目录
一,基本情况
二,list常用命令
2.1 lpush,lrange
2.2 对于“下标越界”的思考
2.3 lpushx,rpush,rpushx
2.4 lpop,rpop
2.5 lindex,linsert,llen
2.6 lrem
2.7 ltrim,lset
2.8 阻塞版本命令
2.9 blpop,brpop
三,内部编码
四,应用场景
4.1 作为数组
4.2 作为消息队列
一,基本情况
- 列表(list)相当于数组或者顺序表,约定最左边元素下标为0,后面依次递增;但是Redis的list支持负数下标,规定最右边的下标为-1,往左依次递减,如下图:

- 如上图,list支持左右两边的插入和删除:lpus,lpop,rpush,rpop。
- 所以list内部的编码方式,并非一个简单的数组,而是接近于deque那样的双端队列
list类型特点:
- 列表中的元素是有序的:“有序”的含义要根据上下文区分,此处的“有序”不仅仅是升序降序,指的是顺序很关键(如果把元素位置调换,得到的新的list和旧的list是不等价的;当调换后新list和旧list一样,就称之为顺序不关键),所以一个词要怎么理解,务必要结合上下文,结合具体场景去理解
- 区分获取元素和删除元素的区别:lrem是删除,lindex是获取,两个命令的返回值是一样的,容易混淆。
- list中的元素允许重复:像hash这样的类型,field不能重复
- 因为当前的list,能头和尾都能插入和删除,可以把list当作一个栈或者队列来使用
二,list常用命令
命令查询文档传送门:Commands | Docs (redis.io)
2.1 lpush,lrange
lpush表示从列表左边头插元素(插入1,2,3,4,完成操作后4在最前面),可以一次插入多个,能减少网络开销;lrange作用是查询指定区间的值,有三个参数,第一个为key,第二个和第三个为指定区间的开始下标和结束下标,是一个闭区间:

要想一次查询所有元素,只需要将lrange的开始设为0,结尾设为-1即可:

注意:
- 如果key已经存在并且对应的value不是list,那么lpush就会报错
- lrange前面显示的序号和下标无关,是专门给结果集使用的序号,给我们看的。(hash类型操作也有这样的序号,但是也和下标无关,因为hash没有下标的概念)
2.2 对于“下标越界”的思考
问题:谈到下标,往往会有“超过范围”这样的情况,如何理解?
解答: C++中,下标超出范围,一般会认为这是一个“未定义行为”,可能会导致程序崩溃,也可以会得到一个不合法的数据,还有可能会得到一个“看起来合法,但是错误”的数据,还有可能得到符合要求的数据(类似开盲盒);而在Java中,下标超出范围,一般会“抛异常”。
而在Redis中,两种行为都为采用,如果区间是合法的就正常搞,如果不合法,就直接尽可能去获取对应的内容,这种处理方式接近于Python的“切片”的处理方式。
比如,盆友找我借100,但是我只有50,盆友说:“50就50吧,借我一下谢谢”,能给多少给多少这样。

C++和Java对于越界的处理方式,有哪些优点和缺点呢?
C++的处理方式:
- 优点:效率是最高的,因为Java要抛异常,就代表Java要多出一步“下标合法性验证”的步骤,做的工作多了,效率就低了
- 缺点:程序员不一定能第一时间发现问题,而且很难发现,就导致最后的结果是“带伤运行”,最后越积越多,导致严重后果
Java的处理方式:
- 优点:出现问题能及时发现
- 缺点:效率没C++高,因为多了一步
Redis或Python的处理方式,是一种更加柔和式的做法,称之为“鲁棒性”(你对我越粗鲁,我就表现得越棒),这样的设定能大大提高程序的“容错性”,但是也有代价,所以这三种方式的实现,还是需要集合具体场景去搞
2.3 lpushx,rpush,rpushx
lpushx作用是,如果key存在,就头插操作,如果不存在就什么都不做;rpush就是尾插,其余机制和lpush一样;rpushx和lpushx的作用一样,只是变成了尾插:


问题:有lrange,有没有rrange呢?
解答:没有,因为lrange,延长来说是list range,不是left range
2.4 lpop,rpop
lpop头删,,当key不存在,返回nil;rpop尾删,当key不存在,返回nil

注意:
在从Redis 6.2 版本中,新增了count参数,但是当前的Redis 5 版本没有,count表示一次要删除几个数,因为一次只删一次相比一次删多个效率确实低了点
2.5 lindex,linsert,llen
lindex作用是根据下标来获取元素,下标非法返回nil;linsert就是在指定下标插入元素,可以自定义在左边插入还是在右边插入,下标非法返回nil;llen返回list长度,key不存在返回0:
lindex:

linsert:
linsert key BEFORE|AFTER pivot element
先从左往右根据基准值找到符合要求的位置,再进行插入
llen:

2.6 lrem
lrem key count elementcount表示要删除的个数,element表示要删除的值
关于count还有一些说法,官方文档给出的解释如下:

解释一下:
- 当count > 0:从左往右去找,比如list值为“1 2 3 4 1 2 3 4 1 2 3 4”,count为2,element为1,表示从左往右找1,删两次1,结果变成“2 3 4 2 3 4 1 2 3 4”,前面两个1被删除
- 当count < 0:从右往做找,以上面的为例,count为-2,element为1,表示从右往左找两个1删除,最后变成“1 2 3 4 2 3 4 2 3 4”,后面的两个1被删除
- 当count = 0:删除所有的指定元素,还是以上面的为例,count为0,element为1,就找到所有的1删除,结果为“2 3 4 2 3 4 2 3 4”

2.7 ltrim,lset
ltrim作用也是删除元素,但是是反过来的,指定一个区间,保存这个区间里的元素,区间外的就删除,区间不合法时返回0;lset作用是根据下标修改元素:
ltrim:

在官方文档中查询ltrim时,还有一个东西:

- 其中ACL全程是access control list,访问控制列表,是一个和权限相关的东西,从Redis 6 版本开始支持
- Redis有很多命令,acl这块就把每个命令打上一些标签,比如上面的@write表示这是一个“写”命令,@list表示这是一个和list类型相关的命令,@slow表示这个命令可能会很耗时
- 打好标签之后,管理员给每个Redis用户配置不同的权限,让该用户执行“能执行”的命令
lset:
lset key index elementindex表示要开始修改的下标位置,element表示要修改的元素

2.8 阻塞版本命令
阻塞:当前的线程不走了,代码不继续执行了,在满足一定条件后被唤醒
blpop,brpop是阻塞命令中两个最重要的,前面的b表示block阻塞
我们在学习生产者消费者模型时,讲到了一个阻塞队列:Linux系统编程——生产者消费者模型_编程 消费者-CSDN博客
用队列来作为交易场所,并且希望这个队列有两个特性:1,线程安全 2,阻塞:
- 如果队列为空,此时尝试出队列,就阻塞,直到队列不为空,阻塞接触
- 如果队列为满,此时尝试入队列,就阻塞,直到队列不为满,阻塞接触
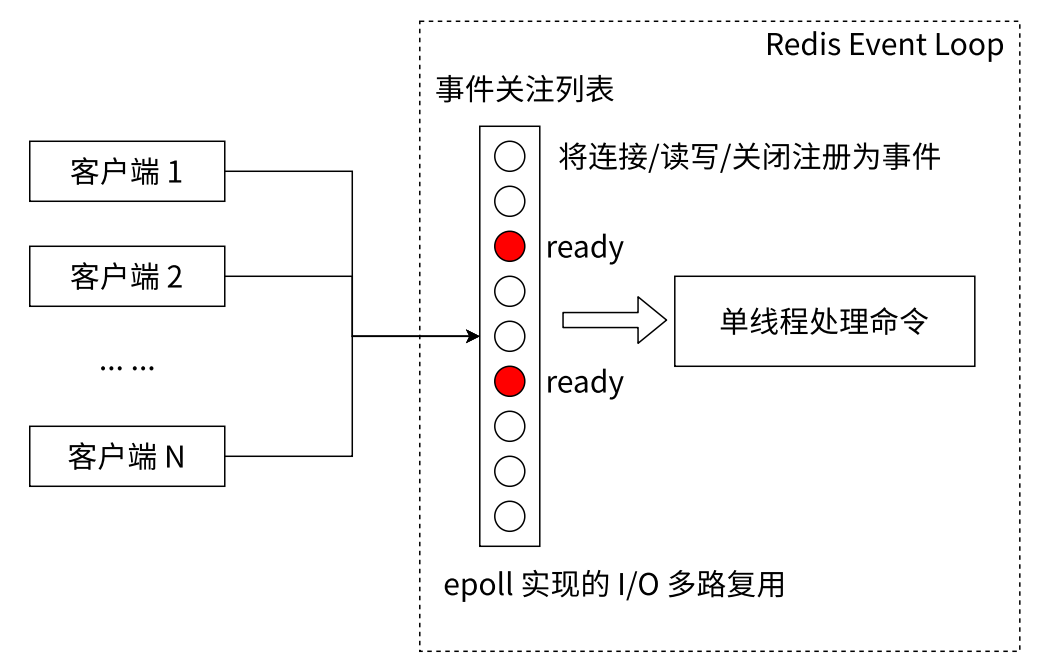
Redis中list也相当于一个阻塞队列, 首先线程安全通过单线程模型能保证,而阻塞只支持“队列为空”的情况,不考虑“队列为满”。
blpop 和 brpop 是 lpop 和 rpop 的阻塞版本,和对应⾮阻塞版本的作⽤基本⼀致,除了:
- 在list不为空的情况下,blpop 和 brpop 就和 lpop 和 rpop作用一样;但如果list为空,blpop 和 brpop就会阻塞住,直到队列不为空
- 使用blpop 和 brpop 的时候,是可以设置阻塞时间的,如果阻塞了,那么在这个阻塞时间内是可以执行其它命令的;当阻塞时间到了,会自动返回(例子:我约女生晚上6点吃饭,结果我等到9点女生还没来,我就不等了,及时止损,节约我的时间)
- blpop 华人 brpop 都是可以同时去获取多个key的列表的元素的,就是命令行可以同时出现多个key的,这多个list哪个有元素了,就会返回哪个值(例子:我可以同时约多个女生出来吃饭,哪个女生先到了我就和哪个去吃饭,其她的不管了)
- 如果多个客⼾端同时多⼀个键执⾏ pop,则最先执⾏命令的客⼾端会得到弹出的元素(例子:多个人约女生,当女生有空时,哪个人最先约的女生,女生就和谁去吃饭)
2.9 blpop,brpop
blpop key [key ...] timeout- blpop的选项和brpop是一样的,可以指定多个key,每个key都对应一个list,如果这些list有任意一个非空,blpop和brpop都能够把这里的元素获取到立即返回,
- 如果list都为空,就会阻塞住,等待其他客户端往list插入数据;
- 另外还可以指定超时时间,单位为秒;在Redis 6 版本后,允许设为小数
我们先针对一个非空的list进行操作:

- 返回的结果是一个pair,一方面告诉我们你当前的数据来自于哪个key,另一方面告诉我们取到的数据是啥
我们针对空的列表进行操作: 
我们删掉key后,在blpop就阻塞住了,然后我们在右边的客户端一创建key, 左边的客户端就立马拿到了数据,brpop作用和现象和blpop一样,就不做演示了
这两个阻塞命令,用途主要就是来作为“消息队列”,但是我们一般不使用,因为前面也说过了,Redis不适合拿来做消息队列,因为有其他更好的产品可以用作消息队列,而且提供的功能也比较多
三,内部编码
旧版本是用ziplist和linkedlist作为底层实现的,但是现在已经不用了,直接用的quicklist来实现了,但是我们去查一些文档时,上面可能还是解释的ziplist和linkedlist,所以我们只简单了解下这两个,重点还是在quicklist:
- ziplist(压缩列表):当列表的元素个数⼩于 list-max-ziplist-entries 配置(默认 512 个),同时 列表中每个元素的⻓度都⼩于 list-max-ziplist-value 配置(默认 64 字节)时,Redis 会选⽤ ziplist 来作为列表的内部编码实现来减少内存消耗。
- linkedlist(链表):当列表类型⽆法满⾜ ziplist 的条件时,Redis 会使⽤ linkedlist 作为列表的内 部实现。
quicklist相当于链表和压缩列表的结合,整体是一个链表,但是它的每个节点是一个压缩列表(每个压缩列表都限制大小,然后再把多个压缩列表通过链式结构组织起来,就是quicklist)

四,应用场景
4.1 作为数组
最经典的,就是用list作为“数组”来存储多个元素

4.2 作为消息队列
虽说Redis不经常用来做消息队列,但毕竟是Redis设计的初心,了解一下有利于了解Redis的发展

多个客户端执行brpop操作,当列表为空时,brpop就会阻塞住,一旦有新元素来了,谁先执行的brpop命令,谁就能拿到这个新来的元素,像这样的设定,就能构成一个“轮询”式的效果。
假设消费者执行的顺序是1 2 3:
- 当新元素到达后,首先是消费者1最先执行的brpop,所以它最先拿到元素,然后brpop执行执行完了直接返回,假设线程1还想继续消费,就需要重新执行brpop,重新去排队
- 然后再来一个新元素,就是消费者2拿到元素,也从brpop返回,要想再拿数据也需要重新排队
- 再来一个新元素,就是消费者3拿到元素了
将上面的模型扩大一下,就是下面这样的了:

因为多个 列表或者频道是非常常见的,比如抖音,需要有一个通道来传输视频数据,还有传输弹幕,传输点赞收藏转发,传输评论数据等等,都需要一个频道来传输,因为像这样搞成多个频道,就可以在一个数据通道发生问题时,不会对其他数据造成影响(解耦合)