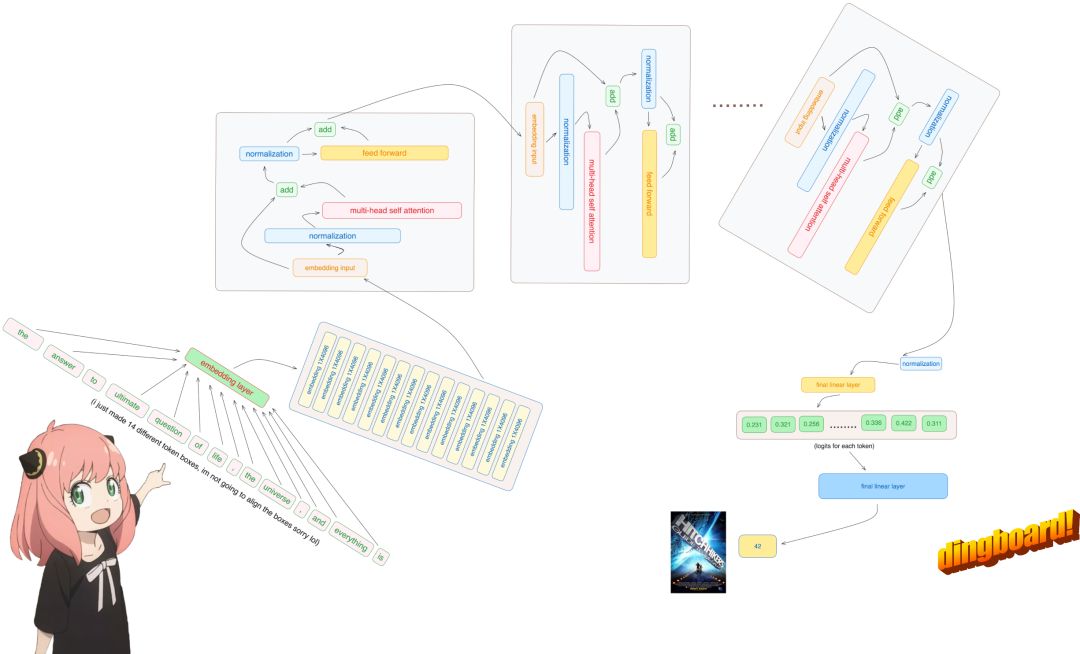
前言
最近在读几篇华为杯的优秀论文,都是关于数据预测相关的,准确来说是时间序列预测,在数据处理部分发现了一个有趣的内容“信息熵”,之前在周志华老师的西瓜书上决策树剪枝部分看到过,在数据降维的部分看到还是第一次,在另一篇文章中也用到了信息增益这个东西,两篇文章我都会放在参考中以便感兴趣的伙伴查看。
信息熵与信息增益
这里提到的都是相对连续的数据,并不是特征是类别的频率,具体可以参考其他文章。这一部分我就完全copy于论文中:“信息熵”理论:克劳德·艾尔伍德·香农(Claude Elwood Shannon)于 1948 年提出了“信息熵”理论。一般来说,某个指标的信息熵越小,计算出来的信息熵权重也就越大,相应提供的信息量越多,其在综合模型的重要程度也越大;相反,某个指标的信息越大,其所占信息权重则越小,提供的信息量也越少,在综合模型中所起到的作用也越小。其中,对于某项指标的一组数据,其信息熵权重的计算方式如下所示:
p
i
j
=
Y
i
j
/
∑
i
=
1
n
Y
i
j
E
j
=
−
ln
−
1
(
n
)
∑
i
=
1
n
p
i
j
ln
p
i
j
W
j
=
1
−
E
j
n
−
∑
i
=
1
n
E
i
(
j
=
1
,
2
,
…
,
n
)
p_{ij}=Y_{ij}/\sum_{i=1}^{n}Y_{ij}\\E_{j}=-\ln^{-1}(n)\sum_{i=1}^{n}p_{ij}\ln p_{ij}\\W_{j}=\frac{1-E_{j}}{n-\sum_{i=1}^{n}E_{i}}(j=1,2,\ldots,n)
pij=Yij/i=1∑nYijEj=−ln−1(n)i=1∑npijlnpijWj=n−∑i=1nEi1−Ej(j=1,2,…,n)其中,
E
j
E_j
Ej为第
j
j
j项指标的信息熵,
n
n
n为样本总数,
Y
j
Y_j
Yj为该指标的第
j
j
j条样本数据。
W
j
W_j
Wj是第
j
j
j个筛选后主要变量的信息熵权重。
第二个式子中的第一项的对数作者在计算中省略了,求和中的对数有时也可换成以2为底的;第三个式子在实际计算中也没有应用,而是使用了“信息熵占比”公式,在后续的代码中可以看到,计算结果相同。
信息增益部分也从论文中截取如下:

这两部分对于数据处理中的作用也不同,信息熵是作为降维之后的验证,信息增益是降维的直接方法。
代码实现——信息熵计算
import pandas as pd
import numpy as np
file_path = '2012年.xls'
data = pd.read_excel(file_path, header=0)
data_array = data.values
def cal_weight(value):
n_features = value.shape[1] # 特征的数量
n_samples = value.shape[0] # 样本的数量
# 初始化熵增益数组
g = np.zeros(n_features)
p = np.zeros_like(data_array, dtype=np.float64)
e = np.copy(p)
# 计算每个特征的熵
summ=np.sum(data_array,axis = 0)
for j in range(n_samples):
for i in range(n_features):
p[j][i] = value[j][i] / summ[i]
p[j][i] = np.where(p[j][i] == 0, 1e-9, p[j][i])
e[j][i]=(p[j][i] * np.log(p[j][i]))
ee = np.sum(e,axis = 0)
for i in range(n_features):
g[i] = 1 - ee[i]
w = g / np.sum(g)
return w
# 计算权重
w = cal_weight(data_array)
feature_names = data.columns # 示例特征名
w_df = pd.DataFrame(w, index=feature_names, columns=['权重'])
print("#######权重:#######")
print(w_df.sort_values(by="权重", ascending=False))
论文中所提供的代码并没有实现(有点乱码),中间的计算部分我又花费了好久才完成(即使公式非常简单),原因是有点太依赖语言大模型不肯自己动脑思考,中间也出现了好多问题:
1、在原始数据的计算过程中记过出现了nan值,原因是第二个式子中的对数计算,
p
i
j
p_{ij}
pij会出现负的,这是由于数据中有正有负,可能论文中用于降维后的验证也有道理(降维后的数据恰好都是正值),但是如果有负值就不能用了吗,我也查询了一些方法可以调整:
最小值加1法:将所有数值转换成它们相对于最小值的偏移量,再加上一个足够大的常数(如最小值+1),使得所有的值都成为非负的。例如,如果最小值是-5,则将每个数变成 ( x + 6 ),再计算信息熵。
最小二乘归一化:将数据标准化到0到1之间,这可以通过将数据减去最小值并除以最大值减去最小值来实现,虽然结果不再是绝对值,但它保证了数据在分析过程中是正的。
对称化:如果数据分布在均值附近存在负值和正值的对称分布,可以选择平均值作为参考点,将数据转换为相对平均值的偏差形式,然后再计算信息熵。
2、信息熵计算公式中的第三个在实际计算中可以写的稍微简单一点。
最后得到的输出形式的代码参考于论文中的,得到的结果如图:
参考
两篇论文都是2022年华为杯E题的优秀论文,其中提到信息熵的编号为E22103350038;信息增益的为E22103040108,分别在29页和20页。下载链接如下:链接:论文下载
提取码:1234