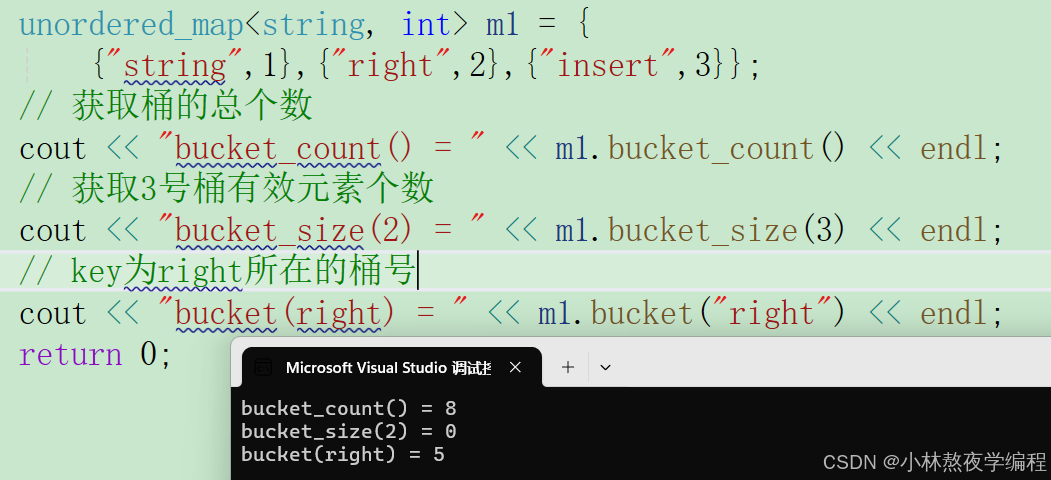
matlab R2024a以上
一、数据集

二、2024年新SCI顶刊算法信息获取优化算法IAO
本期介绍了一种名为信息获取优化算法Information acquisition optimizer,IAO的元启发式算法。该算法受人类信息获取行为的启发,由信息收集、信息过滤和评估以及信息分析和组织三个关键策略组成,以适应不同的优化需求。该成果于2024年8月最新发表在国际顶级SCI期刊 Journal of Supercomputing。

IAO算法是一种创新的尝试,通过模拟人类信息获取行为来解决优化挑战。IAO算法成功地整合了信息收集、信息过滤和评估,以及信息分析和组织三种策略,从而在全局优化问题上表现出色。实验结果表明,IAO算法在基准套件和真实问题上表现出优异的性能,充分验证了其有效平衡探索和利用以获得精确解决方案并确保快速收敛的能力。这种独特的平衡能力使IAO算法在处理各种复杂优化任务方面表现出色。
信息收集
信息收集是获得有用信息的关键步骤,为了确保获得更全面的初始信息,个人采用各种方法从不同来源收集信息,形成初始信息系统。这个过程可以表示如下:

信息过滤与评估
在当今信息过载的背景下,过滤和评估信息的过程已经成为个人迅速辨别相关和有用信息的关键机制,这不仅能有效地消除不准确和误导性信息,还显著提高所获取信息的整体质量。这个过程激发了IAO算法探索阶段的数学表示,可以表达为:

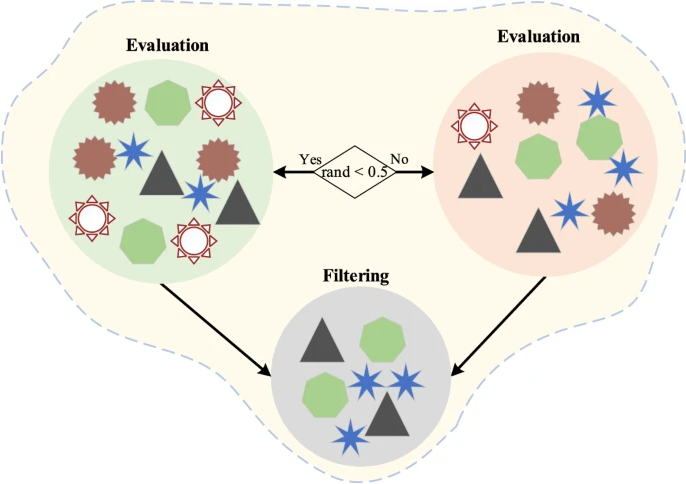
信息分析和整理
信息分析和组织的目的是识别从筛选后的信息中已有的有用信息,并将在前一个阶段中确定的可转换信息转化为有用信息,从而增加获得最佳信息体的概率。此过程如图4所示。它对应于IAO算法的开发阶段,其数学模型表示为:
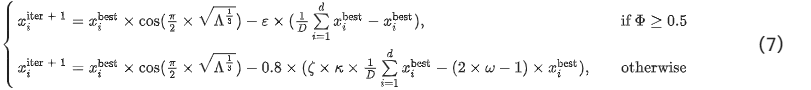


三、Transformer-GRU模型
Transformer-GRU 是一种将 Transformer 和 GRU(Gated Recurrent Unit)两种深度学习模型结合的混合架构,旨在利用两者的优势来处理自然语言处理(NLP)任务。以下是对 Transformer-GRU 模型的介绍:
1. Transformer 简介
- Transformer 是一种基于自注意力机制(Self-Attention)的模型,广泛应用于各种 NLP 任务,如机器翻译、文本生成等。它由编码器和解码器两部分组成,完全抛弃了传统的循环神经网络(RNN)结构,使得模型能够并行处理数据,显著提高了训练速度和性能。
- Transformer 的核心在于其自注意力机制和多头注意力(Multi-Head Attention),可以捕捉输入序列中各个位置之间的依赖关系,从而在处理长序列数据时表现出色。
2. GRU 简介
- GRU 是一种 RNN 的变体,与 LSTM(Long Short-Term Memory)一样,旨在解决传统 RNN 在处理长序列数据时存在的梯度消失问题。GRU 通过引入门控机制(包括更新门和重置门)来控制信息的流动,使得模型能够更好地保留长期依赖信息,同时简化了 LSTM 的结构。
- GRU 的优势在于结构简单、计算效率较高,且在一些任务中能够取得与 LSTM 相当甚至更好的效果。
3. Transformer-GRU 的架构
- Transformer-GRU 模型将 Transformer 和 GRU 结合在一起,通常会以如下两种方式进行融合:
- 串联方式(Sequential Fusion):首先使用 Transformer 处理输入序列,提取全局上下文信息,再将提取的特征输入到 GRU 中,以利用 GRU 的门控机制进行进一步的序列建模。
- 并联方式(Parallel Fusion):将 Transformer 和 GRU 同时应用于输入序列,然后将两者的输出结果进行融合(例如通过加权平均或拼接),以获取综合特征。
- 这种结合利用了 Transformer 的全局建模能力和 GRU 的顺序依赖建模能力,适合处理那些既需要捕捉全局上下文信息又需要考虑顺序依赖的任务。
优势:Transformer-GRU 模型结合了 Transformer 的全局上下文建模能力和 GRU 的时间序列依赖建模能力,具有更强的表达能力。
挑战:这种混合模型的设计和训练可能会更加复杂,特别是在需要调优两种模型的超参数时。
四、效果展示
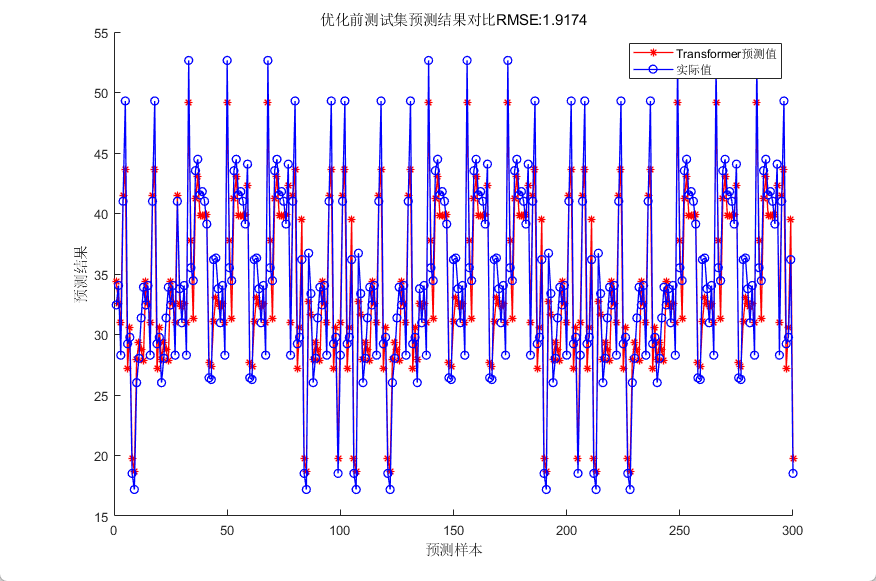



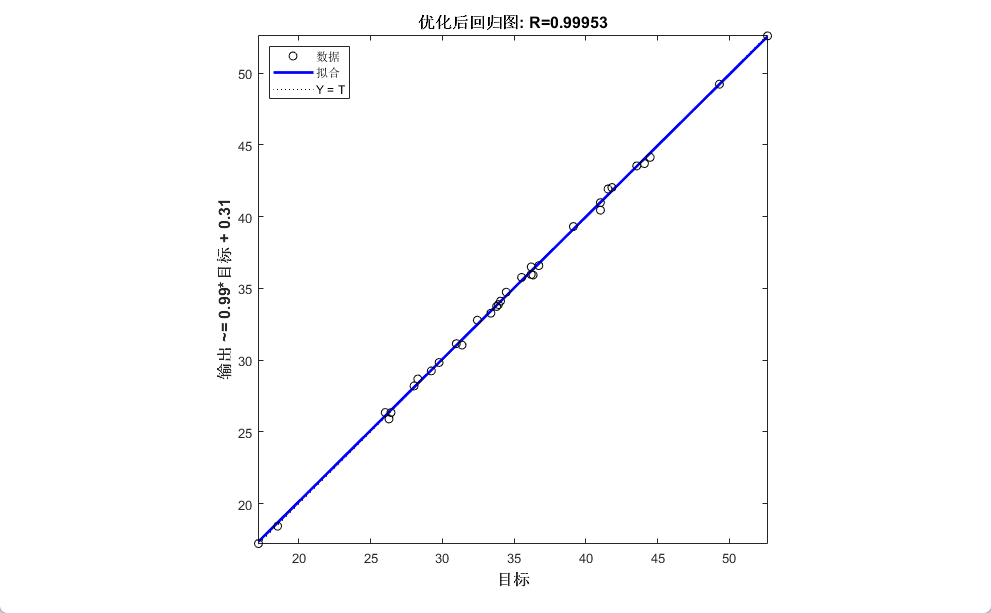
预测结果评价指标:
RMSE = 0.24832
MSE = 0.061661
MAE = 0.19665
MAPE = 0.0012606
相关系数R = 0.99953
决定系数R^2为: 0.999
Transformer注意力机制个数::5
lstm隐层单元个数::7
最佳初始学习率为:0.0037222
最佳L2正则化系数为:0.0001
五、代码获取
感兴趣的朋友可以关注最后一行
% 参数设置
options0 = trainingOptions('adam', ...
'Plots','none', ...
'MaxEpochs', 100, ...
'MiniBatchSize', 32, ...
'Shuffle', 'every-epoch', ...
'InitialLearnRate', 0.01, ...
'L2Regularization', 0.002, ... % 正则化参数
'ExecutionEnvironment', "auto",...
'Verbose',1);
% 网络训练
net0 = trainNetwork(p_train,t_train,lgraph0,options0);
% https://mbd.pub/o/bread/mbd-ZpqTlJdx