首先登录网站,查看网页内容及数据格式(使用代码查看内容),选择两个城市及对应月份,爬取对应天气数据,进行数据预处理(如缺失值处理、数据类型转换、字符串截取等),数据的初步探索性分析(如描述性统计、数据可视化查看数据分布特征等),然后将处理后天气属性数据存储到数据库表和本地文件。存入成功后,使用代码读取数据检验是否正确。
网页分析
第一步:选择适合进行信息爬虫的网页。
(1)由于要获取的是历史天气信息,我们不考虑常见的天气预报网页,最后选择了“天气后报网”作为目标网站。
首先我们登陆天气后报网站:http://lishi.tianqi.com/,如下:

天气后报网站
然后定位到我们需要爬取的数据所存在的网页:http://www.tianqihoubao.com/lishi/beijing/month/202209.html。如下图,该网站天气信息按条分布,符合我们的爬虫需求。
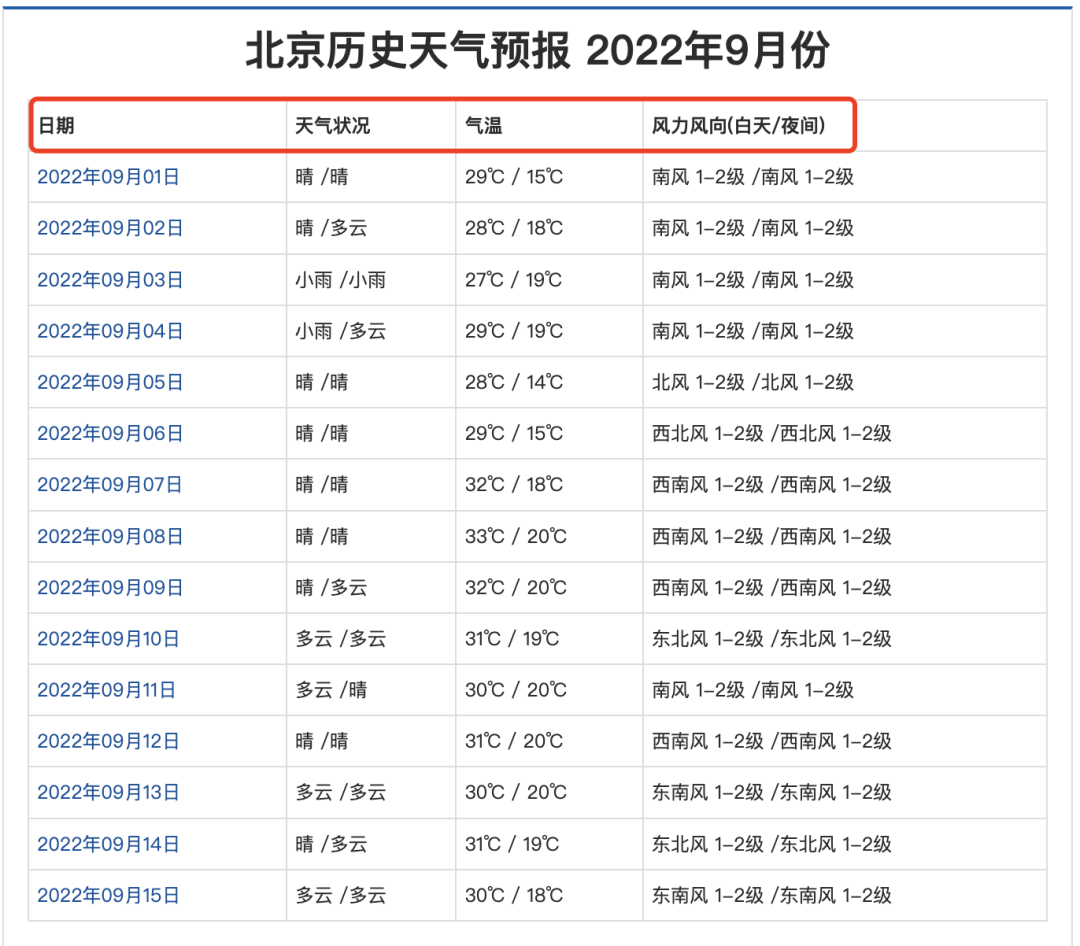
北京9月历史天气
(2)我们查看了该网站的robots协议,通过输入相关网址,我们没有找到robots.txt的相关文件,说明该网站允许任何形式的网页爬虫。
(3)我们查看了该类网页的源代码,如下图所示,发现其标签较为清晰,不存在信息存储混乱情况,便于爬取。

第二步:对该网页相关信息所在的url进行获取。
(1)对网页的目录要清晰的解析

网页结构
为了爬取到北京、天津两地各个月份每一天的所有天气信息,我们小组首先先对网页的层次进行解析,发现网站大体可以分为三层。

-
第一层是地名的链接,通向各个地名的月份链接页面
-
第二层是月份链接,对应各个网页具体天数
-
第三个层次则是具体每一天的天气信息

与是我们本着分而治之的原则,对应不同网页的不同层次依次解析对应的网页以获取我们想要的信息。
第三步:通过解析url对应的网页获取信息并存储。
(1)设置请求登录网页功能,根据不同的url按址访问网页,若请求不成功,抛出HTTPError异常。
(2)设置获取数据功能,按照网页源代码中的标签,设置遍历规则,获取每条数据。注意设置encoding='gb18030',改变标准输出的默认编码, 防止控制台打印乱码。
(3)设置文件存储功能,将爬取的数据按年份和月份分类,分别存储在不同的CSV文件中。注意文件名的设置为城市名加日期,方便后期整理。
爬取数据
登录天气后报网站:http://lishi.tianqi.com/,查看网页内容及数据格式(使用代码或开发者模式查看内容)选择两个城市(如北京和天津),分别选取连续6个月的数据(注意观察网址URL的变化规律),爬取网页中的天气数据(包括城市名、日期、天气状况、气温、风力和风向),保存到DataFrame对象中,控制台输出显示上述DataFrame对象的头5行和后5行。
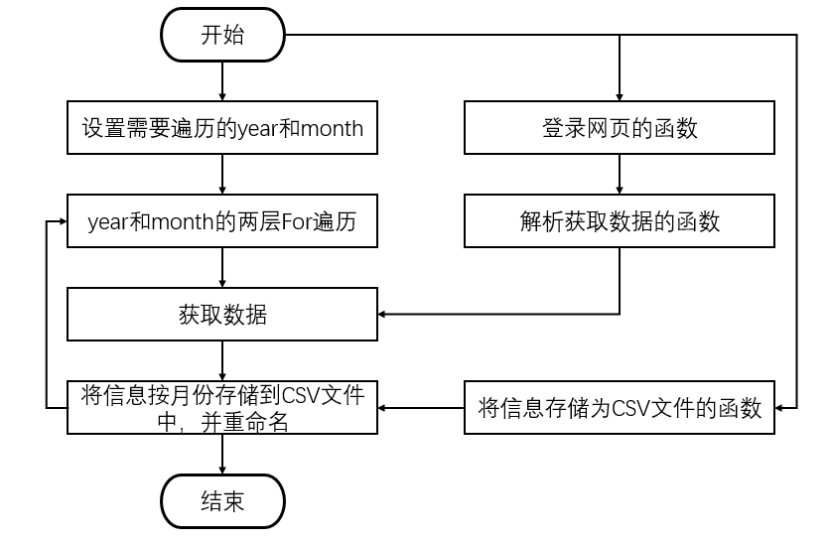
代码流程图
导入相关库
import numpy as np
import pandas as pd
import requests
import seaborn as sns
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
网页爬取代码
def downloadtq(url):
#获取网页源代码
resp = requests.get(url)
html = resp.content.decode('gbk')
#数据提取
soup = BeautifulSoup(html,'html.parser')
tr_list = soup.find_all('tr')
dates,conditions,temp ,fengxiang= [],[],[],[]
for data in tr_list[1:]:## 解析数据
sub_data = data.text.split()
dates.append(sub_data[0])
conditions.append(''.join(sub_data[1:3]))
temp.append(''.join(sub_data[3:6]))
fengxiang.append(''.join(sub_data[6:8]))
_data = pd.DataFrame()
_data['日期'] = dates
_data['天气情况'] = conditions
_data['气温'] = temp
_data['风力'] = fengxiang
return _data
url = 'http://www.tianqihoubao.com/lishi/beijing/month/202107.html'
d1=pd.DataFrame({},columns=['日期','天气情况','气温','风力'])
for y in [2021]:## 遍历循环1-6月的信息
for m in ['01','02','03','04','05','06']:
url = f'http://www.tianqihoubao.com/lishi/beijing/month/{y}{m}.html'
tmp=downloadtq(url)
d1=pd.concat([d1,tmp])
# d.to_csv('BJ.csv',index=0,encoding='gbk')
北京天气数据
|
| 日期 | 天气情况 | 气温 | 风力 |
| — | — | — | — | — |
| 0 | 2021年1月1日 | 晴/晴 | 0℃/-11℃ | 南风1-2级 |
| 1 | 2021年1月2日 | 晴/多云 | 1℃/-9℃ | 西南风1-2级 |
| 2 | 2021年1月3日 | 多云/多云 | -1℃/-9℃ | 南风1-2级 |
| 3 | 2021年1月4日 | 多云/晴 | -1℃/-11℃ | 西北风1-2级 |
| 4 | 2021年1月5日 | 晴/晴 | -2℃/-11℃ | 西南风1-2级 |
| 27 | 2021年6月26日 | 雷阵雨/多云 | 31℃/23℃ | 东南风1-2级 |
| 28 | 2021年6月27日 | 多云/晴 | 34℃/23℃ | 东风1-2级 |
| 29 | 2021年6月28日 | 雷阵雨/雷阵雨 | 35℃/22℃ | 南风1-2级 |
| 30 | 2021年6月29日 | 雷阵雨/雷阵雨 | 29℃/22℃ | 东北风1-2级 |
| 31 | 2021年6月30日 | 雷阵雨/阴 | 32℃/23℃ | 东南风1-2级 |
天津天气数据
|
| 日期 | 天气情况 | 气温 | 风力 |
| — | — | — | — | — |
| 0 | 2021年1月1日 | 晴/晴 | 0℃/-8℃ | 东北风1-2级 |
| 1 | 2021年1月2日 | 晴/多云 | 2℃/-6℃ | 北风1-2级 |
| 2 | 2021年1月3日 | 多云/多云 | 0℃/-5℃ | 东北风1-2级 |
| 3 | 2021年1月4日 | 多云/晴 | 1℃/-8℃ | 北风1-2级 |
| 4 | 2021年1月5日 | 晴/多云 | -2℃/-9℃ | 西南风3-4级 |
| 27 | 2021年6月26日 | 雷阵雨/雷阵雨 | 34℃/22℃ | 南风1-2级 |
| 28 | 2021年6月27日 | 多云/多云 | 31℃/22℃ | 东北风1-2级 |
| 29 | 2021年6月28日 | 阴/雷阵雨 | 32℃/23℃ | 东南风1-2级 |
| 30 | 2021年6月29日 | 雷阵雨/雷阵雨 | 30℃/22℃ | 东南风1-2级 |
| 31 | 2021年6月30日 | 阴/阴 | 31℃/22℃ | 东南风3-4级 |
数据预处理
将北京和天津的不同月份天气数据,连接合并,保存到统一的DataFrame对象中将上述保存天气的DataFrame对象,根据日期创建年度列和月份列及对应数据使用上述爬取存储DataFrame对象,将气温和天气状况属性数据(以“/”符号分割的前后两个数字分别是白天和夜间的,如xsC/25c) ,分别拆分为白天气温、夜间气温和白天天气状况和夜间天气状况属性数据,日期中不能有周六日信息,将数据按照日期按升序进行排序。
气温数据转换为数字形式,去除“c”显示查看字符串类型白天和夜间天气状况的非重复值个数,查看其描述性统计,显示查看数字类型白天气温和夜间气温的描述性统计,显示查看天气状况和气温属性是否有缺失值,如果有缺失值进行填充(如相邻值)按照城市和月份分组统计白天气温的均值(只有一个年度的可只用月份列,否则需要结合年度和月份两列分组),显示两个城市每个月的分组统计结果。
可视化分析
以日期为横轴x,以白天气温为纵轴y,分别绘制显示两个城市的折线图和散点图进行比较分别绘制两个城市白天气温的箱型图进行比较将两个城市每个月的分组统计结果数据,按月份绘制相应的柱状图。(完整代码请联系云朵君获取:wx: Mr_cloud_data)
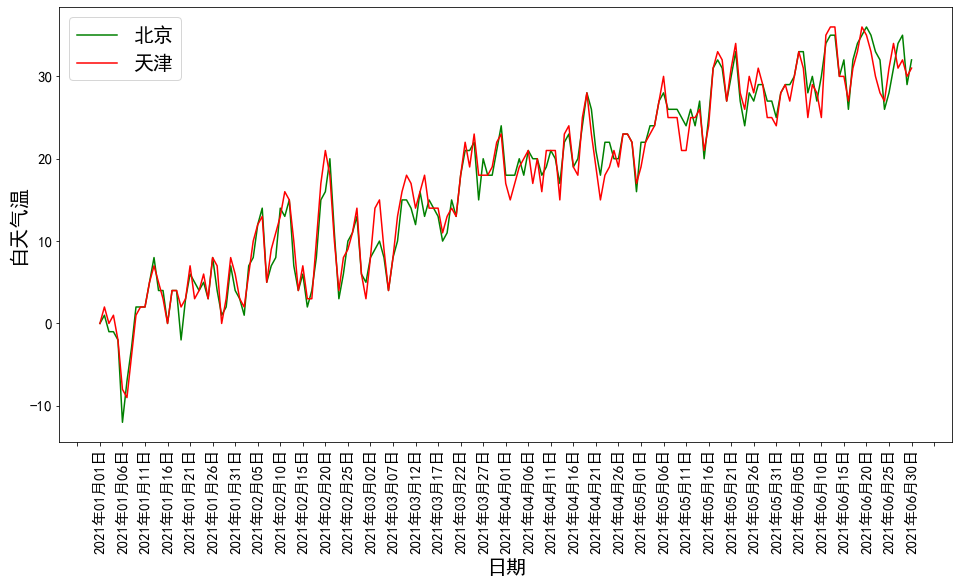
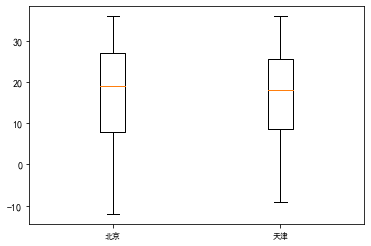
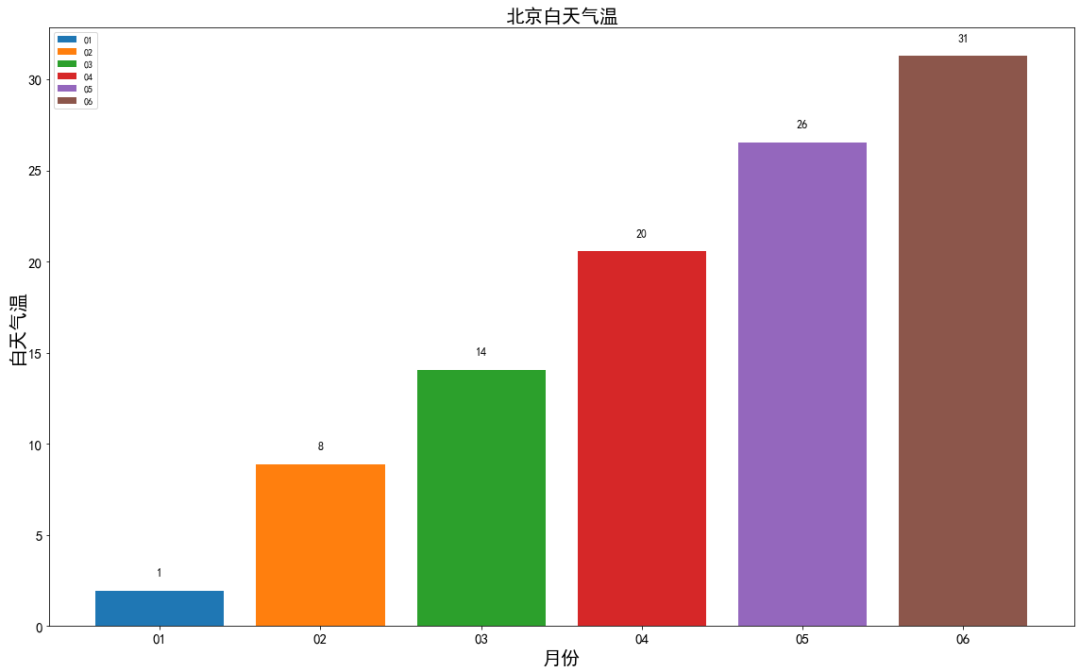
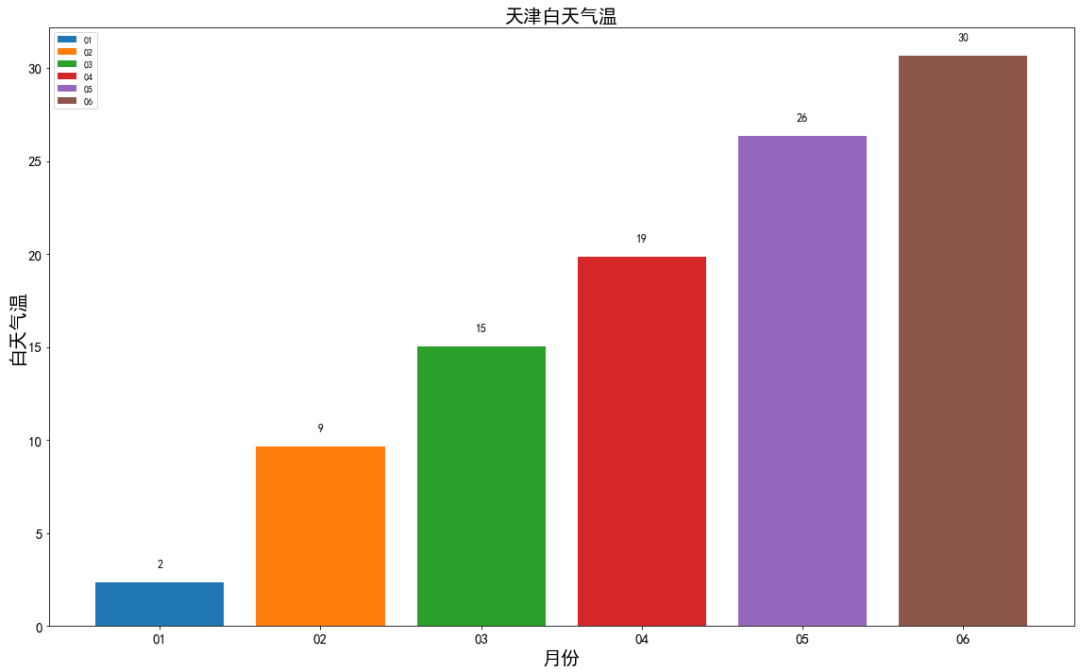
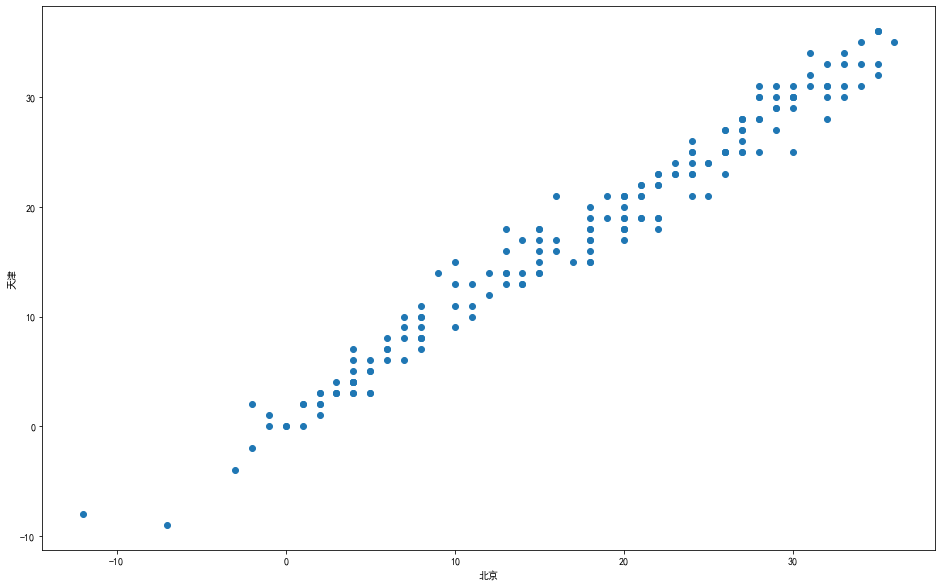
存入数据库和本地
将上述处理后的数据和分组统计数据,存入数据库中对应的一个表中(不要求建立多个表,如城市表和天气表),数据库可以是sqlite或mysql。使用数据库sqlite的,需要上传数据库文件;使用数据库mysql的,需要将数据导出为sq|脚本文件上传,这里我们使用的是SQL数据库的操作,需要包含分别使用数据库专用模块和通用模块练习的代码数据库和表的名称,将上述处理后的数据和分组统计数据,导出为Excel或CSV格式文件(选择其一即可)。
import pymysql
from sqlalchemy import create_engine
engine = 'mysql+pymysql://root:666@127.0.0.1:3306/PyDataStudio'
conn = create_engine(engine)## 连接数据库
try:
d1.to_sql('data',conn,
if_exists='replace',
index=False)### 写入数据库
except:
print('error')
数据库和本地文件读取
读取上述存储到本地文件中的天气数据,输出显示前5行和后5行。
import pymysql
from sqlalchemy import create_engine
sql = 'select * from data'
engine = 'mysql+pymysql://root:666@127.0.0.1:3306/PyDataStudio'
conn = create_engine(engine)## 链接数据库
pdata = pd.read_sql(sql, conn)### 读取数据库信息
pd.concat([pdata.head(5), pdata.tail(5)], axis=0)
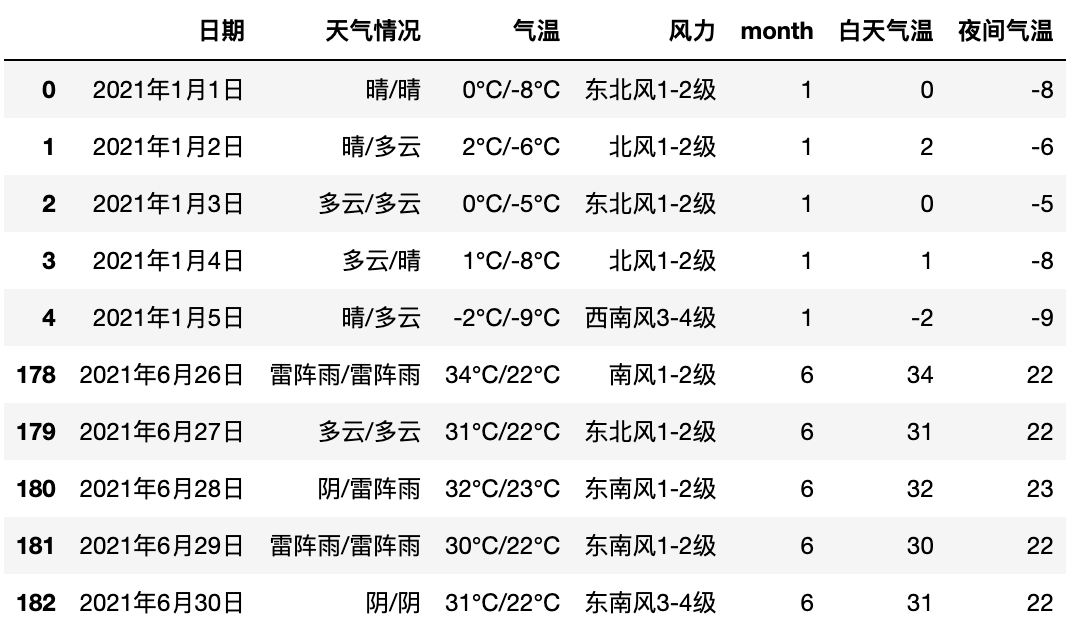
写在最后
批量爬取
注意爬取网页的网址变化规律,可用变量拼出网址字符串进行循环爬取。
例如,我们在分析北京2022年9月1日的天气时,发现url有如下的规律:
-
固定网址:http://www.tianqihoubao.com/lishi/
-
变量网址:地名拼音+时间字符串
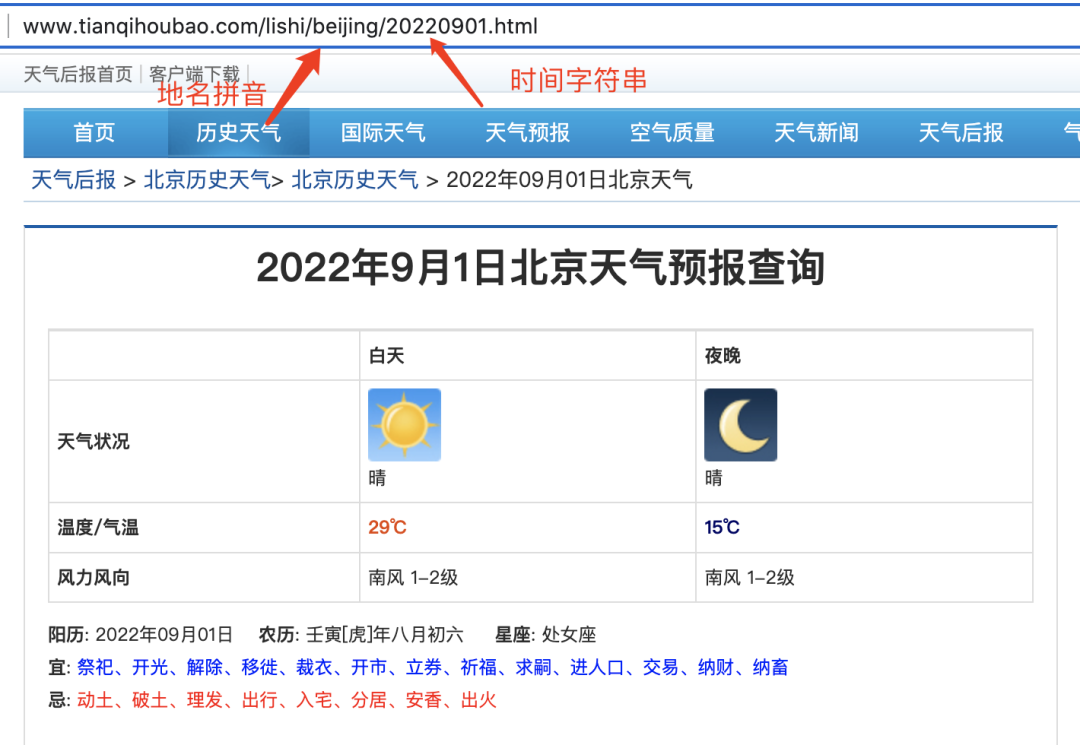
这样就可以通过赋值变量,批量循环爬取了,该部分内容留给同学们继续深入探究。
便捷方法
其实我们做爬取的该网页,属于表格类数据的网页,而爬取该类网页有一个比较便捷的方法,就是使用 pandas 的read_html(),大家可以尝试一下。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!

👉Python学习路线汇总👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

👉Python必备开发工具👈

👉Python学习视频合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉Python副业兼职路线&方法👈
学好 Python 不论是就业还是做副业赚钱都不错,但要学会兼职接单还是要有一个学习规划。

👉 这份完整版的Python全套学习资料已经上传,朋友们如果需要可以扫描下方二维码免费领取