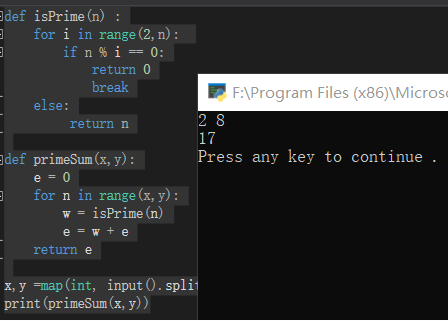
一.Lambda表达式
1.Lambda表达式的简介
Lambda表达式是 jdk1.8 引入的一个新特性,它是函数式编程在Java中的一种体现。也是jdk1.8最值得学习的新特性,另一个就是流式编程。
1.Lambda表达式的引入简化了匿名内部类的语法,让代码更加简洁明了。
2.Lambda表达式提供了一种便捷的语法形式,使得函数可以作为参数传递给方法,或者作为返回值返回。
3.Lambda表达式的引入使得Java在并行编程方面具备了更好的支持。
4.Lambda表达式本质来讲,是一个匿名函数(匿名方法)。
如果Lambda表达式带有多行代码,就必须在外部用大括号括起来
(x, y) -> {
int sum = x + y;
System.out.println("Sum: " + sum);
return sum;
}如果Lambda表达式没有形参的话,括号里可以什么也不填,但是不可以不写;如果只有一个形参的话,可以加上变量的类型,也可以不加,如果不加形参的类型,则可以不加小括号
(int m) -> System.out.println(m);
或
(m) -> System.out.println(m);
或
m -> System.out.println(m);
(int x, int y) -> System.out.println(x + y);
或
(x, y) -> System.out.println(x + y);2.Lambda表达式的应用
Lambda表达式只能作用于函数式接口(有且只有一个抽象方法的接口)
案例演示:
class Person implements Comparable<Person> {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public Person(){}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int compareTo(Person o) {
return this.age - o.age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
首先我们中定义了一个Person类,继承了Comparable接口;并在类中定义了成员变量,提供了构造器,getter和setter方法,并重写了comparabale接口的比较方法和toString方法。
在main方法中测试
List<Person> ps = new ArrayList<>();
ps.add(new Person("张三", 19));
ps.add(new Person("李四", 20));
ps.add(new Person("王五", 18));
ps.add(new Person("赵六", 19));
//排序
Collections.sort(ps);
System.out.println(ps);我们首先创建了一个集合对象,传入Person类,调用add方法添加元素,之后对集合按照年龄默认升序进行排序

如果我们想在不改变源代码的情况下将排序规则变为按照年龄降序,可以使用在sort方法中传入一个比较器对象;在比较器对象中重写compare方法
Comparator c = new Comparator<Person>() {
public int compare(Person o1, Person o2) {
return o2.getAge() - o1.getAge();
}
};
//排序
Collections.sort(ps,c);
System.out.println(ps);![]()
为了简化使用匿名内部类的代码,我们可以使用Lambda表达式来进行替换
Collections.sort(ps, (o1,o2)->(o2.getAge()-o1.getAge()));
System.out.println(ps);我们只使用一行代码就可以等效替换掉匿名内部类中书写了四行的代码;
在Lambda表达式中,我们首先传入了两个参数,使用( )括起来,
用一个 -> 来表示形参需要实现的函数体(方法体),如果该方法返回值则需要添加return,如果没有返回值则无需添加;
3.Lambda表达式的案例演示
//里面的抽象方法没有形参,也没有返回值
interface NoParameterNoReturn{
void print();
}
//一个形参,没有返回值
interface OneParameterNoReturn{
void print(String info);
}
//多个形参,没有返回值
interface MuilParameterNoReturn{
void print(String info,int age);
}
//没有形参,带有返回值
interface NoParameterReturn{
int calculate();
}
//一个形参,带有返回值
interface OneParameterReturn{
int calculate(int a);
}
//多个形参,带有返回值
@FunctionalInterface //注解是用来校验是否是函数式接口
interface MuilParameterReturn{
int calculate(int a,int b);
}我们先定义了六个接口,表示的含义分别是无形参,无返回值的抽象方法,一个形参,无返回值的抽象方法,多个形参,无返回值的抽象方法,无形参,有返回值的抽象方法,一个形参,有返回值的抽象方法,多个形参,有返回值的抽象方法我们需要使用Lambda表达式的方式来实现这些接口
class Test implements NoParameterNoReturn {
@Override
public void print() {
System.out.println("java编程真简单");
}
}我们可以定义一个实现类实现无参无返回值的接口;重写里面的抽象方法即可,输出java编程真简单这个字符串;
//2.测试实现类
Test t1 = new Test();
t1.print();
//3.使用匿名内部类的方式,实现NoParameterNoReturn接口,打印“我一定能学会Java”
NoParameterNoReturn nn = new NoParameterNoReturn() {
@Override
public void print() {
System.out.println("我一定能学会java");
}
};
nn.print();在main方法中,我们可以测试该实现类,创建一个该类的对象,并用对象来调用print方法;我们也可以使用匿名内部类的方式来实现该接口,创建一个该接口的对象nn,并重写print方法,输出打印语句我一定能学会Java,之后在main方法中通过匿名内部类对象来调用该方法。

//4.使用Lambda表达式,实现NoParameterNoReturn接口,打印“哈哈哈,我哭了...”
NoParameterNoReturn nn1 = ()-> System.out.println("哈哈哈,我哭了...");
nn1.print();下面的需求就是使用Lambda表达式来实现接口,输出打印哈哈哈,我哭了...
我们还是创建一个匿名内部类对象,但是我们不需要继续编写里面的方法了,可以用Lambda表达式来代替; 在等号右边 使用()代表没有形参;->来分隔函数体,直接输出打印语句即可
之后使用匿名内部类对象来调用该方法

//5.使用Lambda表达式,实现OneParameterNoReturn接口,打印"我喜欢"+“形参”,形参传入苹果
OneParameterNoReturn opn = (str)->System.out.println("我喜欢"+str);
String str1 = "苹果";
opn.print(str1);
实现单参无返回值接口
创建一个匿名内部类对象,在等号右边 (str)括号里需要传形参,因为是形参,我们可以传自己喜欢的; ->分隔符右侧打印输出语句,拼接字符串和形参即可,最后要使用匿名内部类对象来调用该方法;
![]()
/*6. 使用lambda表达式,实现MuilParameterNoReturn接口,打印两个参数拼接的效果,测试传入"我今年","18"*/
MuilParameterNoReturn mpn = (str,age)-> System.out.println(str+age);
String str2 = "我今年";
int age2 = 18;
mpn.print(str2,age2);实现多参无返回值接口
创建一个匿名内部类对象,在等号右边 (str,age)输入传入的形参,尽量做到见名知意;在->分隔符右侧打印输出语句,拼接这两个形参;
在main方法中声明两个形参类型的变量,并将其传入该方法
![]()
/*7. 使用lambda表达式,实现NoParameterReturn接口,计算两个随机数,区间[25,40]的和",测试*/
NoParameterReturn nr = ()-> {
int random = (int)(Math.random() * 16 + 25);
int random1 = (int)(Math.random() * 16 + 25);
return random+random1;
};
int calculate = nr.calculate();
System.out.println(calculate);实现无参有返回值接口
创建一个匿名内部类对象,在等号右边 ()没有形参括号可以空着,但不可以不写; 在分隔符->右侧书写方法体,代码不是一行需要添加花括号,在方法中声明两个随机数变量,返回值是两个变量的和,注意在花括号后面添加分号;
之后在main方法中通过对象来调用该方法,返回值类型是int,需要声明接收变量并打印

/*8. 使用lambda表达式,实现OneParameterReturn接口,计算形参的立方,测试传入3*/
OneParameterReturn opr = (a)->{
int result = (int)Math.pow(a,3);
return result;
};
int calculate1 = opr.calculate(3);
System.out.println(calculate1);实现单参有返回值接口
创建匿名内部类对象,在等号右边 (a)->{};花括号中写方法体;
可以直接使用Math类的pow方法,传入形参和指数即可,声明一个变量并将其返回;
在main方法中声明一个接收变量并将其打印就欧克了
![]()
/*9. 使用lambda表达式,实现MuilParameterReturn接口,计算两个形参的立方和,测试传入3和4*/
MuilParameterReturn mpr = (a,b)->{
int result = (int)Math.pow(a,3);
int result1 = (int)Math.pow(b,3);
return result+result1;
};
int calculate2 = mpr.calculate(3, 4);
System.out.println(calculate2);实现多参有返回值接口
首先创建匿名内部类对象,等号右边 (a,b)需要两个形参 ->写方法体,带花括号和分号
方法体中分别将两个形参放入pow方法,分别声明变量去接收;最后返回这两个变量的和
在main方法中声明一个变量来接收对象调用该方法的结果,并将其打印

4.三个常用情况
第一种:在排序过程中使用比较器的时候:
List<String> list = new ArrayList<String>();
list.add("michael");
list.add("david");
list.add("bob");
list.add("lucy");
//按照字符串的长度降序: 比较器使用了lambda表达式的方法
Collections.sort(list,(a,b)->b.length()-a.length());
System.out.println(list);我们先创建了一个集合,并向集合中添加了四个人名,可以调用集合工具类的排序方法,当需要传入比较器对象的时候,我们就可以传入Lambda表达式,传入两个形参,用第二个形参的长度减去第一个形参的长度,即完成降序操作;
![]()
第二种:集合的迭代
/*测试第二种:集合的迭代*/
Integer[] arr = new Integer[]{4,5,10,7,2};
List<Integer> nums = Arrays.asList(arr);首先我们创建了一个Integer类型的数组,传入5个数字,之后创建集合,使用数组工具类的转集合的方式;形参传入刚才创建的数组即可;
nums.forEach(num-> System.out.println(num));
System.out.println("============================");
//继续简化
nums.forEach(System.out::println);我们可以使用forEach来实现集合的迭代;形参是num ,我们只需要在方法体中直接打印num即可;更简单的方法就是直接在forEach中传入System.out :: println,使用系统类的输出流对象来调用println方法,简单粗暴有效。

Set接口的迭代:
Set<Integer> set = new HashSet<>(nums);
System.out.println(set);
set.forEach(System.out::println);
我们先需要将nums集合转换为Set接口的集合;也是可以直接调用粗暴forEach方法遍历集合

Map接口的迭代:
System.out.println("=============Map迭代==============");
Map<String, Integer> map = new HashMap<>();
map.put("张三", 18);
map.put("李四", 19);
map.put("王五", 17);
map.put("赵六", 28);
//key的迭代
map.keySet().forEach(System.out::println);
//entrySet的迭代
map.entrySet().forEach(entry -> System.out.println(entry.getKey() + "--" + entry.getValue()));
//value的迭代
map.values().forEach(value->System.out.println(value));
System.out.println("========================================");Map接口的迭代相对来讲较为复杂,因为有三种不同的遍历方式,首先是key的迭代,我们可以调用map.keySet()的方法先获取一个只有key的单列集合,再调用forEach的粗暴方式即可
对于entry的迭代,我们同样先获取键值对的集合,然后调用forEach方法,我们使用Lambda表达式,形参是键值对,可以直接调用打印方法,分别调用键值对的getKey方法和getValue方法通过字符串拼接来拼到一起;也可以直接使用粗暴方式;
最后是value的迭代,先获取到value,然后通过forEach,形参是value,函数体是直接打印输出语句,传入value即可,也可以直接使用粗暴方式;

第三种情况就是根据条件去删除元素
List<Integer> ages = Arrays.asList(18,19,17,20,17);
List<Integer> ages2 = new ArrayList<>(ages);
/**
* removeIf(Predicate filter):
* 源码解析:
* 内部逻辑就是一个迭代器遍历集合,根据条件做删除操作
* 条件就是filter的test方法
* Predicate 是一个函数接口,里面有boolean test(T t)方法,因此我们在使用是就是写一个
* Lambda表达式来实现test方法即可。
*/
ages2.removeIf(m->m.equals(17));
System.out.println(ages2);对于数组转成集合的集合,我们不能直接删除,需要创建一个原集合的副本来操作;我们可以调用removeIf方法,传入的形参,并通过形参调用equals方法,传入我们想删除的元素

5.匿名内部类对变量的捕获
在内部类中对外部类的变量的引用和访问;变量包括:
1.实例变量 2.静态变量 3.方法形参 4.本地变量
interface MyTest{
void test1();
}首先我们创建一个接口;定义一个抽象方法
public class _01InnerClassDemo {
private int a ; //实例变量
private static int b ; //静态变量
static{
b=2;
}
public _01InnerClassDemo() {
a = 1;
}
public void m1(int c) {
int d = 4;之后我们在主类中定义变量,有静态变量,实例变量,成员变量,形参变量,
public void m1(int c) {
int d = 4;
MyTest mt = new MyTest() {
@Override
public void test1() {
a+=1;
b+=1;
c+=1;
d+=1;
//访问外部类的成员变量:外部类名.this.成员变量 或者直接写
System.out.println("instance variable:" + a);
//访问外部类的静态变量:外部类名.静态变量 或者直接写
System.out.println("static variable:" + b);
//匿名内部来访问的方法形参也是只能访问,不能覆盖
System.out.println("method parameter" + c);
//匿名内部类访问的局部变量是默认被final修饰的:final修饰的变量只能初始化一次
System.out.println("native variable:" + d);
}
};
mt.test1();
}之后定义一个成员方法,创建一个匿名内部类对象mt实现MyTest接口;重写里面的test1方法,并对这四个变量都进行加一操作

我们发现,只有静态变量和实例变量才能操作,而形参和成员变量只能进行读,不能写
public void m2(int c) {
int d = 4;
MyTest mt = () -> {
a+=1;
b+=1;
c+=1;
d+=1;
//访问外部类的成员变量:外部类名.this.成员变量 或者直接写
System.out.println("instance variable:" + a);
//访问外部类的静态变量:外部类名.静态变量 或者直接写
System.out.println("static variable:" + b);
//匿名内部来访问的方法形参也是只能访问,不能覆盖
System.out.println("method parameter" + c);
//匿名内部类访问的局部变量是默认被final修饰的:final修饰的变量只能初始化一次
System.out.println("native variable:" + d);
};
mt.test1();
}可以在Lambda表达式中也测验一边

结果是一样的;

总结:匿名内部类访问的局部变量(本地变量,形参)都是只能访问,不能写,只能读
Lambda表达式对于局部变量也是只能读,不能写,实例变量和静态变量可以覆盖。
二.集合的流式编程
用传统的方式对集合进行增删过滤等操作,可能要书写大量的代码,而集合的流式编程可以大大减少代码量; 集合的流式编程,是在jdk1.8引入的两个重要特性之一;集合的流式编程是对传统方式的一种简化操作。
集合的流式编程一般分为3步:
1.获取数据源(关联数据源),返回Stream对象;
2.对stream对象进行各种处理,并返回stream对象
3.对stream对象进行整合处理,处理的结果一般都不是stream对象,可能是集合,字符串,int,boolean等
-----注意:在对stream对象操作的时候,数据源中的元素是不会发生改变的。
1.数据源的获取
public static void main(String[] args) {
List<Integer> nums = new ArrayList<Integer>();
nums.add(1);
nums.add(2);
nums.add(3);
nums.add(4);
nums.add(5);
/**
* 如果想要对这个集合进行流式编程,第一步必须获取数据源(关联数据源)
*/
//1.获取的流对象是串行的,不是并行的,好比只有一个人在工作
Stream<Integer> stream = nums.stream();
//2.获取的流对象是并行的,好比有多个人同时工作,效率更高
Stream<Integer> stream1 = nums.parallelStream();
}我们在main方法中创建了一个集合对象,并添加了元素,之后创建流对象,使用集合名.stream的方法即可,还有一种方式是集合名.parallelStream的方法,这两种方法的区别是 .stream() 获取的流对象是串行的,好比只有一个人工作,工作较慢; .parallelStream()获取的流对象是并行的,好比一个工厂有多人工作,工作效率高。
2.集合的流式编程的最终操作
最终操作指的是将流对象中的数据整合到一起。可以存入一个新的集合,也可以进行遍历,排序,统计等操作。
最终操作执行后,会自动关闭这个流,如果对已经关闭的流对象,继续操作,会报错
stream has already been operated upon or closed 该流已经被操作关闭了
最终操作的常用方法:
1.collect: 搜集方法可以将流中的数据搜集成一个新的集合,该方法的形参是一个Collector接口,可以用来指定搜集规则,但是通常不需要程序员自己制定规则,因为接口中提供的方法已经够用了
public static void main(String[] args) {
List<Integer> nums = new ArrayList<Integer>();
nums.add(1);
nums.add(2);
nums.add(3);
nums.add(4);
nums.add(5);
//获取数据源
Stream<Integer> stream = nums.stream();
// 搜集1:搜集成List集合
List<Integer> c1 = stream.collect(Collectors.toList());
System.out.println(c1);
System.out.println(c1==nums);在上述代码中,我们先创建了一个List集合,并添加元素,获取数据源通过.stream方法,在搜集操作中,将stream对象搜集成一个List集合;并打印;

得到的结果与数据源相等,但是地址不同,因为在搜集过程中创建了一个新的集合对象;所以会返回false。
还可以将流对象搜集为Set集合或Map集合;操作方法大体相同,调用方法时需要加以变通
Set<Integer> c2 = stream.collect(Collectors.toSet());
System.out.println(c2);![]()
Map<String, Integer> c3 = stream.collect(Collectors.toMap(e -> "Key" + e, e -> e));
System.out.println(c3);![]()
需要注意的时,Map集合中的元素是无序的(存入顺序和取出顺序无关),我们在调用toMap方法时,需要重写函数体,因为继承了函数式接口;我们可以直接把形参前面加上key作为键,值就直接赋给value就可以
2.reduce方法:将集合中的元素按照一定规则聚合起来;需要我们自己指定规则;
List<Integer> nums = new ArrayList<Integer>();
nums.add(1);
nums.add(2);
nums.add(3);
nums.add(4);
nums.add(5);
Stream<Integer> stream = nums.stream();
//计算数据源的元素之和 方法参数也是Lambda表达式:对应的抽象方法 R apply(T t,U u)
//返回的类型: Optional,需要调用他的get方法获取里面的数据
/**
* 从下面的案例可以得出结论,a变量接受的是数据源中的第一个元素,然后b变量接收的是剩下的元素
* a -=b
* a+=b
*/
// Optional<Integer> reduce = stream.reduce((a, b) -> a - b);//-13 前一个元素减后一个元素
Optional<Integer> reduce = stream.reduce((a,b)->a + b); //15 前一个元素加后一个元素
int sum = reduce.get();
System.out.println("计算结果"+sum);
}
}还是先创建一个集合对象nums,之后获取数据源,创建流对象,然后就可以通过流对象调用reduce( )方法,需要我们定义比较规则可以使用Lambda表达式,传入两个形参 a , b 如果函数体是a+b则表示前一个元素与后一个元素累计相加,如果是a-b则表示前一个元素与后一个元素累计相减;需要注意的是,该方法的返回值类型是Optional类型,需要调用get方法来获取里面的数据;

3.count方法: 用于统计数据源中元素的个数底层源码将每个元素映射成了1,然后求和,就相当于元素的个数;
long count = stream.count();
System.out.println("count: "+count);直接通过流对象调用即可,需要接收返回值,
![]()
4.forEach方法:对流中的数据进行遍历,无返回值,在遍历完毕后,流就关闭了
stream.forEach(num -> System.out.println(num));
stream.forEach(System.out::println);需要注意的是,上述的两种方法只能选择一种遍历,因为在遍历了第一次后,流就关闭了,第二次遍历就会报错;

5.max方法和min方法
/**
* max(Comparator c): 取排序的最后一位元素
*/
Optional<Integer> max = stream.max(((o1, o2) -> o1-o2));
System.out.println(max.get());在上述代码中,我们使用流对象来调用max方法,需要传入排序规则,max方法会取出排序的最后一个元素;min方法会取出排序的第一个元素,所以我们需要传入一个升序规则;
Optional<Integer> min = stream.min((o1, o2) -> o1 - o2);
System.out.println(min.get());![]()

6.match方法
第一种是allMatch方法,当数据源中所有的元素都满足条件时返回true;
boolean b = nums.stream().allMatch(e -> e < 10);
System.out.println(b);我们判断集合中的元素是否都满足小于10;如果都满足就会返回true;

第二种是anyMatch方法,当数据源中有元素满足条件就返回true;
boolean b1 = nums.stream().anyMatch(e -> e < 2);
System.out.println(b1);
第三种是noneMatch方法,当数据源中的数据都不满足条件时返回true
boolean b2 = nums.stream().noneMatch(e -> e < 0);
System.out.println(b2);
7.find方法
第一种是findFirst,第二种是findAny,这两种方法针对于串行的流,返回的结果是一样的,针对于并行的流,返回的结果可能不同;
List<Integer> nums = new ArrayList<Integer>();
nums.add(1);
nums.add(2);
nums.add(3);
nums.add(4);
nums.add(5);
Stream<Integer> stream = nums.stream();
//串行的流的演示
Integer e1 = nums.stream().findFirst().get();
System.out.println(e1);
Integer e2 = nums.stream().findAny().get();
System.out.println(e2);
//并行的流
Integer e3 = nums.parallelStream().findFirst().get();
System.out.println(e3);
Integer e4 = nums.parallelStream().findAny().get();
System.out.println(e4);
首先创建数据源的流对象;然后用对象调用findFirst方法;然后我们在创建并行的流对象来调用方法,发现两次返回的结果是不同的

3.流式编程的中间操作
1.过滤操作 filter( ) 过滤出来满足条件的数据
public static void main(String[] args) {
List<Integer> nums = new ArrayList<Integer>();
nums.add(1);
nums.add(2);
nums.add(3);
nums.add(4);
nums.add(5);
nums.add(2);
nums.add(4);
Stream<Integer> stream = nums.stream();
/**
* filter(...) 过滤出来满足条件的数据
* 比如想要所有奇数
*/
List<Integer> c1 = nums.stream().filter(x -> x % 2 != 0).collect(Collectors.toList());
System.out.println(c1);
首先我们创建一个集合并添加元素,之后创建一个流对象,然后用流对象来调用filter方法,括号里面需要使用匿名内部类对象或者Lambda表达式,来提供过滤的条件;之后进行搜集操作,将流对象中剩余的元素搜集成一个集合,并提供一个接收变量,之后对其打印,我们需要的是奇数,所以在filter的匿名内部类中设置一个符合的即可;

2.去重操作 distinct( )括号里面的Lambda表达式可以理解为一个没有名字的方法
/**
* distinct() 去重 Lambda表达式可以理解为一个没有名字的方法
*/
nums.stream().distinct().forEach(System.out::println);我们可以直接通过对象来调用此方法,不需要传入其他的Lambda表达式,因为已经提供好了;之后直接而对这个流对象进行forEach的粗暴遍历即可。

3.sorted( ) 排序 在流中升序排序,可以自己制定一个比较器接口,自定义排序规则;
List<Integer> nums = new ArrayList<Integer>();
nums.add(3);
nums.add(2);
nums.add(5);
nums.add(4);
nums.add(1);
/**
* sorted(): 在流中升序排序
* sorted(Comparator c): 在流中自定义规则排序
*/
nums.stream().sorted(((o1, o2) -> o2 - o1)).forEach(System.out::println);
System.out.println("==========================");首先我们自定义一个集合并创建数据源,流对象;然后用流对象来调用方法,在sorted的括号里面放入一个Lambda表达式,因为我们希望降序,所以用后一个减前一个,并对其使用粗暴方法遍历

4.截取操作 limit( ) 表示从流中截取前size个元素
/**
* limit(long size): 表示截取流中的前size个元素
*/
nums.stream().limit(2).sorted((a,b)->a-b).forEach(System.out::println);
System.out.println("==========================");我们使用流对象来调用该方法,方法的形参传入想要截取的长度,之后对其进行升序排序,然后粗暴方式遍历

5.跳过操作 skip()表示跳过流中的前size个元素
/**
* skip(long size): 表示跳过前size个元素
*
*/
nums.stream().filter(e-> e!=2).sorted().skip(2).forEach(System.out::println);我们先用流对象调用过滤方法得到不等于2的数据,之后对其升序排序,然后跳过前两个数据,然后遍历

6.map 映射操作:将流对象中的数据映射成一个其它形式的类型
List<Integer> nums = new ArrayList<Integer>();
nums.add(3);
nums.add(2);
nums.add(5);
nums.add(4);
nums.add(1);
/**
* map(......): 将元素映射成另外一种类型
*
* 比如:将上述的元素映射成字符串类型
*/
List<String> c1 = nums.stream().map(e -> "" + e).collect(Collectors.toList());
System.out.println(c1);
在上述代码中,调用map方法将流对象中的数据映射成了字符串类型,之后搜集成一个新的集合,虽然新集合和数据源的元素数字都相同但是类型已经改变了;
![]()
/**
* mapToInt(......): 将元素映射成intStream
* mapToLong
* mapToDouble
*/
int sum = nums.stream().mapToInt(e -> 1).sum();
System.out.println(sum);我们还可以调用mapToInt方法,将流对象中的数据直接映射成int类型,并把每个数据都变为1,之后进行求和操作,这个也就是统计集合中元素个数的方法;

4.综合案例
需求 : 一个集合中存储了了若干个Student对象 , 要求查询出以下结果 :
1. 所有及格的学生信息
2. 所有及格的学生姓名
3. 所有学生的平均成绩
4. 班级的前3名(按照成绩)
5. 班级的3-10名(按照成绩)
6. 所有不不及格的学生平均成绩
7. 将及格的学生 , 按照成绩降序输出所有信息
8. 班级学生的总分
public class Student {
private String name;
private int scores;
public Student(String name, int scores) {
this.name = name;
this.scores = scores;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getScores() {
return scores;
}
public void setScores(int scores) {
this.scores = scores;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", scores=" + scores +
'}';
}首先我们创建了一个Student类并提供了两个成员变量,之后提供了构造器和setter,getter方法,并重写了toString方法。
public static void main(String[] args) {
Student s1 = new Student("张三",80);
Student s2 = new Student("李四",90);
Student s3 = new Student("王五",100);
Student s4 = new Student("赵六",88);
Student s5 = new Student("孙七",90);
Student s6 = new Student("周八",78);
Student s7 = new Student("吴九",54);
Student s8 = new Student("郑十",70);
Student s9 = new Student("陈十一",99);
Student s10 = new Student("林十二",96);
Student s11 = new Student("韩十三",32);
Student s12 = new Student("杨十四",89);
Student s13 = new Student("黄十五",58);
Student s14 = new Student("魏十六",68);
List<Student> list = new ArrayList<>();
list.add(s1);
list.add(s2);
list.add(s3);
list.add(s4);
list.add(s5);
list.add(s6);
list.add(s7);
list.add(s8);
list.add(s9);
list.add(s10);
list.add(s11);
list.add(s12);
list.add(s13);
list.add(s14);
list.forEach(System.out::println)首先我们需要创建集合对象并且传入集合中,然后简单遍历一下

之后我们就可以完成案例的需求了
1.获取及格学生的信息:
//1.获得及格学生的信息
System.out.println("=============及格的学生信息=============");
list.stream().filter(student -> student.getScores() >= 60).collect(Collectors.toList()).forEach(System.out::println);首先我们创建了流对象并调用过滤操作filter()方法,在括号中传入条件形参是student,调用student的getScores获得分数,并过滤出我们需要的及格分数,然后就搜集成一个集合并粗暴遍历了

2.获得及格的学生姓名:
//2.获得及格的学生姓名
System.out.println("=============及格的学生姓名=============");
list.stream().filter(student -> student.getScores() >= 60).map(Student::getName).forEach(System.out::println);和第一步的方法类似,在过滤出需要的数据后,调用map方法将数据映射成名字,传入Student::getName,然后使用粗暴遍历;

3.获取学生的平均成绩
//3.获得所有学生的平均成绩
System.out.println("=============所有学生的平均成绩=============");
list.stream().mapToInt(Student::getScores).average().ifPresent(System.out::println);我们先获取到学生的分数数据,然后在调用average方法来得到平均数,之后如果有平均值(流对象不为空),就将其打印到控制台;

4.获取到班级的前三名
System.out.println("=============班级的前三名=============");
list.stream().sorted((sc1,sc2) -> sc2.getScores()-sc1.getScores()).limit(3).forEach(System.out::println);我们先调用排序方法获得降序排序的流对象,然后调用截取操作 limit(),传入长度3,并粗暴遍历即可;

5.获得班级的3-10名
//5.班级的3-10名
System.out.println("=============班级的3-10名=============");
list.stream().sorted((sc1,sc2) -> sc2.getScores()-sc1.getScores()).skip(2).limit(8).forEach(System.out::println);
还是根据降序排序,这次我们可以跳过前两个数据,然后截取8个长度就是3-10名了

6.获取所有不及格学生的平均成绩
//6.所有不及格学生的平均成绩
System.out.println("=============不及格学生的平均成绩=============");
list.stream().filter(stu -> stu.getScores() < 60 ).mapToInt(Student::getScores).average().ifPresent(System.out::println);
我们先想办法获取到不及格学生的数据,可以通过过滤操作得到不及格的学生,再通过map将数据映射成其分数,然后对分数求平均值在打印就可以了

7.将及格的学生按照成绩降序打印
//7.将及格的学生,按照成绩降序
System.out.println("=============及格的学生,按照成绩降序排列=============");
list.stream().filter(student -> student.getScores() >= 60).sorted((stu1,stu2) -> stu2.getScores()-stu1.getScores()).forEach(System.out::println);我们可以先过滤出需要的及格学生,并按照成绩进行降序排序,然后对其遍历即可

8.求出班级的总分
//8.班级学生的总分
System.out.println("=============班级的总分=============");
int sumScores = list.stream().mapToInt(Student::getScores).sum();
System.out.println(sumScores);我们直接将数据映射成其分数,然后再调用求和操作,并声明一个变量来接收,之后打印接收变量即可