Redis缓存场景
文章目录
- Redis缓存场景
- Redis做缓存
- 旁路缓存
- 缓存异常
- 缓存穿透
- 缓存击穿
- 缓存雪崩
- 缓存一致性
- 先写缓存再写数据库
- 先写数据库再写缓存
- 先删除缓存再写数据库
- 先写数据库再删缓存
- 缓存双删
- Binlog异步更新
- 总结
Redis做缓存
部分图解来自于:https://www.mianshiya.com/
Redis由于高性能,通常可以作为数据库存储的缓存,比如给MySQL当缓存。
旁路缓存
Cache Aside,即旁路缓存,最常见的模式。应用服务把缓存作为数据库的旁路,直接和缓存进行交互。
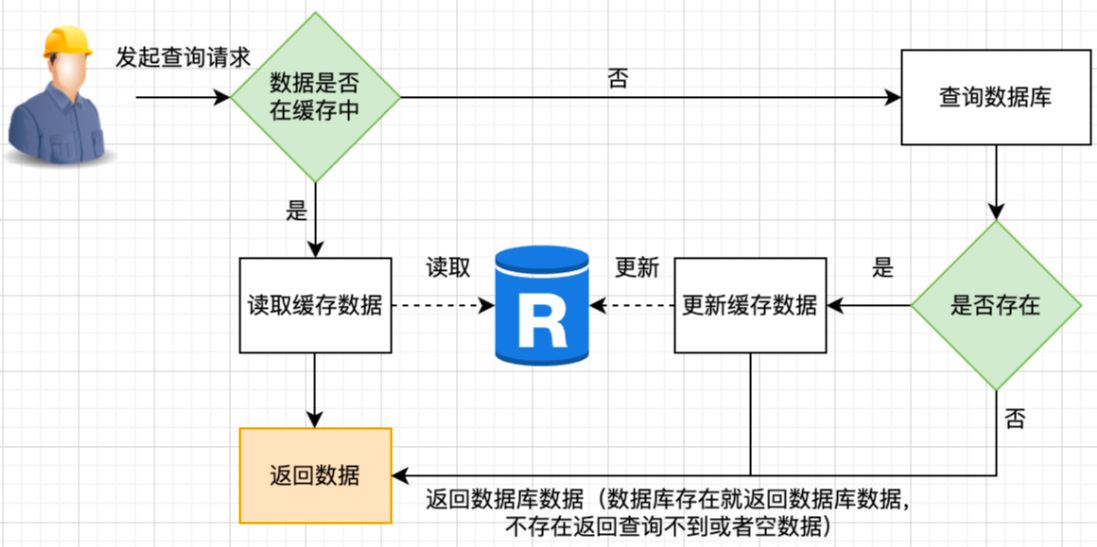
读操作:
1.应用服务收到查询请求,先去查询数据是否在缓存上
2.如果在,把缓存数据打包返回;如果不在,去访问数据库查询,然后放到缓存上
写操作:
旁路缓存一般都是先更新数据库,然后直接删除缓存。
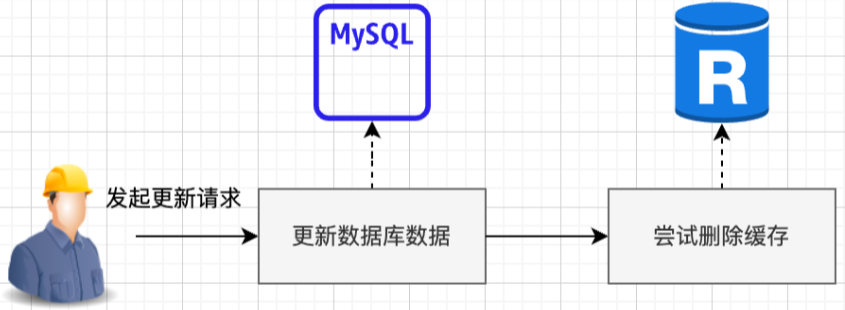
为什么不是更新缓存,而是删除缓存呢?因为更新比删除更容易导致时序性问题。
比如:
thread1更新一个MySQL字段为1,thread2更新MySQL字段为2,thread2更新缓存为2,thread1更新缓存为1。
最终缓存被更新为1,正确的数据因为时序性被覆盖了。
缓存异常
缓存穿透
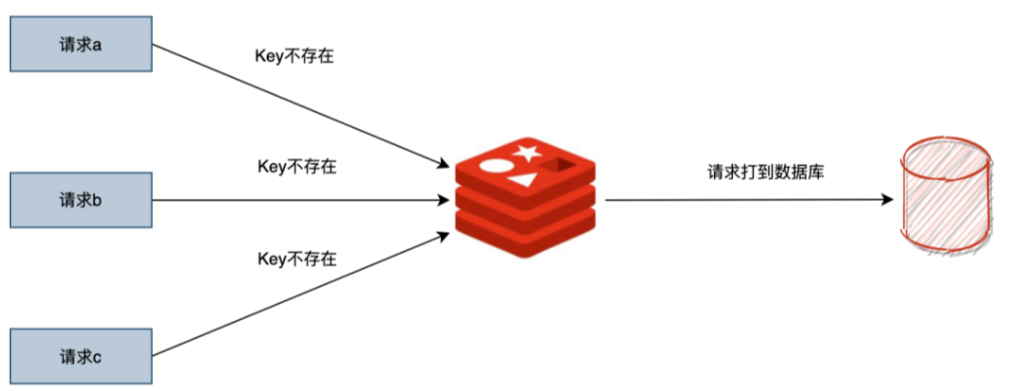
缓存穿透指,缓存和数据库中都没有的数据,而用户不断发起请求。
如果从存储层查不到则不写入缓存,这个导致不存在的数据每次都请求到存储层去,失去了缓存的意义。
在流量大时,DB可能就挂了,如果有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
解决方案:
1.接口层增加校验,如用户鉴权,id做基础校验,id<=0直接拦截
2.缓存中取不到的数据,数据库也取不到,将key-value设置为key-null,设置到缓存中(设置一个过期时间,如30秒,时间太长,正常情况也没法使用)。这样可以防止一个用户反复用同一个id暴力攻击
3.使用布隆过滤器,布隆过滤器可以快速判断某个元素是否存在于集合中。
布隆过滤器是一种巧妙的数据结构,可以用来查询,某个元素可能存在或一定不存在。
布隆过滤器的原理:
底层为一个bit数组,将字符串用多个哈希函数映射到不同位置,将对应位置置为1。
在查询时,如果一个字符串所有哈希函数映射的值都为1,那么数据可能存在;否则不存在。
为什么说可能呢?因为其他字符也可能占据这个bit位的值。
缓存击穿
缓存击穿是指缓存中没有数据库有的数据(一般都是缓存时间到期),由于并发量特别大,同时读缓存没有读到缓存,又同时去数据库去数据,引起数据库压力瞬间增大,造成过大压力。
缓存击穿,一般指热键在过期失效的一瞬间,还没来得及重新生产,就有海量数据,直达数据库。
解决方案:
1.热点数据支持续期,持续访问的数据可以不断续期,避免因为续期而失效而被击穿
2.发现缓存失效,重建缓存加互斥锁,当线程查询缓存发现缓存不存在就会尝试加锁,线程争抢锁,拿到锁的线程进行查询数据库,然后重建缓存,争抢锁失败的线程,加一个睡眠然后循环重试。
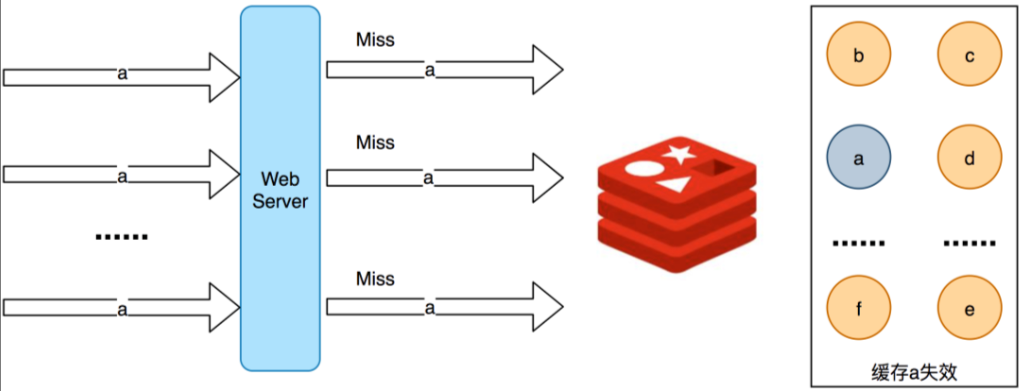
缓存雪崩
缓存雪崩,指大量的应用请求因为异常无法在Redis缓存中进行处理,像雪崩一样,直接打到数据库。
异常原因主要是:缓存中数据大批量到过期时间,而查询数据量大,引起数据库压力增大甚至宕机。
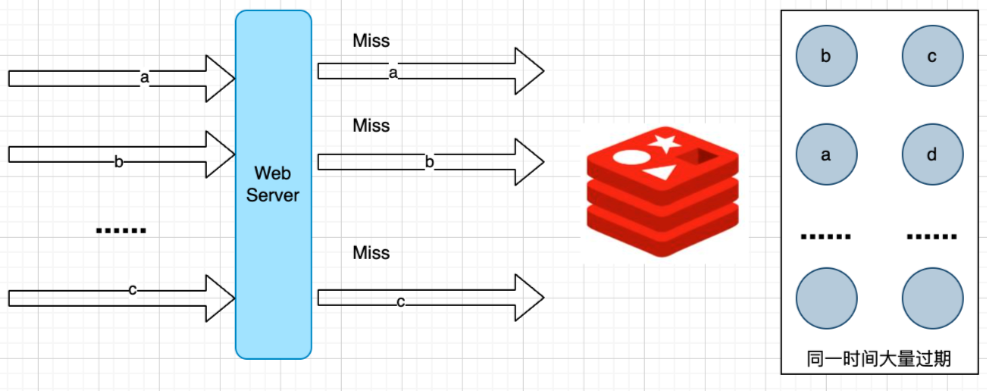
和缓存击穿不同的是,缓存击穿是指一条热点数据没在Redis及时重建,缓存雪崩是大批量数据在Redis同时失效。
解决方案:
1.缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发送。
2.重建缓存加互斥锁,当线程拿到缓存后发现缓存不存在就会尝试加锁,线程争抢锁,拿到锁的线程进行查询数据库,重建缓存,争抢锁失败的线程加一个睡眠然后循环重试。
缓存一致性
部分图解来自于:https://www.mianshiya.com/
不推荐使用:
1.先写缓存再写数据库
2.先写数据库再写缓存
3.先删除缓存再写数据库
推荐使用:
4.先写数据库再删缓存
5.缓存双删
6.Binlog异步更新
先写缓存再写数据库
部分图解来自于:https://www.mianshiya.com/
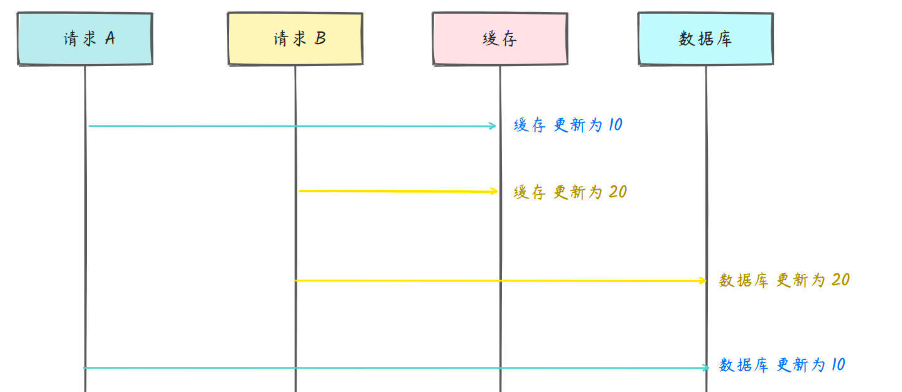
由于网络问题,请求顺序无法保证,有可能出现,后更新缓存的请求反而先更新了数据库。
先写数据库再写缓存
部分图解来自于:https://www.mianshiya.com/
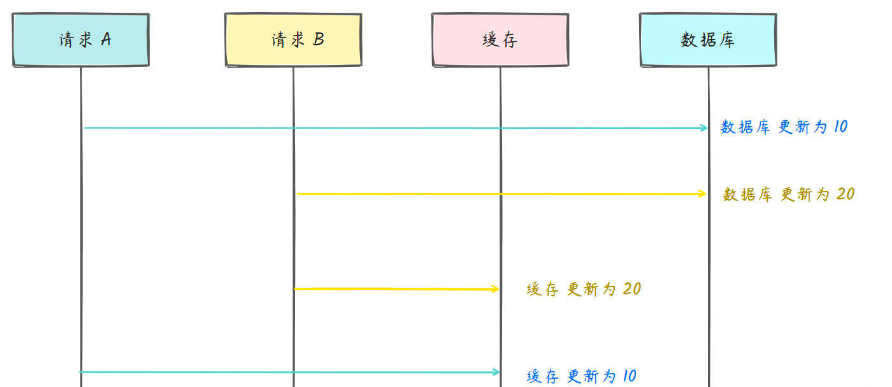
同样的,后更新数据库的请求先更新了缓存。
先删除缓存再写数据库
部分图解来自于:https://www.mianshiya.com/
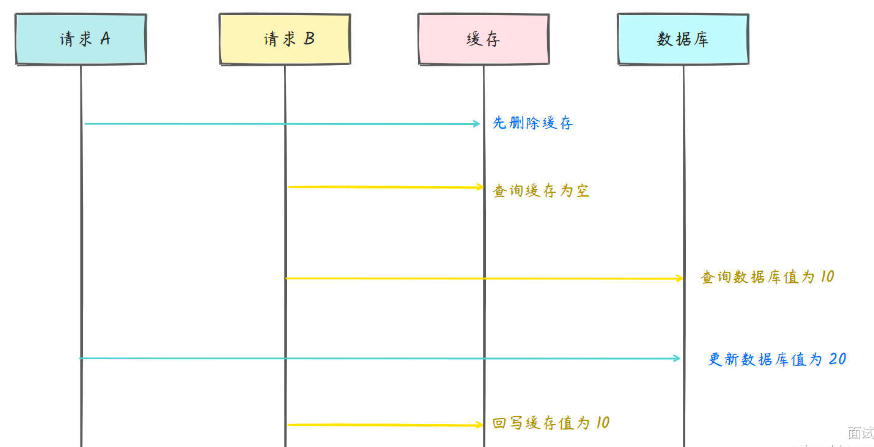
读操作读到了过期的数据,虽然写操作已经完成了,但是因为缓存被删除了,读操作必须从数据库读到了更新前的旧值。
先写数据库再删缓存
部分图解来自于:https://www.mianshiya.com/
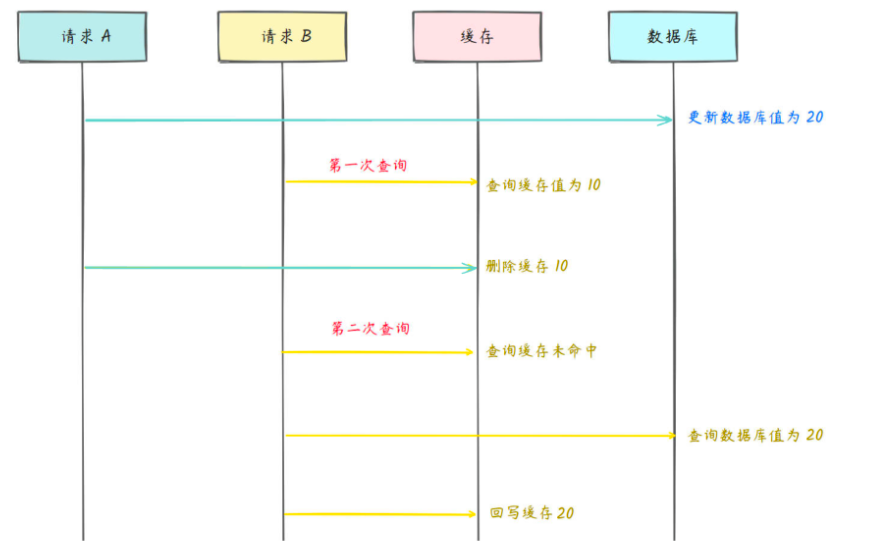
先修改数据库的值,再去删除对应缓存,在修改数据库期间允许一定时间的缓存不一致,保证最终程序一致性。
但是也会有一定的问题:
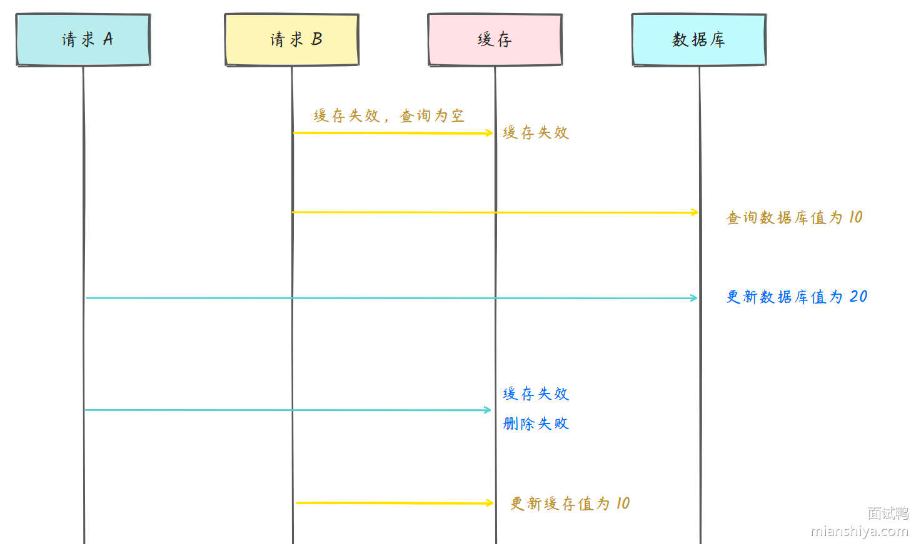
在写操作时,并发有个读请求,又因为缓存失效,读请求在写操作之后更新缓存,导致数据库和缓存不一致。
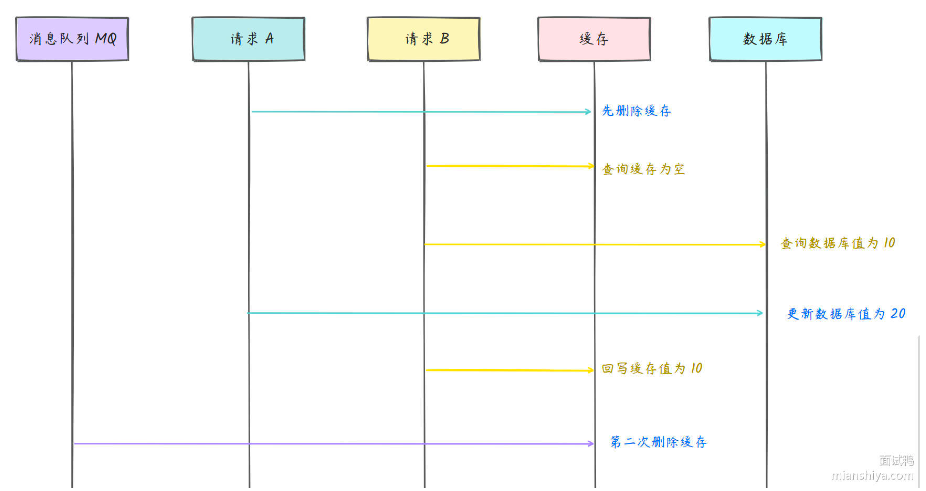
缓存双删
缓存双删,先删除数据库,再写数据库,过一段时间再删除缓存
部分图解来自于:https://www.mianshiya.com/
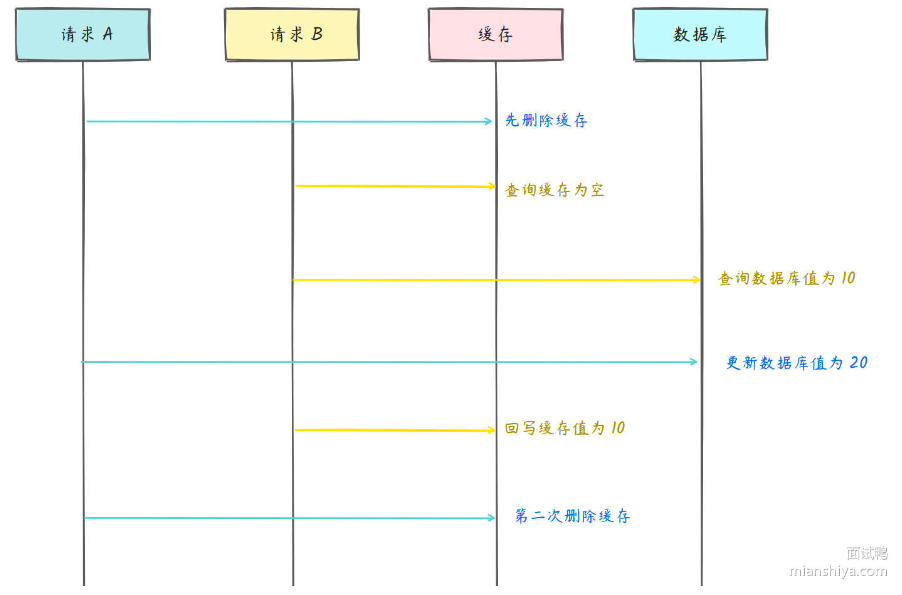
避免数据被回种到缓存,间隔一段时间删除缓存。
也可以使用消息队列、定时任务或延迟任务实现删除:
Binlog异步更新
部分图解来自于:https://www.mianshiya.com/
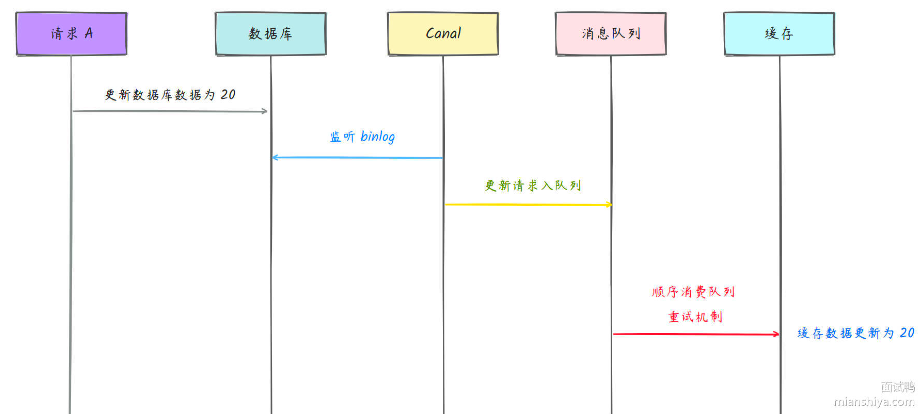
先修改数据库,然后通过Canal监听数据库的binlog日志,记录数据库的修改信息,然后通过消息队列异步修改缓存的数据。这里注意保证顺序消费,保证缓存中数据按顺序更新,然后加上重试机制,避免网络问题导致更新失败。
总结
1.一般不使用前三种方式
2.后三种根据使用场景进行选择
- 实时一致性:考虑先写MySQL,再删Redis(有短期不一致,但它能尽量保证数据一致性)
- 最终一致性:考虑binlog+消息队列(因为重试和顺序消费,最大限度保证缓存与数据库最终一致性)




![[028-3].第05节:RabbitMQ中的交换机](https://i-blog.csdnimg.cn/direct/f23424614214428288fbb0aa8c0d7da3.png)