作者:阳明。Kubernetes 布道师,公众号 K8s 技术圈主理人
最近我们新开发了一个项目 fastclass.cn,这个项目是一个独立开发者的学习网站,我们的目标是帮助你使用 Figma、Python、Golang、React、VUE、Flutter、ChatGPT 等设计构建真实的应用程序,助你成为一个全栈开发者,算是在 youdianzhishi.com 的基础上的一个延伸。
由于该项目还处于早期阶段,所以我们需要尽可能地提高效率,减少重复劳动,这样才能更快地推出新的课程。该项目使用的技术栈如下:
- 前端:React、Next.js、Tailwind CSS
- 后端:Python、Django、MySQL、Celery、Redis
因为之前的项目是直接用 Docker 方式部署到阿里云的服务器上面的,为了节约成本,自然我们还是使用 Docker 容器的方式部署这个项目,但是由于该项目涉及到更多的服务,比如 Next.js、Celery 这些都比较消耗资源,导致我们的服务器性能不够,所以需要另外一种低成本的方式来部署,最好还能应对不断增长的流量。
Sealos 简介
在这种情况下,我就想到了 Kubernetes,因为 Kubernetes 可以很好地解决这个问题,但是如果我自己搭建 Kubernetes 集群的话,成本又会比较高,使用云服务商的 Kubernetes 服务,比如阿里云的 ACK、腾讯云的 TKE 等,成本也不会太低。这个时候想到了 Sealos 的云服务,其官网介绍:Sealos 是一个无需云计算专业知识,就能在几秒钟内部署、管理和扩展应用的云操作系统。就像使用个人电脑一样!
当然最终选择直接使用 Sealos 云服务主要还是因为其高效、经济:仅需为容器付费,自动伸缩杜绝资源浪费,大幅度节省成本。

这确实是非常符合我们的需求的,我完全不需要一个完整的 Kubernetes 集群,说白了就是我只需要跑几个 Pod 就行,不需要去维护整个集群,这样就能大大减少成本(经济成本、运维成本等),而且 Sealos 云服务还提供了很多功能,比如自动伸缩、监控、日志等,这些都是我需要的,有这样的服务,我就可以专注于开发,而不用去管运维了,何乐而不为呢?
Sealos 是一个基于 Kubernetes 的云服务,所以要使用 Sealos 云服务,建议你最好了解一下 Kubernetes 的基本概念,比如 Pod、Service、Deployment、Ingress 等,这样会更容易上手,当然不了解也不影响你使用,因为 Sealos 云服务提供了很好的界面,你可以很容易地完成部署、管理、扩展等操作。
容器化
当然首先需要将我们的服务容器化,打包成 Docker 镜像,我们的后端服务代码结构如下所示:

容器化说白了就是将我们的服务打包成 Docker 镜像,我们的后端服务是一个 Django 项目,对应的 Dockerfile 内容如下所示:
FROM python:3.11.4-slim-buster
LABEL author=icnych@gmail.com
# set environment variables
ENV PYTHONDONTWRITEBYTECODE 1
ENV PYTHONUNBUFFERED 1
ENV DEBUG False
WORKDIR /app
RUN sed -i 's/deb.debian.org/mirrors.ustc.edu.cn/g' /etc/apt/sources.list && \
apt-get update && \
apt-get install -y pkg-config python3-dev default-libmysqlclient-dev build-essential
RUN pip install --upgrade pip --index-url https://mirrors.sustech.edu.cn/pypi/simple && \
pip config set global.index-url https://mirrors.sustech.edu.cn/pypi/simple
COPY . .
RUN pip install -r requirements.txt
RUN apt-get clean autoclean && \
apt-get autoremove --yes && \
rm -rf /var/lib/{apt,dpkg,cache,log}/ \
EXPOSE 8000
CMD ["gunicorn", "--bind", ":8000", "--workers", "4", "--access-logfile", "-", "--error-logfile", "-", "fastclass.wsgi:application"]这个 Dockerfile 文件很简单,就是基于 python:3.11.4-slim-buster 镜像构建,然后安装一些依赖,最后运行 gunicorn 启动 Django 项目。
另外需要注意我们这里使用了 Celery 来处理异步任务,使用的 Redis 做为 Broker,所以需要在 Django 的配置文件中配置 Celery,内容如下所示:
# ==========Celery===========
REDIS_URL = os.getenv("REDIS_URL", "localhost:6379")
REDIS_USER = os.getenv("REDIS_USER", "default")
REDIS_PASSWORD = os.getenv("REDIS_PASSWORD", "default")
REDIS_BROKER_DB = 1
REDIS_RESULT_DB = 2
CELERY_BROKER_URL = (
f"redis://{REDIS_USER}:{REDIS_PASSWORD}@{REDIS_URL}/{REDIS_BROKER_DB}"
)
#: Only add pickle to this list if your broker is secured
#: from unwanted access (see userguide/security.html)
CELERY_ACCEPT_CONTENT = ["json"]
CELERY_RESULT_BACKEND = (
f"redis://{REDIS_USER}:{REDIS_PASSWORD}@{REDIS_URL}/{REDIS_RESULT_DB}"
)
CELERY_TASK_SERIALIZER = "json"
CELERY_TIMEZONE = "Asia/Shanghai"
CELERY_ENABLE_UTC = True这里我们使用了环境变量来配置 Redis 的连接信息,这样就可以在容器启动的时候通过环境变量来配置。当然还有数据库的连接信息也是通过环境变量配置的,这样就可以很方便地在不同环境中配置不同的连接信息。
DATABASES = {
"default": {
"ENGINE": "django.db.backends.mysql",
"NAME": os.getenv("DB_NAME", "fastclass"),
"USER": os.getenv("DB_USER", "root"),
"PASSWORD": os.getenv("DB_PASSWORD", "root"),
"HOST": os.getenv("DB_HOST", "localhost"),
"PORT": os.getenv("DB_PORT", 3306),
"OPTIONS": {"charset": "utf8mb4"},
}
}接下来就是前端的 Next.js 项目,对应的项目结构如下所示:
同样需要将我们的 Next.js 项目容器化,对应的 Dockerfile 内容如下所示:
FROM node:18.19.0-alpine3.18 AS base
# Check https://github.com/nodejs/docker-node/tree/b4117f9333da4138b03a546ec926ef50a31506c3#nodealpine to understand why libc6-compat might be needed.
RUN apk add --no-cache libc6-compat
# 2. Rebuild the source code only when needed
FROM base AS builder
WORKDIR /app
COPY . .
# 切换镜像源
RUN npm config set registry https://repo.nju.edu.cn/repository/npm/ && npm install sharp && npm install --production && npm run build
FROM base AS runner
WORKDIR /app/web
ENV NODE_ENV production
# Uncomment the following line in case you want to disable telemetry during runtime.
ENV NEXT_TELEMETRY_DISABLED 1
# copy need files(this can exclude code files)
COPY --from=builder /app/node_modules ./node_modules
COPY --from=builder /app/.next ./.next
COPY --from=builder /app/public ./public
COPY --from=builder /app/docker/pm2.json ./pm2.json
COPY --from=builder /app/docker/entrypoint.sh /entrypoint.sh
COPY --from=builder /app/next.config.js ./next.config.js
RUN npm install pm2 -g && chmod +x /entrypoint.sh
EXPOSE 3000
ENTRYPOINT ["/bin/sh", "/entrypoint.sh"]这里我们采用的是一个多阶段构建的方式,首先是基于 node:18.19.0-alpine3.18 镜像构建,然后安装依赖,最后使用 pm2 来启动 Next.js 项目。pm2 是一个 Node.js 进程管理工具,可以很方便地管理 Node.js 进程,比如启动、停止、重启等。这里我们通过 ENTRYPOINT 定义了一个脚本 entrypoint.sh,内容如下所示:
#!/bin/bash
set -e
#if [[ -z "$APP_URL" ]]; then
# export NEXT_PUBLIC_PUBLIC_API_PREFIX=${APP_API_URL}/api
#else
# export NEXT_PUBLIC_PUBLIC_API_PREFIX=${APP_URL}/api
#fi
#
#export NEXT_PUBLIC_SENTRY_DSN=${SENTRY_DSN}
/usr/local/bin/pm2 -v
/usr/local/bin/pm2-runtime --raw start /app/web/pm2.json这个脚本主要是启动 pm2,对应的 pm2.json 文件内容如下所示:
{
"apps": [
{
"name": "FastClass",
"exec_mode": "cluster",
"instances": 2,
"script": "./node_modules/next/dist/bin/next",
"cwd": "/app/web",
"args": "start"
}
]
}最后分别前后端服务构建成 Docker 镜像,然后推送到镜像仓库,这样我们的服务就容器化完成了。
部署
现在有了应用镜像,接下来只需要将这些镜像部署到 Sealos 云服务上面就行了。
首先当然需要注册一个账号,前往 cloud.sealos.run 注册即可,国内用户需要实名认证,初始会提供 5 元的试用金,可以用来体验一下,整个控制台界面如下所示:
然后我们可以根据自己的业务需求选择不同的可用区域,我们这里选择的是北京 A区域。

由于我们的后端应用依赖 MySQL 和 Redis 数据库,所以我们首先要创建这两个数据库,Sealos 也是提供了单独的数据库服务的(底层使用的是 kubeblocks),选择新建数据库,然后选择要创建的数据库类型,我们先选择 MySQL 数据库。
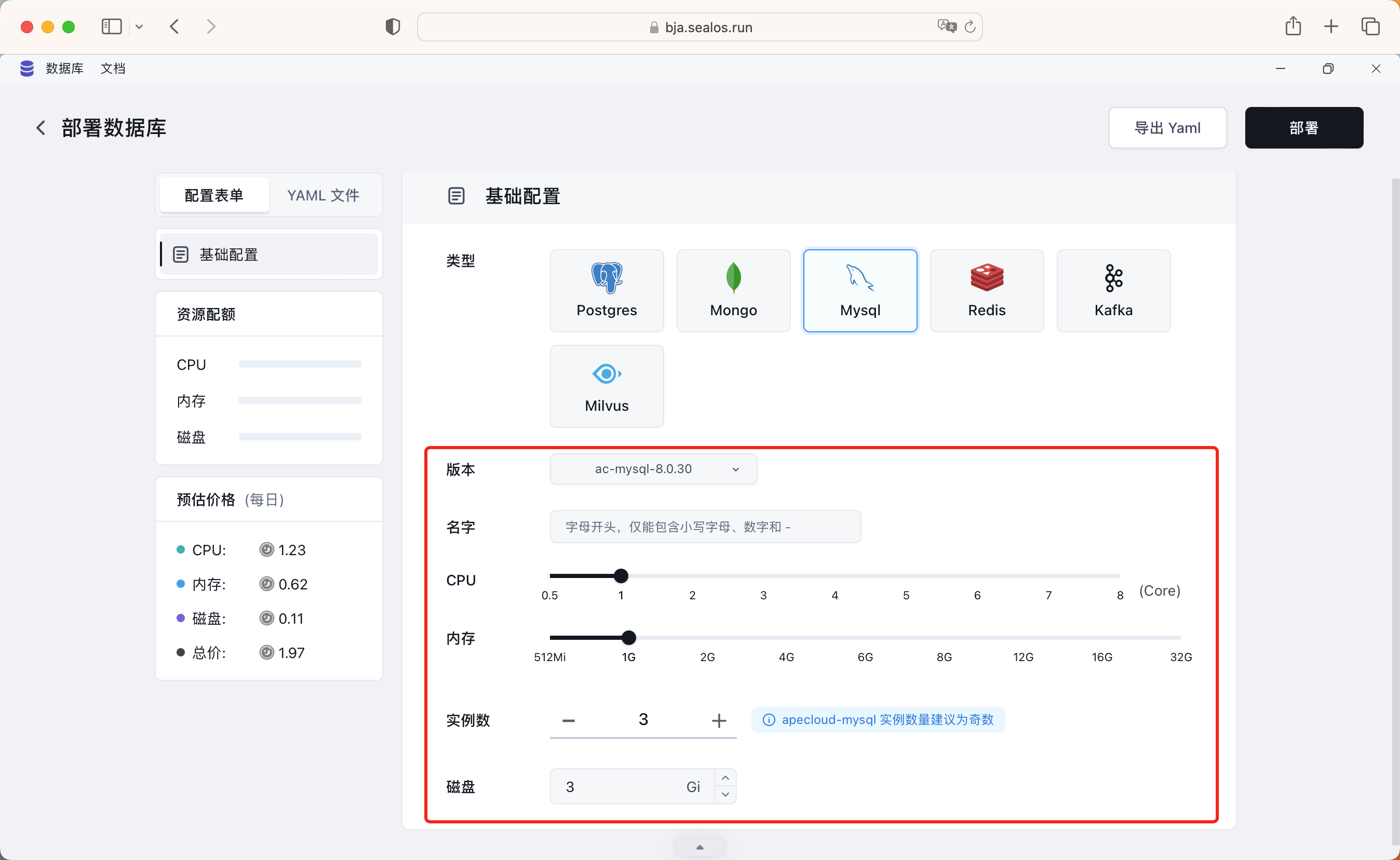
然后我们可以配置数据库的名称、CPU、内存资源,我们可以选择最低配置,如果后面发现资源不够,可以随时变更资源,这里我们配置的 CPU 和内存实际上就是 Pod 里面的 limit 资源,另外就是实例数建议最低配置为 3 个,这样可以保证数据库的高可用性,在左侧也有对应的资源预估价格显示。我们也可以切换查看对应的 YAML 资源清单文件:
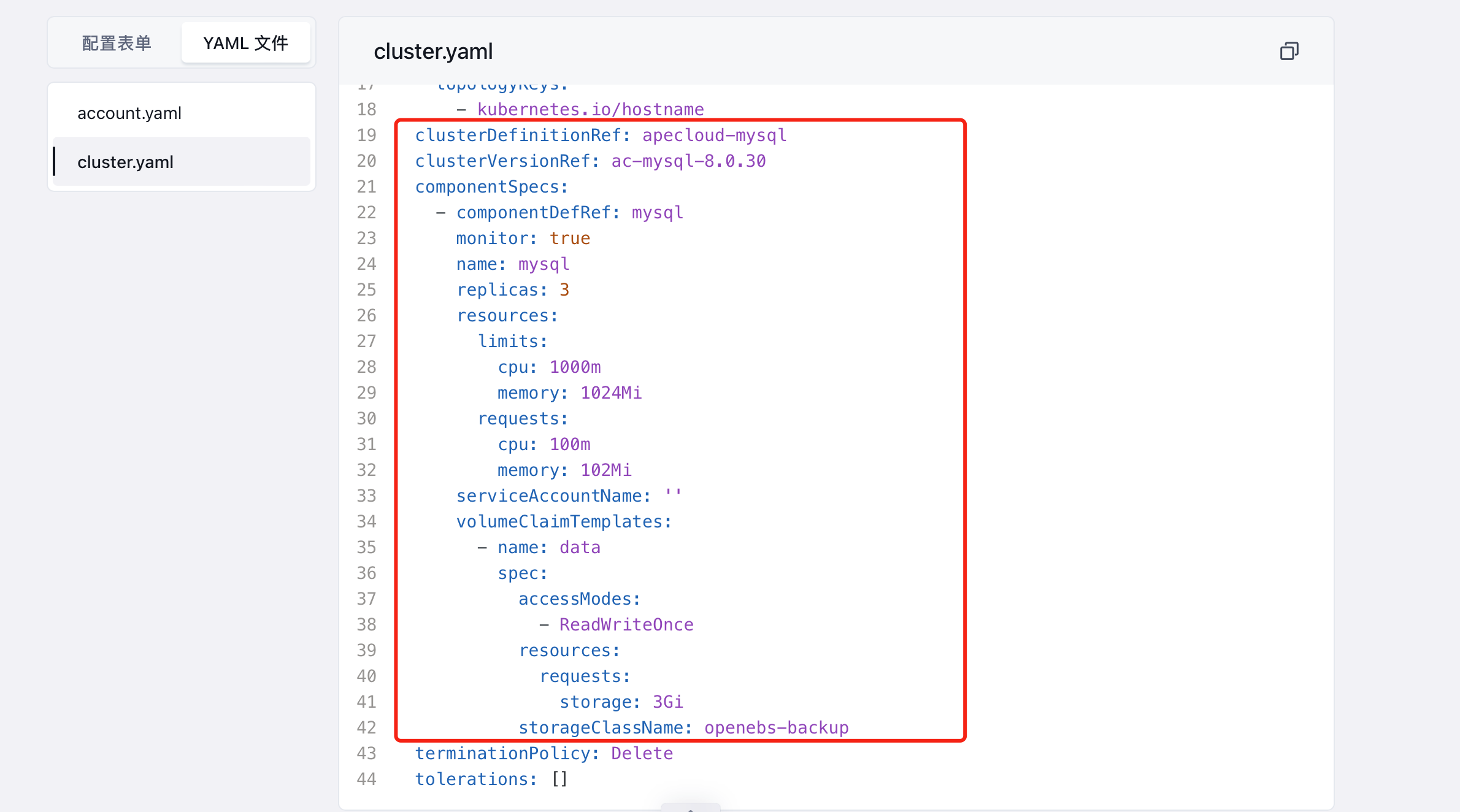
其实这就是 KubeBlocks 的一个 CR 实例。配置完成后点击右上角的"部署"按钮,等待部署完成即可。用同样的方式再部署一个 Redis 数据库即可。
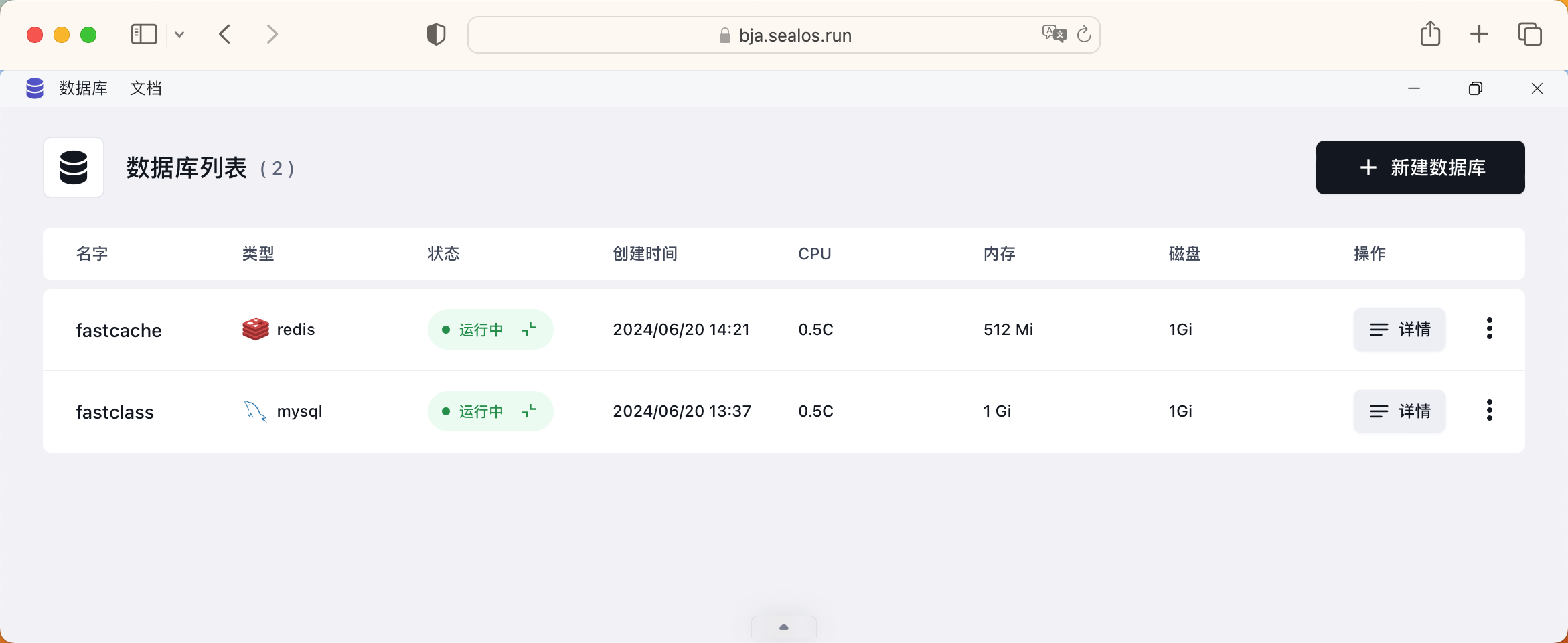
点击查看详情,在左侧可以看到数据库的连接信息,我们的后端服务需要用到这些信息。在右侧可以看到数据库的实时监控信息,我们可以根据这些信息来调整数据库的资源配置,此外还可以备份数据库,在线导入数据等。
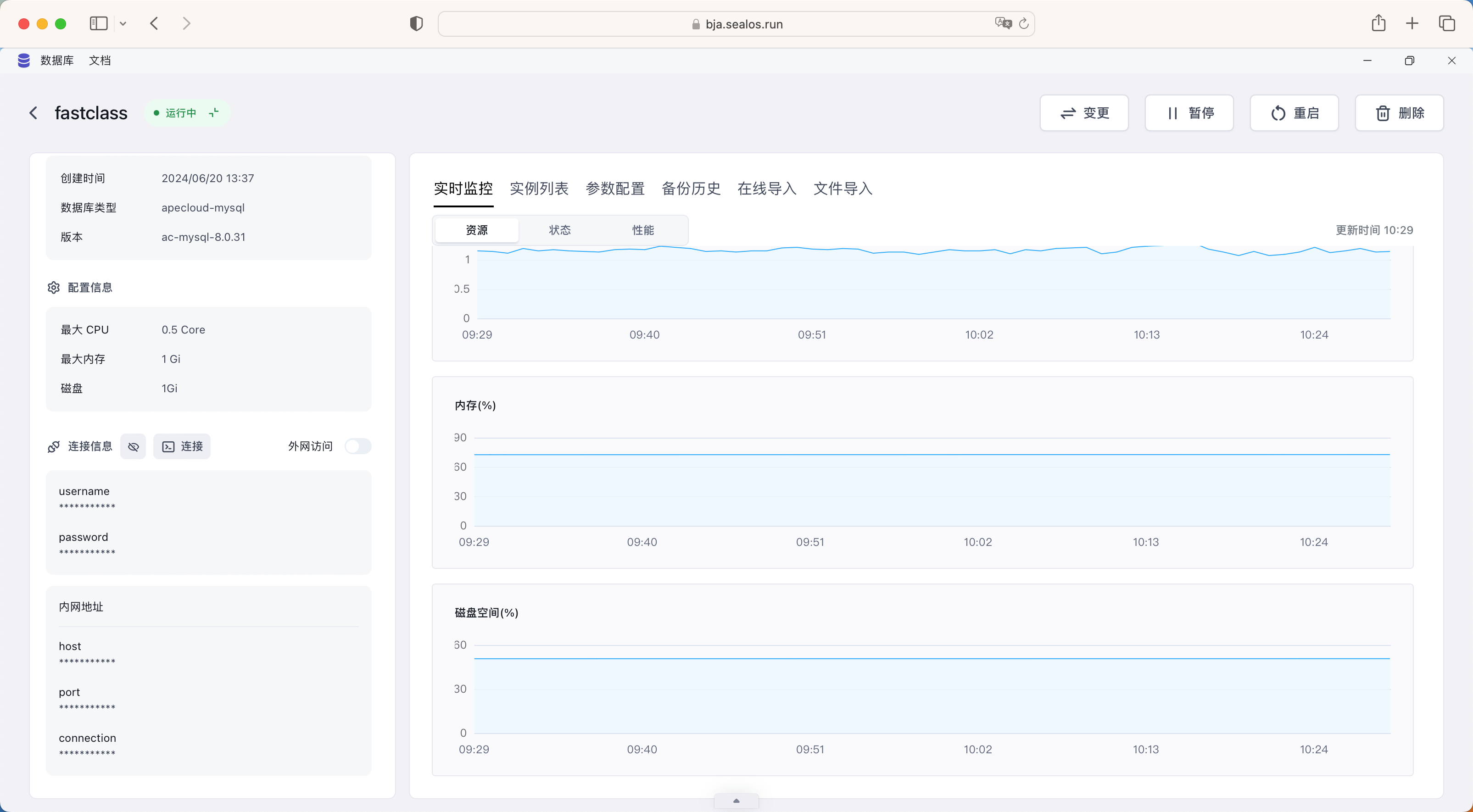
数据库准备好过后,接下来就可以部署我们的应用了,点击首页的"应用管理",开始新建应用。首先我们来部署后端服务,在表单中填上后端服务的镜像相关信息。然后部署模式有固定实例和弹性伸缩两种模式,弹性伸缩也就是我们熟悉的 HPA 模式,比如我们这里配置的是内存使用率超过 80% 时,自动扩容到 2 个 Pod,同样还可以配置 CPU、内存等资源。
如果想要对外暴露后端服务,可以在网络配置中开启公网访问,也就是创建一个 Ingress 资源,这样就可以通过公网访问我们的后端服务了,我们这里暂时不需要,所以不勾选。
另外还需要在高级配置里面配置环境变量,比如数据库连接信息、Redis 连接信息等,这样我们的后端服务就可以连接到数据库和 Redis 了。
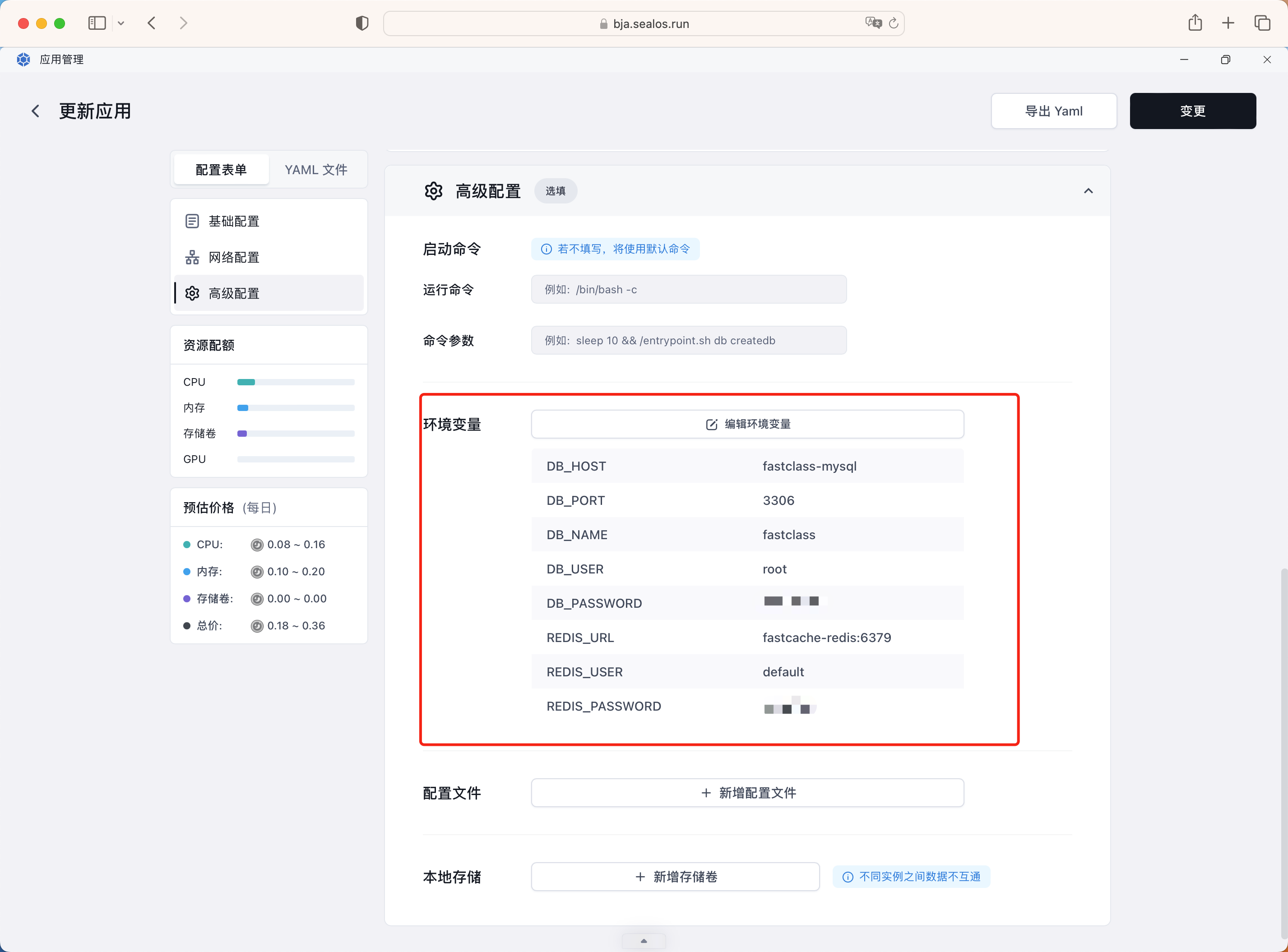
我们只需要简单的在页面上填写一些配置信息,其实就对应着 Kubernetes 里面的一些资源,比如 Deployment、Service、Ingress、HPA、Secret 等,Sealos 云服务会根据我们的配置信息生成对应的资源清单文件,然后部署到 Kubernetes 集群上面。
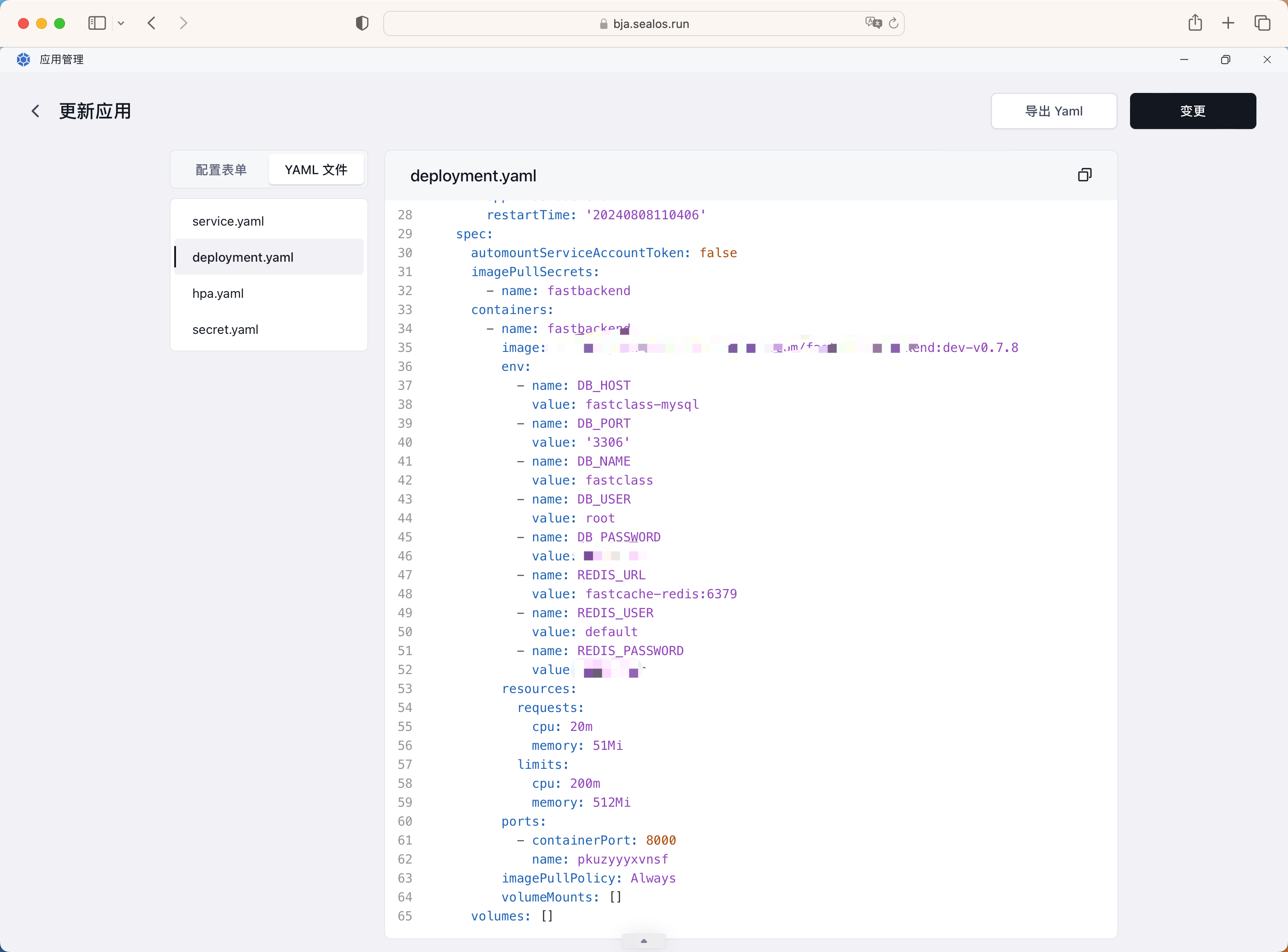
配置完成后点击右上角的"部署"按钮,等待部署完成即可,部署完成后我们可以在应用列表中看到我们的后端服务已经部署成功了。
用同样的方式部署前端服务,这里需要注意的是需要开启公网访问,因为我们的前端服务是需要对外暴露的,这样用户才能访问到我们的网站。
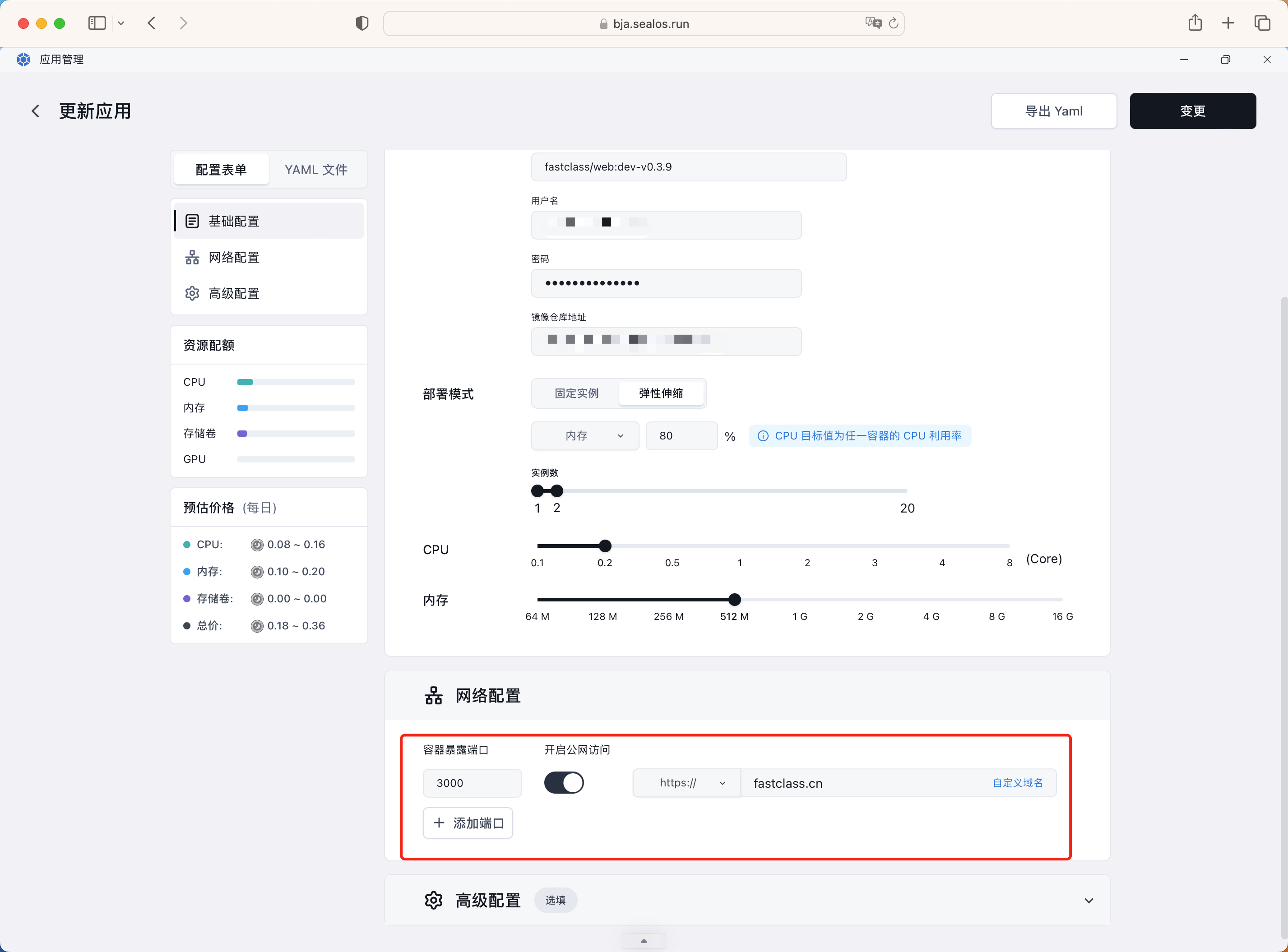
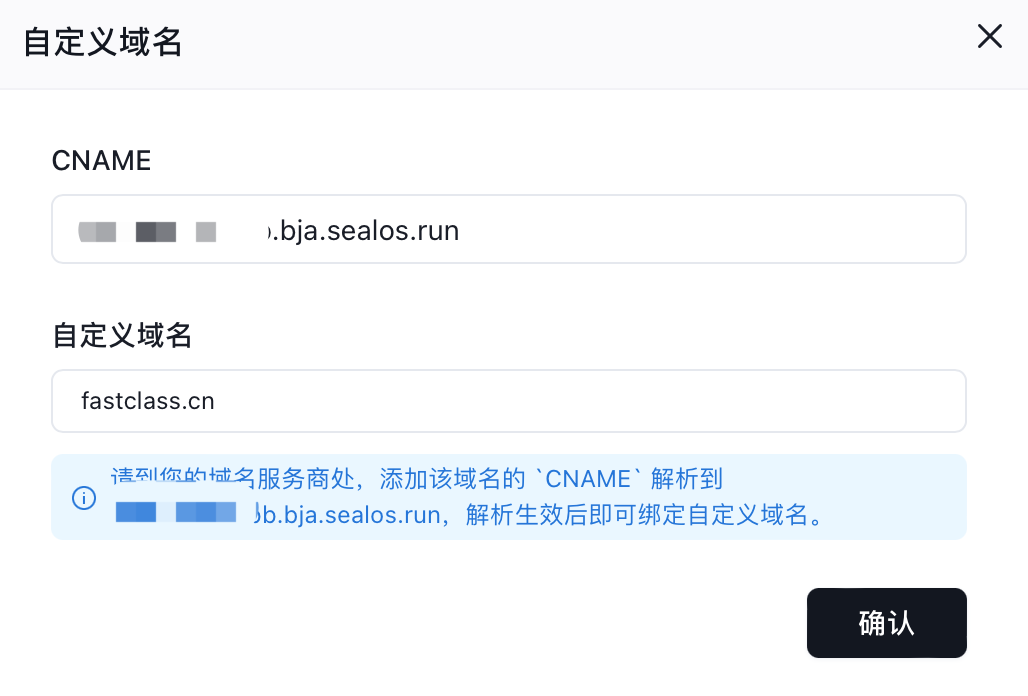
而且需要注意开启公网访问后,系统会自动为我们分配一个域名,我们肯定是希望使用自己的域名,所以需要自定义域名,需要在域名服务商处添加自定义域名的 CNAME 解析到这个自动生成的域名地址。
这样我们的前端服务就可以通过自定义域名访问了,但是这里还有一个问题,就是我们的前端 Next.js 服务还需要访问我们的后端服务,当我们访问 https://fastclass.cn 的时候会访问到前端服务,但是当访问 https://fastclass.cn/api/xxx 的时候需要访问到后端服务,这个时候就需要配置 Ingress 路由规则,将 /api 路由转发到后端服务,但是 Sealos 云服务的页面上目前还不支持配置 Ingress 路由规则,所以我们需要手动配置 Ingress 路由规则。
点击"终端"就可以进入到 Kubernetes 集群的终端界面,然后我们可以通过 kubectl 来管理 Kubernetes 集群,首先需要将 fastclass.cn 的 https 证书导入到 Kubernetes 集群中,用一个 Secret 对象来存储证书信息,然后我们修改下系统自动生成的 Ingress 对象,将 https 证书换成我们自己的证书。
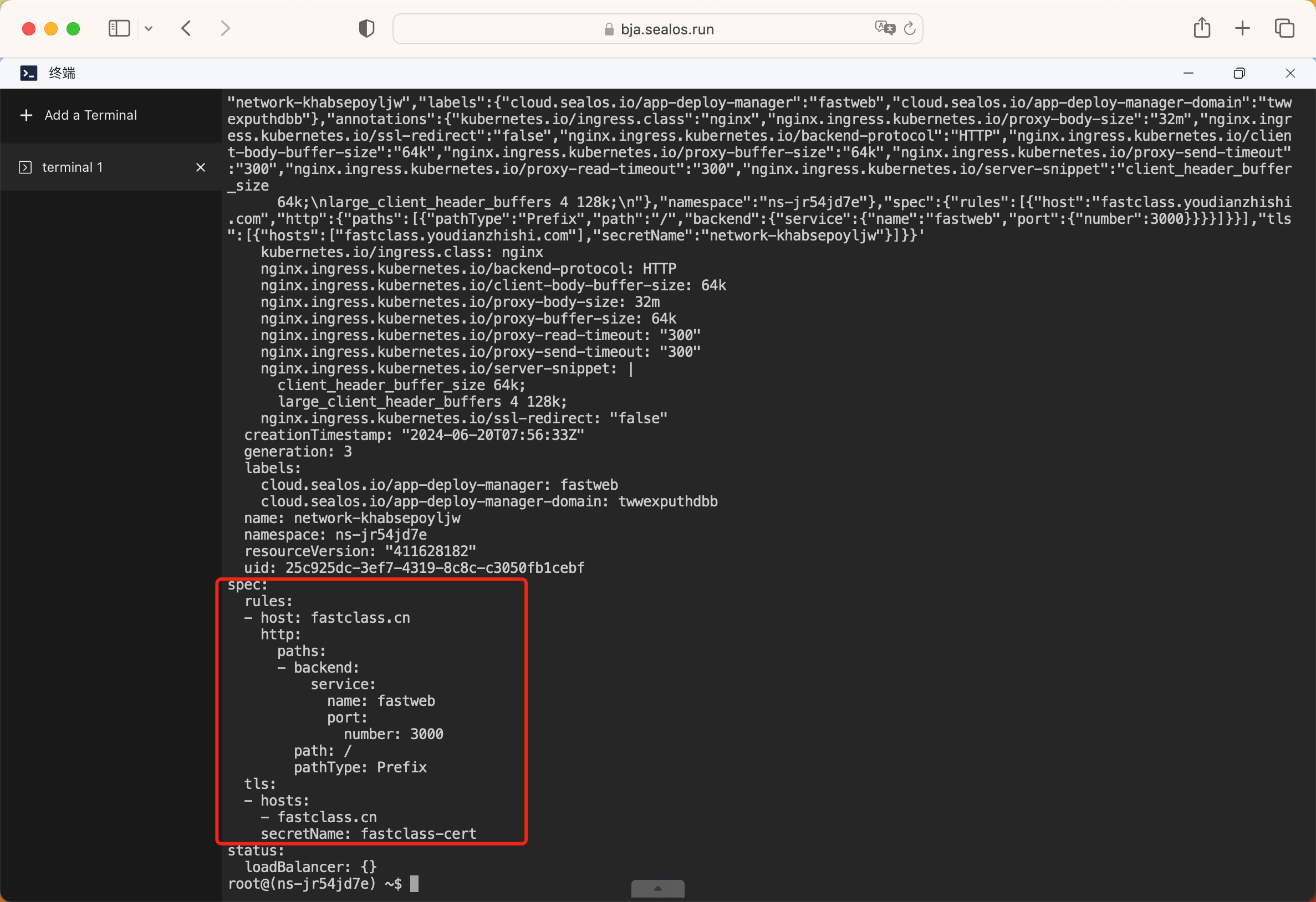
然后再创建一个新的 Ingress 对象,用来配置后端服务的路由规则,这样我们的前端服务就可以访问到后端服务了,如下所示:
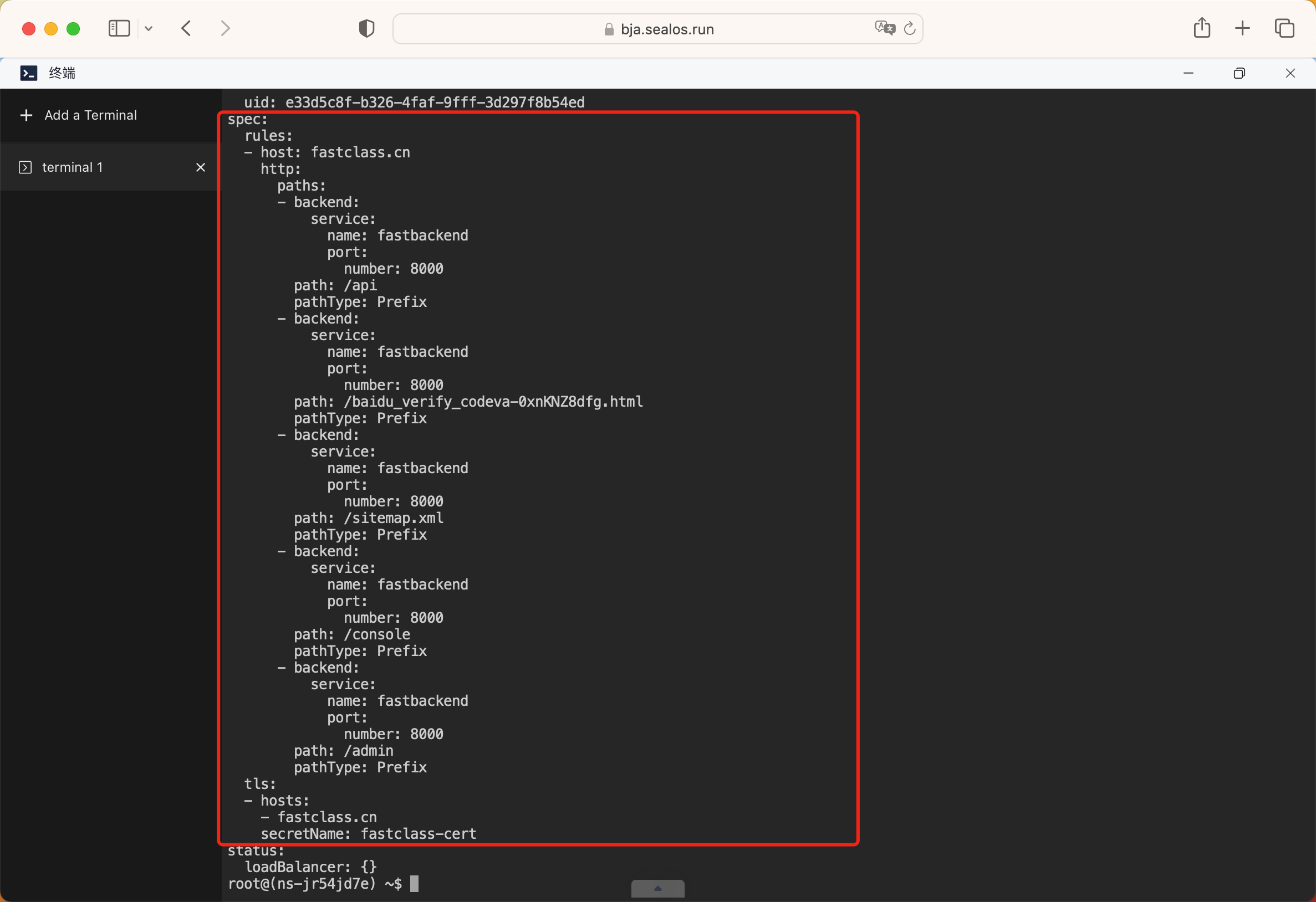
这样我们就可以正常访问我们的网站了。除此之外我们还需要部署下 Celery 服务,用来处理后端的异步任务的。和部署后端服务类似,也是使用相同的镜像和环境变量,不过需要注意的是这里我们不是启动 Web 服务,而是启动 Celery Worker 服务,所以需要修改启动命令。
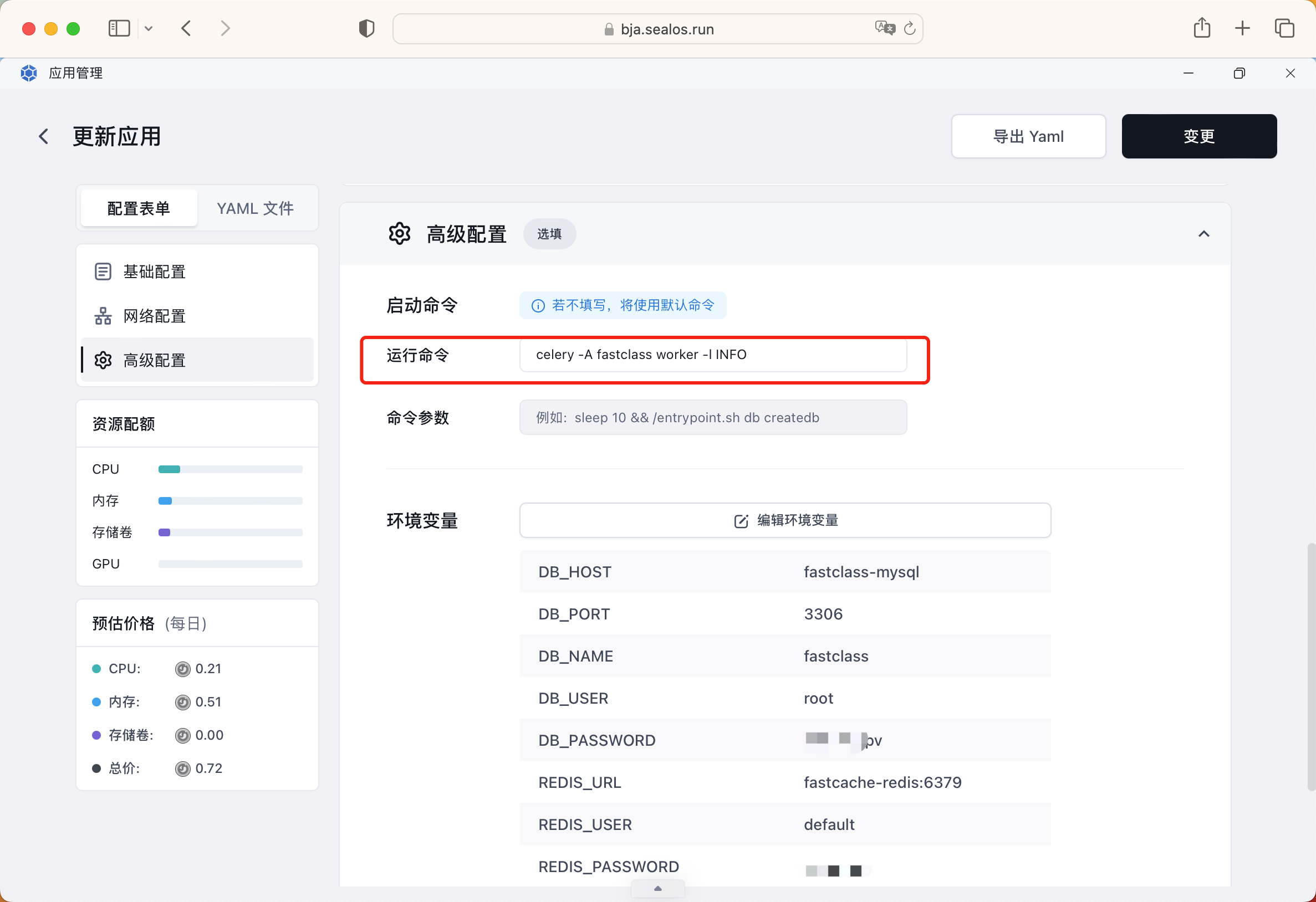
同样还有一个定时任务服务,用来定时执行一些任务,这里我们使用的是 Celery Beat 服务,同样需要使用相同的镜像和环境变量,不过需要修改启动命令,命令如下所示:
celery -A fastclass beat -l INFO --scheduler django_celery_beat.schedulers:DatabaseScheduler最终我们部署了 4 个服务,分别是前端服务、后端服务、Celery Worker 服务、Celery Beat 服务,这样我们的应用就部署完成了。
后续其他的功能服务,我们也可以采用微服务的方式来部署,非常方便。
在 KubePanel 里面也可以看到我们整个集群的资源使用情况,相当于一个 Kubernetes 集群 Dashboard。

如果控制台页面不支持的一些 Kubernetes 功能特性,我们还可以通过终端来自行操作,就相当于我们平时使用的 Kubernetes 集群一样。
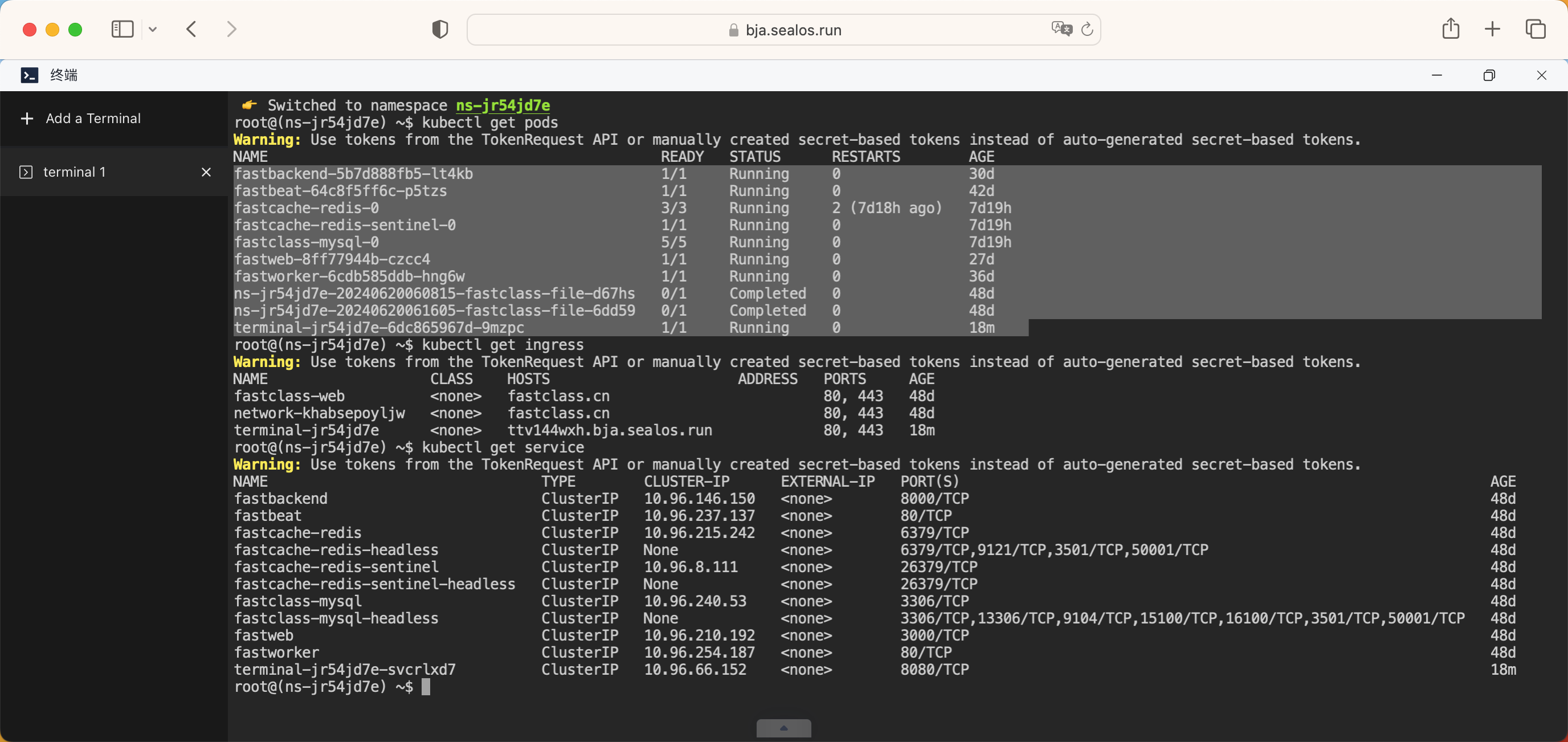
此外我们还可以将集群的 kubeconfig 文件导入到本地,这样我们就可以使用 kubectl 命令在本地来管理集群了。
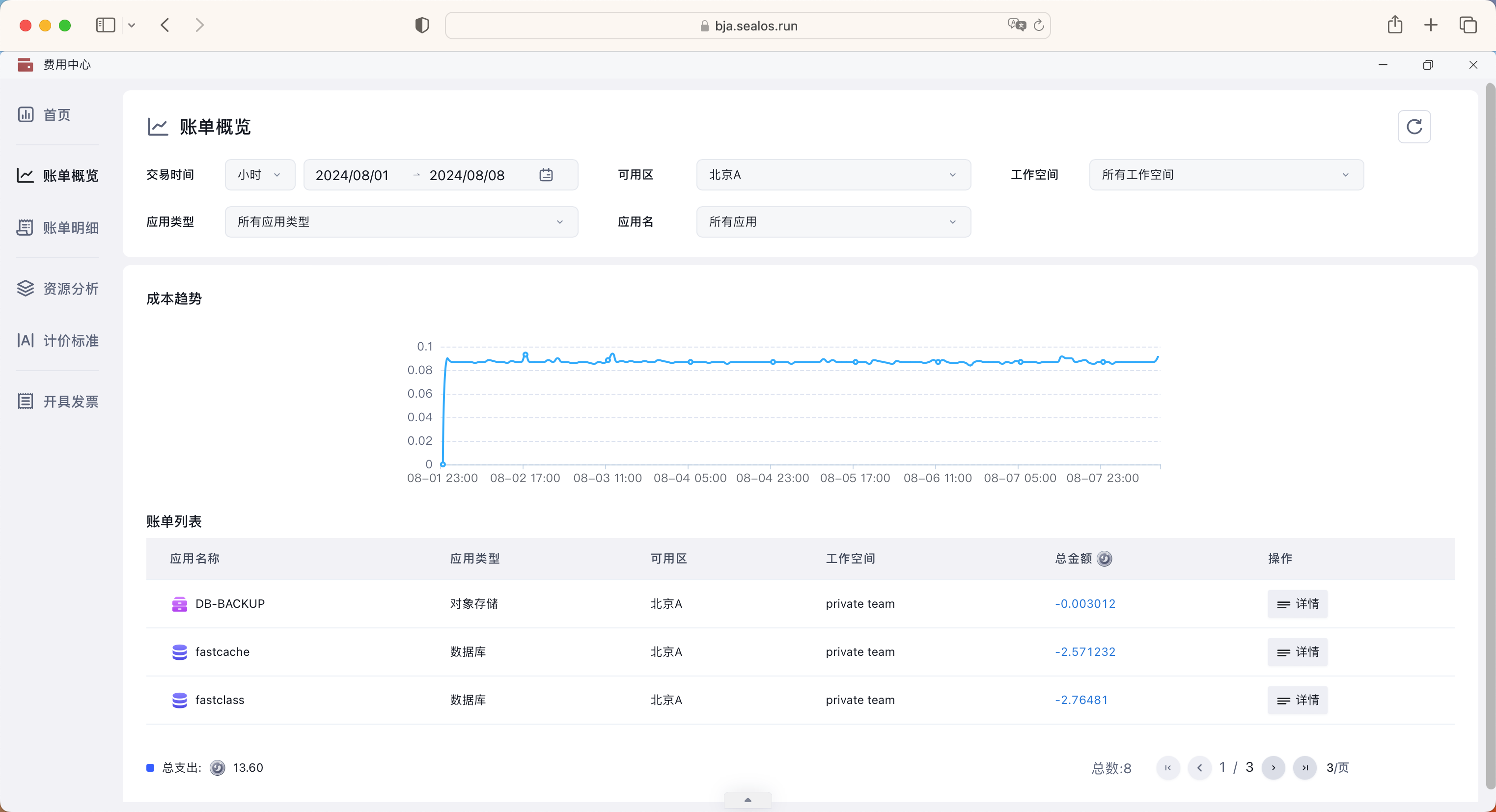
在费用中心也可以看到我们的消费详细账单信息。
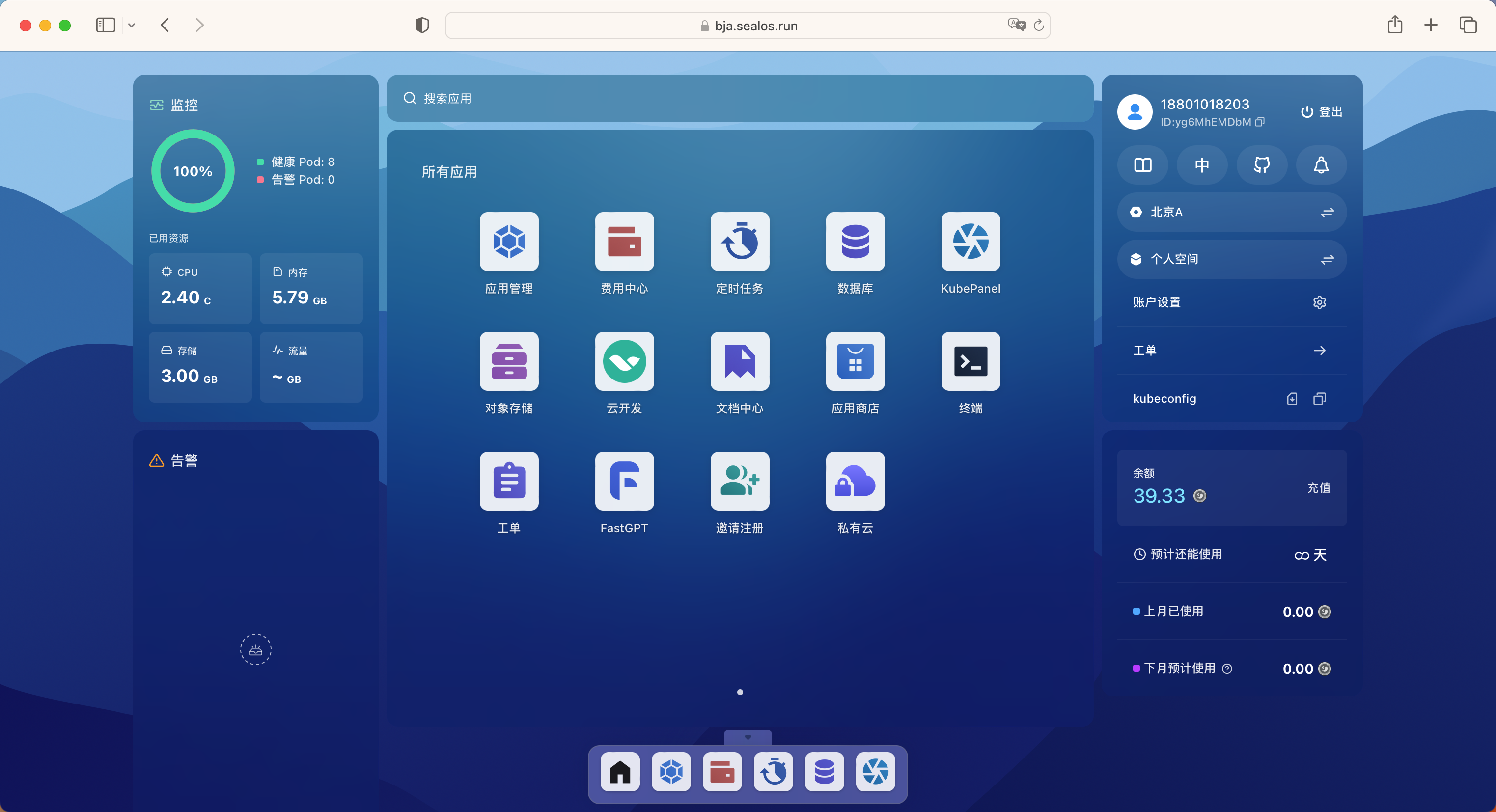
我们这里只是使用了 Sealos 的一部分功能,还有很多其他功能,比如对象存储、云开发等等能力,大家可以自行探索。
这不比买 ECS 服务器折腾来得简单方便吗?成本也降低不少,如果你是一个创业团队,需要小步快跑,快速验证产品,那么 Sealos 绝对是你应用托管的一个最佳选择。