 修改阈值,设置阈值范围不断迭代来判断概率最大值
recalls = []
for i in thresholds:
y_predict_proba = lr.predict_proba(x_test) # 打印属于0类和1类的概率
y_predict_proba = pd.DataFrame(y_predict_proba) # 更改数据类型为二维数组
y_predict_proba = y_predict_proba.drop([0],axis=1) # 删除类别0的数据
y_predict_proba[y_predict_proba[[1]] > i] = 1 # 判断如果概率大于i,则将其定义为1类
y_predict_proba[y_predict_proba[[1]] <= i] =0
recall = metrics.recall_score(y_test,y_predict_proba[1]) # 输入测试集标签和测试结果,直接打印需要的召回率
recalls.append(recall)
print("{}Recall metric in the testing dataset:{:.3f}".format(i,recall))
代码输出结果如下:
1)最初的样本分类情况

2)处理后的数据的混淆矩阵:


3)最终打印输出结果

四、总结:
下采样是一种处理大批量数据的方法,其目的是减少数据集的规模,从而提高算法的效率和速度,同时保持对数据集的代表性。
总结下采样的步骤如下:
-
确定下采样的目标:首先需要明确下采样的目的是为了解决什么问题。例如,如果数据集不平衡,可以采用下采样来平衡正负样本的比例;如果算法运行速度较慢,可以采用下采样来减少计算量。
-
选择下采样的方法:常见的下采样方法包括随机下采样、集群下采样和有选择性地下采样。
-
随机下采样:随机从原始数据集中抽取一定数量的样本,使得抽样后的数据集大小满足要求。这种方法简单快速,但可能会损失一些稀有的样本信息。
-
集群下采样:使用聚类算法将原始数据集划分为若干个簇,然后从每个簇中选择代表性的样本作为下采样的结果。这种方法可以保留原始数据集中的多样性特征,但计算复杂度较高。
-
有选择性地下采样:根据具体问题的需求,有选择地保留或删除某些特定的样本。例如,根据样本的分类结果或属性进行选择性地下采样。
-
-
实施下采样:根据选择的下采样方法,对原始数据集进行处理。可以使用编程工具或库来实现下采样的操作,如Python中的numpy、pandas和sklearn等工具。
-
检查结果:完成下采样后,需要对结果进行检查,确保下采样后的数据集仍保持了原始数据集的代表性和特征。可以使用数据可视化和统计分析等方法对下采样结果进行评估。