文章汇总
存在的问题
问题1
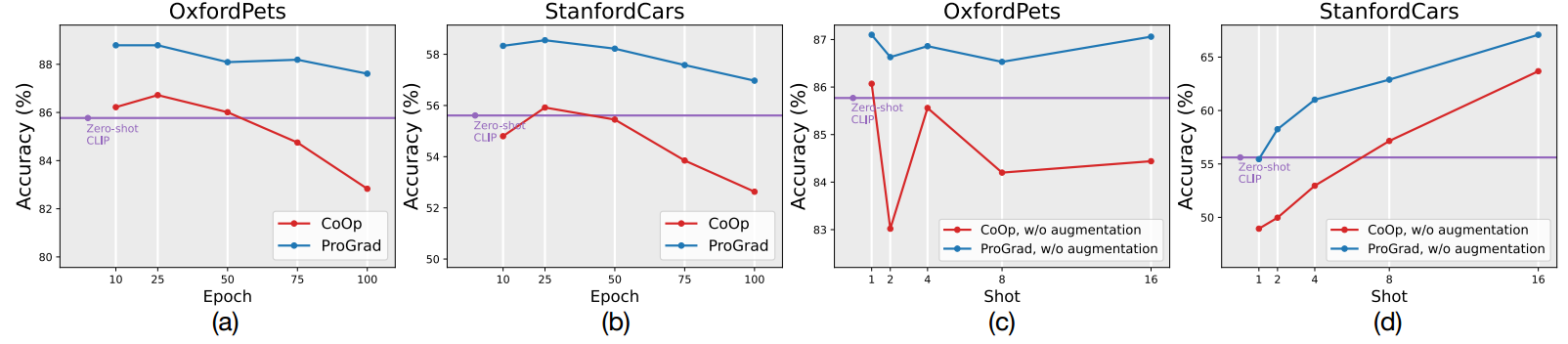
如图(a),(b):CoOp随着训练的继续,泛化能力可能会下降,甚至低于zero-shot基线。
如图©,(d):在shot比较小的情况,即数据量比较少的情况(1-shot,2-shot),CoOp的性能可能还不如clip的zero-shot基线。
问题2
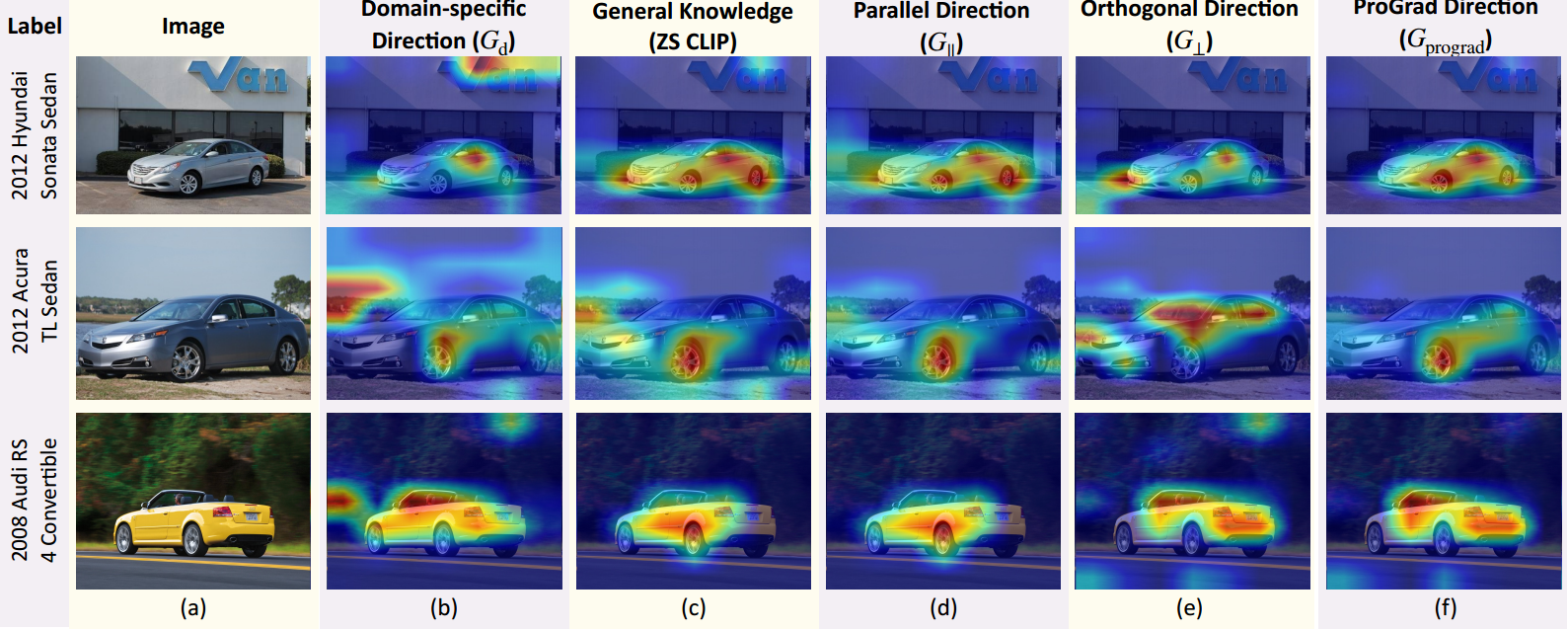
对比CoOp模型(图2(b))和zero-shot CLIP模型(图2©),我们发现CoOp模型将注意力分散到背景上,而CLIP模型主要关注前景目标。
动机
当学习到下游知识优化方向与一般知识冲突,选择一种“居中”的办法以此避免继续被学习到的下游知识“带偏”。
解决办法
L
c
e
(
v
)
\mathcal{L}_{ce}(v)
Lce(v):模型预测
p
(
t
i
∣
x
)
p(t_i|x)
p(ti∣x)与真实值
y
y
y的交叉熵损失
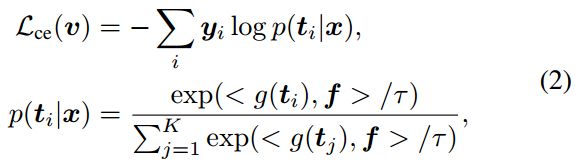
L
k
l
(
v
)
\mathcal{L}_{kl}(v)
Lkl(v):模型预测
p
(
t
i
∣
x
)
p(t_i|x)
p(ti∣x)与zero-shot CLIP预测
p
z
s
(
w
i
∣
x
)
p_{zs}(w_i|x)
pzs(wi∣x)的KL散度
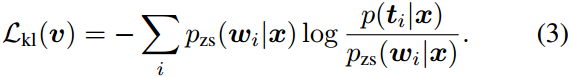
如何避免过拟合与下游知识
G
d
=
▽
v
L
c
e
(
v
)
G_d=\bigtriangledown_v\mathcal{L}_{ce}(v)
Gd=▽vLce(v)表示为
L
c
e
(
v
)
\mathcal{L}_{ce}(v)
Lce(v)的梯度
G
g
=
▽
v
L
k
l
(
v
)
G_g=\bigtriangledown_v\mathcal{L}_{kl}(v)
Gg=▽vLkl(v)表示为
L
k
l
(
v
)
\mathcal{L}_{kl}(v)
Lkl(v)的梯度
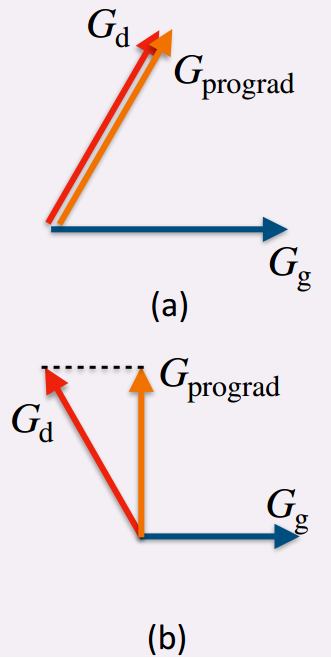
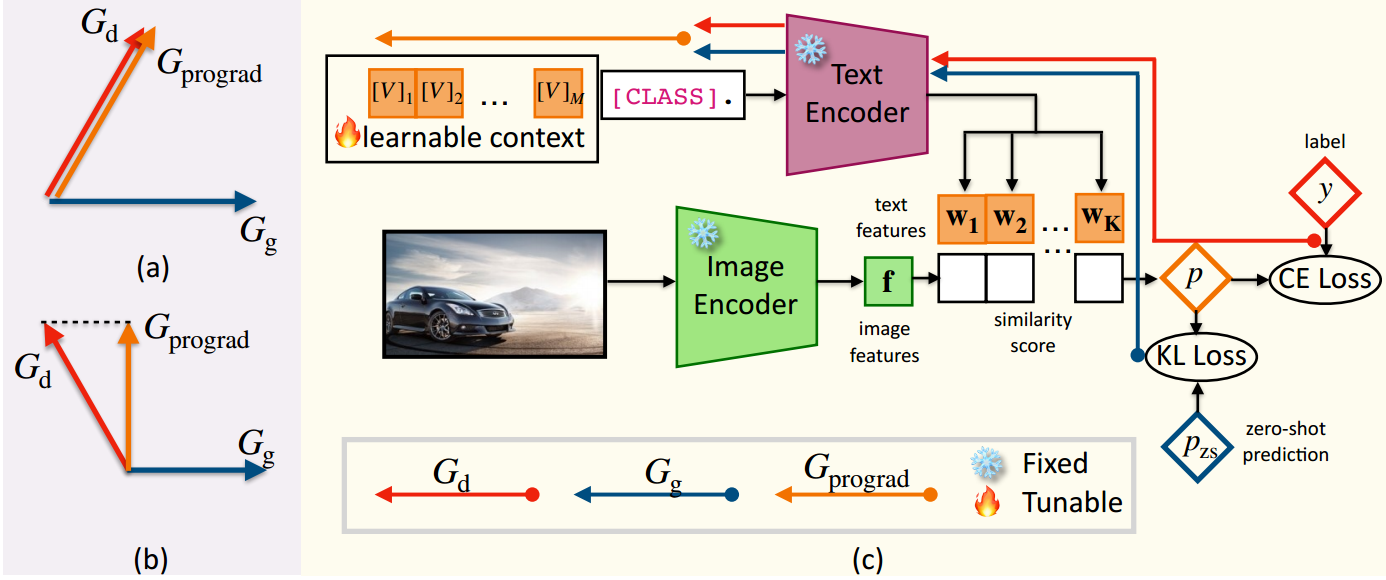
图(a)说明小样本下游知识的优化方向与一般知识不冲突(夹角小于90度),将更新的梯度方向
G
p
r
o
g
r
a
d
G_{prograd}
Gprograd设置为
G
d
G_d
Gd。
图(b)说明小样本下游知识的优化方向与一般知识发生冲突(夹角大于90度),将
G
d
G_d
Gd投影到
G
g
G_g
Gg的正交方向上,以优化模型进行分类,避免增加KL损失。
公式化表示如下:
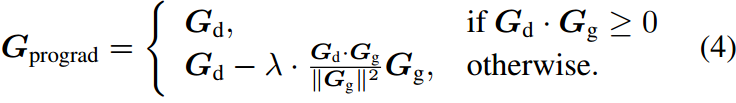
其中
λ
=
1
\lambda=1
λ=1表示将
G
d
G_d
Gd投影到
G
g
G_g
Gg的正交方向上(图b),
λ
=
0
\lambda=0
λ=0则使ProGrad退化为CoOp,即CoOp是我们策略的特例。
摘要
由于像CLIP[37]这样的大型预训练视觉语言模型(VLM),我们可以通过离散提示设计来制作零射击分类器,例如,如果图像与提示句子“a photo of a [CLASS]”具有相似性,则可以使用VLM来获得图像为“[CLASS]”的置信分数。此外,如果我们用少量样本微调软提示,提示显示出vlm快速适应下游任务的巨大潜力。然而,我们发现了一个常见的失败,即不适当的微调或使用极少的样本进行学习,甚至可能导致零样本预测的效果不佳。现有的方法仍然通过使用传统的反过拟合技术来解决这个问题,例如早期停止和数据增强,这些技术缺乏针对提示的原则性解决方案。在本文中,我们提出了提示对齐梯度,称为ProGrad,以防止提示调优忘记从VLM中学到的一般知识。特别是,ProGrad只更新梯度与一般知识对齐(或不冲突)的提示,一般知识表示为预定义提示预测提供的优化方向。在少量学习、领域泛化、base-to-new泛化和跨数据集传输设置下的大量实验表明,ProGrad的小样本泛化能力强于最先进的提示调优方法。
1. 介绍
大型和深度视觉语言模型(VLM)在看到和阅读了无数的图像-文本关联对后[37,18],可以记忆关于哪些视觉模式对应于哪些文本序列的一般知识(又称百科知识),反之亦然。由于VLM强大的语言建模功能,我们可以用人类可读的自然语言(即提示符[25,52,19])建立一个通信通道来查询通用知识。
提示弥补了预训练任务和下游任务之间的接口差距(例如,回归与分类),而不需要额外的微调适应。例如,我们可以为zero-shot图像分类制作一个具体的提示“a photo of a [CLASS]”:我们使用流行的视觉语言模型CLIP[37],将图像输入到视觉端,将提示句输入到语言端,然后获得一个视觉语言相似度作为将图像分类为“[CLASS]”的置信度分数。
在实践中,基于提示的零样本图像分类并不准确,因为手工制作的提示可能不是最适合机器的(例如,““this is
a picture of”在VLM训练中可能更符合语法),或者不是特定于下游领域(例如,“a photo of a person doing”在动作识别中更好)[37]。最近,提示调优或前缀调优[23,26,55,56]被提出用一组可调的词嵌入向量取代手工制作的提示,这些词嵌入向量不必被翻译回人类可读的词。然而,提示调整仍然像传统的微调一样棘手:随着训练的继续,泛化能力可能会下降,甚至低于zero-shot基线。如图1(a&b)所示,提示调优方法CoOp[55]通过提前停止达到最佳效果,当训练继续进行时,其准确率最多下降4%。此外,图1(c&d)显示,在没有增强或从下游任务获得足够样本的情况下,CoOp的表现不如zero-shotCLIP。据我们所知,现有的方法仍然依赖于传统的反过拟合技术,如早期停止和数据增强[55,56,11,36],缺乏对不适当的提示调谐本质的原则解决方案。此外,Grad-CAM可视化结果表明,微调提示误导了VLM忘记了分类至少应该关注前景目标而不是背景的一般知识。对比CoOp模型(图2(b))和zero-shot CLIP模型(图2©),我们发现CoOp模型将注意力分散到背景上,而CLIP模型主要关注前景目标。这些结果证明了现有提示调优的过度拟合风险,特别是当训练样本的数量非常有限时(例如,1或2)。
图1:Zero-shot CLIP、CoOp和我们的ProGrad在Stanford Cars和OxfordPets数据集上的比较。(a)和(b):给定1-shot训练样本,当训练继续时,CoOp的性能严重下降,并大大低于zero-shot CLIP。©和(d):如果没有数据增强或大量样本,CoOp可能无法改善CLIP。
图2:在Stanford Cars数据集上使用不同梯度策略的Grad-CAM[43]可视化提示微调方法的比较。
为此,我们提出了一种新的提示调谐方法,称为提示对齐梯度(ProGrad),以克服CLIP的不适当偏置调谐。ProGrad的原理是使每个调优步骤规范化,不与原始提示提供的一般知识相冲突,例如,zero-shot CLIP预测。具体而言,我们使用zero-sho提示CLIP和few-shot 微调模型预测之间的Kullback-Leibler (KL)散度梯度来测量一般知识方向
G
g
G_g
Gg,我们将其称为一般方向。类似地,我们使用ground truth和few-shot微调模型之间的交叉熵梯度计算领域特定知识方向
G
d
G_d
Gd,称为领域特定方向。我们将特定领域的方向
G
d
G_d
Gd分解为:1)与一般方向正交的向量
G
⊥
G_{\perp}
G⊥,表示不冲突的特定领域知识;2)向量
G
∥
G_{\lVert}
G∥**平行于一般方向,表示一般知识。**请注意,第一个梯度分量不会覆盖一般方向,因为任何两个正交向量都可以转换为两个不冲突的基向量。对于第二个组件,它必须是两个方向之一:1)**与一般方向相同,这表明更新与一般知识一致;2)与一般方向相反,表明应该放弃冲突的更新,以避免遗忘。**总的来说,在每次迭代中,ProGrad只在与一般方向有锐角的提示对齐方向上更新参数。与CoOp和CLIP相比,
G
g
G_g
Gg和
G
⊥
G_{\perp}
G⊥(图2(d&e))都有助于正则化模型以聚焦于前景,而ProGrad(图2(f))进一步改善了视觉响应
3. 方法
在本节中,我们介绍了基于提示的小样本推理和基于提示的学习的初步概念,并提出了我们提出的基于提示对齐的梯度解决方案,将领域知识与一般知识对齐以进行小样本泛化。
3.1. 准备知识
对比语言-图像预训练(contrast language-image pre-training, CLIP)[37]采用了一种对大量具有自然语言描述的图像对进行对比语言-图像预训练的范式。在对比学习中,将关联的图像和句子作为正样本,将不关联的对作为负样本。对比目标使正对的相似性最大化,而使负对的相似性最小化。
零样本转移推理使预训练的CLIP模型适应下游任务,而不需要对模型进行微调。以图像分类为例,通过将分类任务表述为一个图像-文本匹配问题来实现零样本转移,其中文本是通过使用““a photo of a [CLASS]”之类的模板扩展“[CLASS]”的名称来获得的。CLIP[37]发现这样一个简单的模板缩小了预训练文本输入的分布差距。基于第
i
i
i类的图像特征
f
f
f与类扩展文本特征
w
i
w_i
wi之间的余弦相似度
<
w
i
,
f
>
<w_i,f>
<wi,f>来衡量图像类匹配得分。图像
x
x
x的图像特征
f
f
f由图像编码器提取,第
i
i
i类的文本特征
w
i
w_i
wi通过向文本编码器输入提示描述得到。第
i
i
i类的概率为
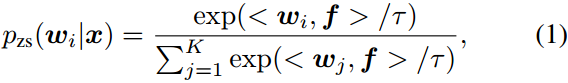
其中
K
K
K表示类的数量,
τ
\tau
τ是CLIP。
基于提示的学习进一步增强了CLIP模型的迁移能力,并通过从下游任务中自动学习少量样本的提示来避免提示工程。与使用固定手工提示符的零样本转移不同,CoOp[55]构建并微调了一组
M
M
M个连续上下文向量
v
=
{
v
1
,
v
2
,
…
,
v
M
}
v=\{v_1,v_2,\ldots,v_M\}
v={v1,v2,…,vM}作为可旋转的提示符。具体来说,提示符
t
i
=
{
v
1
,
v
2
,
…
,
v
M
,
c
i
}
t_i=\{v_1,v_2,\ldots,v_M,c_i\}
ti={v1,v2,…,vM,ci}将可学习的上下文向量
v
v
v和嵌入
c
i
c_i
ci的类标记结合起来,并被馈给文本编码器
g
(
⋅
)
g(\cdot)
g(⋅)。CoOp通过最小化真实标签token负对数似然来优化静态上下文向量
v
v
v:
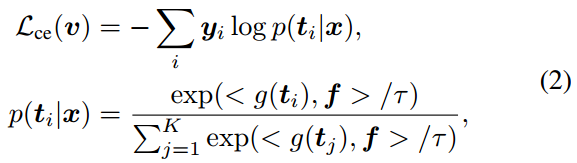
其中
y
y
y表示one-hot ground-truth注释,
K
K
K表示类的数量
3.2. Prompt-aligned梯度
CoOp面临的挑战是,当注释的数量非常有限(例如,每个类一个注释)时,传输性能会下降,甚至不如zero-shot迁移。此外,CoOp很大程度上依赖于抗过拟合技术,如早期停止和数据增强。为了克服过度拟合的挑战,我们提出了一种有效的微调范式ProGrad,将少量的下游知识与大规模的一般知识进行对齐。
受知识蒸馏在知识转移中的成功[34,16]的激励,我们利用zero-shot CLIP预测作为一般知识,并将微调后的预测与一般知识进行比较,以正则化梯度方向。具体来说,我们根据Eq.(2)计算模型预测
p
(
t
i
∣
x
)
p(t_i|x)
p(ti∣x)与ground-truth
y
y
y之间的交叉熵
L
c
e
(
v
)
\mathcal{L}_{ce}(v)
Lce(v)得到域特定方向,根据
p
(
t
i
∣
x
)
p(t_i|x)
p(ti∣x)与zero-shot CLIP预测
p
z
s
(
w
i
∣
x
)
p_{zs}(w_i|x)
pzs(wi∣x)之间的Kullback-Leibler (KL)散度得到一般知识方向:
我们将
L
k
l
(
v
)
\mathcal{L}_{kl}(v)
Lkl(v)和
L
c
e
(
v
)
\mathcal{L}_{ce}(v)
Lce(v)的梯度分别表示为
G
g
=
▽
v
L
k
l
(
v
)
G_g=\bigtriangledown_v\mathcal{L}_{kl}(v)
Gg=▽vLkl(v)和
G
d
=
▽
v
L
c
e
(
v
)
G_d=\bigtriangledown_v\mathcal{L}_{ce}(v)
Gd=▽vLce(v)。
G
g
G_g
Gg和
G
d
G_d
Gd之间的关系是双重的。(1)它们的夹角小于90◦(图3(a)),说明小样本下游知识的优化方向与一般知识不冲突。在这种情况下,我们安全地将更新的梯度方向
G
p
r
o
g
r
a
d
G_{prograd}
Gprograd设置为
G
d
G_d
Gd。(2)它们的夹角大于90◦(图3(b)),说明下游的少量知识与一般知识发生冲突。换句话说,在
G
d
G_d
Gd之后优化上下文向量会导致预先训练好的一般知识的遗忘。在这种情况下,我们将
G
d
G_d
Gd投影到
G
g
G_g
Gg的正交方向上,以优化模型进行分类,避免增加KL损失。我们的ProGrad策略的数学公式如下:
图3©说明了我们的编程程序的管道。在CoOp[55]中,我们没有使用
G
d
G_d
Gd来更新上下文向量,而是使用
G
p
r
o
g
r
a
d
G_{prograd}
Gprograd来优化上下文向量,这可以防止梯度方向过度拟合到小样本下游。我们进一步在Eq.(4)中引入
λ
\lambda
λ对公式进行推广,可以在应用中灵活控制通用知识引导的强度。其中
λ
=
1
\lambda=1
λ=1表示将
G
d
G_d
Gd投影到
G
g
G_g
Gg的正交方向上(图3(b)),设
λ
=
0
\lambda=0
λ=0使ProGrad退化为CoOp,即CoOp是我们策略的特例。我们在附录中包含了
λ
\lambda
λ的详细分析。
泛化误差分析。进一步从理论上分析了该算法的泛化误差。在这里,我们提供了一个草图证明,并在附录中包含了详细的理由。我们的ProGrad在优化下游领域的经验风险时,保持预训练领域的最优值
L
k
l
\mathcal{L}_{kl}
Lkl。通过这种更新规则学习的模型可被视为对预训练域和下游域的经验风险进行优化[53]:
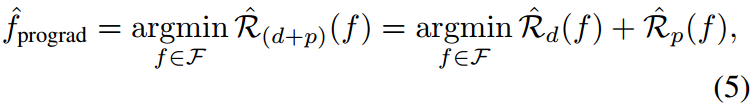
式中,
F
\mathcal{F}
F为函数类,
R
(
⋅
)
,
R
^
(
⋅
)
\mathcal{R}(\cdot),\hat{\mathcal{R}}(\cdot)
R(⋅),R^(⋅)分别表示预期风险和经验风险。我们利用Rademacher Complexity[1]和[54]中的定理6.2对ProGrad的泛化误差进行了限定。详细证明见附录。
4. 实验(做了很多实验)
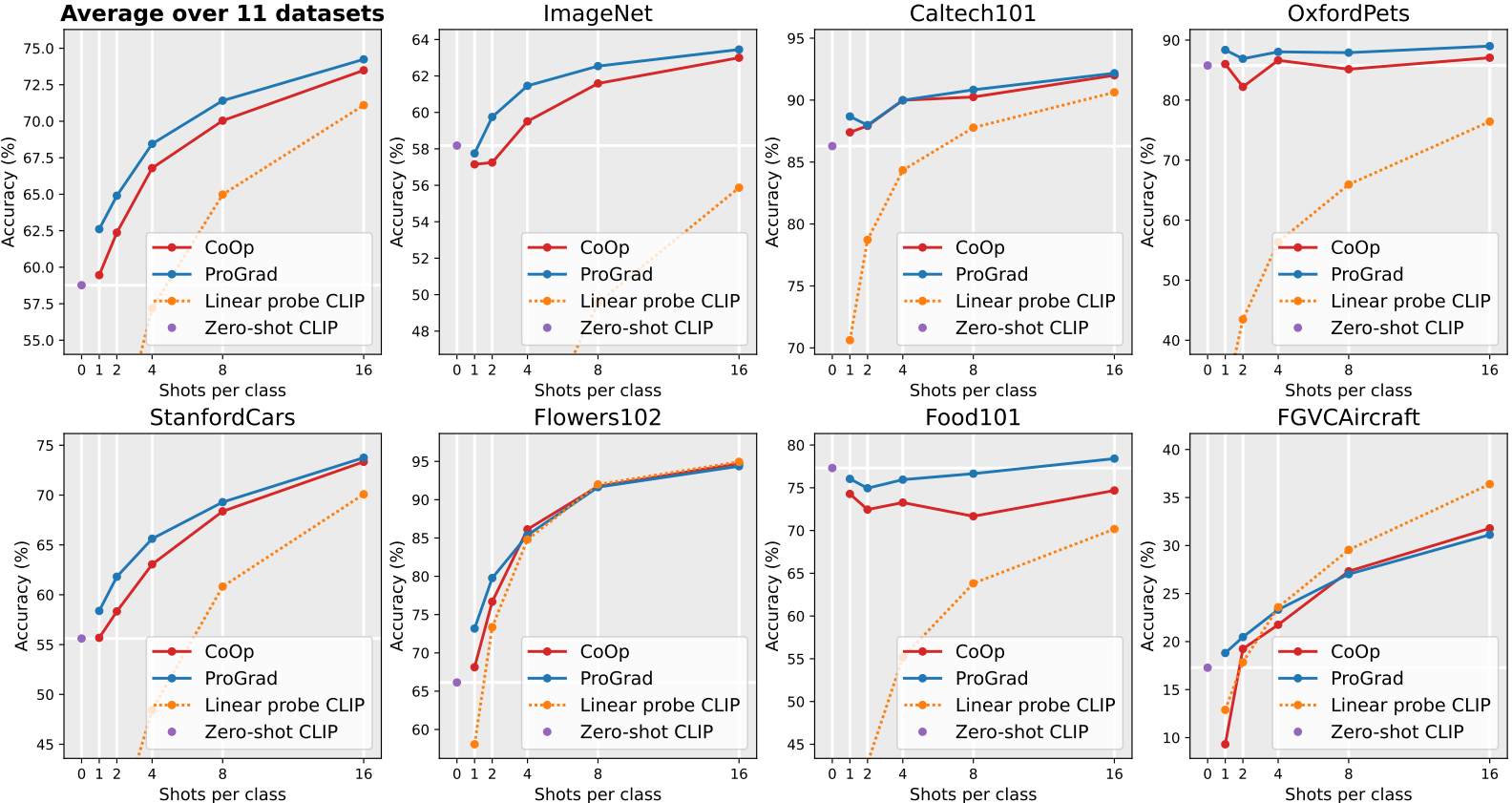
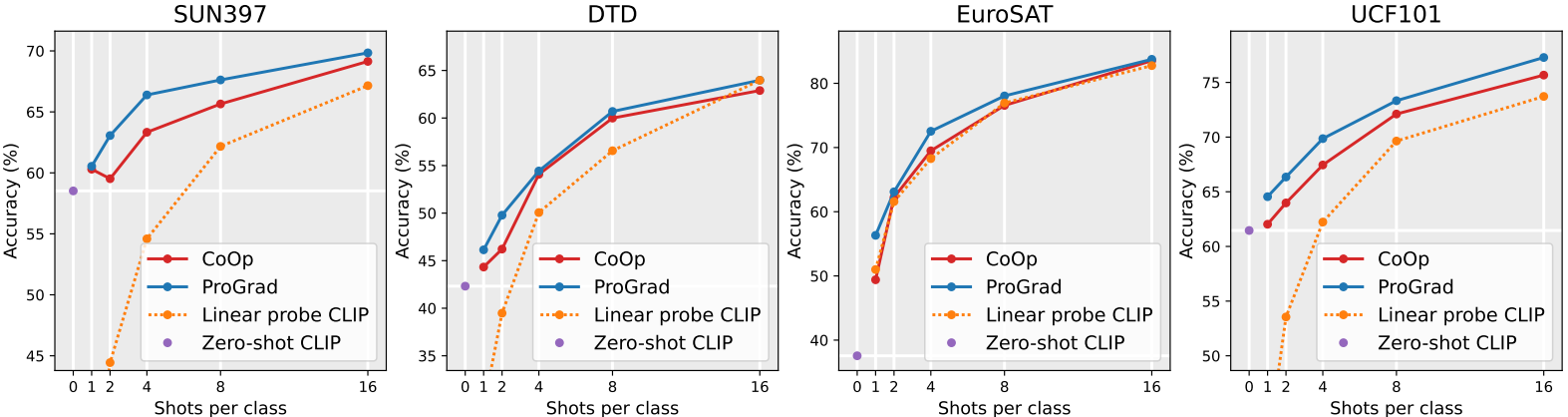
图4:11个数据集上的小样本学习准确率(%)。上下文长度M设置为16。标准偏差见附录。
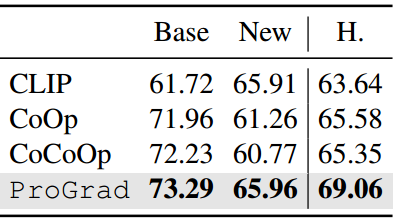
表3:基类到新类泛化在11个数据集上的平均精度(%)。
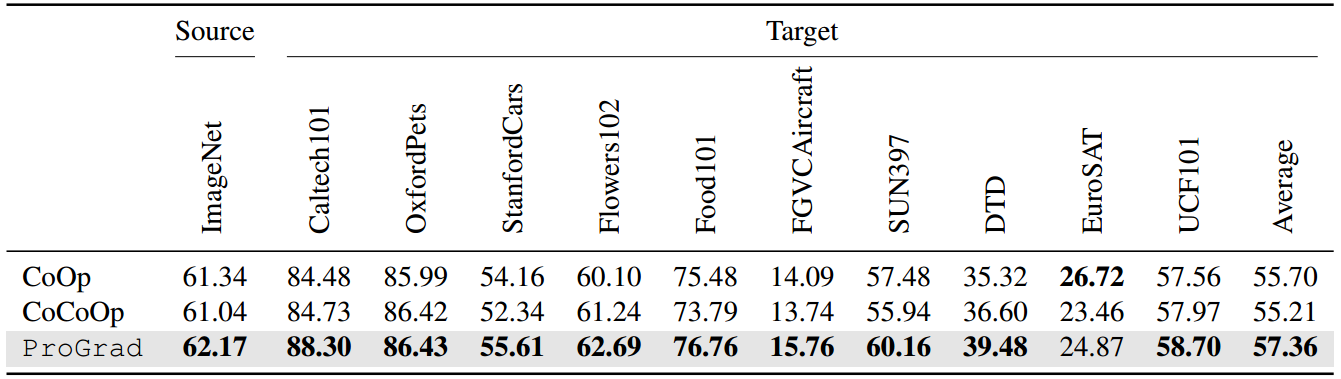
表4:跨数据集迁移设置下提示学习方法的比较。提示是从4-shot ImageNet学习的。
5. 结论
本文指出了现有的小样本泛化提示调优方法存在的过度拟合问题,这些方法严重依赖于早期停止和数据增强。提出了一种提示调优方法规范每个调优步骤,以免与手工制作的提示符的一般知识相冲突。在11个数据集上进行的少样本分类、base-to-new概化、域概化和跨数据集传输实验证明了该方法的有效性和高效性。在未来,我们将探索如何将ProGrad应用于其他任务,如目标检测和分割。
参考资料
论文下载(ICCV 2023)
https://arxiv.org/abs/2205.14865
[Prompt-aligned Gradient for Prompt Tuning.pdf]

代码地址
https://github.com/BeierZhu/Prompt-align
参考文章
https://blog.csdn.net/weixin_51293984/article/details/137423337?spm=1001.2014.3001.5502










![[219] 存在重复元素 II](https://i-blog.csdnimg.cn/direct/7da7cafab48f45558e7b6073f4b5265d.png)