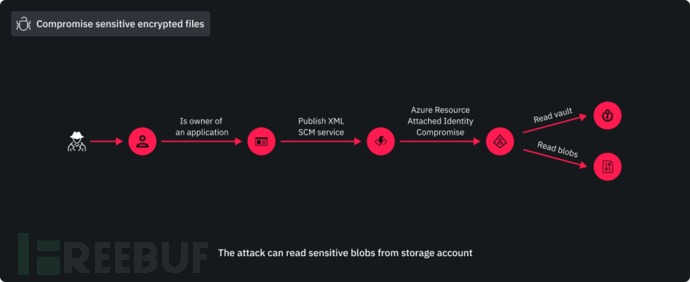
关联比赛: ACM MM2021 安全AI挑战者计划第七期:鲁棒性标识检测
ACM MM2021 鲁棒性目标检测比赛 TOP 2 方案
赛题背景
在商品知识产权领域,知识产权体现为在线商品的设计和品牌。不幸的是,在每一天,存在着非法商户通过一些对抗手段干扰商标识别来逃避侵权,这带来了很高的知识产权风险和财务损失。为了促进先进的多媒体人工智能技术的发展,以保护企业来之不易的创作和想法免受恶意使用和剽窃,因此提出了鲁棒性标识检测挑战赛 (ACM MM2021 Robust Logo Detection)。挑战赛需要参赛者处理小目标检测、长尾对象类别、对抗性干扰图像。这一挑战集中于现实世界机器学习和多媒体系统中安全问题的最新研究和未来方向。
前言
-
我们的计算设备是 8块 Tesla V100 32GB;😃
-
本方案初赛排名 TOP 6,复赛排名 TOP 2,综合排名 TOP 2;
-
特别感谢阿里安全组织的这场比赛,一方面锻炼了我们的能力,一方面给了我们探索实际业务场景中各种困难的机会;
赛题分析
-
初赛不涉及鲁棒性防御相关的测评,复赛主要集中在干扰图片的测评,因此整个竞赛围绕着目标检测,一个强大的目标检测器是基本保证;
-
测试数据的第一个特点是小目标。针对小目标检测,常见的方法有增大输入图片尺度(必然有效)、网络结构的设置(深层浅层网络的融合)、小目标数据的增广和重采样(效率与增益需要平衡)等;
-
测试数据的第二个特点是长尾分布。针对长尾分布,可以轻易想到的方案是通过loss权重设置来达到数据数量不一致的平衡;
-
测试数据的第三个特点是对抗干扰。通过给出的样例,可以看出这些对抗图片主要通过无限制攻击生成,它们可能来自噪声的添加、图片的模糊、目标位置的遮挡等,常见的对抗训练方式必然不可取(效率太低,对抗噪声来源未知),基于transform 的防御或许可行,但是容易造成干净图片上检测性能的下降;
-
训练数据集共有商标515类,共584,920张图片,好的硬件平台是好名次的基本保证!
赛题攻关
检测模型的选取:
如何选取一个有效的检测模型是该比赛的关键,由于数据量巨多,所以网络模型的选取须谨慎,因为不会有太多时间换模型!(任意一个检测的训练至少需要4天+)因此,我们首先根据coco检测性能排行榜来选取detector。我们选取检测器的原则是MAP越高越好,算法越新越好,不盲目听从论文,有过竞赛验证和检测框架(MMdetection,Paddle,Detectron)收录优先考虑。通过对相关竞赛的学习和分析,发现cascade这种结构基本是竞赛提分的必备条件之一,由于Cascade_RCNN比较老,即使通过增加一系列改进,想必性能也会有较大的瓶颈,另外由于对抗干扰的存在,对抗噪声的生成,不可缺少的攻击模型就是Faster_RCNN,所以我们选择了detectoRS作为我们的检测模型,该模型当前在目标检测coco排行榜排名第七,我们选择了其cascade的框架。Cascade_detectoRS网络结构如下:
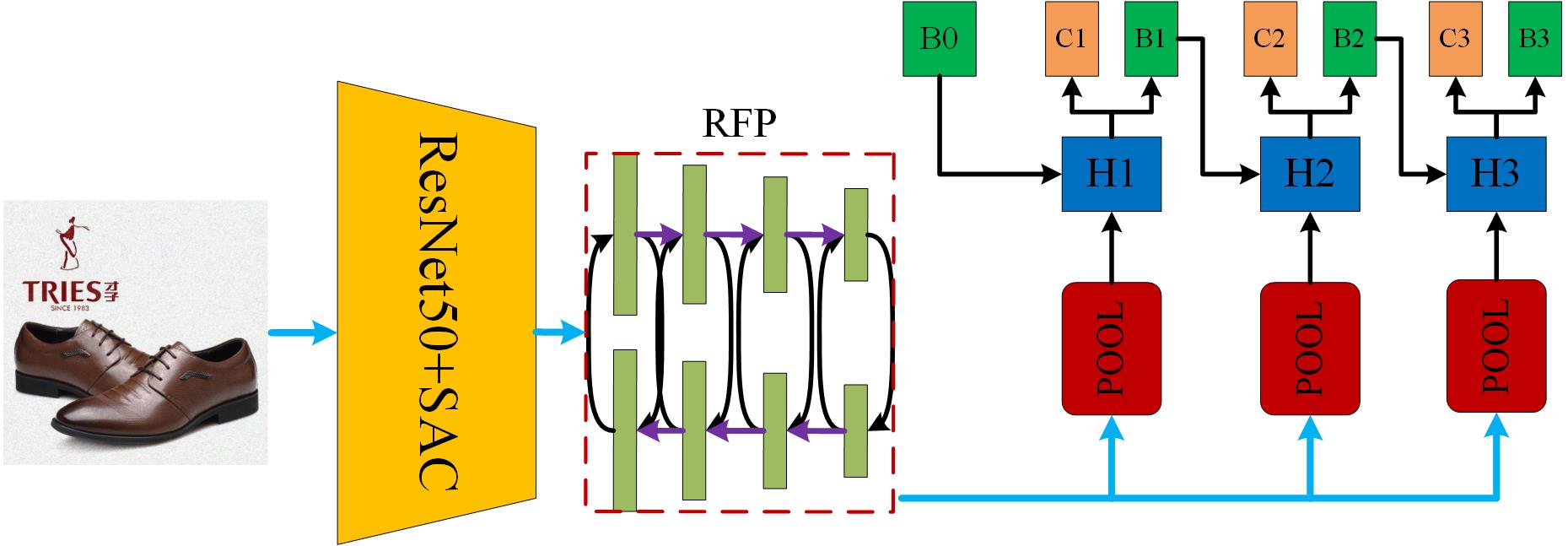
其中SAC (Switchable Atrous Convolution) 表示可切换的空洞卷积,它可以自适应选择感受野 ,其中 RFP (Recursive Feature Pyramid)采用循环结构来反复利用和精炼提取的特征,“H”表示检测头,我们使用了广泛使用的三级cascade结构,“B”表示回归框,“C”表示类别预测结果,“B0”表示RPN网络的输出结果。除此之外,整个网络模型还使用了基于注意力的特征融合机制和类似SENet的全局上下文模块来增强网络的表征能力。显而易见,该网络结构基本集合了常见的检测涨点的tricks。对于backbone的选取,一般而言,越大越复杂的特征提取网络,往往具有较好的性能表现,通过对网络复杂程度与训练耗时tradeoff的多次实验和思考,我们最终选择了ResNet50作为基本的网络,并将网络中标准的3*3卷积换成SAC卷积模块。
小目标处理策略:
对于小目标问题,我们并没有单独地去设计网络模块或者对数据进行小目标增广处理。由于网络模型的backbone是基于ResNet50的,所以我们可以使用较大尺度的输入,比如800,900,1000等。在兼顾小目标检测问题的同时,如何提升检测性能也是很重要的,在实验中我们采用了多尺度训练的机制,训练尺度最大边长为1333,短边尺度范围为800~1100。
长尾分布处理:
对于长尾数据的处理,容易想到的处理方案有重采样和均衡损失这两种。正如前面所介绍的那样,重采样会增加训练的时间,而且采样率也不容易设置,对于大数据集很不友好。均衡损失,往往是通过对类别项概率进行权重矫正实现的,如
$$ L_{EQL}=-\sum_{j=1}^{C}W_{j}*log(p_j) $$
其中 $C$ 表示类别数,$W_j$ 表示类别 $j$ 的权重,$p_j$ 表示网络对当前proposal类别的预测概率值。这种方案的缺陷在于忽略了背景候选区域的影响。此外,固定的权重值不一定适合不同训练阶段网络的学习。因此,我们使用了EQ-Loss V2作为检测模型中的分类损失函数,RPN处的分类损失,我们依然使用交叉熵损失函数。EQL_V2 loss的特点是基于梯度引导的,它根据正梯度与负梯度的累积比,分别对正负梯度进行加权矫正,正梯度 $q_t^j$ 和负梯度 $r_t^j$ 的权重如下:
$$ \begin{cases} q_j^{(t)} = 1+4*(1-f(g_j^{(t)}))\\ r_j^{(t)} = f(g_j^{(t)}) \end{cases} $$
其中 $t$ 表示迭代次数,$f(x)=1/(1+e^{-12*(x-0.8)})$ ,得到正负梯度权重后,便可以分别更新当前的梯度值,
$$ \begin{cases} \bigtriangledown_{z_j}^{pos^{\prime}}(L^{(t)})=q_j^{(t)}\bigtriangledown_{z_j}^{pos}(L^{(t)})\\ \bigtriangledown_{z_j}^{neg^{\prime}}(L^{(t)})=q_j^{(t)}\bigtriangledown_{z_j}^{neg}(L^{(t)}) \end{cases} $$
其中 $z_i$ 表示分类器的输出,$L$ 表示损失函数, 则第 $t+1$ 次正负梯度累积比为 $g_j^{t+1} = \sum_{t=0}^{T}|\bigtriangledown_{z_j}^{pos^{\prime}}(L^{(t)})|/\sum_{t=0}^{T}|\bigtriangledown_{z_j}^{neg^{\prime}}(L^{(t)})|$ 。
对抗干扰的处理:
对于干扰的处理方案,我们最初的想法是基于transform的方法,其中多尺度测试方法就是最理想的方法。数值领域的对抗噪声攻击鲁棒性往往比较差,对于输入尺度的变化,往往会造成攻击性能的骤降。当然也存在input diversity这种较强泛化性的攻击算法,但是从目标检测攻击策略(分类攻击、定位攻击、置信度攻击等)角度分析,这种泛化性强的噪声不易实现。因此,从性能提升角度和对抗防御的角度,我们从初赛到复赛,都使用了multi-scale testing。尺度范围在训练尺度范围的基础我增加了(1333,1200),这种较大尺度的使用主要作用在于提升小目标检测的recall值以及提升模型鲁棒性。当然我们也尝试了一系列图像数字领域防御的方法,例如 JPEG compression,quantization,denoise 等经典的手段,这些方法都会造成检测性能的下降,其主要的原因在于测试数据集中包含图像数字攻击的对抗样本很少,绝大多数的对抗样本基本都是无限制攻击下产生的扰动,这些扰动的生成和常见的防御机理存在很大程度的不一致性,因此这些方法基本没有任何防御效果。甚至由于防御造成的信息损失,导致最终正常图片性能的下降。
因此,对于对抗干扰的可能有效的处理方法,是模拟当前噪声的生成,通过增广数据来提升模型的鲁棒性,我们尝试加Gaussian噪声、加雨、加雾、图像模糊化等方法,有一定程度的性能提升效果。😓
检测效果图:

提分tricks以及一些思考
-
考核指标 MAP 0.5:0.95,能多训就多训,越多的训练Epoch,定位精度往往会有所提升。当然,也有可能是当前模型处于欠拟合状态;
-
RPN训练、测试阶段一致性问题,训练阶段rpn前后保留的候选框大约2000左右,测试时默认只有1000,往往会造成大量的漏检,这些漏检的目标往往是小目标,稀少类别的目标,所以测试阶段最起码得保证2000+的候选框。当然,这种现象并非具有广泛性,但是针对当前的数据,确实存在这个问题。
-
soft-nms提点必备,检测结果中漏检的代价大于虚景的代价;😅
-
Anchor比例的选取,我们使用 Kmeans 聚类算法计算得到,合适的锚框设置有利于网络的收敛。
-
通过此次比赛,我们发现其实每个检测模型都可以很鲁棒,这种鲁棒性并不需要特定的网络结构,模型鲁棒性很大程度取决于训练后网络收敛的位置点,不同的收敛点往往具有较大的鲁棒性差别。如何研究出有效的网络训练策略或许会是网络鲁棒性的基本保证! 💥
竞赛代码:地址一 地址二
最后,再次感谢举办方各位工作人员的辛苦付出,感谢整个竞赛过程中结识的各位朋友,向每一位优秀并且努力的对手学习!
查看更多内容,欢迎访问天池技术圈官方地址:鲁棒性目标检测 TOP2 方案分享_天池技术圈-阿里云天池
![[Python学习日记-9] Python中的运算符](https://i-blog.csdnimg.cn/direct/273f031708ae409eb08757b0cd557cd0.png)