你是否曾在半夜被一个顽固的bug折磨得睡不着觉?是否因为理解不了复杂算法而感到沮丧?别担心,你并不孤单。作为一名经验丰富的大数据开发者,我深知编程之路上的挫折感。但今天,我要和你分享我是如何在这条充满荆棘的道路上找到突破,最终成长为一名得心应手的编程高手的。

前言:每个程序员都曾跌倒
还记得你第一次面对一个看似无法解决的编程问题时的感觉吗?那种挫败感,就像站在一座高耸入云的大山前,不知从何处着手攀登。但请记住,即便是那些让你仰望的编程大神,也曾在这条路上跌倒过、迷茫过。

作为一名在大数据领域摸爬滚打多年的开发者,我想告诉你的是:挫折不是你的敌人,而是你最好的老师。每一次的失败,都是通向成功的必经之路。今天,我将毫无保留地分享我是如何在重重困难中找到突破口的,希望能为你的编程之路点亮一盏希望之灯。
Bug迷宫中的突围之策
在大数据开发中,Bug就像是隐藏在代码丛林中的猛兽,随时可能跳出来给你一记重击。但别怕,让我们一起来看看如何在这个迷宫中找到出路。

案例分析:当Hadoop集群罢工时
还记得那个让我彻夜难眠的夜晚吗?公司的核心Hadoop集群突然宕机,数以TB计的数据处理任务陷入瘫痪。作为项目参与人,我面临着巨大的压力。让我们回顾一下当时的情况:
[2023-05-15 02:30:45] ERROR: Hadoop NameNode无法启动
[2023-05-15 02:31:20] WARN: DataNode连接失败
[2023-05-15 02:32:10] CRITICAL: HDFS文件系统不可访问
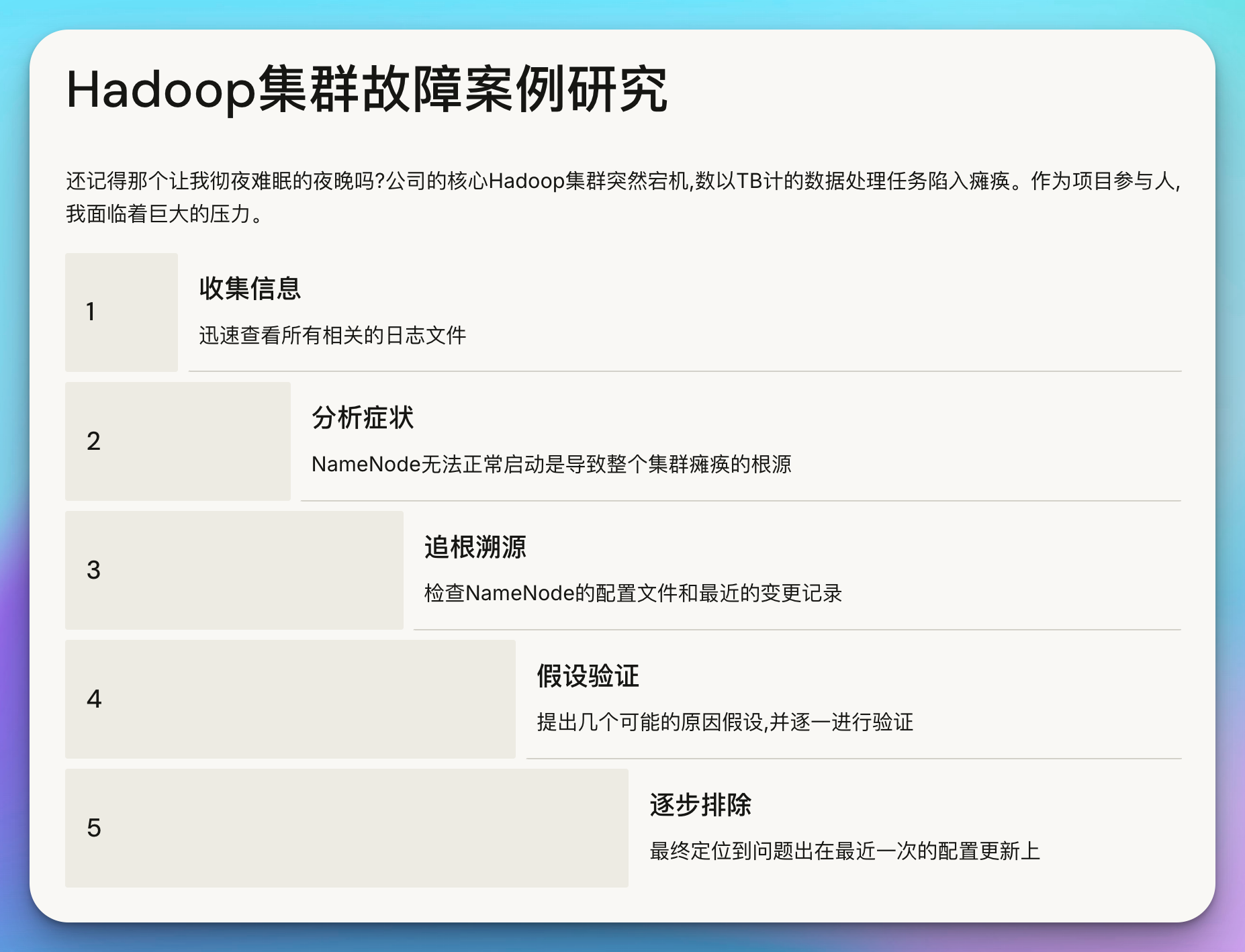
面对这样的场景,很容易陷入恐慌。但正是在这种时刻,保持冷静至关重要。我采取了以下步骤:
-
收集信息: 我迅速查看了所有相关的日志文件,包括NameNode、DataNode和YARN的日志。
-
分析症状: 通过日志分析,我发现NameNode无法正常启动是导致整个集群瘫痪的根源。
-
追根溯源: 进一步深入,我检查了NameNode的配置文件和最近的变更记录。
-
假设验证: 我提出了几个可能的原因假设,并逐一进行验证。
-
逐步排除: 通过排除法,我最终定位到问题出在最近一次的配置更新上。
在经过近4小时的奋战后,我找到了罪魁祸首:一个看似无害的配置参数修改导致了NameNode无法正确识别DataNode。
解决方案:
<!-- hdfs-site.xml -->
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property>
将这个参数设置为false后,NameNode终于能够正常启动,整个集群恢复了运转。
技巧总结:Debug如何事半功倍
从这次经历中,我总结出了几点在面对棘手bug时的关键技巧:
-
保持冷静: 慌乱只会让问题变得更糟。深呼吸,告诉自己:“这只是另一个待解决的问题。”
-
系统化思考: 使用排除法和二分法来缩小问题范围。比如,在Hadoop集群故障时,我们可以先确定是网络问题、配置问题还是硬件故障。
-
善用工具: 日志分析工具、性能监控工具都是我们的好帮手。在大数据开发中,我常用的工具包括:
- Elasticsearch + Kibana: 用于集中化日志管理和分析
- Grafana: 用于实时监控集群性能
- Wireshark: 在网络问题排查时非常有用
-
建立知识库: 每解决一个问题,就将其记录下来。这不仅能帮助你在未来遇到类似问题时快速解决,也能帮助团队其他成员。
-
模拟复现: 如果可能,尝试在测试环境中复现问题。这能让你在不影响生产环境的情况下自由尝试各种解决方案。
-
寻求帮助: 不要害怕向他人寻求帮助。有时候,一个外部的视角可能会带来意想不到的突破。
记住,每一个bug都是一次学习的机会。通过不断地解决问题,你会逐渐建立起自己的问题解决模式,这正是成为编程高手的关键所在。

面对复杂算法时的冷静之道
在大数据开发中,复杂的算法问题是我们常常需要面对的挑战。当你第一次接触MapReduce、Spark的RDD转换,或者是复杂的机器学习算法时,很容易感到不知所措。但请记住,每个复杂的问题都可以被分解成若干个简单的子问题。

实战经历:征服MapReduce的惊魂24小时
还记得我第一次尝试实现一个复杂的MapReduce算法时的情景。那是一个需要对海量用户行为数据进行多维度分析的项目,要求在有限的时间内完成从数据清洗、转换到最终分析的全过程。
问题描述:
- 输入:数TB的用户点击流日志
- 要求:计算每个用户在不同时间段、不同页面类型的停留时长,并按照多个维度进行汇总
这个问题之所以复杂,在于:
- 数据量巨大,需要高效的分布式处理
- 涉及多个维度的计算和汇总
- 需要处理各种异常情况(如用户会话中断、日志数据不完整等)

面对这样的挑战,我采取了以下步骤:
-
问题分解:
- 第一步:数据清洗和预处理
- 第二步:用户会话识别
- 第三步:页面停留时间计算
- 第四步:多维度汇总
-
逐步实现:
让我们以"用户会话识别"这一步为例,看看如何用MapReduce来实现:
public class SessionIdentifier {
public static class SessionMapper extends Mapper<LongWritable, Text, Text, Text> {
private final static long SESSION_TIMEOUT = 30 * 60 * 1000; // 30分钟超时
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] fields = value.toString().split("\t");
if (fields.length < 3) return; // 跳过格式不正确的记录
String userId = fields[0];
long timestamp = Long.parseLong(fields[1]);
String pageInfo = fields[2];
// 输出格式: key=userId, value=timestamp|pageInfo
context.write(new Text(userId), new Text(timestamp + "|" + pageInfo));
}
}
public static class SessionReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
List<Pair<Long, String>> sortedActions = new ArrayList<>();
// 收集并排序用户的所有行为
for (Text value : values) {
String[] parts = value.toString().split("\\|");
sortedActions.add(new Pair<>(Long.parseLong(parts[0]), parts[1]));
}
Collections.sort(sortedActions, Comparator.comparing(Pair::getKey));
// 识别会话
long lastTimestamp = 0;
int sessionId = 0;
for (Pair<Long, String> action : sortedActions) {
if (action.getKey() - lastTimestamp > SESSION_TIMEOUT) {
sessionId++;
}
// 输出格式: key=userId_sessionId, value=timestamp|pageInfo
context.write(new Text(key.toString() + "_" + sessionId), new Text(action.getKey() + "|" + action.getValue()));
lastTimestamp = action.getKey();
}
}
}
// 主函数省略...
}
这段代码展示了如何使用MapReduce来识别用户会话:
- Mapper阶段:提取用户ID、时间戳和页面信息
- Reducer阶段:对每个用户的行为按时间排序,并根据时间间隔划分会话
- 优化与改进:
实现基本功能后,我又进行了多轮优化,包括:
- 使用Combiner减少网络传输
- 优化数据序列化方式
- 调整MapReduce作业的配置参数
- 测试与验证:
为确保结果的正确性,我设计了一系列测试用例,包括:
- 单元测试:验证Mapper和Reducer的逻辑
- 集成测试:在小规模数据集上验证整个流程
- 性能测试:使用大规模数据集测试系统的扩展性
经过24小时的奋战,我不仅成功实现了这个复杂的MapReduce算法,还在此过程中深化了对分布式计算的理解。这次经历让我明白,即便是最复杂的算法,只要方法得当,也能被攻克。
方法论:如何优雅地拆解算法难题
从上面的经历中,我总结出了面对复杂算法时的几个关键方法:
-
问题分解: 将大问题拆分成小问题。就像我们处理MapReduce任务一样,先考虑Map阶段该做什么,Reduce阶段又该做什么。
-
画图理解: 对于复杂的数据流或算法逻辑,画图是一个非常有效的理解工具。例如,对于上面的会话识别算法,我们可以画出这样的流程图:
-
从简单案例开始: 不要一开始就处理全部复杂度。先用一个简化的例子实现基本逻辑,然后逐步添加复杂性。
-
查阅文档和最佳实践: 对于像Hadoop、Spark这样的大数据框架,官方文档和社区最佳实践是宝贵的资源。
-
实践与反思: 动手实现很重要,但更重要的是实现后的反思。每次编码后,问问自己:
- 这个解决方案是最优的吗?
- 有没有可能进一步优化?
- 我从中学到了什么新知识?
-
利用数学思维: 很多复杂的算法问题本质上是数学问题。培养数学思维可以帮助你更好地理解和设计算法。例如,在处理大数据时,概率论和统计学的知识经常能派上用场。
-
构建知识体系: 将新学到的算法知识与已有的知识联系起来,构建自己的知识网络。这样不仅能加深理解,还能在遇到新问题时更快地找到解决思路。

让我们用一个具体的例子来说明如何应用这些方法:
假设我们需要实现一个基于Spark的实时热门商品推荐系统。这个系统需要处理用户的浏览、点击、购买等行为数据,实时计算商品的热度,并为用户推荐热门商品。
-
问题分解:
- 数据接入: 如何实时接收用户行为数据?
- 数据处理: 如何清洗和转换原始数据?
- 热度计算: 如何定义和计算商品热度?
- 推荐生成: 如何基于热度生成推荐列表?
- 结果输出: 如何将推荐结果返回给用户?
-
画图理解:
让我们用一个流程图来梳理整个系统的数据流: -
从简单案例开始:
我们可以先实现一个简化版本,只考虑点击行为,用一个简单的计数器来表示热度。import org.apache.spark.streaming._ import org.apache.spark.streaming.kafka010._ object SimpleHotItemsRecommender { def main(args: Array[String]): Unit = { val spark = SparkSession.builder.appName("SimpleHotItemsRecommender").getOrCreate() val ssc = new StreamingContext(spark.sparkContext, Seconds(5)) val kafkaParams = Map[String, Object]( "bootstrap.servers" -> "localhost:9092", "key.deserializer" -> classOf[StringDeserializer], "value.deserializer" -> classOf[StringDeserializer], "group.id" -> "hot_items_group", "auto.offset.reset" -> "latest", "enable.auto.commit" -> (false: java.lang.Boolean) ) val topics = Array("user_behaviors") val stream = KafkaUtils.createDirectStream[String, String]( ssc, PreferConsistent, Subscribe[String, String](topics, kafkaParams) ) val itemClicks = stream.map(record => (record.value, 1)) .reduceByKeyAndWindow((a:Int, b:Int) => a + b, Seconds(60), Seconds(5)) itemClicks.foreachRDD { rdd => val topItems = rdd.sortBy(_._2, ascending = false).take(10) println("Hot Items: " + topItems.mkString(", ")) } ssc.start() ssc.awaitTermination() } }这个简化版本使用Spark Streaming从Kafka接收数据,统计60秒窗口内的商品点击次数,并每5秒输出一次当前最热门的10个商品。
-
查阅文档和最佳实践:
在实现过程中,我们可能会遇到一些问题,比如:- Spark Streaming的背压机制如何配置?
- 如何优化Kafka的消费性能?
- 窗口操作的最佳实践是什么?
这时,查阅Spark和Kafka的官方文档,以及社区中的最佳实践文章就显得尤为重要。
-
实践与反思:
实现基本功能后,我们需要反思和优化:- 当前的热度计算方法是否合理?是否需要考虑时间衰减?
- 系统的扩展性如何?能否处理更大规模的数据?
- 有没有可能引入机器学习算法来优化推荐效果?
-
利用数学思维:
在优化热度计算时,我们可以引入一些数学模型,例如:- 使用指数衰减函数来计算时间权重
- 引入TF-IDF算法来平衡热门程度和稀缺性
- 使用协同过滤算法来个性化推荐结果
-
构建知识体系:
通过这个项目,我们可以将以下知识点串联起来:- 流式计算的基本概念和实现方法
- 分布式系统的数据一致性问题
- 实时推荐系统的架构设计
- 大数据处理中的性能优化技巧
通过这个例子,我们可以看到,即使面对复杂的算法问题,只要我们有正确的方法论,也能逐步攻克。关键在于保持冷静,系统地分析问题,并在实践中不断学习和优化。
持续学习:编程高手的不二法门

在大数据这个快速发展的领域,持续学习不仅是一种必要,更是保持竞争力的关键。作为一个经验丰富的大数据开发者,我深知学习永无止境。以下是我的一些持续学习策略,希望能对你有所启发。
学习清单:紧跟大数据技术前沿
-
核心技术栈更新:
- Apache Hadoop生态系统: HDFS, YARN, MapReduce
- Apache Spark: Core, SQL, Streaming, MLlib
- Apache Flink: DataStream, DataSet, CEP
- 实时计算引擎: Apache Storm, Apache Samza
- NoSQL数据库: HBase, Cassandra, MongoDB
- 分布式协调服务: Apache ZooKeeper
- 分布式消息系统: Apache Kafka, RabbitMQ
-
新兴技术:
- 容器化和编排: Docker, Kubernetes
- 大数据云服务: AWS EMR, Google Cloud Dataproc, Azure HDInsight
- 实时数仓: Apache Druid, Apache Pinot
- 流批一体化处理: Apache Beam
- 图数据处理: Apache Giraph, Neo4j
- AI和机器学习: TensorFlow, PyTorch, Scikit-learn
-
编程语言和范式:
- 函数式编程: Scala, Haskell
- 并发编程: Akka, Go
- Python: 数据科学库 (NumPy, Pandas, SciPy)
- Java: 版本更新和新特性
-
数据科学和算法:
- 机器学习算法: 深度学习, 强化学习
- 数据挖掘技术
- 自然语言处理 (NLP)
- 推荐系统
- 时间序列分析
-
软技能:
- 系统设计和架构
- 项目管理方法论: Agile, Scrum
- 技术写作和文档
- 数据可视化: D3.js, ECharts
行动指南:打造个人技术壁垒
-
制定学习计划:
根据自己的职业目标和兴趣,制定短期(3个月)、中期(1年)和长期(3-5年)的学习计划。例如:短期计划(3个月):
- 深入学习Apache Flink,完成官方文档的所有练习
- 实现一个基于Flink的实时数据处理项目
- 学习并在项目中应用容器化技术(Docker + Kubernetes)
中期计划(1年):
- 掌握至少一种云平台的大数据服务(如AWS EMR)
- 深入学习机器学习,完成Andrew Ng的深度学习课程
- 参与或发起一个开源大数据项目
长期计划(3-5年):
- 成为某个大数据领域(如实时计算、数据湖)的专家
- 在技术社区建立影响力,定期分享技术文章或做技术演讲
- 转向大数据架构师或技术负责人的角色
-
实践驱动学习:
光看不练是不够的。每学习一个新技术,都要通过实际项目来巩固。以下是一些实践的方法:- 个人项目: 设计并实现一个完整的大数据处理系统,涵盖数据采集、存储、处理、分析和可视化。
- 开源贡献: 参与知名大数据项目的开发,如提交Bug修复或新功能。
- 技术博客: 记录学习过程,分享经验和见解。
- 模拟真实场景: 使用公开数据集,模拟企业级的数据处理需求。

例如,你可以尝试实现一个基于Spark和Kafka的实时日志分析系统:
import org.apache.spark.sql.SparkSession import org.apache.spark.sql.functions._ import org.apache.spark.sql.streaming.Trigger object LogAnalyzer { def main(args: Array[String]): Unit = { val spark = SparkSession.builder .appName("LogAnalyzer") .getOrCreate() import spark.implicits._ val logs = spark.readStream .format("kafka") .option("kafka.bootstrap.servers", "localhost:9092") .option("subscribe", "logs") .load() val parsedLogs = logs.selectExpr("CAST(value AS STRING)") .as[String] .flatMap(line => { val parts = line.split(" ") if (parts.length == 3) Some((parts(0), parts(1), parts(2).toInt)) else None }) .toDF("timestamp", "level", "message_length") val windowedCounts = parsedLogs .groupBy(window($"timestamp", "1 minute"), $"level") .agg(count("*").alias("count"), avg("message_length").alias("avg_length")) val query = windowedCounts.writeStream .outputMode("complete") .format("console") .trigger(Trigger.ProcessingTime("10 seconds")) .start() query.awaitTermination() } }这个例子展示了如何使用Spark Structured Streaming来实时处理Kafka中的日志数据,按照日志级别进行分组统计,并计算消息长度的平均值。
-
建立学习社区:
- 加入技术社区和论坛,如Stack Overflow, GitHub
- 参加技术会议和研讨会,如Strata Data Conference, Spark Summit
- 组织或参与本地的技术沙龙和读书会
- 与同行保持交流,分享学习心得
-
保持好奇心和开放心态:
- 关注行业动态和技术趋势
- 尝试跨领域学习,如将机器学习技术应用到大数据处理中
- 不要局限于特定的技术栈,保持对新技术的开放态度
-
反思和总结:
定期回顾自己的学习进度和成果,可以采用以下方法:- 维护一个技术博客,记录学习心得和实践经验
- 每月做一次技术分享,向团队介绍新学到的知识
- 建立个人知识库,如使用Notion或GitBook整理学习笔记
- 参与技术写作,如翻译技术文档或撰写教程

通过持续学习和实践,你不仅能够跟上技术的发展步伐,还能在解决实际问题时更加得心应手。记住,在编程的道路上,学习永无止境,而每一次的挑战都是成长的机会。
结语:在挫折中成长,在坚持中成功
回首我的编程之路,深感每一次的挫折都是一次宝贵的学习机会。从初入职场时被复杂的分布式系统困扰,到现在能够从容应对各种技术挑战,这个过程充满了汗水、挫折,但也饱含成就感和喜悦。
记住,编程世界中没有无法攻克的难题,只有尚未找到的解决方案。面对挫折时,不要气馁,而应该保持冷静,系统地分析问题,并勇于寻求帮助。通过不断学习和实践,你终将找到属于自己的突破之路。

在这个日新在这个日新月异的技术世界中,保持学习的热情和韧性至关重要。每一个成功的程序员背后,都有无数次的尝试和失败。正是这些经历,塑造了我们的技术实力和问题解决能力。
让我们回顾一下本文中讨论的关键点:
-
在Bug迷宫中找到出路:
- 保持冷静,系统化思考
- 善用调试工具和日志分析
- 建立个人知识库,积累经验
-
面对复杂算法时的应对之道:
- 问题分解,从简单开始
- 利用可视化工具理解算法流程
- 实践与反思并重
-
持续学习的重要性:
- 制定个人学习计划
- 通过实际项目巩固所学
- 建立学习社区,与同行交流
记住,每一次你觉得自己要放弃的时候,很可能就是你即将突破的前夜。在我的职业生涯中,有很多次我感到困惑和沮丧,但正是这些时刻让我有了最大的成长。
比如,有一次我在处理一个复杂的数据倾斜问题时,尝试了各种优化方法都收效甚微。就在我几乎要放弃的时候,我决定重新审视问题本身,而不是一味地对症下药。最终,我发现问题的根源在于数据预处理阶段的一个微小疏忽。这次经历不仅让我解决了当前的问题,还让我深刻理解了"了解你的数据"这一原则的重要性。
作为结束,我想分享一段代码,它一直激励着我在编程道路上前进:
def programmer_life():
skills = []
experience = 0
while True:
try:
new_challenge = face_next_challenge()
solution = solve_problem(new_challenge)
skills.append(learn_from(solution))
experience += 1
except Failure as f:
learn_from_failure(f)
continue
except Burnout as b:
take_break_and_reflect()
continue
finally:
never_give_up()
programmer_life()
这段代码虽然简单,但它概括了程序员生活的精髓:不断面对挑战,解决问题,从中学习,积累经验。即使遇到失败或倦怠,我们也要学会从中吸取教训,适时休息,但永远不要放弃。
记住,每一个伟大的程序员都曾是一个初学者,每一个成功的项目背后都有无数次的调试和重构。你现在所面临的挑战,终将成为你明天的实力。保持热情,持续学习,相信自己的能力,你就一定能在这条充满挑战但也充满机遇的编程之路上走得更远。
最后,我想用一句我很喜欢的话来结束这篇文章:
“The expert in anything was once a beginner.” — Helen Hayes
无论你现在处于哪个阶段,都请记住,坚持就是胜利。愿你在编程的道路上,永远保持好奇,勇于挑战,不断成长。未来的你,一定会为现在努力的自己感到骄傲。

让我们一起在代码的海洋中探索,在bug的迷宫中突围,在算法的森林中穿梭,创造属于我们自己的技术传奇!