文章目录
- 🌈 一、准备工作
- 🌈 二、多表查询
- ⭐ 1. 多表笛卡尔积
- ⭐ 2. 多表查询示例
- 🌈 三、自连接
- 🌈 四、子查询
- ⭐ 1. 标量子查询
- ⭐ 2. 多行子查询 (需要插入其他博客的链接)
- ⭐ 3. 多列子查询 (需要插入其他博客的链接)
- ⭐ 4. 在 from 子句中使用子查询 (一切皆表)
- 🌈 五、合并查询
- ⭐ 1. union
- ⭐ 2. union all

🌈 一、准备工作
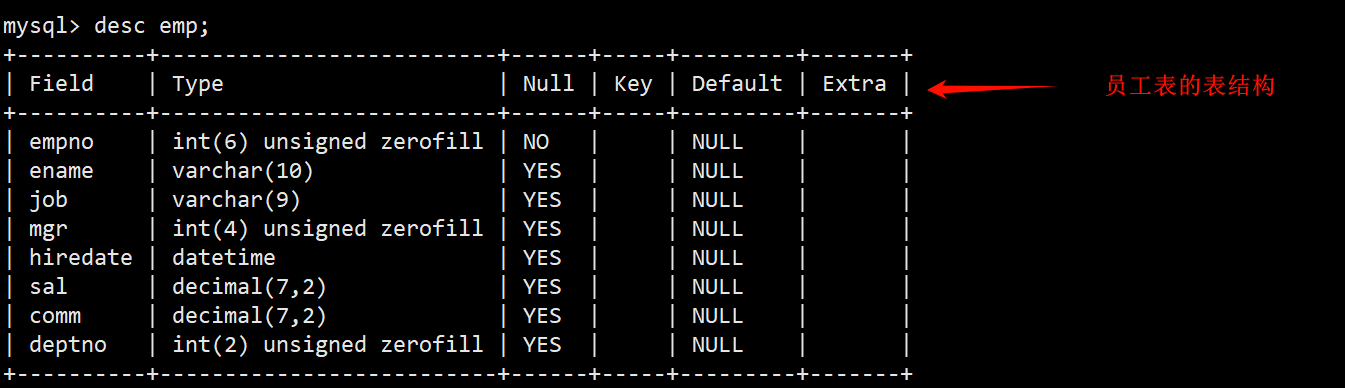
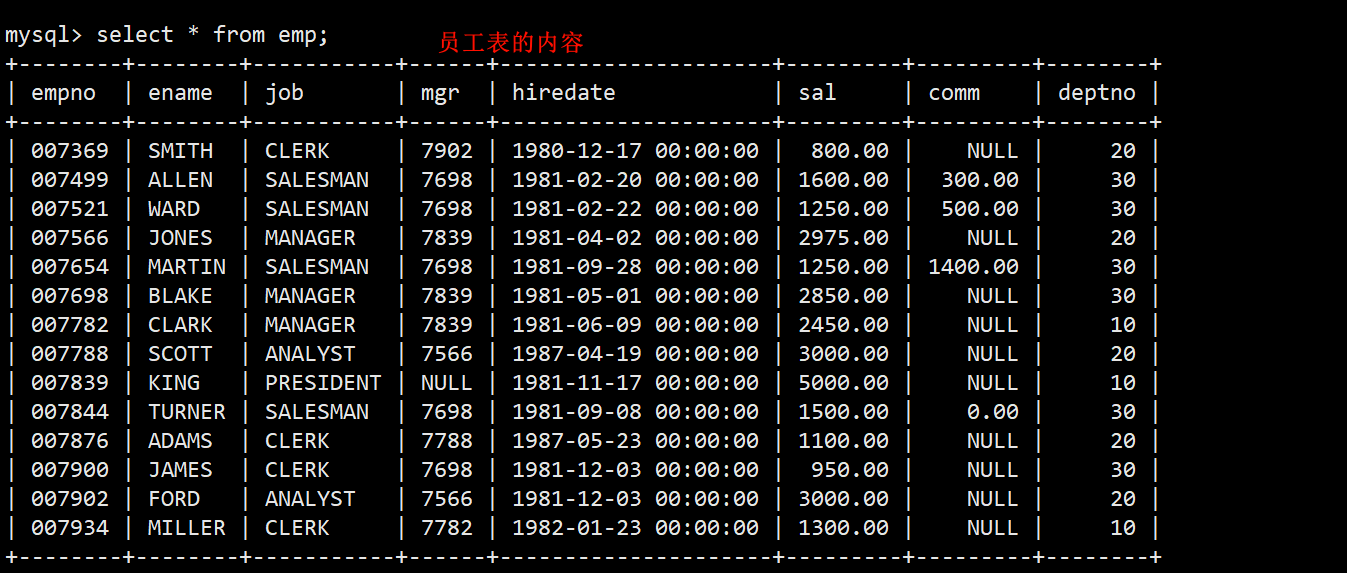
- 当前有三张表,分别是:部门表 dept,员工表 emp,薪资等级表 salgrade,之后的查询工作主要依赖于这三张表进行。
- 这三张表各自包含的字段和每个字段的内容如下。
- 员工表 emp:员工编号 (empno)、员工姓名 (ename)、员工职位 (job)、员工领导的编号 (mgr)、雇佣时间 (hiredate)、月薪 (sal)、奖金 (comm)、部门编号 (deptno)。
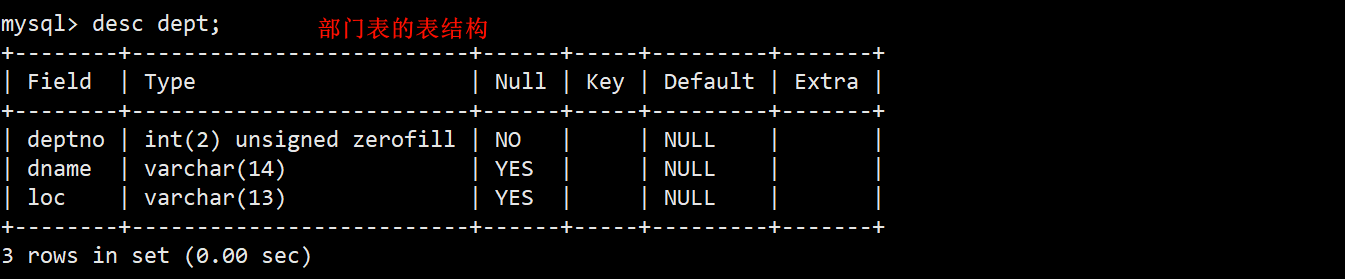
- 部门表 dept:部门编号 (deptno)、部门名称 (dname)、部门所在地 (loc)。

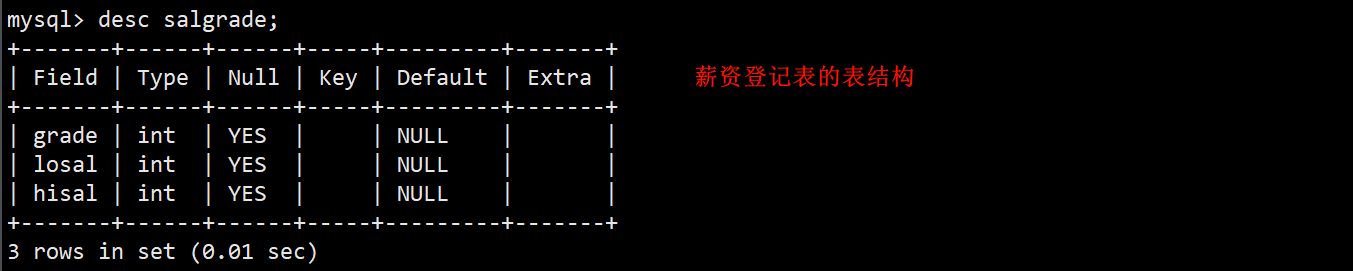
- 薪资登记表 salgrade:等级 (grade)、此等级最低工资 (losal)、此等级最高工资 (hisal)。

🌈 二、多表查询
select * from 表1 , 表2, ..., 表n;
-
在实际开发中实际开发中数据通常来自不同的表,需要对多张表关联起来进行查询,这种查询被称为多表查询。
-
在进行多表查询时,只要将多张表的表名用逗号隔开依次放到 from 子句之后即可,MySQL 会对这多张表取笛卡尔积,用取到的笛卡尔积来作为多表查询的数据。
-
多表查询的本质:多表查询就是对多张表取笛卡尔积,用笛卡尔积的形式将多张表合并成一张表,然后对这一张表进行单表查询。
⭐ 1. 多表笛卡尔积
-
多表笛卡尔积就是,一张表中的每一条记录都会和另一张表中的所有纪录进行组合。
- 例:A = {a, b, c},B = {1, 2, 3},A 与 B 的笛卡尔积为:a1 a2 a3,b1 b2 b3,c1 c2 c3。
-
在多表查询时,需要消除无效的笛卡尔积。
select * from 表1, 表2 where 表1外键值 = 表2主键值;
举个例子
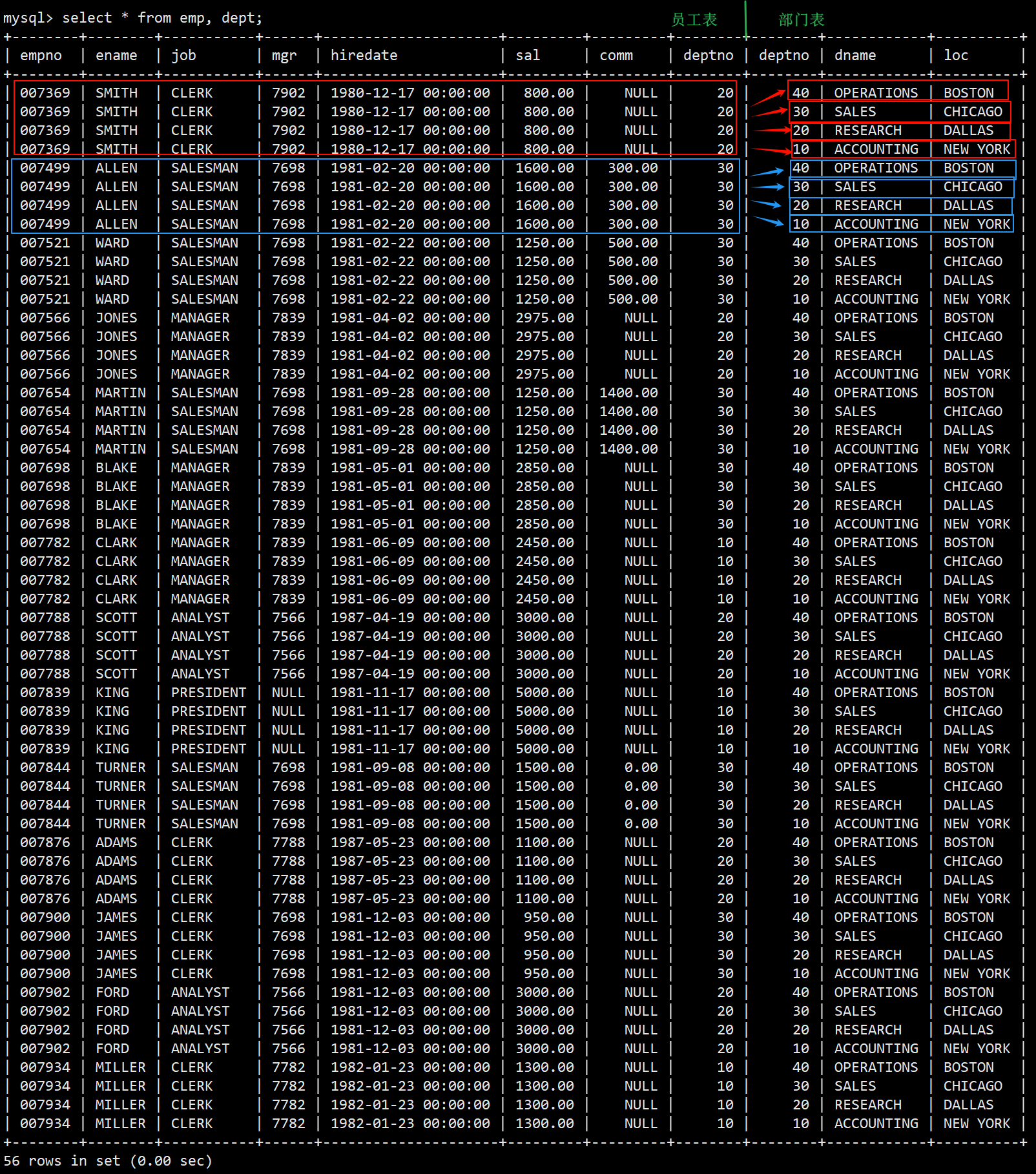
- 对员工表 emp 和部门表 dept 表进行全列的多表查询,由于使用多表查询会产生笛卡尔积,对这两张表进行联合查询的结果如下。
- 员工表 emp 和部门表 dept 合并形成了一张新的大表。
- 员工表 emp 中的每一条记录都会和部门表 dept 中的所有记录进行组合从而产生很多无效的查询数据。
对笛卡尔积进行过滤
-
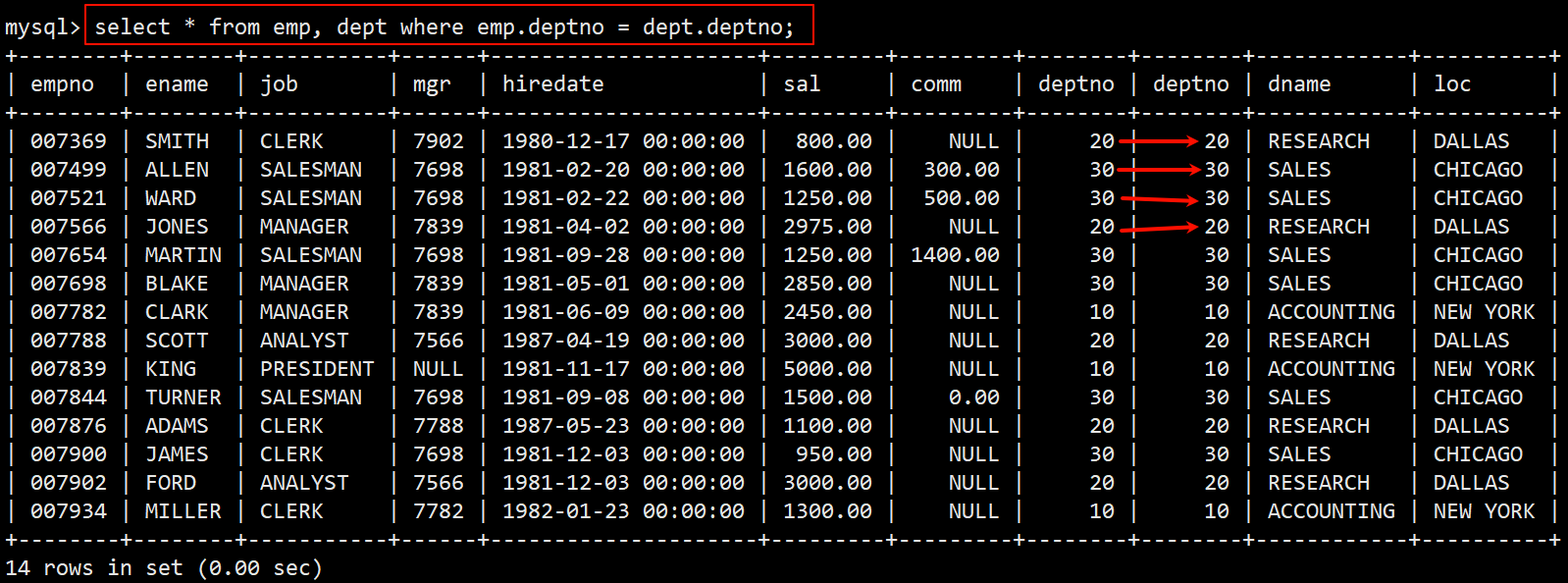
在进行多表查询时,将 emp 和 dept 这两张表合并成了一张表,可使用 where 条件过滤笛卡尔积对这一张表进行查询。
-
例:由于两张表都有 deptno 这个字段,那么只需要筛选出与 emp 表中的 deptno 所对应的部门表的 deptno 即可。
-
假设一个员工的所在部门是 10 号部门,那么他和其他的部门进行组合就没有任何意义,需要过滤掉这些无意义的笛卡尔积。
-
⭐ 2. 多表查询示例
- 为多表查询准备的案例如下:
- 显示雇员名、雇员工资以及所在部门的名字。
- 显示部门号为10的部门名,员工名和工资。
- 显示各个员工的姓名,工资,及工资级别。
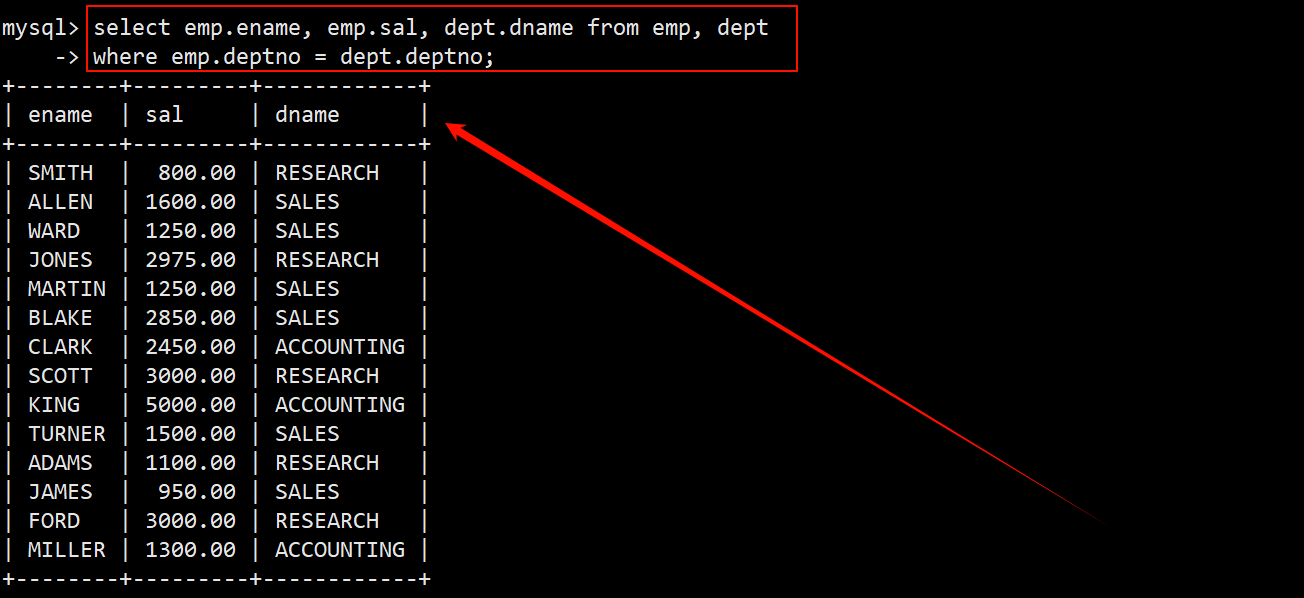
1. 显示雇员名、雇员工资以及所在部门的名字
- 部门名 dname 只存在于部门表 dept 中,而员工名 ename 和员工工资 sal 只存在于员工表 emp 中。需要同时对员工表 emp 和部门表 dept 进行多表查询,在 where 子句中指明筛选条件为 emp.deptno = dept.deptno。
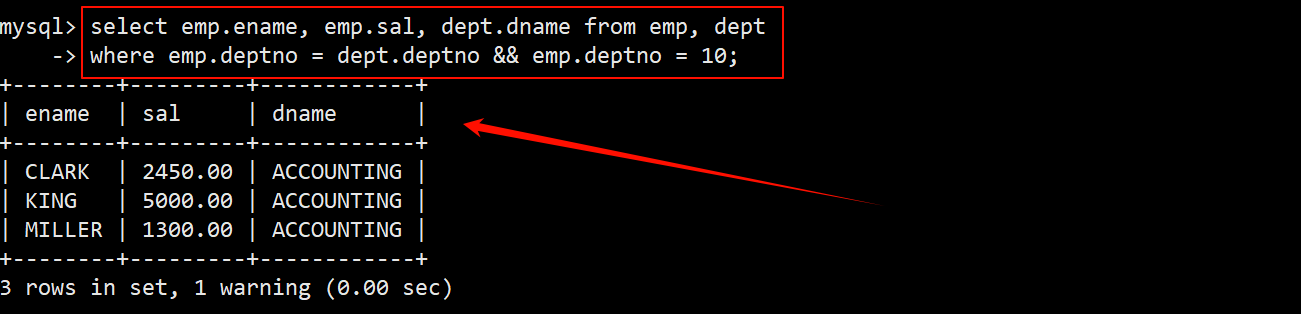
2. 显示部门号为10的部门名,员工名和工资
- 在上一题的基础上,对 where 子句添加一个条件:并且部门号为 10 的记录。
- 该筛选条件可以使用员工表 emp 中的部门编号,也可以使用部门表中的部门编号。
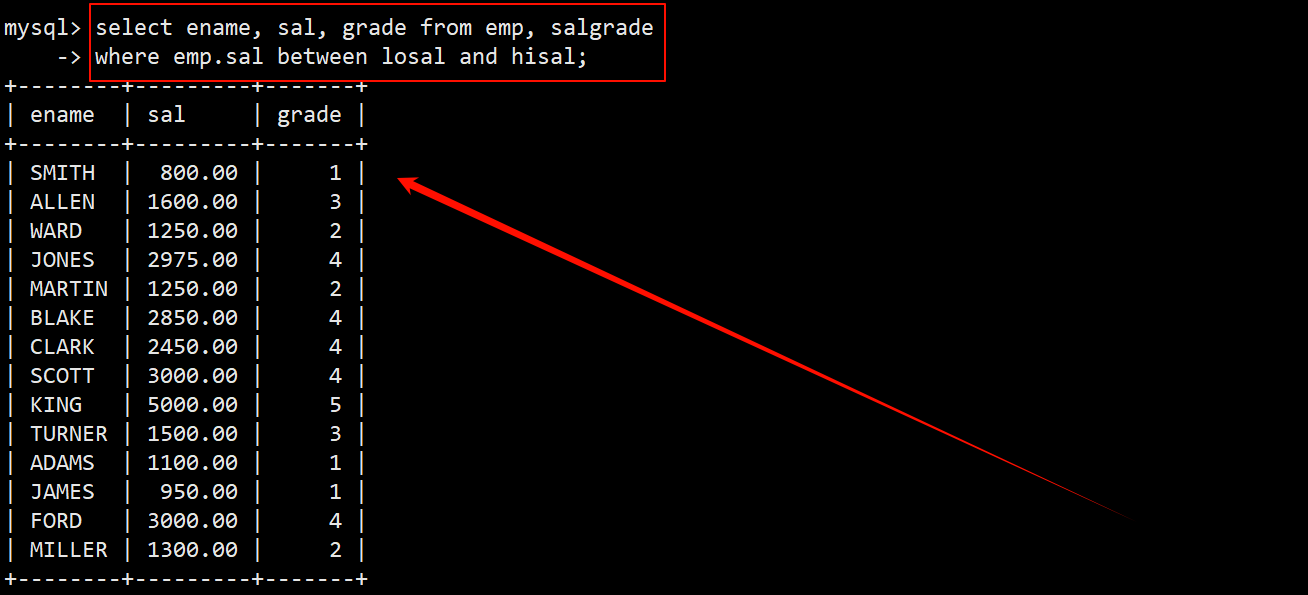
3. 显示各个员工的姓名,工资,及工资级别
- 员工名 ename 和员工工资 sal 只存在于员工表 emp 中,而工资级别 grade 只存在于工资等级表 salgrade 中。需要同时对员工表 emp 和工资等级表 salgrade 进行多表查询,在 where 子句中指定筛选条件为员工的工资在 losal 和 hisal 之间。
🌈 三、自连接
select 字段列表 from 表A as 别名A, 表A as 别名B where 条件 ... ;
- 既然对不同的表取笛卡尔积,同样也能对同一张表取笛卡尔积,对同一张表进行多表 (连接) 查询被称之为自连接。
- 在自连接中,必须对掉取别名。
- 如果一张表中的某个字段能够将表中的多条记录关联起来,则能通过自连接将表中与该字段关联的记录组合起来。
案例:显示员工 FORD 的上级领导的编号和姓名
- 即使是员工的领导,甚至是公司老板,都会被记录在员工表 emp 中,因此 FORD 的上级领导的信息也需要在员工表 emp 中查询。
- 使用子查询解决:先对员工表进行查询得到 FORD 的领导的员工编号 mgr,再根据领导的员工编号从员工表中找到 FORD 领导的信息。

- 使用自连接解决:emp 表中的领导编号 mgr 字段和员工编号字段 empno 可以关联起来。
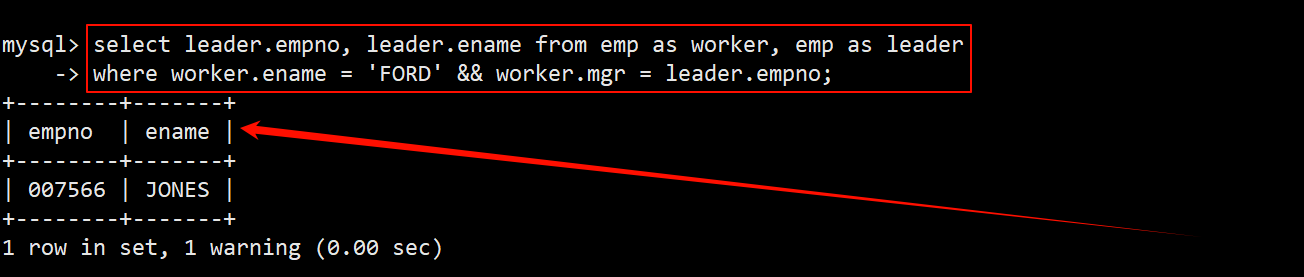
-
因此可以将 emp 通过重命名的方式变成两张表,再对这两张表通过自连接的方式实现多表查询,将这两张表合并成一张未消除笛卡尔积的表。
- 之后的操作就是消除这张表的笛卡尔积,在 where 子句中指定筛选条件为员工的领导编号 mgr 等于领导的员工编号 empno。
🌈 四、子查询
select 字段列表 from t1 where column1 = (select column1 from t2);
-
MySQL 支持在一条查询语句的内部再执行一条查询语句,先执行最内部的查询语句,执行完后外部的 sql 语句根据内部 sql 的查询结果进行查询。
- 嵌套在另一条查询语句中的查询语句被称之为子查询。
-
根据子查询返回的结果可将子查询分为标量子查询、多行子查询、多列子查询,表子查询。
- 标量子查询:子查询返回的结果是单个的值,为单行单列的数据。
- 多行子查询:子查询返回的结果为多行数据,每行都只能有一列。
- 多列子查询:子查询返回的结果为多列数据,每列都只能有一行。
- 表子查询:子查询返回的结果是一张子表,是多行多列的数据。
-
在进行子查询时,如果搞不清楚逻辑,可以先将所有的子查询都拆成一条查询语句,再进行嵌套查询。
⭐ 1. 标量子查询
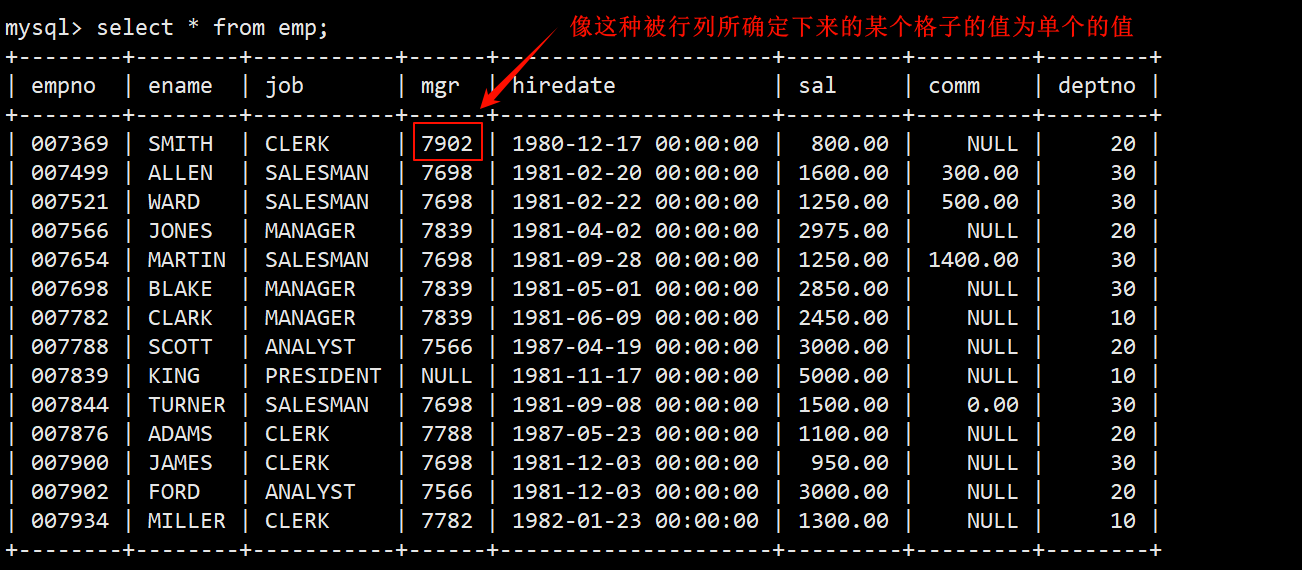
- 子查询返回的结果是是单个的值,即表中背单行单列所框住的某一个格子的值。
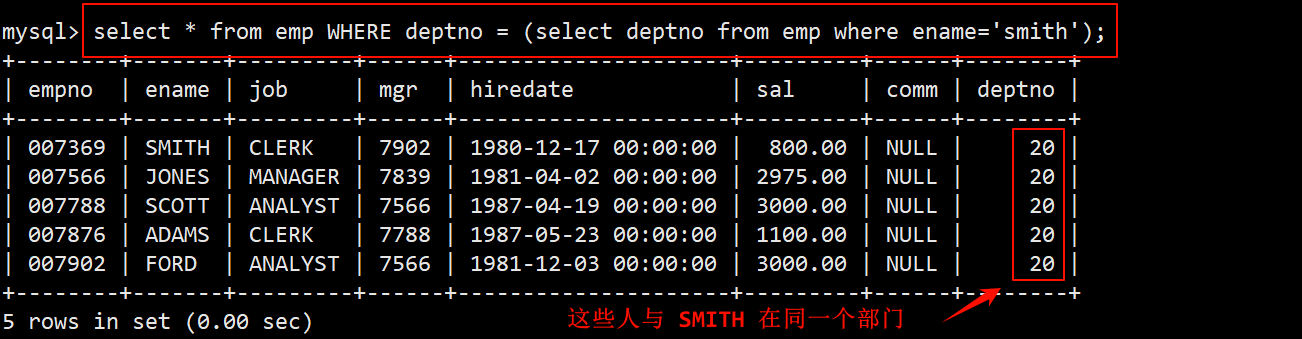
案例:显示与 SMITH 同一部门的员工
- 在子查询中找出 SMITH 所在的部门号 deptno (SMITH 的部门号是单个的值)。

- 在 where 子句中指定筛选条件为员工部门号 deptno 等于子查询返回的部门号。
⭐ 2. 多行子查询 (需要插入其他博客的链接)
- 子查询返回的结果为多行数据,每行都只能有一列。
- 多行子查询的常用操作符:=、<>、in、not in (这些操作符的意思详情见/表的增删查改 (此处要插入对应博客的链接)/中的操作符介绍)。
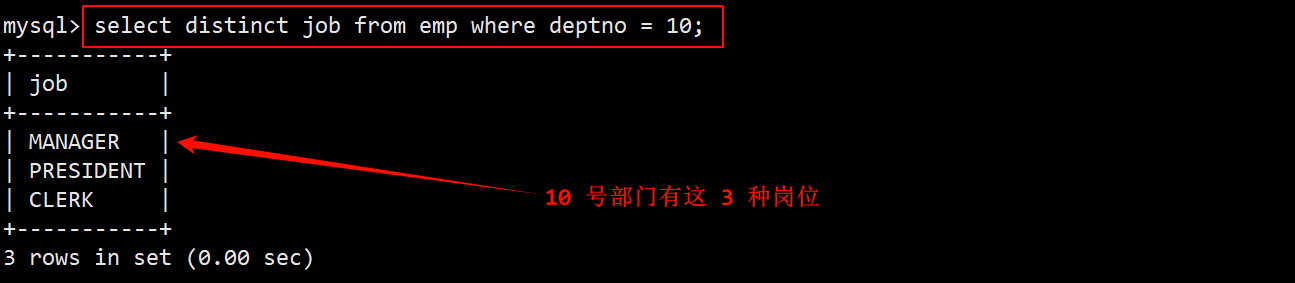
1. 查询和 10 号部门的工作岗位相同的员工的名字岗位,工资,部门号,但是不包含 10 号部门的员工
- 先找出 10 号部门都有哪些工作岗位,由于某些员工的岗位可能相同,因此在查询时还需要进行去重操作。
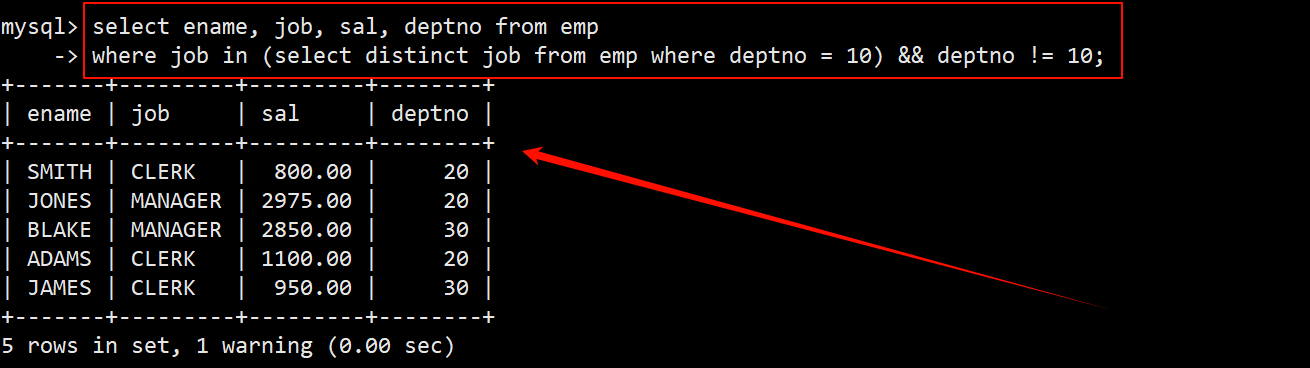
- 再将上述查询作为多行子查询,在 where 子句中使用 in 关键字,判断员工的工作岗位是行子查询得到的这 3 个岗位中的一个。由于还要将 10 号部门的员工给筛出来,因此同时还需要在 where 子句中指定筛选条件为 deptno != 10。
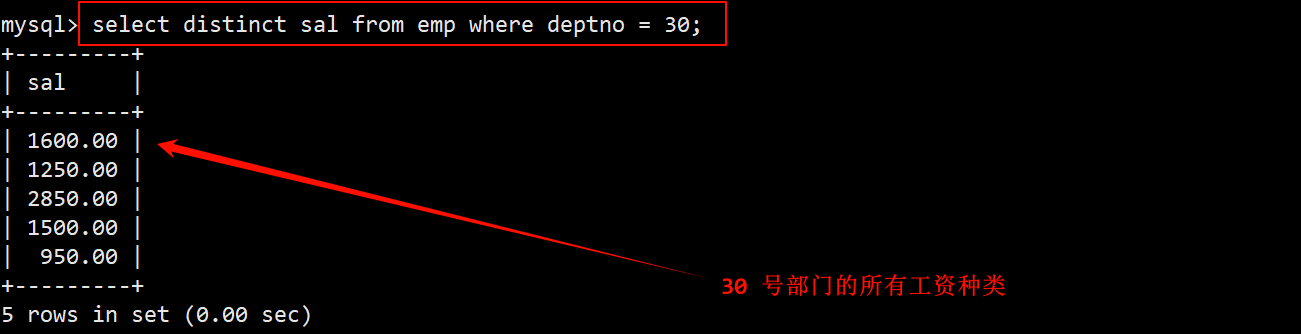
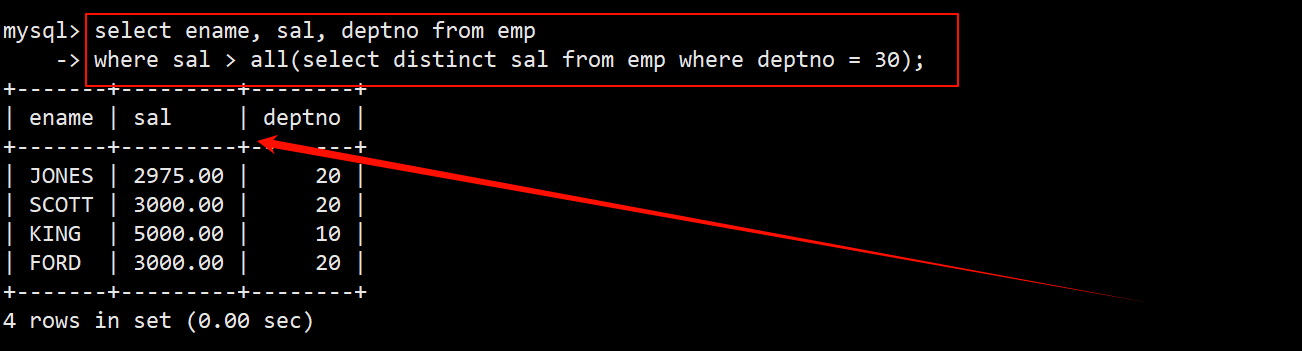
2. 显示工资比 30 号部门的所有员工的工资高的员工的姓名、工资和部门号
- 先找出 30 号部门所有的工资,在查询时最好对结果进行去重。
- 再将上述查询语句作为多行子查询,在 where 子句中使用 all 关键字,判断员工的工资是否 > 行子查询得到的所有工资。
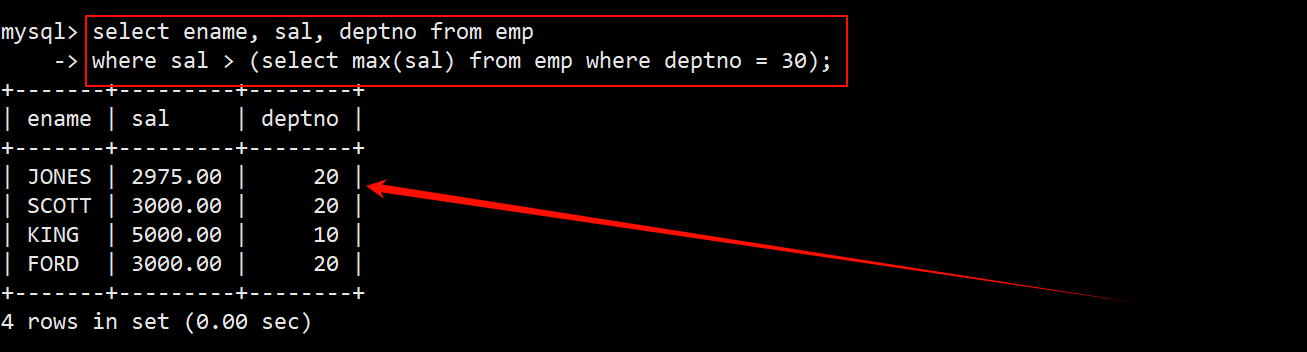
- 这道题也能看作找出员工表中比 30 号部门中的最高薪资高的员工的相关信息,可以使用标量子查询找出 30 号部门的最高薪资。
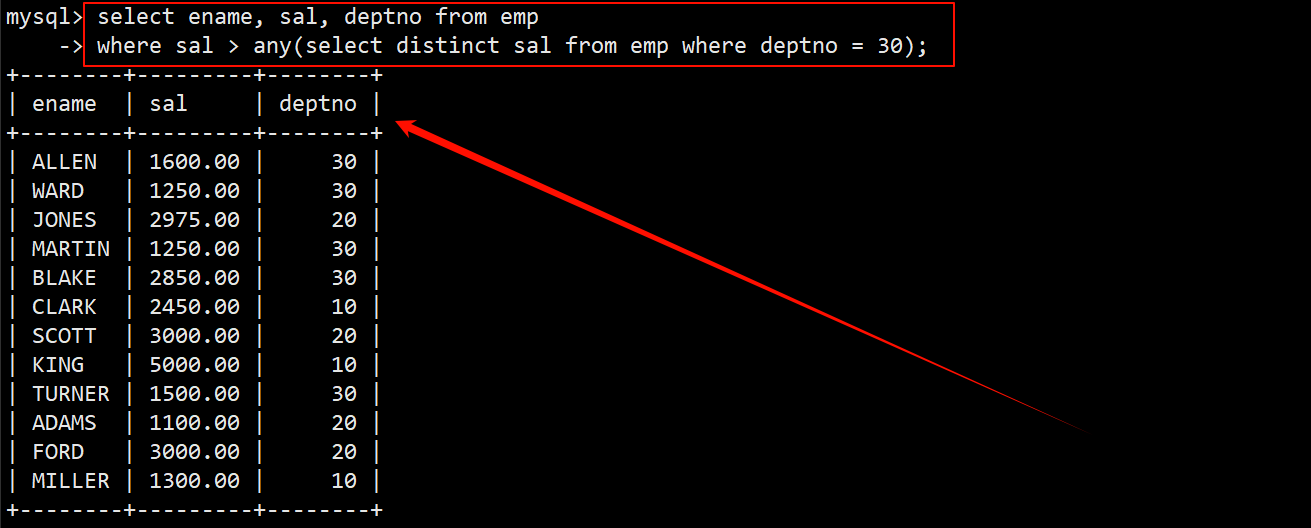
3. 显示工资比 30 号部门的任意员工的工资高的员工的姓名、工资和部门号,包含 30 号部门的员工
- 先找出 30 号部门所有的工资,在查询时最好对结果进行去重。
- 再将上述查询语句最为多行子查询,在 where 子句中使用 any 关键字,只要工资高于行子查询得出的结果中的任意一个即可。
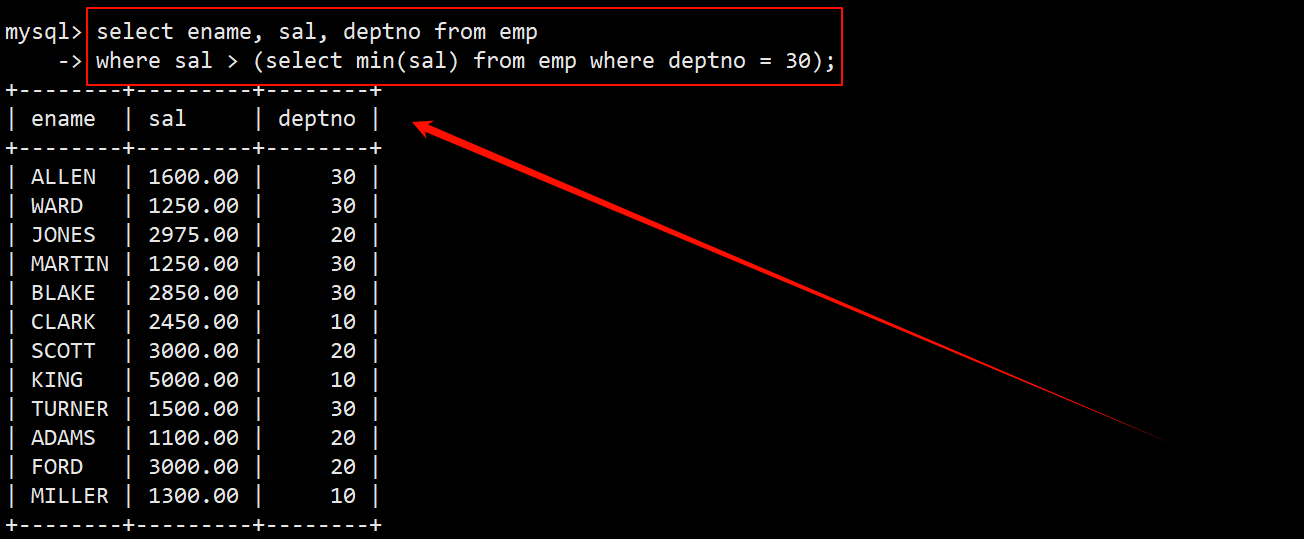
- 换个角度看,大于任意一个表示工资至少要大于 30 号部门的最低薪资才行,可以使用标量子查询找出 30 号部门的最低薪资。
⭐ 3. 多列子查询 (需要插入其他博客的链接)
-
子查询返回的结果为多列数据,每列都只能有一行。
-
多列子查询的常用操作符:in、not in、any、some、all ( (这些操作符的意思详情见/表的增删查改 (此处要插入对应博客的链接)/中的操作符介绍)。
案例:显示和 SMITH 的部门和岗位完全相同的员工,但不包含 SMITH 本人
- 先查询 SMITH 所在部门的部门编号 deptno 以及他的岗位 job。

- 将上述查询作为多列子查询,在 where 子句中,指定筛选条件为部门编号 deptno 和岗位 job 都等于多列子查询得到的部门号和岗位,并且员工的姓名 ename != SMITH。

⭐ 4. 在 from 子句中使用子查询 (一切皆表)
- 子查询不仅仅能在 where 中充当判断条件,也能在 from 子句中充当笛卡尔积。
- 支持这种做法的原因是,在 MySQL 中,一切皆表,因此也能将子查询查出来的结果当成一张临时表来看待。
- 注意:在 from 子句中使用子查询时,必须为子查询得到的临时表取别名。
1. 显示每个高于自己部门平均工资的员工的姓名、部门、工资和部门的平均工资
- 先使用 group by 分组查询找出每个部门的平均工资,显示出来的信息就是所说的临时表。
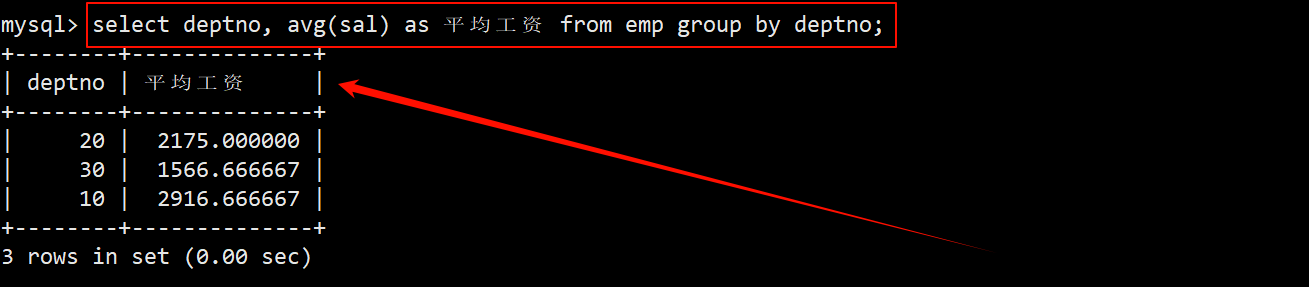
- 将上述查询的结果作为临时表放在 from 子句中,再对员工表和临时表取笛卡尔积。在 where 子句中指定筛选条件为员工的部门号等于临时表中的部门号,并且员工的工资大于临时表中的平均工资。
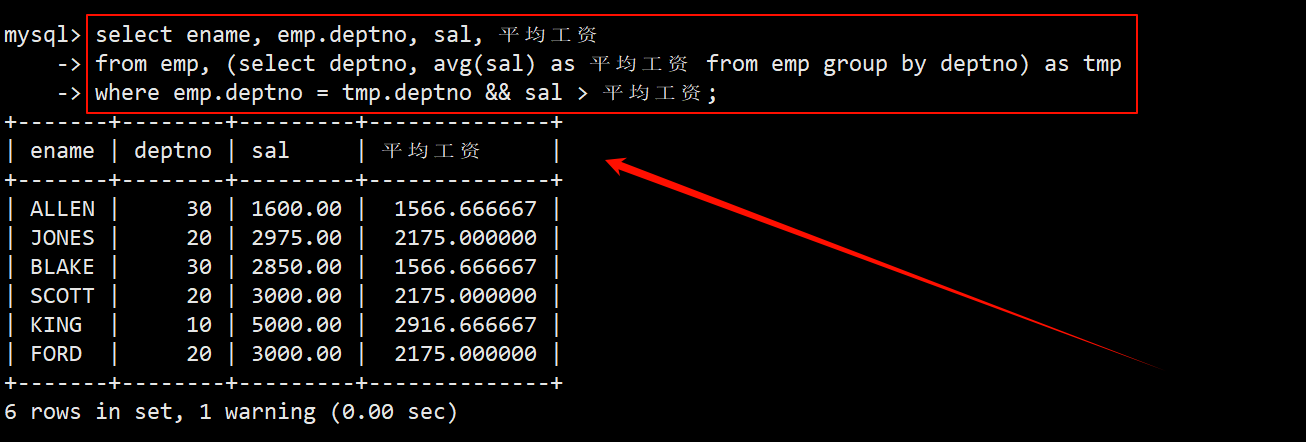
2. 显示每个部门工资最高的员工的姓名、工资、部门和部门的最高工资
- 先使用 max 函数和 group by 分组查询找出每个部门的最高工资。
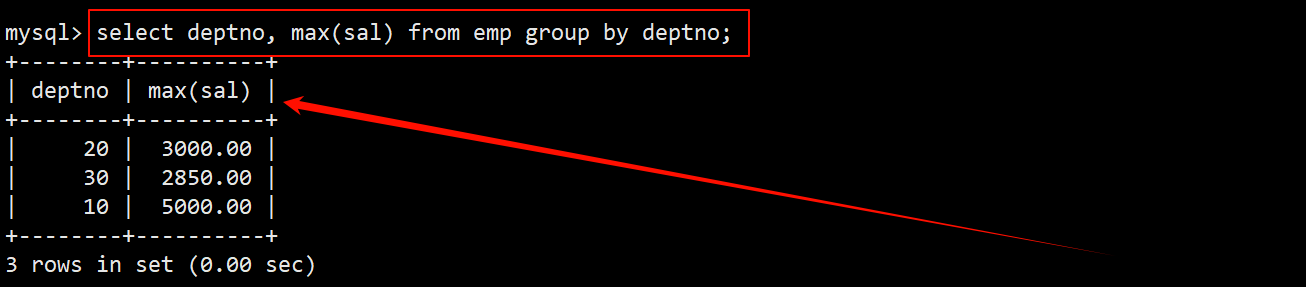
- 将上述查询结果作为临时表放在 from 子句中与 emp 作笛卡尔积,在 where 子句中指定筛选条件为员工的部门号等于临时表的部门号,并且员工的工资等于临时表的最高工资。
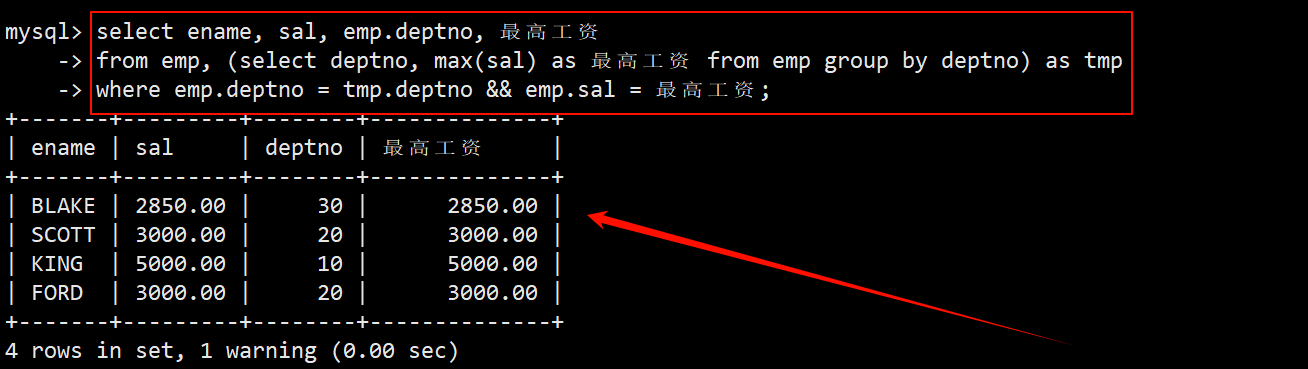
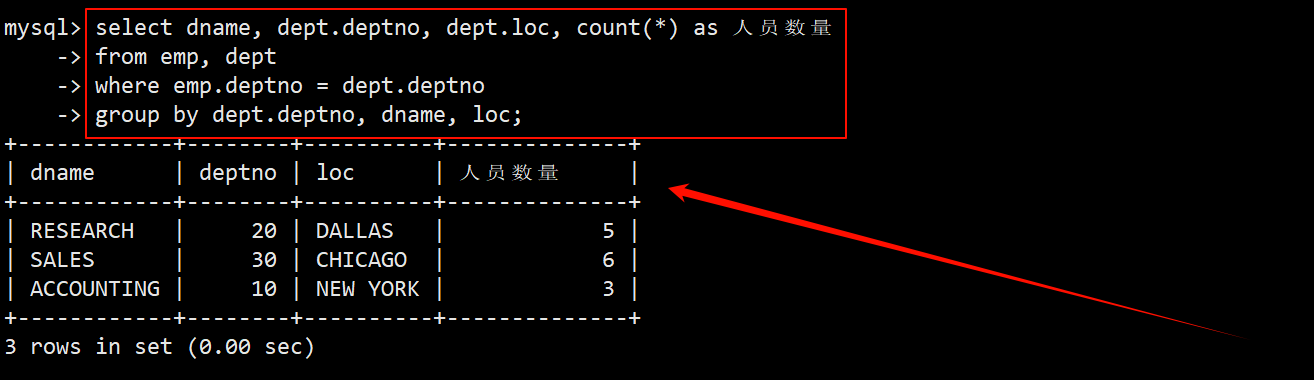
3. 显示每个部门的信息(部门名,编号,地址)和人员数量
- 使用多表查询:对员工表 emp 和部门表取 dept 取笛卡尔积,在 where 子句中指定筛选条件为 emp.deptno = dept.deptno 筛出部门号相同的记录,在 group by 子句中指定按照部门号 deptno、部门名 dname 和部门地址 loc j进行分组,统计出每个部门的人数。
- 使用子查询(推荐):
- 在员工表 emp 中使用 group by 分组查询,找出每个部门的人员数量、部门编号。

- 将上述查询结果作为临时表放进 from 子句中,对部门表和临时表作笛卡尔积,将 where 子句的筛选条件指定为部门表的部门编号等于临时表的部门编号。
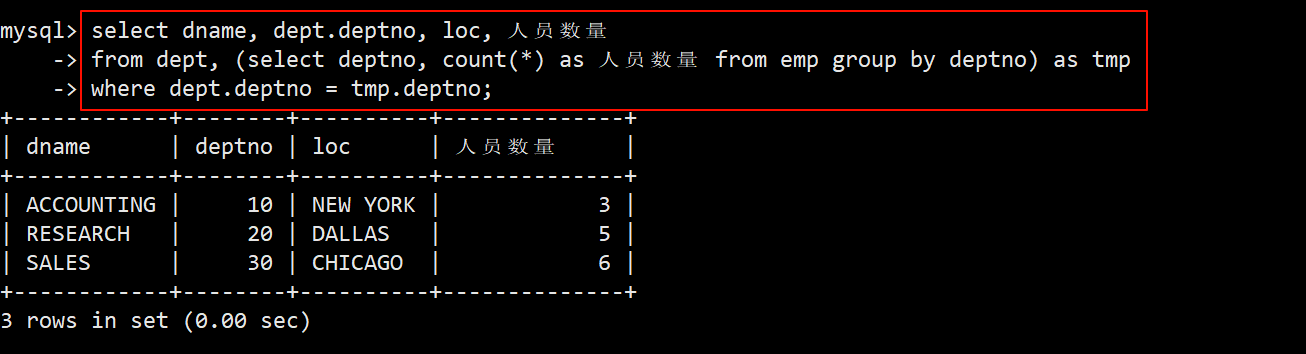
- 由于一切皆表的缘故,该方法其实也算是一种多表查询,只不过是用子查询的形式展现出来了而已。
🌈 五、合并查询
select 字段列表 from 表A ... union [all] select 字段列表 from 表B ... ;
- MySQL 支持将多次查询的结果合并起来,形成一个新的查询结果集,可使用的操作符有 union 和 union all。
- union 和 union all 都能获得多个查询结果的并集,区别是 union 会对合并后的并集进行去重,而 union all 则不会。
- 注意:对于合并查询的多张表的列数必须保持一致,字段类型也需要保持一致。
⭐ 1. union
- 该操作符用于取得两个结果集的并集。当使用该操作符时,会去掉结果集中的重复行。
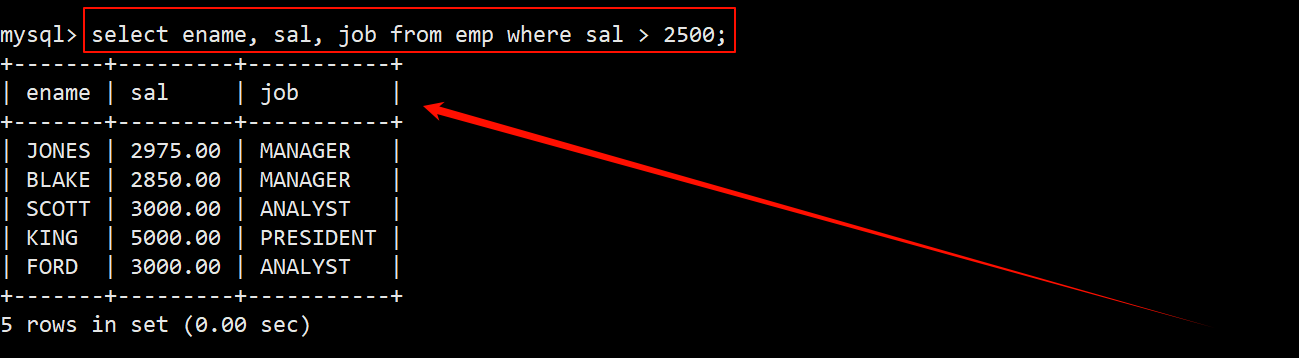
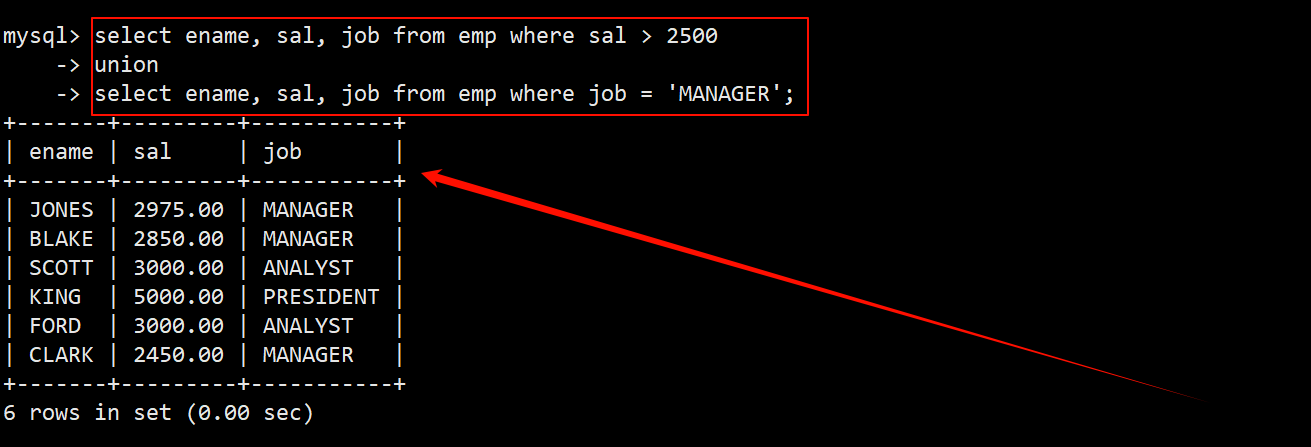
案例:将工资大于 2500 或职位是 MANAGER 的人找出来
- 找出工资 sal 大于 2500 的人。
- 找出职位 job 是 MANAGER 的人。
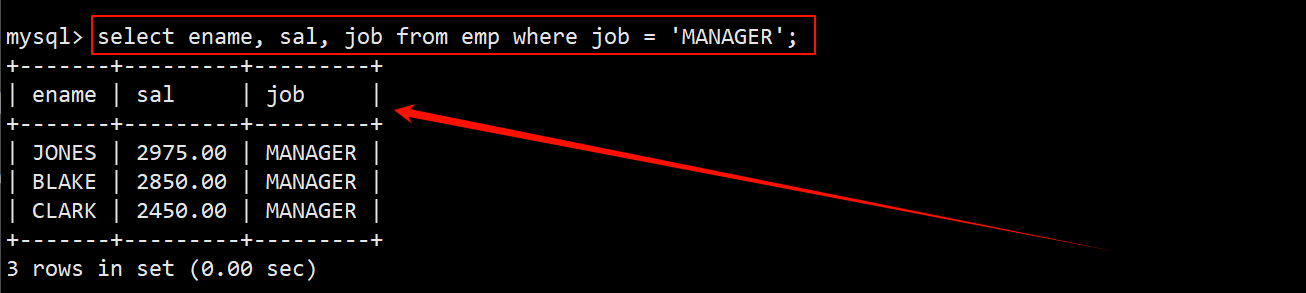
- 使用 union 关键字将上述两种查询结果进行去重合并(合并的前提是两个查询的字段数和字段类型要一致)。
⭐ 2. union all
- 该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。
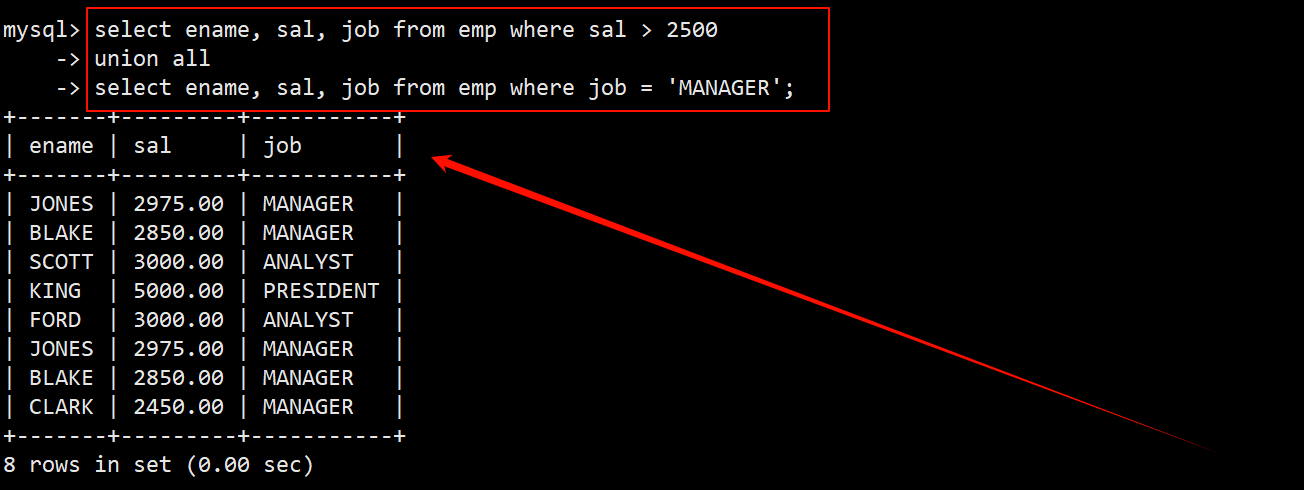
案例:将工资大于 25000 或职位是 MANAGER 的人找出来
- 前置操作就不演示了,直接使用 union 关键字将上述两种查询结果进行不去重合并。














![[数据集][目标检测]夜间老鼠检测数据集VOC+YOLO格式316张1类别+视频文件1个](https://i-blog.csdnimg.cn/direct/3c31e661150241fe855d8e65e8a96ab5.png)



