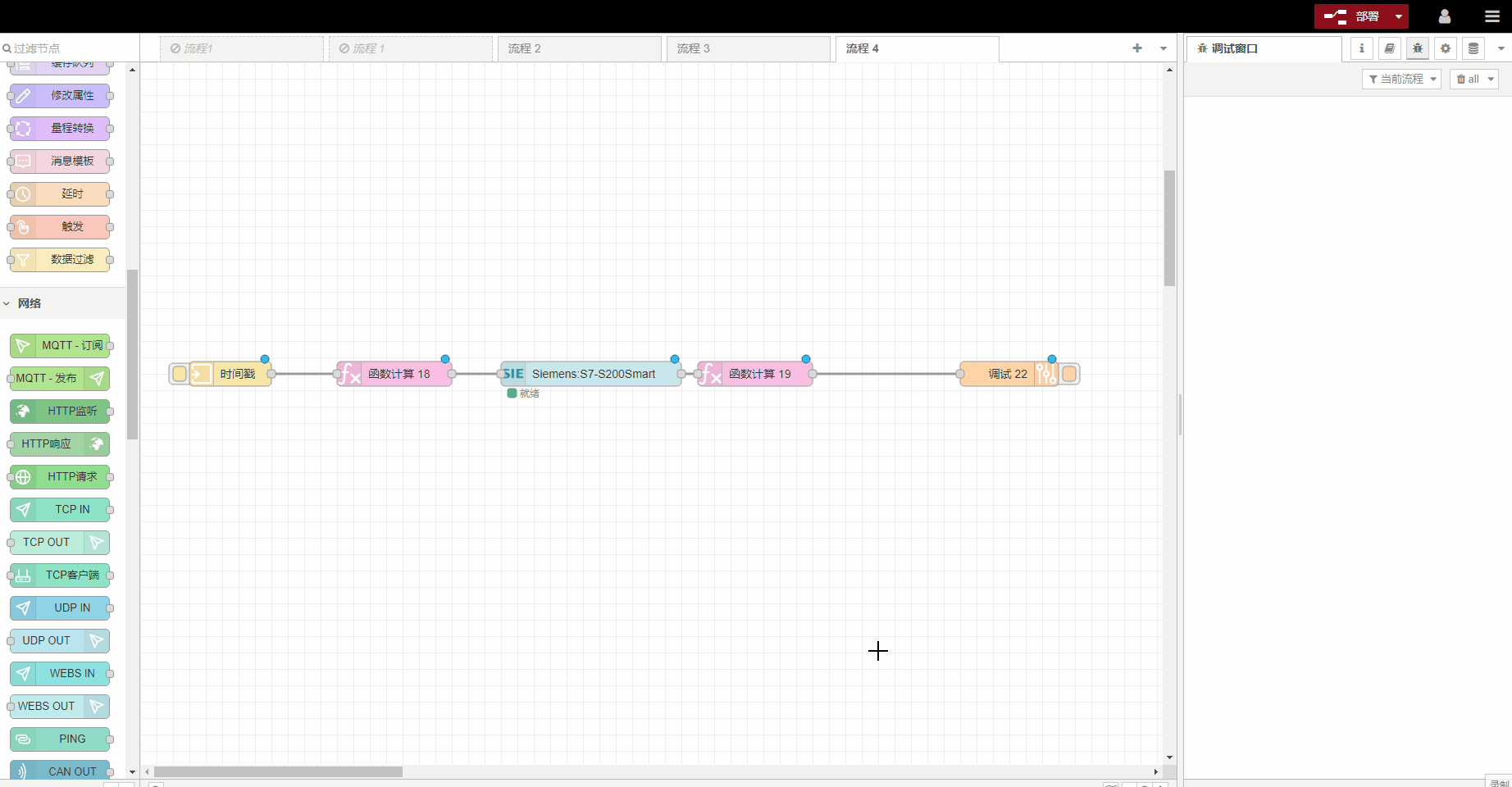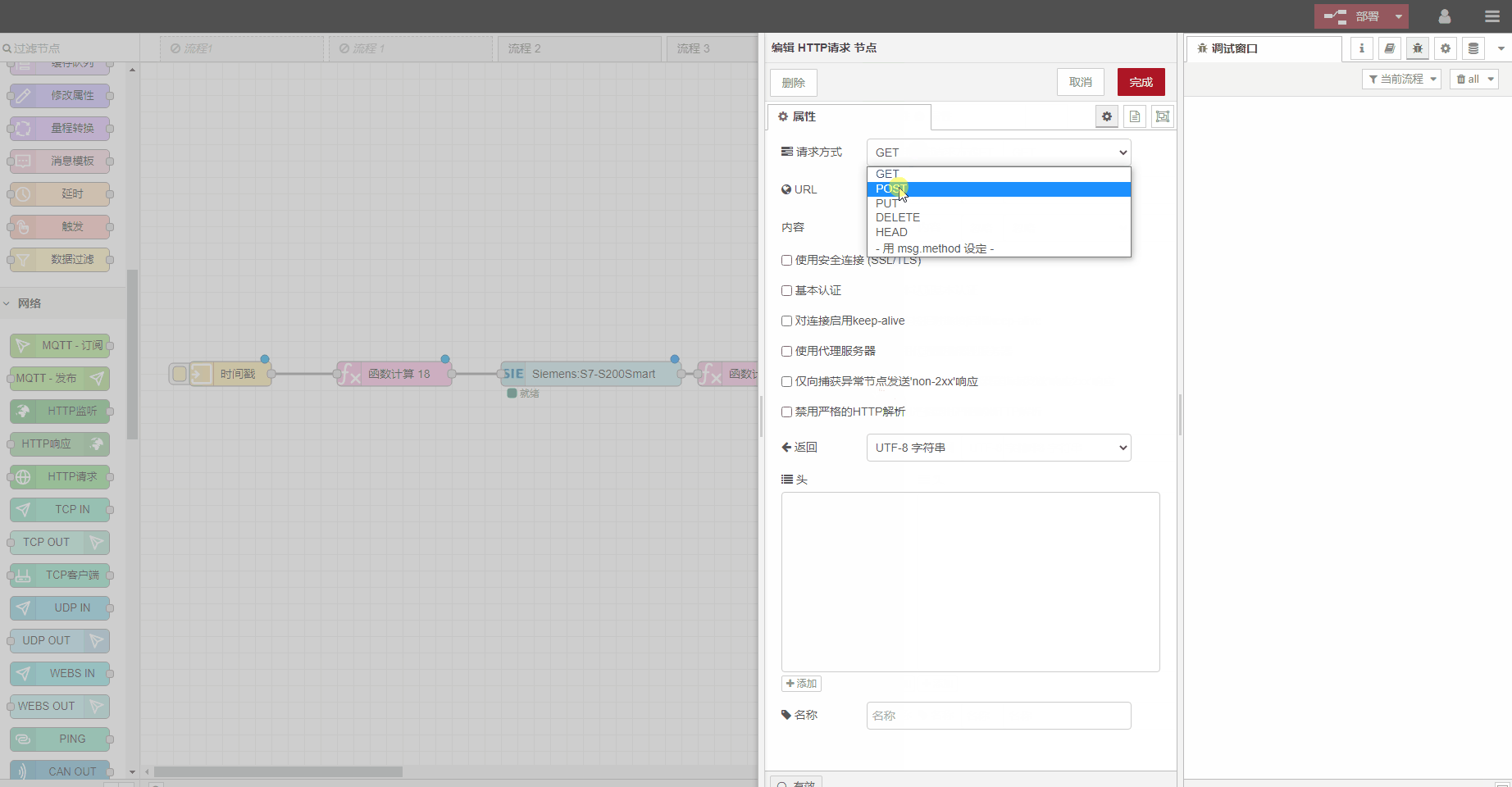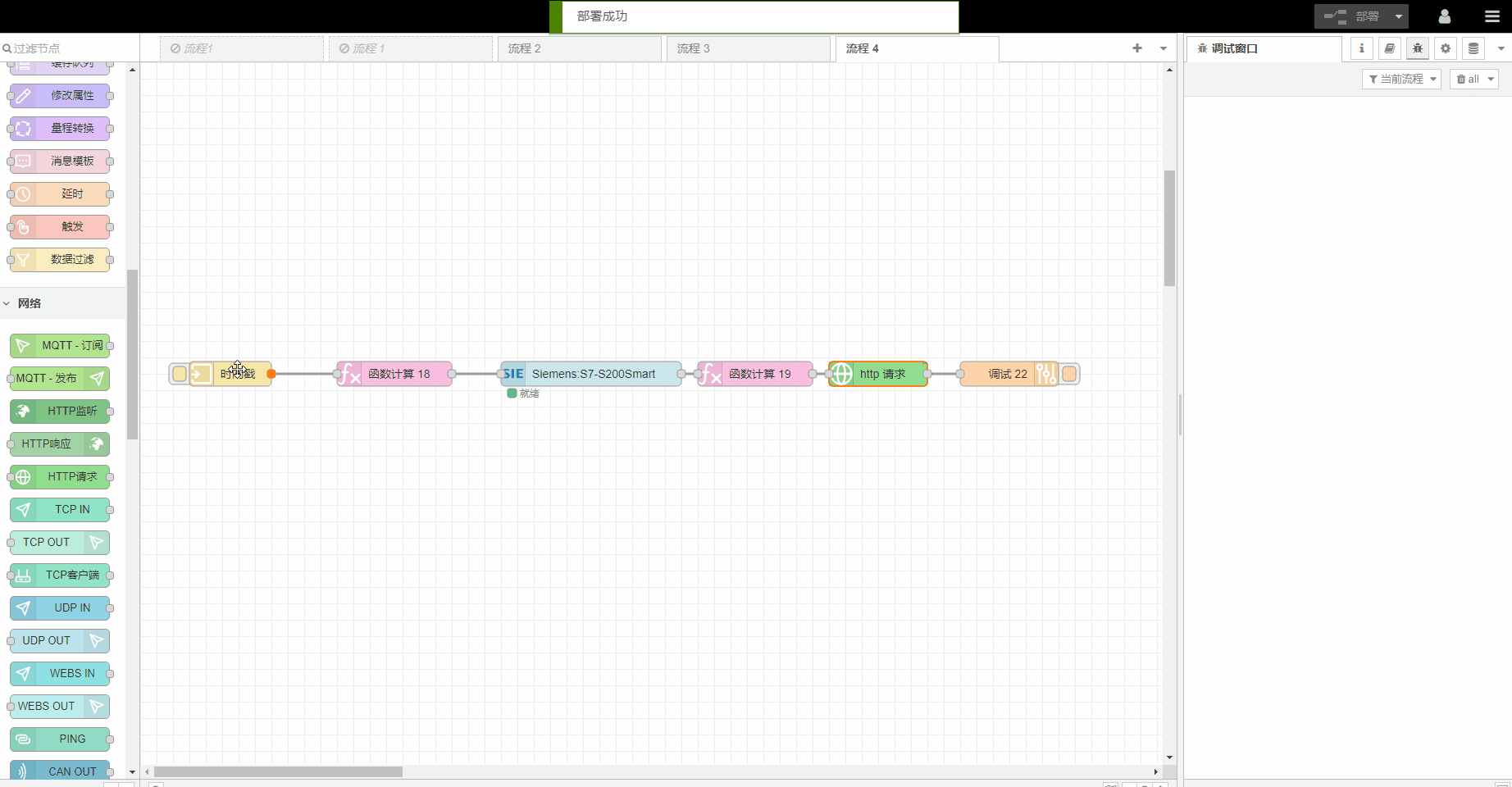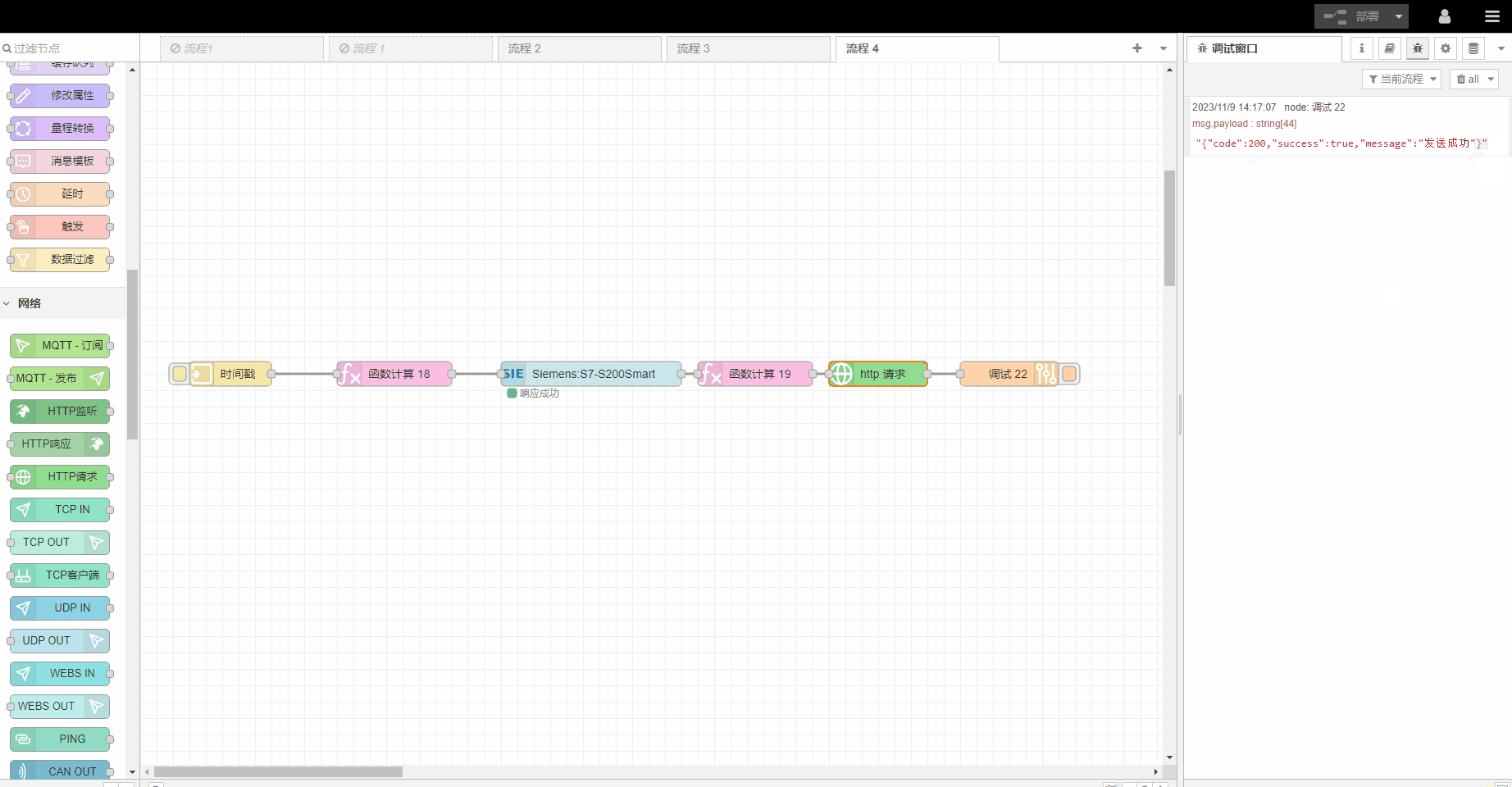
说明
本篇主要对基于LIDAR的3D目标检测算法PointPillars算法论文进行解析。
论文地址:https://arxiv.org/pdf/1812.05784.pdf
代码地址:https://github.com/open-mmlab/OpenPCDet
参考链接1:https://zhuanlan.zhihu.com/p/357626425
参考链接2:https://blog.csdn.net/Yong_Qi2015/article/details/119834000
参考链接3:https://blog.csdn.net/weixin_45080292/article/details/130217320
1.算法简介
核心思想: PointPillars算法从俯视图的角度将点云划分为一个个的柱状体(Pillar),等同于丢掉了高度信息,只保留水平方向上的xy坐标,每个柱状体(Pillar)等同于2D图像中的一个像素坐标。在得到伪图像之后使用常见2D网络进行特征的提取和学习,最后使用SSD检测头进行Bbox的回归。
PointPillar算法的网络框架如下图所示,算法的输入是原始点云数据,输出是3D目标检测框。整个算法包括以下几个模块:
- Voxel Feature Encoding (VFE)模块
- MAP_TO_BEV模块
- BACKBONE_2D模块
- 检测头(DENSE_HEAD)模块
- POST_PROCESSING模块

2.网络框架和算法流程
2.1 VFE模块
参考链接:https://blog.csdn.net/Jack_Man_N/article/details/134613118
PillarVFE模块是OpenPCDet(Open Point Cloud Detection)中的一个特征编码模块,用于将点云数据转换为结构化的特征表示。它是PointPillars算法中的关键组件。
PointPillars是一种基于单张俯视图的点云目标检测算法,它将点云数据投影到二维的俯视图平面上,并使用PillarVFE模块对每个投影区域(称为pillar)进行特征编码。PillarVFE模块的主要功能包括:
- 构建pillar:将点云数据投影到二维的俯视图平面,并将投影区域划分为多个小的正方形区域,称为pillar。每个pillar代表一个局部区域。
- 特征编码:对每个pillar中的点云数据进行特征编码。PillarVFE模块使用一个卷积神经网络(通常是多层的3D卷积操作)对每个pillar提取pillar内部的点云的特征表示。这些特征表示捕捉了点云数据的局部结构信息。
- 特征聚合:PillarVFE模块还执行特征聚合操作,将每个pillar的特征表示合并为一个全局的特征表示。这样可以利用全局特征进行目标检测和定位。
通过PillarVFE模块的特征编码和特征聚合操作,PointPillars算法能够有效地处理大规模点云数据并提取有用的特征表示,从而实现高效的点云目标检测。
2.1.1 构建pillar
通过激光雷达获取的一般是一个N*4的点云向量,N指云点的数量,4指点云有xyzi4个维度的信息。
第一步需要对点云进行张量化处理,将原始点云数据从俯视图的角度,根据点云的XY坐标信息将其划分为一个个垂直的网格。每个网格可以理解为一个长为n宽为n,高为h的体素。

图像参考链接:https://blog.csdn.net/ChuiGeDaQiQiu/article/details/118675912
每个点云用一个9维的向量表示:
(
x
,
y
,
z
,
r
,
x
c
,
y
c
,
z
c
,
x
p
,
y
p
)
(x,y,z,r,x_c,y_c,z_c,x_p,y_p)
(x,y,z,r,xc,yc,zc,xp,yp)。其中x,y,z指原始的点云坐标,r表示反射率信息,x_c,y_c,z_c为该点云所处Pillar中所有点的几何中心,x_p,y_p分别为x-x_c和y-y_c反应了点与几何中心的相对位置。
假定每个点云样本中有P个非空pillar,每个pillar有N个点,则该帧点云可以用张量
(
D
,
P
,
N
)
(D, P, N)
(D,P,N)进行表示,即图中的Stacked Pillars。其中,D指每个pillars的维度即D=9;P指pillars的数量;N指每个pillars中云点的数量,如果pillar中的云点数大于N则对其进行采样得到N个点,如果云点数量小于N则用0补齐。
pillars转换的代码在pcdet/datasets/processor/data_processor.py
2.1.2 pillar内部点云特征提取
在得到pillars表示的点云张量后,使用简化版本的PointNet对张量化的点云数据进行处理和VFE特征提取,即对每个点都运用线性层+BatchNormalization层+ReLU层学习9维的云点特征,生成(C,P,N)的张量,再对于通道上使用最大池化操作,输出一个(C,P)的张量。
特征提取可以理解为对点云的维度进行处理,原来的点云维度为
(
D
,
P
,
N
)
(D,P,N)
(D,P,N),处理后的维度为
(
C
,
P
,
N
)
(C,P,N)
(C,P,N)。按照Pillar所在维度进行Max Pooling操作,即获得了(C,P)维度的特征图。这一步应指其特征聚合操作。
2.1.3 MAP_TO_BEV模块
(C,P)维度的特征图表示通道数为C,长度为P,维度为1的张量,在经过简化版的pointnet网络提取出每个pillar的特征信息后,就需要将每个的pillar数据重新放回原来的坐标中,也就是二维坐标,组成 伪图像 数据,将其转换为HxW的2维张量,即伪图像信息,对应算法结构图中的Pseudo Image,代码中的PointPillarScatter模块。
2.2 BACKBONE_2D模块
在初步得到“伪图像”对应的特征之后,需要进一步提取图片特征。
 PointPillars使用类似VGG的结构来构建二维CNN主干。通过堆叠几个卷积层,主干将在每个阶段产生具有不同解决方案的特征图。来自几个阶段的特征图将被融合在一起,形成最终的特征表示。在特征融合过程中,去卷积层被引入,对具有较小分辨率的高水平特征图进行上采样。在去卷积之后,所有具有相同分辨率的输出特征图可以连接在一起,形成一个综合张量,用于最终的预测。
PointPillars使用类似VGG的结构来构建二维CNN主干。通过堆叠几个卷积层,主干将在每个阶段产生具有不同解决方案的特征图。来自几个阶段的特征图将被融合在一起,形成最终的特征表示。在特征融合过程中,去卷积层被引入,对具有较小分辨率的高水平特征图进行上采样。在去卷积之后,所有具有相同分辨率的输出特征图可以连接在一起,形成一个综合张量,用于最终的预测。
之所以选择这样架构,是因为不同分辨率的特征图负责不同大小物体的检测。比如分辨率大的特征图往往感受野较小,适合捕捉小物体(在KITTI中就是行人)。
2.3 检测头模块
在本文中,我们使用单击检测器(SSD)[18]设置来执行3D目标检测。与SSD类似,我们使用2D联合交叉(IoU)[4]将先验框与真值相匹配。边界框高度和标高未用于匹配;而不是给定2D匹配,高度和高程成为额外的回归目标。
类似于SSD的检测头被用于PiontPillars中,在OpenPCDet的实现中,直接使用一个网络对车、人、自行车三个类别进行训练,而没有像原论文中对车和人使用不同的网络结构。因此,在检测头中,一共有三个类别的先验框,每个先验框都有两个方向,分别是BEV视角下的0度和90度。每个类别的先验框只包含一种尺度信息。
车 [3.9, 1.6, 1.56]
人[0.8, 0.6, 1.73]
自行车[1.76, 0.6, 1.73](单位:米)
在进行anchor和GT的匹配过程中,PointPillars采用了2D IOU匹配方式,直接从BEV视角的特征图中进行匹配。这种匹配方式不需要考虑物体的高度信息,主要是因为在Kitti数据集中,所有物体都在同一个平面内,不存在一个物体在另一个物体上面的情况,并且所有类别物体的高度差异不大。因此,直接使用SmoothL1回归就可以得到较好的匹配结果。
每个anchor都需要预测七个参数:中心坐标的 (x, y, z) 以及长宽高 (w, l, h) 以及旋转角度 θ。此外,为了解决两个完全相反的box的角度预测问题,PointPillars的检测头还添加了一个基于softmax的方向分类来预测box的两个朝向信息。对于车、人和自行车这三个类别,每个anchor的正负样本匹配阈值不同,具体而言:
- 对于车辆,匹配IOU阈值大于等于0.65的anchor被视为正样本,小于0.45的被视为负样本,阈值在两者之间的样本不会被计算损失。
- 对于行人和自行车,匹配IOU阈值大于等于0.5的anchor被视为正样本,小于0.35的被视为负样本,阈值在两者之间的样本不会被计算损失。
3.损失函数
作者采用了SECOND中类似的损失函数,每个3D BBox用一个7维的向量表示,分别为 ( x , y , z , w , h , l , θ ) (x,y,z,w,h,l,\theta) (x,y,z,w,h,l,θ),其中 ( x , y , z ) (x,y,z) (x,y,z)为中心坐标,w,h,l为尺寸数据, θ \theta θ为方向角,检测框回归任务中要学习的参数为这7个变量的偏移量
真值和锚之间的定位回归残差定义如下:
 作者采用了Smooth L1损失函数进行训练:
作者采用了Smooth L1损失函数进行训练:

和SECOND中相同,为了避免方向判别错误,作者引入了个Softmax损失学习物体的方向。该损失记做
L
d
i
r
L_{dir}
Ldir.
有关分类损失,作者仍然采用了Focal Loss,定义如下:

整体的损失函数如下: