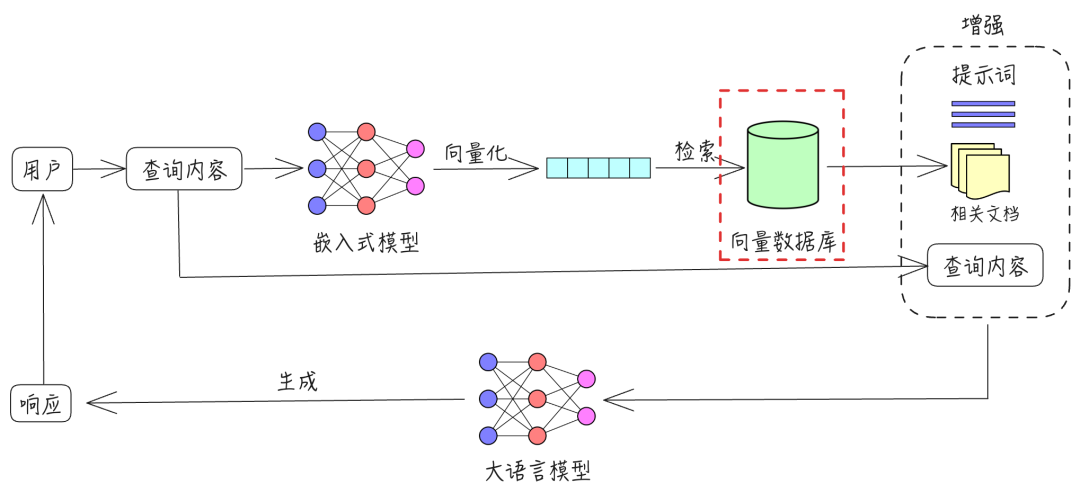
在 RAG(检索增强生成)简介的流程图中,有一个环节是检索向量数据库(下图中红色框标识的部分)。向量数据库存储了外部知识库经过向量化处理的内容。在检索之前,我们首先需要创建向量数据库,而创建的第一步是解析知识库中的文件,提取其中的文本、表格等信息。由于 PDF 格式的文件占据了文件的大部分,因此如何从 PDF 文件中精确且高效地提取这些信息,便成为创建向量数据库的关键。本文将介绍如何解析 PDF 文件,帮助实现这一目标。
PDF,即便携式文档格式(英语:Portable Document Format,缩写 PDF),是一种能够独立于应用程序、硬件和操作系统呈现文档的文件格式。PDF 之所以受欢迎,是因为它能够完全保留原文档的格式,不受设备、软件或系统的影响,这对于传播信息来说意义重大。试想一下,如果你使用的是 Word 文档,一旦更换设备,字体、图片、颜色和格式等可能都会发生变化。但 PDF 不会出现这种情况,它能够原汁原味地保留重要的图文信息,不用担心设备的影响。正是为了实现这种显示的一致性,PDF 牺牲了可编辑性。这里有一点需要注意,不是 PDF 不想做到容易编辑,也不是故意让你无法修改,而是为了极致的显示一致性,必须牺牲可编辑性。PDF 会将文本的位置、字体、间距、缩放比例、页边距等所有属性在文件格式中限定死,让软件没有自由发挥的空间。这就是为什么不同软硬件打开 PDF 效果都能一致的原因。本质上,PDF 的格式限制确保了它在任何设备上的显示效果都一样。比如,一个包含 “Hello World” 字样的 PDF 文件用 PDF 阅读器打开时,效果如下面的左边所示。如果用文本编辑器打开这个 PDF 文件,显示结果如下面的右边所示。

看到上面的这个文件内容,我们也就明白了 PDF 为什么难于编辑的原因了。但也正是这个文件,会手把手地告诉电脑,怎么一点一点把这个文件的内容在屏幕上打印出来,最大程度地确保了所有人看到这个文件的效果都一样。
上面说的这类 PDF 文件是文本 PDF,也就是机器生成的 PDF。还有一类 PDF 文本 是扫描 PDF,这类文件的每一页都是一张图片,所用到的解析方法和文本 PDF 也是不一样的。下面就分别把解析两类 PDF 文件效果还不错的工具介绍给大家。
文本 PDF 的解析
文本的提取
能够进行文本提取的 Python 库包括:pdfminer.six、PyMuPDF、PyPDF2 和 pdfplumber,效果最好的是 PyMuPDF,PyMuPDF 在进行文本提取时能够最大限度地保留 PDF 的阅读顺序,这对于双栏 PDF 文件的抽取非常有用。下面就以难度比较大的双栏 PDF 为例,来介绍使用 PyMuPDF 库进行文字抽取的效果。
我们以下面的 PDF 为例来看使用 PyMuPDF 进行文字提取的效果。

进行文本提取的代码如下:
import pymupdf
pages = pymupdf.open("bert.pdf")
text = pages[0].get_text()
print(text)
打印的结果如下:
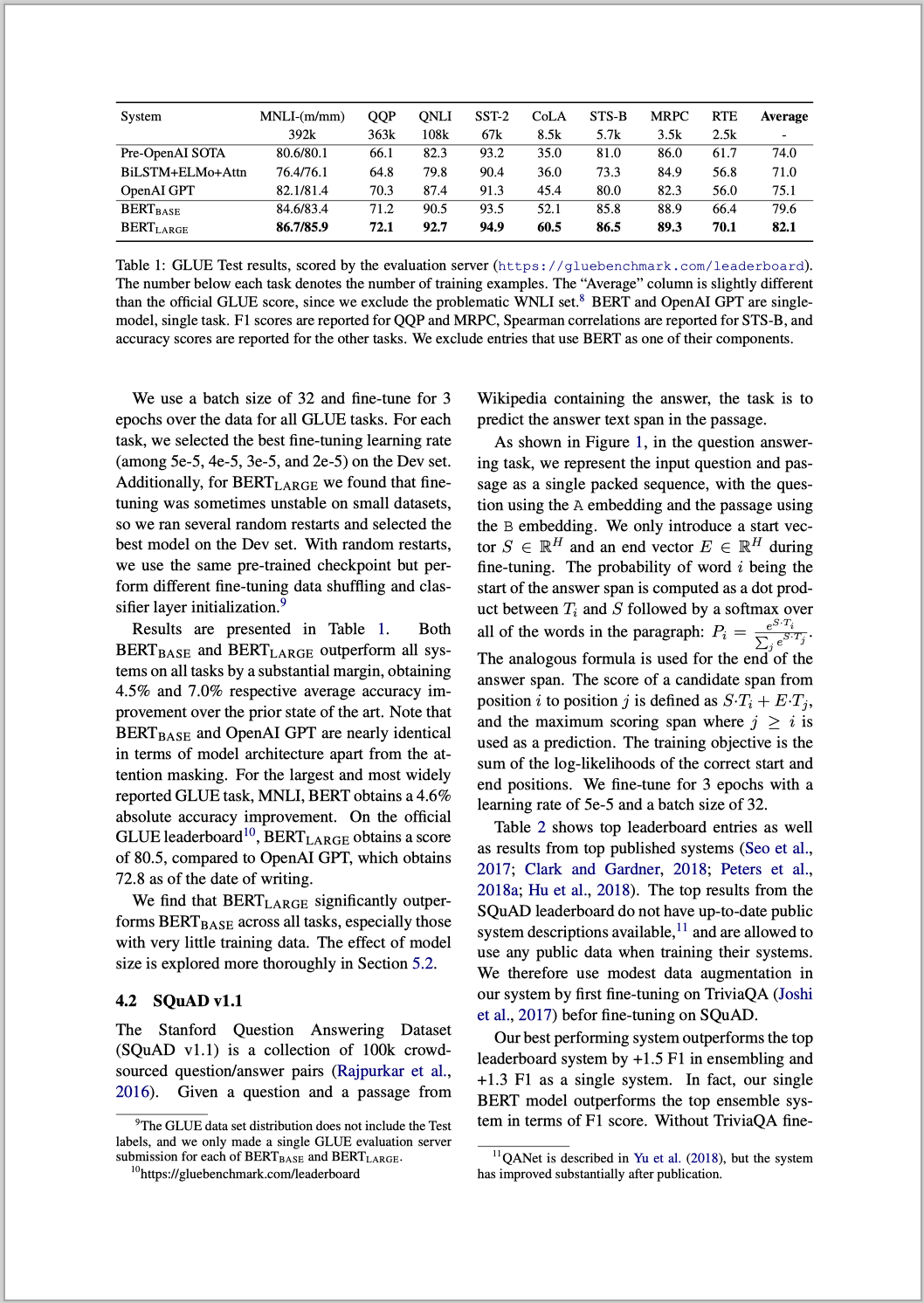
BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding
Jacob Devlin
Ming-Wei Chang
Kenton Lee
Kristina Toutanova
Google AI Language
{jacobdevlin,mingweichang,kentonl,kristout}@google.com
Abstract
We introduce a new language representa-
tion ......
(5.1 point absolute improvement).
1
Introduction
Language model pre-training has been shown to
......
De Meulder, 2003; Rajpurkar et al., 2016).
There are two existing strategies for apply-
ing ......
predict the original vocabulary id of the masked
arXiv:1810.04805v2 [cs.CL] 24 May 2019
提取出的文字遵循了原 PDF 文件的阅读顺序,也就是先读左边栏的文字,再读右边栏的文字,(为了节省版面,对部分文字进行了省略),这样提取出的文本也就保持了原 PDF 的语义。
除了上面的这种提取方式之外,我们还可以将文本提取为文本块的列表。代码如下:
import pymupdf
pages = pymupdf.open("bert.pdf")
text = pages[0].get_text("blocks")
print(text)
打印的结果如下:
[(116.51899719238281, 67.92063903808594, 481.02740478515625, 102.5250473022461, 'BERT: Pre-training of Deep Bidirectional Transformers for\nLanguage Understanding\n', 0, 0), (107.78799438476562, 128.531005859375, 492.7443542480469, 179.3809814453125, 'Jacob Devlin\nMing-Wei Chang\nKenton Lee\nKristina Toutanova\nGoogle AI Language\n{jacobdevlin,mingweichang,kentonl,kristout}@google.com\n', 1, 0), (158.89096069335938, 222.02301025390625, 203.37625122070312, 237.57672119140625, 'Abstract\n', 2, 0), ...... , (10.940000534057617, 256.5899658203125, 37.619998931884766, 609.8900146484375, 'arXiv:1810.04805v2 [cs.CL] 24 May 2019\n', 8, 0)]
由上面的结果可以看出,每个文本块包含了文本块的坐标、文本块的内容以及文本块的序号(为了节省版面,对部分文本块进行了省略)。有了每个文本块的上述信息,我们便可以知道文本块的阅读顺序;如果需要的话,还可以使用每个文本块的坐标信息对版面进行恢复。
表格的提取
表格提取效果比较好的库有 camelot 和 tabula ,表格又可以分为有线表和少线表。下面就分别以有线表和少线表为例来介绍 camelot 和 tabula 的使用。
有线表
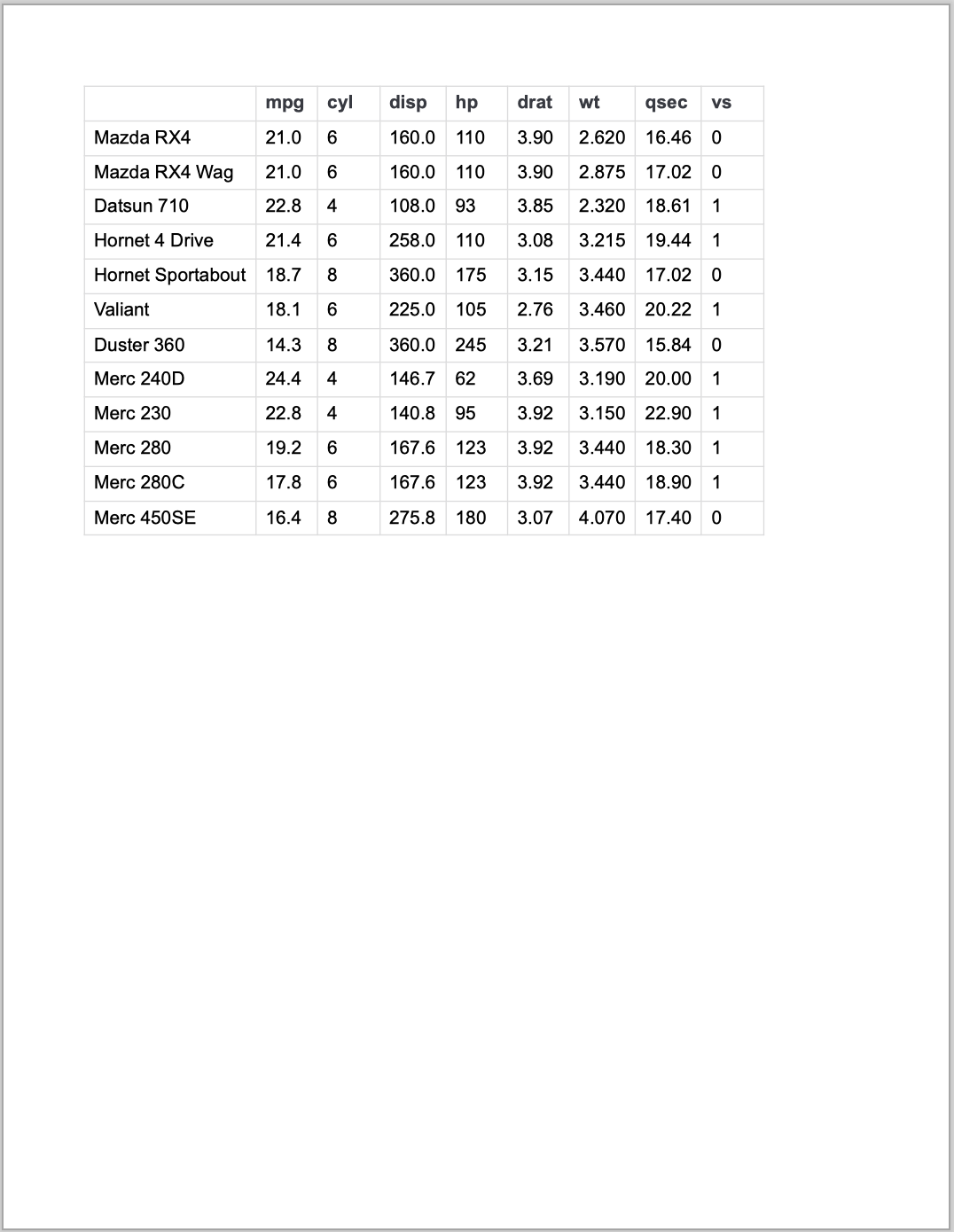
我们以下面的 PDF 为例来看使用 camelot 和 tabula 进行有线表格提取的效果。
- 使用
camelot进行表格提取的代码如下:
import camelot
tables = camelot.read_pdf('data.pdf')
print(tables[0].df)
输出结果如下:
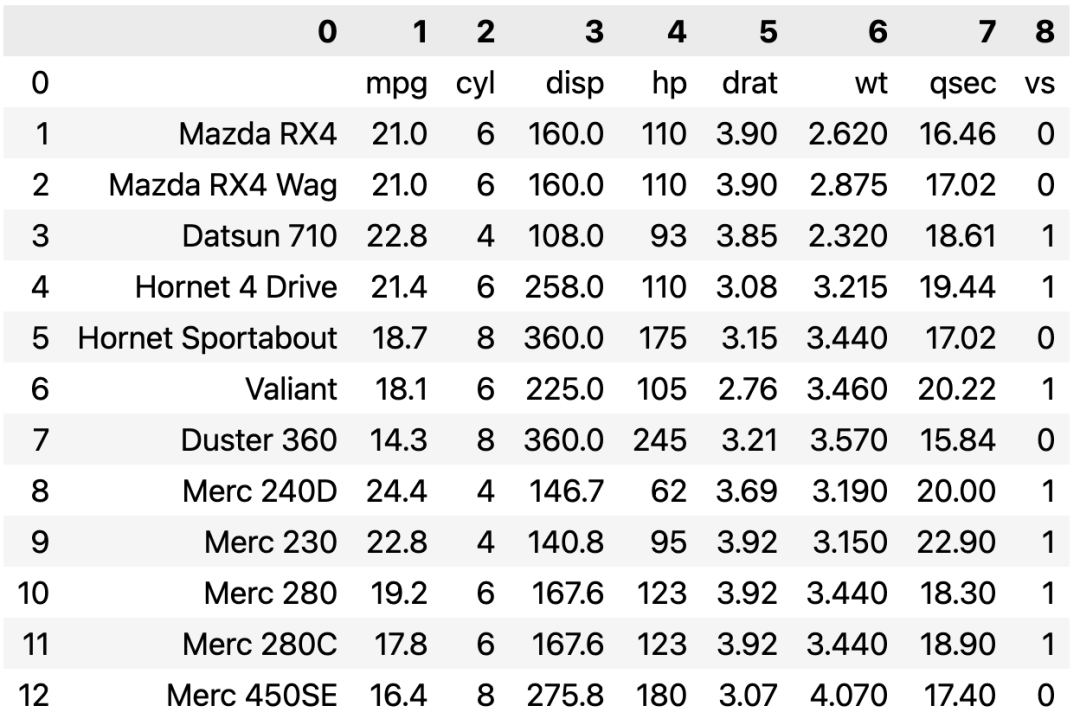
- 使用
tabula进行表格提取的代码如下:
import tabula
dfs = tabula.read_pdf("data.pdf")
print(dfs[0])
输出结果如下:
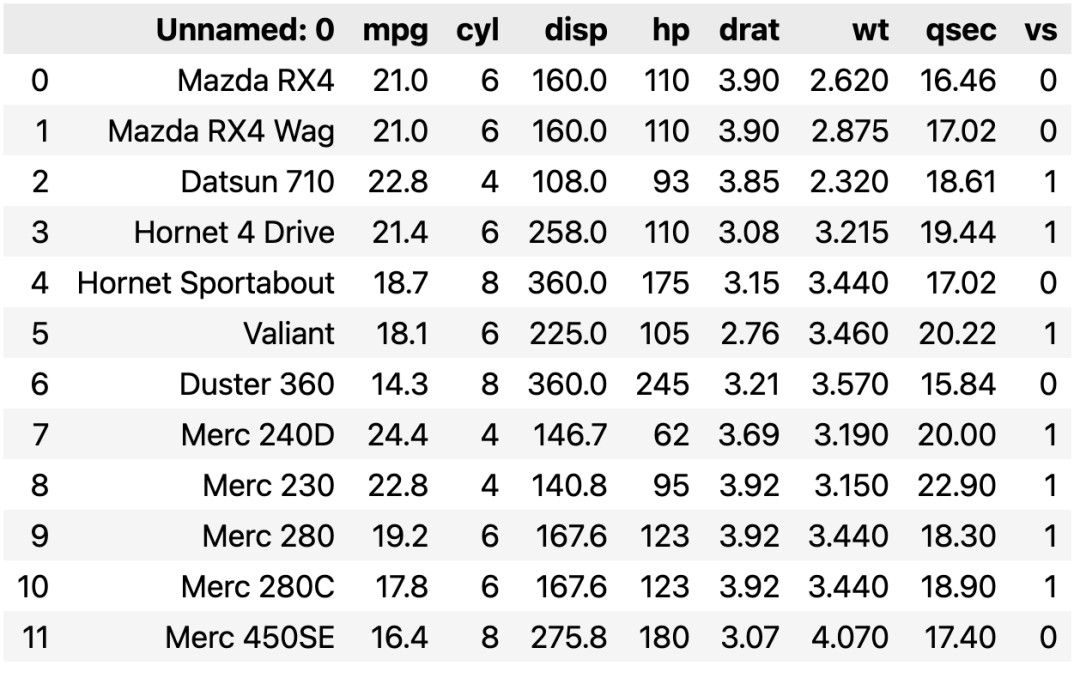
从结果可以看出,在提取有线表时,不管是 camelot 还是 tabula 都能很好地进行提取,而且不需要过多的参数设置。
少线表
我们以下面的 PDF 为例来看使用 camelot 和 tabula 进行少线表格提取的效果。
- 使用
camelot进行少线表格提取的代码如下:
import camelot
tables = camelot.read_pdf('bert-6.pdf', flavor='stream')
tables[0].df
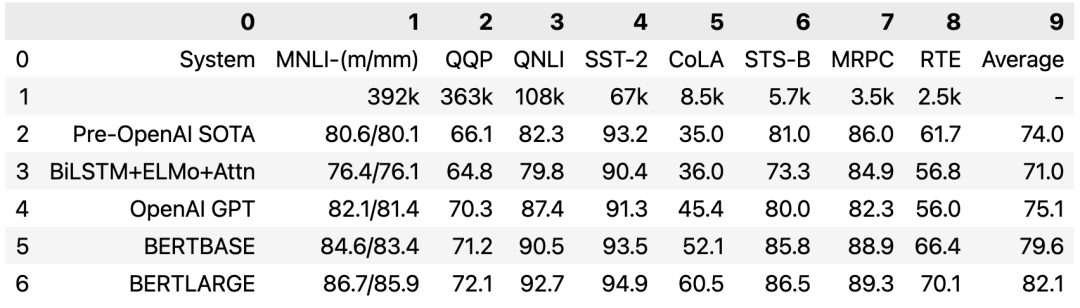
在使用 camelot 进行少线表格的提取时,需要将参数 flavor 设置成 stream ,输出结果如下:
- 使用
tabula进行少线表格提取的代码如下:
import tabula
dfs = tabula.read_pdf("bert-6.pdf", stream=True)
dfs[0]
在使用 tabula 进行少线表格的提取时,需要将参数 stream 设置成 True ,输出结果如下:
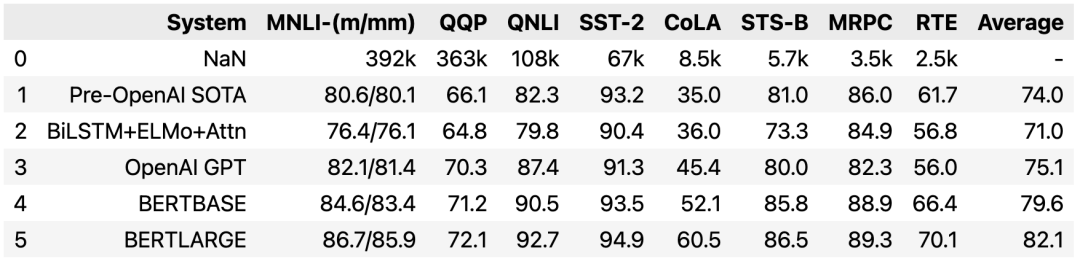
在使用 camelot 和 tabula 进行少线表格的提取时,需要设置相应的参数。
扫描 PDF 的解析
文本的提取
在从扫描的 PDF 文件中提取文本时,使用开源的 PaddleOCR,并且用 PPStructure 做版面的分析。我们还是以下面的 PDF 文件为例,不过这是的 PDF 文件是扫描 PDF。

提取文本的代码如下:
import os
import cv2
from paddleocr import PPStructure, draw_structure_result, save_structure_res
from PIL import Image
img_path = "./bert-1.png"
table_engine = PPStructure(show_log=True)
save_folder = './output'
img = cv2.imread(img_path)
result = table_engine(img)
save_structure_res(result, save_folder, os.path.basename(img_path).split('.')[0])
font_path = './fonts/simfang.ttf'
image = Image.open(img_path).convert('RGB')
im_show = draw_structure_result(image, result, font_path=font_path)
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
得到的结果如下:

图中的左边是根据给出的版面分析结果画出来的,可以看出对双栏 PDF 做了正确的解析。右边是根据识别出来的文本以及文本的坐标画出来的,可以看出基本上和左边的版面以及内容是一致的。
表格的提取
我们还是以下面的 PDF 文件为例,不过这是的 PDF 文件是扫描 PDF。
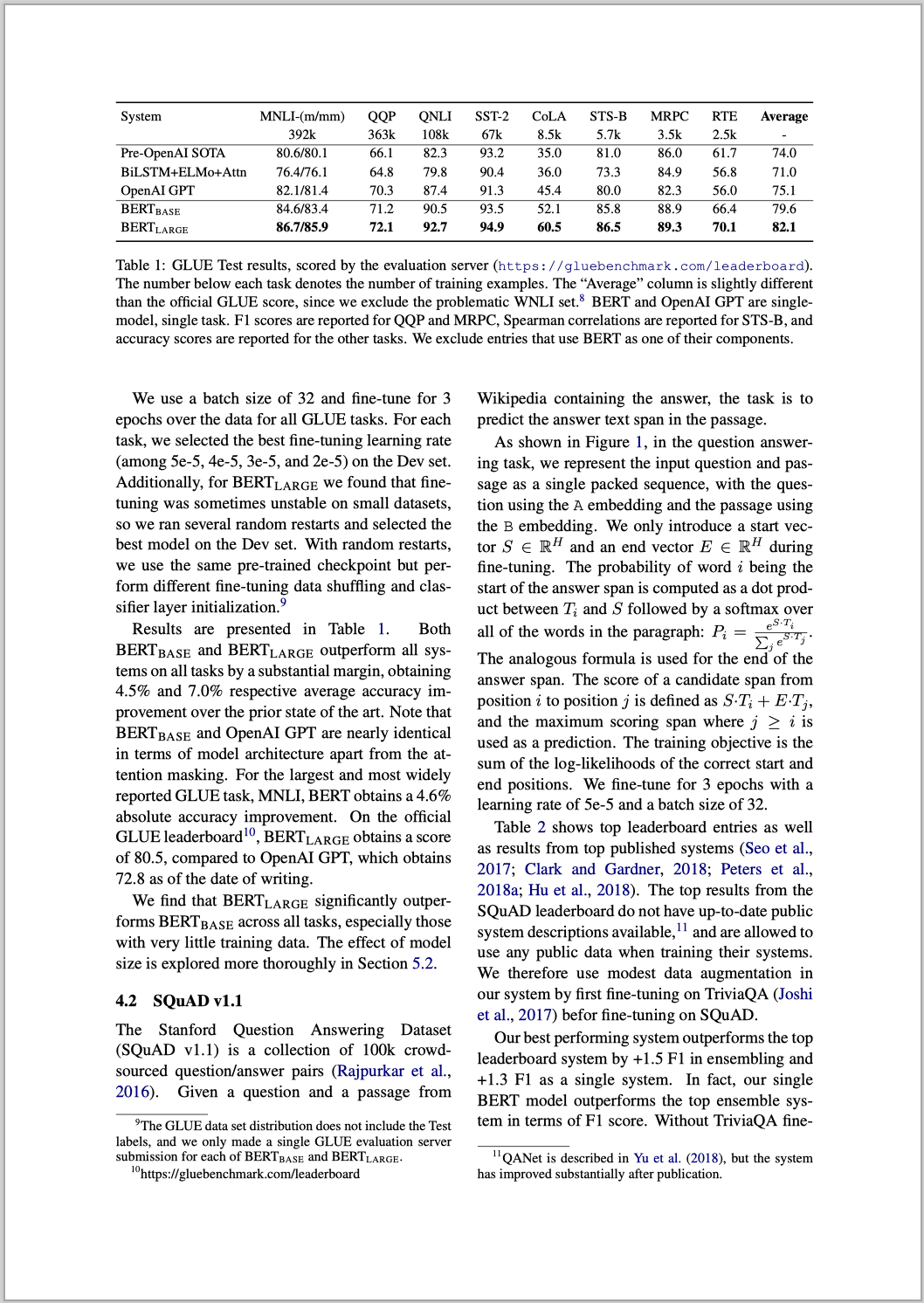
代码如下:
import os
import cv2
from paddleocr import PPStructure,draw_structure_result,save_structure_res
from PIL import Image
table_engine = PPStructure(show_log=True)
save_folder = './output'
img_path = './bert-6.png'
img = cv2.imread(img_path)
result = table_engine(img)
save_structure_res(result, save_folder,os.path.basename(img_path).split('.')[0])
for line in result:
line.pop('img')
print(line)
在上面的输出结果中,有一行类型为 table 的输出,我们将这一行中 html 标签下的内容拷贝出来,放到一个 html 文件中,得到如下的表格:

可以看出在表头这一块还是有一些差异,但是其他的信息基本都是正确的,应该说效果还是不错的。
总结
本文重要介绍了文本 PDF 和 扫描 PDF 的解析,了解到了 PDF 文件解析的复杂性。要想 RAG(检索增强生成)后面的环节取得比较好的效果,文件解析的准确性至关重要。如果在文件解析这一环节质量不高的话,后面的环节不论怎么优化,也不会达到很好的效果。所以花大力气在文件的解析上,后面会收到事半功倍的效果。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈