1. 论文基本信息

发布于: IEEE SPL 2024
2. 创新点
- 分析了基于 one-hot 编码的交叉熵损失函数为什么不能准确衡量标签与预测概率分布之间的差异。
- 介绍了 ACNP 模块,该模块通过预测占用的子节点数量来增强上下文模型的表现。
- 实验证明了ACNP模块在基于八叉树的上下文模型中的有效性。
3. 背景
- 现有上下文模型的局限性:
现有的上下文模型使用交叉熵作为损失函数,但交叉熵更适用于分类问题,无法准确衡量标签与预测概率分布之间的差异。在这些模型中,节点的占用情况被转换为255维的one-hot编码,作为训练标签。然后使用交叉熵来计算标签与上下文模型估计的概率分布之间的差异。这种方法可以衡量子节点之间的位置信息差异,但对于衡量实际占用的子节点数量和预测的差异不够准确。这实际上是一个回归问题,而不是分类问题。
- ACNP模块的提出:
为了应对上述问题,作者提出了一个基于注意力的ACNP模块,该模块直接预测占用的子节点数量,并将其映射为一个8维向量,该向量包含占用子节点数量的信息。这个8维向量作为特征,帮助上下文模型的训练。该模块是通用的,能够提升多种上下文模型的性能。
核心问题所在:
当前使用的交叉熵损失函数适合分类问题,但在八叉树几何压缩上下文中使用它来衡量预测与真实占用子节点数量之间的差异(这里本身是一个回归问题)时是不合适的。
举例说明:假设一个八叉树节点的真实占用状态是 11100000 (224),即只有第六、第七和第八个子节点被占用(实际占用数量为3个)。但如果模型预测状态是11111111(255),交叉熵可能会产生一个相对较小的损失,因为 one-hot 编码没有显著差异。但实际上,两者的子节点占用数量相差很大:预测的数量是8个,而实际只有3个。
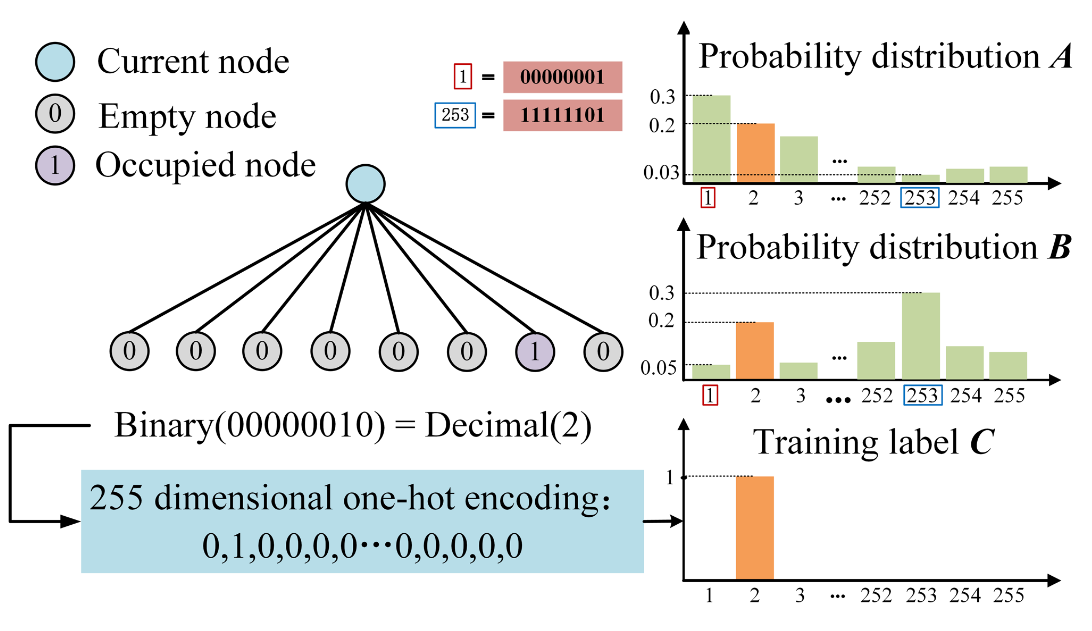


当占用子节点的数量已知时,占用子节点的位置成为一个分类问题。在这种情况下,交叉熵损失适用。
因此,交叉熵损失只是在判断两者one-hot编码的差异,但并未直接衡量预测与实际占用子节点数量的误差。这种差异对于几何压缩来说是重要的,因为目标是在尽可能少的比特中准确表示点云。 在这个场景下,模型的任务不仅是预测每个子节点是否被占用(分类),而且是要准确预测占用的子节点数量(回归)。
4. pipeline
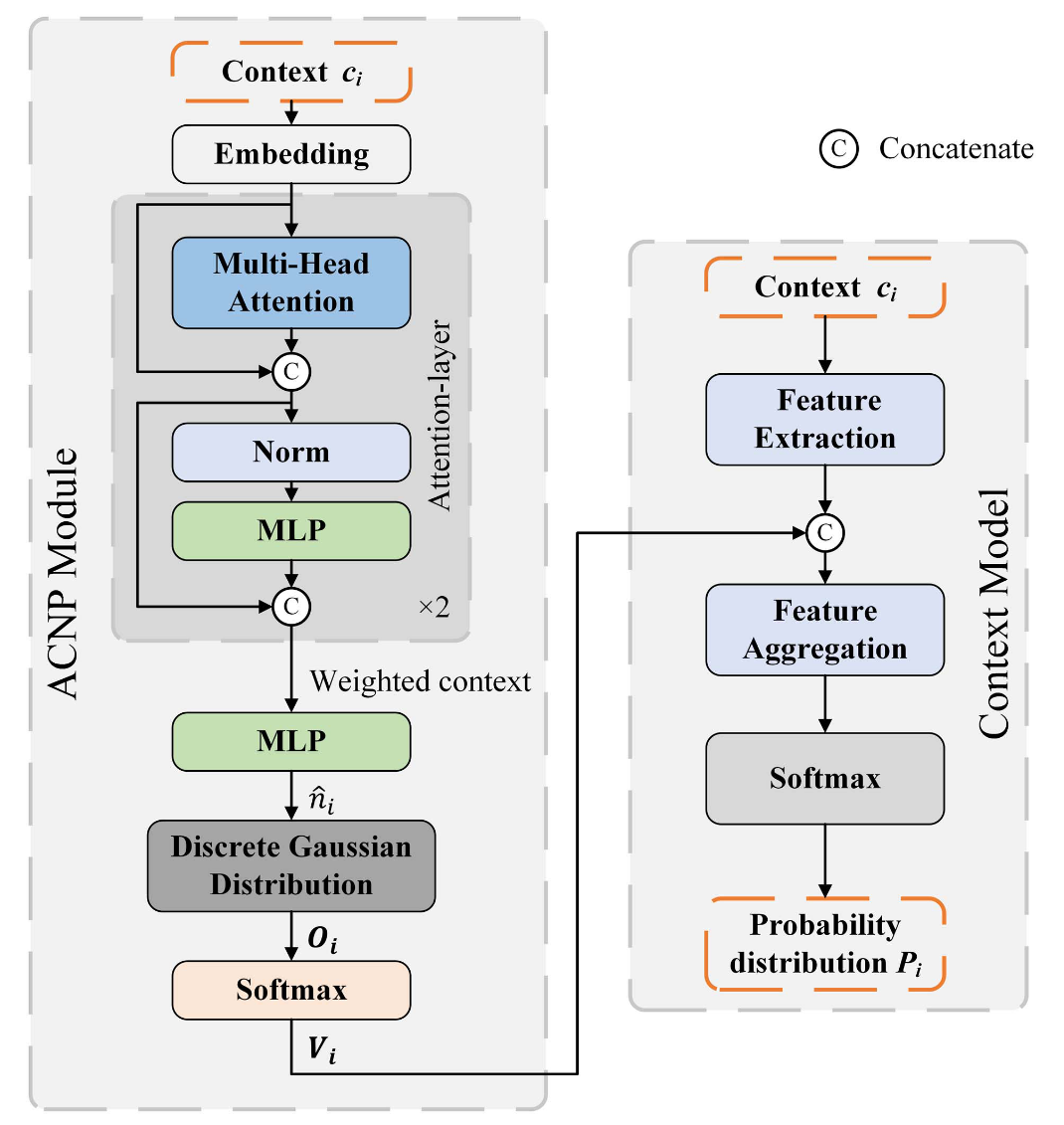
ACNP 模块的核心思想是通过注意力机制来预测当前节点的占用子节点数量,并将这一信息融入到上下文模型中以提升模型性能。
结构组成:
- 注意力层:首先,将节点的上下文信息输入注意力层,生成加权后的上下文信息。这一步通过注意力机制强调重要的上下文特征。
- 两层 MLP:然后,将加权后的上下文信息输入一个两层的多层感知机(MLP),它聚合这些信息并输出预测的子节点占用数量
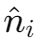
- 预测映射到 8 维向量:由于一维的
不能直接用于 MLP 训练,系统将其映射到 8 维向量
这个向量通过如下公式计算: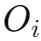
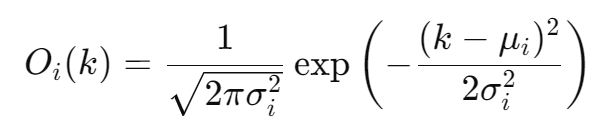
- Softmax 层:接着,将 Oi 输入到 Softmax 层,生成一个 8 维的概率向量 Vi。其中,第 k 维表示节点 Xi 具有 k 个占用子节点的概率。
- 上下文模型整合:最终,Vi 被整合到上下文模型中,作为一种特征信息用于上下文模型的训练,从而生成增强的概率分布 Pi 。
- 损失函数:

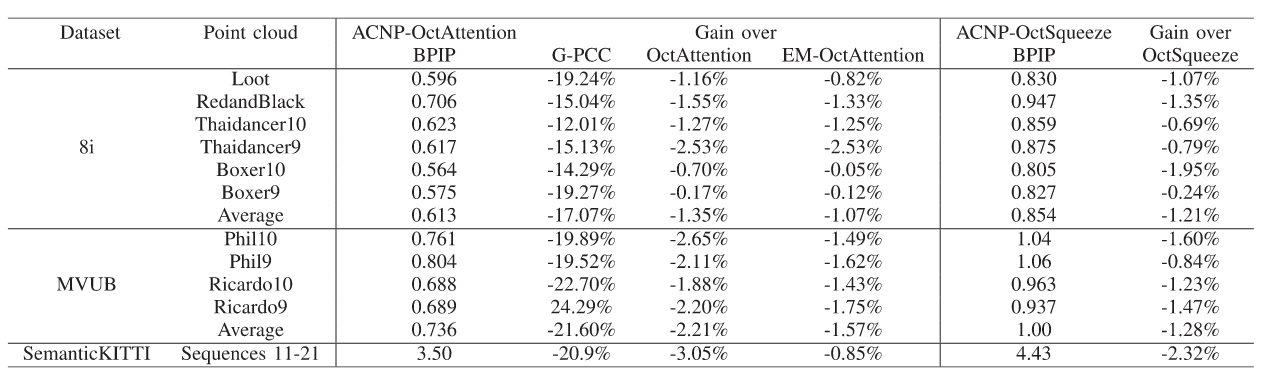
5. 💎实验成果展示