文章目录
- 一、神经网络基本骨架 nn.Module
- 二、卷积层
- 三、池化层
- 四、非线性激活层
- 五、线性层
- 六、模型搭建小练习:CIFAR 10 model 结构
- 七、损失函数与反向传播
- 八、优化器
- 九、现有网络模型的使用与修改
- 十、网络模型的保存与读取
- 十一、一个完整模型训练套路
- 十二、GPU加速
- 十三、一个完成的模型验证套路
一、神经网络基本骨架 nn.Module
import torch
from torch import nn
class Frame(nn.Module):
def __init__(self):
super().__init__()
def forward(self, input):
output = input + 1
return output
frame = Frame()
x=torch.tensor(1.0)
output = frame(x) # 执行forward函数,相当于触发Frame的__call__方法
print(output)
二、卷积层
卷积计算就是卷积核与输入数据,按对应位置,逐个求其乘积,再求这些乘积之和,得到一个值。按照上述方法,按设置的步长stride,移动卷积核,分别求出所有的值。
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
input = torch.reshape(input, (1, 1, 5, 5)) # (batch_size,channel,row,column)
kernel = torch.reshape(kernel, (1, 1, 3, 3))
output1 = F.conv2d(input, kernel, stride=1) # conv2d表示二维卷积
print(output1)
output2 = F.conv2d(input, kernel, stride=2) # 卷积核每步移动2
print(output2)
output3 = F.conv2d(input, kernel,stride=1, padding=1) # padding=1表示原始数据填充一圈数字,默认填充0
print(output3)
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../dataset", train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Network(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=3,
stride=1, padding=0)
# conv1 的权重(out_channels, in_channels, kernel_height, kernel_width)
# 即为(6,3,3,3)
def forward(self, x):
x = self.conv1(x)
return x
network = Network()
writer = SummaryWriter("./logs")
step = 0
for data in dataloader:
imgs, targets = data
output = network(imgs)
# print(imgs.shape) # torch.Size([64, 3, 32, 32])
# print(output.shape) # torch.Size([64, 6, 30, 30])
writer.add_images("input",imgs, step)
output = torch.reshape(output, (-1, 3, 30, 30))
# 上句代码中的-1.可以自动计算batch数量
# print(output.shape) # # torch.Size([128, 3, 30, 30])
writer.add_images("output",output,step)
step = step + 1
注:如果在tensorboard中显示的step不连续,可在pycharm终端中输入:tensorboard --logdir=logs --samples_per_plugin=images=10000
三、池化层
池化的目的是:保留输入的特征,同时减少数据量。
以最大池化为例:池化核与输入数据,按对应位置,选出最大的一个值。按照上述方法,按设置的步长stride,移动池化核,分别求出所有的值。
import torch
from torch import nn
from torch.nn import MaxPool2d
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]], dtype=torch.float32)
input = torch.reshape(input,(-1, 1, 5, 5))
print(input.shape) # torch.Size([1, 1, 5, 5])
class Network(nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=False)
# ceil_mode=Ture时,则会启用ceil模式,即移动池化核进行计算时,输入数据不足池化核数量,也进行计算
# stride默认是池化核的大小
def forward(self, input):
output = self.maxpool1(input)
return output
network = Network()
output = network(input)
print(output) # tensor([[[[2.]]]])
import torchvision.datasets
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Network(nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=False)
# ceil_mode=Ture时,则会启用ceil模式,即移动池化核进行计算时,输入数据不足池化核数量,也进行计算
# stride默认是池化核的大小
def forward(self, input):
output = self.maxpool1(input)
return output
network = Network()
writer = SummaryWriter("./logs_maxpool")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, step)
output = network(imgs)
writer.add_images("output", output, step)
step = step + 1
writer.close()
四、非线性激活层
import torch
from torch import nn
input = torch.tensor([[1, -0.5],
[-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2))
print(input.shape) # torch.Size([1, 1, 2, 2])
class Network(nn.Module):
def __init__(self):
super().__init__()
self.relu1 = nn.ReLU() # inplace=True则会输出值覆盖输入值。一般使用默认值False
def forward(self, input):
output = self.relu1(input)
return output
network = Network()
output = network(input)
print(output)
# tensor([[[[1., 0.],
# [0., 3.]]]])
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
input = torch.tensor([[1, -0.5],
[-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2))
print(input.shape) # torch.Size([1, 1, 2, 2])
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Network(nn.Module):
def __init__(self):
super().__init__()
self.sigmoide1 = nn.Sigmoid()
def forward(self, input):
output = self.sigmoide1(input)
return output
network = Network()
writer = SummaryWriter("./logs_relu")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, global_step=step)
output = network(imgs)
writer.add_images("output", output, step)
step += 1
writer.close()
五、线性层

其中nn.Linear()中的参数,in_features可以理解为x的个数,out_features可以理解为g的个数
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", train=False,
transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Network(nn.Module):
def __init__(self):
super().__init__()
self.linearl = nn.Linear(196608, 10) # 因为该数据集分为10类,所以out_features设置为10
def forward(self, input):
output = self.linearl(input)
return output
network = Network()
for data in dataloader:
imgs, targets = data
print(imgs.shape) # torch.Size([64, 3, 32, 32])
# output = torch.reshape(imgs, (1, 1, 1, -1))
output = torch.flatten(imgs) # 与上一句代码作用类似
print(output.shape) # torch.Size([196608])
output = network(output)
print(output.shape) # torch.Size([10])
break
六、模型搭建小练习:CIFAR 10 model 结构

import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class Network(nn.Module):
def __init__(self):
super().__init__()
# Sequential内参数模块,会顺序执行
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(), #我的版本默认start_dim=1
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
network = Network()
# 检验网络正确性
input = torch.ones(64, 3, 32, 32)
output = network(input)
print(output.shape)
# 可视化
writer = SummaryWriter("./logs_seq")
writer.add_graph(network, input)
writer.close()
七、损失函数与反向传播
损失函数loss的作用:
1、计算实际输出和目标之间的差距
2、为我们更新输出提供一定的依据(反向传播), grad
import torch
from torch.nn import L1Loss
from torch import nn
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
loss = L1Loss()
result = loss(inputs, targets)
print(result) # tensor(0.6667)
loss = L1Loss(reduction="sum")
result = loss(inputs, targets)
print(result) # tensor(2.)
loss_mse = nn.MSELoss()
result_mse = loss_mse(inputs, targets)
print(result_mse) # tensor(1.3333)
交叉熵计算公式
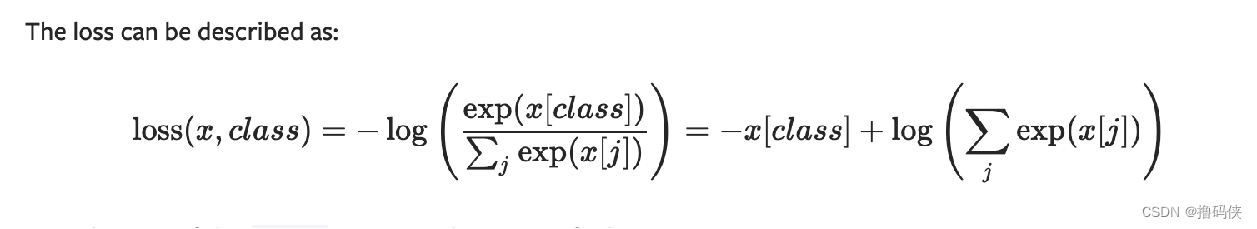
import torch
from torch import nn
# 交叉熵适用于分类问题
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x, (1, 3))
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x, y)
print(result_cross) # tensor(1.1019)
# Loss(x, class) = -0.2+log(exp(0.1)+exp(0.2)+exp(0.3))
backward()可以得到每个要更新参数的梯度
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
class Network(nn.Module):
def __init__(self):
super().__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
network = Network()
for data in dataloader:
imgs, targets = data
outputs = network(imgs)
result_loss = loss(outputs, targets)
result_loss.backward()
print("ok")
八、优化器
import torch
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.optim.lr_scheduler import StepLR
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
class Network(nn.Module):
def __init__(self):
super().__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
network = Network()
# 创建一个随机梯度下降优化器对象
optim = torch.optim.SGD(network.parameters(), lr=0.01) # lr为学习率
# 创建学习率调度器对象
scheduler = StepLR(optim, step_size=5, gamma=0.1)
# step_size=5: 每经过 5 个epoch,学习率会按照 gamma 的比例进行衰减。
# gamma=0.1: 这是学习率衰减的乘数因子。每次调度器触发时,当前学习率会乘以 gamma
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = network(imgs)
result_loss = loss(outputs, targets)
optim.zero_grad() # 所有参数梯度清零
result_loss.backward() # 反向传播,获得参数梯度
optim.step() # 调度优化器优化模型参数
running_loss = running_loss + result_loss
scheduler.step() # 学习率调度器,调整学习率
print(running_loss)
九、现有网络模型的使用与修改
以vgg16为例
import torchvision
from torch import nn
from torchvision.models import VGG16_Weights
# 只下载网络模块结构
vgg16_false = torchvision.models.vgg16(weights = None)
# 下载网络模块结构和训练的权重值
vgg16_true = torchvision.models.vgg16(weights=VGG16_Weights.DEFAULT)
# print(vgg16_true)
# 添加一个线性层
# vgg16_true.add_module('add_linear', nn.Linear(1000, 10))
# print(vgg16_true)
vgg16_true.classifier.add_module('add_linear', nn.Linear(1000, 10))
print(vgg16_true)
# 修改网络中的某个模块
print(vgg16_false)
vgg16_false.classifier[6] = nn.Linear(4096, 10)
print(vgg16_false)
十、网络模型的保存与读取
方法一(保存模型结构+模型参数):
保存:
import torch
import torchvision
vgg16 = torchvision.models.vgg16(weights=None)
torch.save(vgg16, "vgg16_method1.pth")
加载:
import torch
model = torch.load("vgg16_method1.pth")
print(model)
此方法存在以下问题:
保存:
import torch
from torch import nn
class Network(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3)
def forward(self, x):
x = self.conv1(x)
return x
network = Network()
torch.save(network, "network_method1.pth")
加载:
import torch
from torch import nn
# 注意,不写此类,直接执行torch.load,会报错
class Network(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3)
def forward(self, x):
x = self.conv1(x)
return x
model = torch.load("network_method1.pth")
print(model)
方法二(只保存模型参数,推荐)
保存:
import torch
import torchvision
vgg16 = torchvision.models.vgg16(weights = None)
torch.save(vgg16.state_dict(), "vgg16_method2.pth")
加载:
import torch
import torchvision
vgg16 = torchvision.models.vgg16(weights = None)
model_par = torch.load("vgg16_method2.pth")
vgg16.load_state_dict(model_par)
print(vgg16)
十一、一个完整模型训练套路
model.py:
import torch
from torch import nn
class Network(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3,32,5,padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024,64),
nn.Linear(64,10)
)
def forward(self,x):
output = self.model(x)
return output
if __name__ == '__main__':
network = Network()
input = torch.ones((64, 3, 32, 32))
output = network(input)
print(output.shape)
train.py:
import torchvision
from torch.utils.tensorboard import SummaryWriter
from model import *
from torch import nn
from torch.utils.data import DataLoader
################## 准备数据 ##################
train_data = torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
print("训练集长度为:{}".format(len(train_data)))
print("测试集长度为:{}".format(len(test_data)))
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
################## 创建网络 ##################
network = Network()
################## 损失函数 ##################
loss_fn = nn.CrossEntropyLoss()
################### 优化器 ###################
learning_rate = 1e-2 # 0.01
optimizer = torch.optim.SGD(network.parameters(), lr=learning_rate)
################## 训练循环 ##################
total_train_step = 0
total_test_step = 0
epoch = 10
writer = SummaryWriter("./logs_train")
for i in range(epoch):
print("------第 {} 论训练开始------".format(i+1))
# 训练步骤开始
network.train() # 设置网络进入训练模式
# 因为有的模块在训练和测试模式下的行为不一样,所以最好设置一下
for data in train_dataloader:
imgs, targets = data
outputs = network(imgs)
loss = loss_fn(outputs, targets) # loss是tensor类型
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
print("训练次数:{}, Loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
network.eval() # 设置网络进入测试模式
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = network(imgs)
loss = loss_fn(outputs, targets)
total_test_loss += loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
# outputs.argmax(1)会比较outputs每行最大值,返回它的索引
# outputs.argmax(1) == targets 会返回一个元素为bool的tensor
# sum()会将这个tensor所有的True个数加和
total_accuracy += accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/len(test_data)))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/len(test_data), total_test_step)
total_test_step += 1
torch.save(network, "network_{}.pth".format(i))
print("模型已保存")
writer.close()
十二、GPU加速
GPU加速需将将网络模型、数据(输入数据和标签)、损失函数,移动到CUDA上。
第一种方法:调用cuda()方法
import torch.cuda
import torchvision
from torch.utils.tensorboard import SummaryWriter
from model import *
from torch import nn
from torch.utils.data import DataLoader
################## 准备数据 ##################
train_data = torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
print("训练集长度为:{}".format(len(train_data)))
print("测试集长度为:{}".format(len(test_data)))
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
################## 创建网络 ##################
network = Network()
if torch.cuda.is_available():
network.cuda() # 调用cuda()会在模型原对象中修改,不需要赋值给原对象
################## 损失函数 ##################
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn.cuda() # 冗余操作,该代码可以省略,因为它已经在 GPU 上进行计算
################### 优化器 ###################
learning_rate = 1e-2 # 0.01
optimizer = torch.optim.SGD(network.parameters(), lr=learning_rate)
################## 训练循环 ##################
total_train_step = 0
total_test_step = 0
epoch = 10
writer = SummaryWriter("./logs_train")
for i in range(epoch):
print("------第 {} 论训练开始------".format(i+1))
# 训练步骤开始
network.train() # 设置网络进入训练模式
# 因为有的模块在训练和测试模式下的行为不一样,所以最好设置一下
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda() # 输入数据调用cuda(),会产生新的张量,需要赋值给原对象
targets = targets.cuda() # 同上
outputs = network(imgs)
loss = loss_fn(outputs, targets) # loss是tensor类型
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
print("训练次数:{}, Loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
network.eval() # 设置网络进入测试模式
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = network(imgs)
loss = loss_fn(outputs, targets)
total_test_loss += loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
# outputs.argmax(1)会比较outputs每行最大值,返回它的索引
# outputs.argmax(1) == targets 会返回一个元素为bool的tensor
# sum()会将这个tensor所有的True个数加和
total_accuracy += accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/len(test_data)))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/len(test_data), total_test_step)
total_test_step += 1
torch.save(network, "network_{}.pth".format(i))
print("模型已保存")
writer.close()
第二种方法:调用to(device)方法
import torch.cuda
import torchvision
from torch.utils.tensorboard import SummaryWriter
from model import *
from torch import nn
from torch.utils.data import DataLoader
################## 准备数据 ##################
train_data = torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
print("训练集长度为:{}".format(len(train_data)))
print("测试集长度为:{}".format(len(test_data)))
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
################ 定义训练设备 #################
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
################## 创建网络 ##################
network = Network()
network.to(device)
################## 损失函数 ##################
loss_fn = nn.CrossEntropyLoss()
################### 优化器 ###################
learning_rate = 1e-2 # 0.01
optimizer = torch.optim.SGD(network.parameters(), lr=learning_rate)
################## 训练循环 ##################
total_train_step = 0
total_test_step = 0
epoch = 10
writer = SummaryWriter("./logs_train")
for i in range(epoch):
print("------第 {} 论训练开始------".format(i+1))
# 训练步骤开始
network.train() # 设置网络进入训练模式
# 因为有的模块在训练和测试模式下的行为不一样,所以最好设置一下
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = network(imgs)
loss = loss_fn(outputs, targets) # loss是tensor类型
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
print("训练次数:{}, Loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
network.eval() # 设置网络进入测试模式
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = network(imgs)
loss = loss_fn(outputs, targets)
total_test_loss += loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
# outputs.argmax(1)会比较outputs每行最大值,返回它的索引
# outputs.argmax(1) == targets 会返回一个元素为bool的tensor
# sum()会将这个tensor所有的True个数加和
total_accuracy += accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/len(test_data)))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/len(test_data), total_test_step)
total_test_step += 1
torch.save(network, "network_{}.pth".format(i))
print("模型已保存")
writer.close()
十三、一个完成的模型验证套路
from PIL import Image
from model import *
from torchvision import transforms
image_path = "./airplane.jpg" # 网上随便找张飞机的图片
image = Image.open(image_path)
image = image.convert("RGB") # 图片变成RGB模式
transform = transforms.Compose([transforms.Resize((32, 32,)),
transforms.ToTensor()])
image = transform(image)
print(image.shape) # torch.Size([3, 32, 32])
image = torch.reshape(image,(1,3,32,32,))
image = image.cuda()
# CIFAR10的类别列表
classes = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
model_curr = torch.load("network_9.pth")
print(model_curr)
model_curr.eval()
with torch.no_grad():
output = model_curr(image)
output = output.argmax(1).item()
print(classes[output])