目录
115.不同的子序列
分析:
583. 两个字符串的删除操作
72. 编辑距离
115.不同的子序列
力扣题目链接(opens new window)
给定一个字符串 s 和一个字符串 t ,计算在 s 的子序列中 t 出现的个数。
字符串的一个 子序列 是指,通过删除一些(也可以不删除)字符且不干扰剩余字符相对位置所组成的新字符串。(例如,"ACE" 是 "ABCDE" 的一个子序列,而 "AEC" 不是)
题目数据保证答案符合 32 位带符号整数范围。
分析:
这道题目如果不是子序列,而是要求连续序列的,那就可以考虑用KMP。
确定dp数组(dp table)以及下标的含义
dp[i][j]:以i-1为结尾的s子序列中出现以j-1为结尾的t的个数为dp[i][j]。
确定递推公式
这一类问题,基本是要分析两种情况
- s[i - 1] 与 t[j - 1]相等
- s[i - 1] 与 t[j - 1] 不相等
当s[i - 1] 与 t[j - 1]相等时,dp[i][j]可以有两部分组成。
一部分是用s[i - 1]来匹配,那么个数为dp[i - 1][j - 1]。即不需要考虑当前s子串和t子串的最后一位字母,所以只需要 dp[i-1][j-1]。
一部分是不用s[i - 1]来匹配,因为可能前面出现了和t[j-1]相同的字母,这种情况个数为dp[i - 1][j]。
例如: s:bagg 和 t:bag ,s[3] 和 t[2]是相同的,但是字符串s也可以不用s[3]来匹配,即用s[0]s[1]s[2]组成的bag。
当然也可以用s[3]来匹配,即:s[0]s[1]s[3]组成的bag。
所以当s[i - 1] 与 t[j - 1]相等时,dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
当s[i - 1] 与 t[j - 1]不相等时,dp[i][j]只有一部分组成,不用s[i - 1]来匹配(就是模拟在s中删除这个元素),即:dp[i - 1][j]
所以递推公式为:dp[i][j] = dp[i - 1][j];
这里可能有录友还疑惑,为什么只考虑 “不用s[i - 1]来匹配” 这种情况, 不考虑 “不用t[j - 1]来匹配” 的情况呢。
这里大家要明确,我们求的是 s 中有多少个 t,而不是 求t中有多少个s,所以只考虑 s中删除元素的情况,即 不用s[i - 1]来匹配 的情况。
dp数组如何初始化
从递推公式dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j]; 和 dp[i][j] = dp[i - 1][j]; 中可以看出dp[i][j] 是从上方和左上方推导而来,如图:,那么 dp[i][0] 和dp[0][j]是一定要初始化的。
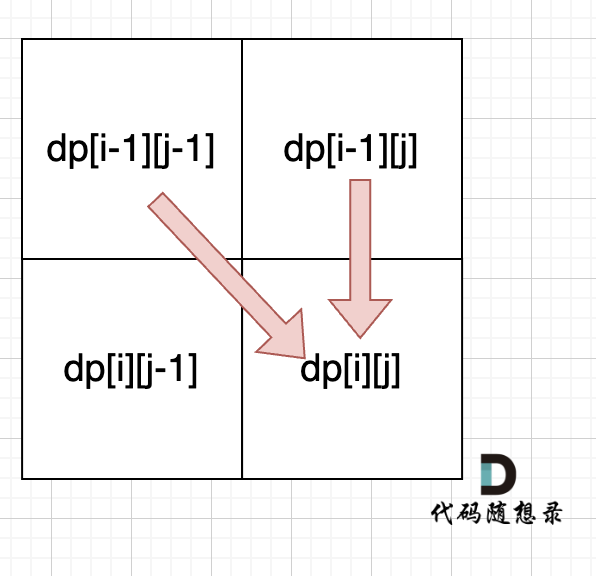
每次当初始化的时候,都要回顾一下dp[i][j]的定义,不要凭感觉初始化。
dp[i][0]表示什么呢?
dp[i][0] 表示:以i-1为结尾的s可以随便删除元素,出现空字符串的个数。
那么dp[i][0]一定都是1,因为也就是把以i-1为结尾的s,删除所有元素,出现空字符串的个数就是1。
再来看dp[0][j],dp[0][j]:空字符串s可以随便删除元素,出现以j-1为结尾的字符串t的个数。
那么dp[0][j]一定都是0,s如论如何也变成不了t。
最后就要看一个特殊位置了,即:dp[0][0] 应该是多少。
dp[0][0]应该是1,空字符串s,可以删除0个元素,变成空字符串t。
确定遍历顺序
从递推公式dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j]; 和 dp[i][j] = dp[i - 1][j]; 中可以看出dp[i][j]都是根据左上方和正上方推出来的。
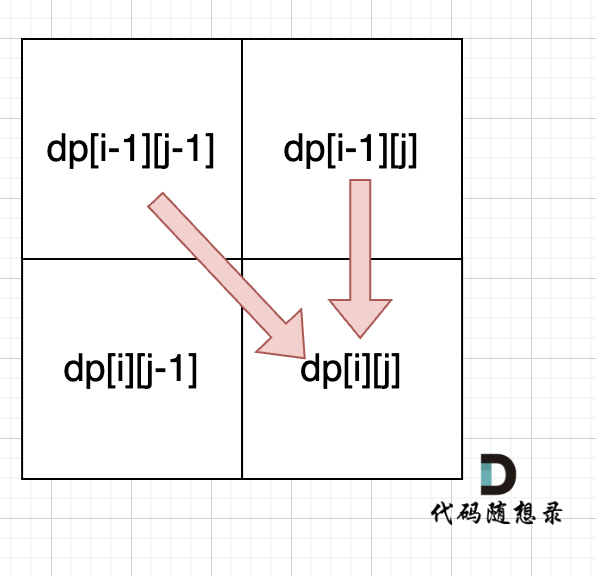
所以遍历的时候一定是从上到下,从左到右,这样保证dp[i][j]可以根据之前计算出来的数值进行计算。
注意:如果发现数太大——变成unsigned long long
注意对循环边界的判断
int numDistinct(char* s, char* t) {
long l1=strlen(t),l2=strlen(s);
unsigned long long dp[l1+1][l2+1];
memset(dp,0,sizeof(dp));
for (long j=0;j<l2;j++){
dp[0][j]=1;
}
for(long i=1;i<=l1;i++){
for(long j=1;j<=l2;j++){
if(t[i-1]==s[j-1]) dp[i][j]=dp[i-1][j-1]+dp[i][j-1];
else dp[i][j]=dp[i][j-1];
}
}
return dp[l1][l2];
}583. 两个字符串的删除操作
力扣题目链接(opens new window)
给定两个单词 word1 和 word2,找到使得 word1 和 word2 相同所需的最小步数,每步可以删除任意一个字符串中的一个字符。
示例:
- 输入: "sea", "eat"
- 输出: 2
- 解释: 第一步将"sea"变为"ea",第二步将"eat"变为"ea"
int minDistance(char* word1, char* word2) {
int l1=strlen(word1),l2=strlen(word2);
int dp[l1+1][l2+1];//避免初始化麻烦;dp是最长公共子集,操作数=长度和-2*公共子集
memset(dp,0,sizeof(dp));
for (int i=1;i<=l1;i++){ //从1开始,长度可以取到
for (int j=1;j<=l2;j++){
//对于字符串来说是i-1,对于dp来说是i
//结尾相同——那考虑没有结尾的时候,两个的选择
if(word1[i-1] == word2[j-1] ) dp[i][j]=dp[i-1][j-1]+1;
//结尾不同,那么就是分别一边少一个结尾,取最大值
else dp[i][j]=fmax(dp[i-1][j],dp[i][j-1]);
}
}
return l1+l2-2*dp[l1][l2];
}也可以正向思考:记录删除的最小次数
确定dp数组(dp table)以及下标的含义
dp[i][j]:以i-1为结尾的字符串word1,和以j-1位结尾的字符串word2,想要达到相等,所需要删除元素的最少次数。
这里dp数组的定义有点点绕,大家要撸清思路。
确定递推公式
- 当word1[i - 1] 与 word2[j - 1]相同的时候
- 当word1[i - 1] 与 word2[j - 1]不相同的时候
当word1[i - 1] 与 word2[j - 1]相同的时候,dp[i][j] = dp[i - 1][j - 1];
当word1[i - 1] 与 word2[j - 1]不相同的时候,有三种情况:
情况一:删word1[i - 1],最少操作次数为dp[i - 1][j] + 1
情况二:删word2[j - 1],最少操作次数为dp[i][j - 1] + 1
情况三:同时删word1[i - 1]和word2[j - 1],操作的最少次数为dp[i - 1][j - 1] + 2
那最后当然是取最小值,所以当word1[i - 1] 与 word2[j - 1]不相同的时候,递推公式:dp[i][j] = min({dp[i - 1][j - 1] + 2, dp[i - 1][j] + 1, dp[i][j - 1] + 1});
因为 dp[i][j - 1] + 1 = dp[i - 1][j - 1] + 2,所以递推公式可简化为:dp[i][j] = min(dp[i - 1][j] + 1, dp[i][j - 1] + 1);
这里可能不少录友有点迷糊,从字面上理解 就是 当 同时删word1[i - 1]和word2[j - 1],dp[i][j-1] 本来就不考虑 word2[j - 1]了,那么我在删 word1[i - 1],是不是就达到两个元素都删除的效果,即 dp[i][j-1] + 1。
dp数组如何初始化
从递推公式中,可以看出来,dp[i][0] 和 dp[0][j]是一定要初始化的。
dp[i][0]:word2为空字符串,以i-1为结尾的字符串word1要删除多少个元素,才能和word2相同呢,很明显dp[i][0] = i。
72. 编辑距离
力扣题目链接(opens new window)
给你两个单词 word1 和 word2,请你计算出将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
-
插入一个字符
-
删除一个字符
-
替换一个字符
-
示例 1:
-
输入:word1 = "horse", word2 = "ros"
-
输出:3
-
解释: horse -> rorse (将 'h' 替换为 'r') rorse -> rose (删除 'r') rose -> ros (删除 'e')
-
示例 2:
-
输入:word1 = "intention", word2 = "execution"
-
输出:5
-
解释: intention -> inention (删除 't') inention -> enention (将 'i' 替换为 'e') enention -> exention (将 'n' 替换为 'x') exention -> exection (将 'n' 替换为 'c') exection -> execution (插入 'u')
提示:
- 0 <= word1.length, word2.length <= 500
- word1 和 word2 由小写英文字母组成
分析:
要考虑所有的推导情况

int minDistance(char* word1, char* word2) {
int l1=strlen(word1);
int l2=strlen(word2);
int dp[l1+1][l2+1];//最小替换次数
memset(dp,0,sizeof(dp));
for (int i=0;i<=l1;i++){
dp[i][0]=i;
}
for (int j=1;j<=l2;j++) dp[0][j]=j;
for(int i=1;i<=l1;i++){
for(int j=1;j<=l2;j++){
if(word1[i-1]==word2[j-1]) dp[i][j]=dp[i-1][j-1];
else dp[i][j]=fmin(dp[i-1][j-1],fmin(dp[i-1][j],dp[i][j-1]))+1;
//dp[i-1][j-1]+1补上了一个替换
//dp[i-1][j]补一个删减
//dp i j-1 补一个增加
}
}
return dp[l1][l2];
}