文件系统的基本组成
1.什么是linux文件系统
Linux 最经典的⼀句话是:「⼀切皆⽂件」,不仅普通的⽂件和⽬录,就连块设备、管道、socket 等,也
都是统⼀交给⽂件系统管理的。
Linux ⽂件系统会为每个⽂件分配两个数据结构:索引节点(index node)和⽬录项**(**directory
entry**)**,它们主要⽤来记录⽂件的元信息和⽬录层次结构。
- 索引节点,也就是 inode,⽤来记录⽂件的元信息,⽐如 inode 编号、⽂件⼤⼩、访问权限、创建时间、修改时间、数据在磁盘的位置等等。索引节点是⽂件的唯⼀标识,它们之间⼀⼀对应,也同样都
会被存储在硬盘中,所以索引节点同样占⽤磁盘空间。
- ⽬录项,也就是 dentry,⽤来记录⽂件的名字、索引节点指针以及与其他⽬录项的层级关联关系。多
个⽬录项关联起来,就会形成⽬录结构,但它与索引节点不同的是,⽬录项是由内核维护的⼀个数据结构,不存放于磁盘,⽽是缓存在内存。
由于索引节点唯⼀标识⼀个⽂件,⽽⽬录项记录着⽂件的名,所以⽬录项和索引节点的关系是多对⼀,也
就是说,⼀个⽂件可以有多个别字。⽐如,硬链接的实现就是多个⽬录项中的索引节点指向同⼀个⽂件。
注意,⽬录也是⽂件,也是⽤索引节点唯⼀标识,和普通⽂件不同的是,普通⽂件在磁盘⾥⾯保存的是⽂件数据,⽽⽬录⽂件在磁盘⾥⾯保存⼦⽬录或⽂件。
2.目录项和目录是一个东西吗?
虽然名字很相近,但是它们不是⼀个东⻄,⽬录是个⽂件,持久化存储在磁盘,⽽⽬录项是内核⼀个数据
结构,缓存在内存。
如果查询⽬录频繁从磁盘读,效率会很低,所以内核会把已经读过的⽬录⽤⽬录项这个数据结构缓存在内
存,下次再次读到相同的⽬录时,只需从内存读就可以,⼤⼤提⾼了⽂件系统的效率。
注意,⽬录项这个数据结构不只是表示⽬录,也是可以表示⽂件的。
3.⽂件数据是如何存储在磁盘的呢?
磁盘读写的最⼩单位是扇区,扇区的⼤⼩只有 512B ⼤⼩,很明显,如果每次读写都以这么⼩为单位,
那这读写的效率会⾮常低。
所以,⽂件系统把多个扇区组成了⼀个逻辑块,每次读写的最⼩单位就是逻辑块(数据块),Linux 中的逻
辑块⼤⼩为 4KB ,也就是⼀次性读写 8 个扇区,这将⼤⼤提⾼了磁盘的读写的效率。
以上就是索引节点、⽬录项以及⽂件数据的关系,下⾯这个图就很好的展示了它们之间的关系:

索引节点是存储在硬盘上的数据,那么为了加速⽂件的访问,通常会把索引节点加载到内存中。
另外,磁盘进⾏格式化的时候,会被分成三个存储区域,分别是超级块、索引节点区和数据块区。
-
超级块,⽤来存储⽂件系统的详细信息,⽐如块个数、块⼤⼩、空闲块等等。
-
索引节点区,⽤来存储索引节点;
-
数据块区,⽤来存储⽂件或⽬录数据;
我们不可能把超级块和索引节点区全部加载到内存,这样内存肯定撑不住,所以只有当需要使⽤的时候,
才将其加载进内存,它们加载进内存的时机是不同的:
-
超级块:当⽂件系统挂载时进⼊内存;
-
索引节点区:当⽂件被访问时进⼊内存;
虚拟文件系统
4.什么是虚拟文件系统
⽂件系统的种类众多,⽽操作系统希望对⽤户提供⼀个统⼀的接⼝,于是在⽤户层与⽂件系统层引⼊了中
间层,这个中间层就称为虚拟⽂件系统(Virtual File System,VFS)。
VFS 定义了⼀组所有⽂件系统都⽀持的数据结构和标准接⼝,这样程序员不需要了解⽂件系统的⼯作原
理,只需要了解 VFS 提供的统⼀接⼝即可
在 Linux ⽂件系统中,⽤户空间、系统调⽤、虚拟机⽂件系统、缓存、⽂件系统以及存储之间的关系如下
图:
5.linux支持哪些文件系统
Linux ⽀持的⽂件系统也不少,根据存储位置的不同,可以把⽂件系统分为三类:
-
磁盘的⽂件系统,它是直接把数据存储在磁盘中,⽐如 Ext 2/3/4、XFS 等都是这类⽂件系统。
-
内存的⽂件系统,这类⽂件系统的数据不是存储在硬盘的,⽽是占⽤内存空间,我们经常⽤到的
/proc 和 /sys ⽂件系统都属于这⼀类,读写这类⽂件,实际上是读写内核中相关的数据。
- ⽹络的⽂件系统,⽤来访问其他计算机主机数据的⽂件系统,⽐如 NFS、SMB 等等
6.用户如何使用文件
我们从⽤户⻆度来看⽂件的话,就是我们要怎么使⽤⽂件?⾸先,我们得通过系统调⽤来打开⼀个⽂件

fd = open(name, flag); # 打开⽂件
...
write(fd,...); # 写数据
...
close(fd); # 关闭⽂件
上⾯简单的代码是读取⼀个⽂件的过程:
-
⾸先⽤ open 系统调⽤打开⽂件, open 的参数中包含⽂件的路径名和⽂件名。
-
使⽤ write 写数据,其中 write 使⽤ open 所返回的⽂件描述符,并不使⽤⽂件名作为参数。
-
使⽤完⽂件后,要⽤ close 系统调⽤关闭⽂件,避免资源的泄露。
我们打开了⼀个⽂件后,操作系统会跟踪进程打开的所有⽂件,所谓的跟踪呢,就是操作系统为每个进程
维护⼀个打开⽂件表,⽂件表⾥的每⼀项代表「⽂件描述符」,所以说⽂件描述符是打开⽂件的标识。

操作系统在打开⽂件表中维护着打开⽂件的状态和信息:
⽂件指针:系统跟踪上次读写位置作为当前⽂件位置指针,这种指针对打开⽂件的某个进程来说是唯
⼀的;
⽂件打开计数器:⽂件关闭时,操作系统必须重⽤其打开⽂件表条⽬,否则表内空间不够⽤。因为多
个进程可能打开同⼀个⽂件,所以系统在删除打开⽂件条⽬之前,必须等待最后⼀个进程关闭⽂件,
该计数器跟踪打开和关闭的数量,当该计数为 0 时,系统关闭⽂件,删除该条⽬;
⽂件磁盘位置:绝⼤多数⽂件操作都要求系统修改⽂件数据,该信息保存在内存中,以免每个操作都
从磁盘中读取;
访问权限:每个进程打开⽂件都需要有⼀个访问模式(创建、只读、读写、添加等),该信息保存在
进程的打开⽂件表中,以便操作系统能允许或拒绝之后的 I/O 请求;
在⽤户视⻆⾥,⽂件就是⼀个持久化的数据结构,但操作系统并不会关⼼你想存在磁盘上的任何的数据结
构,操作系统的视⻆是如何把⽂件数据和磁盘块对应起来。
我们来分别看⼀下,读⽂件和写⽂件的过程:
- 当⽤户进程从⽂件读取 1 个字节⼤⼩的数据时,⽂件系统则需要获取字节所在的数据块,再返回数据
块对应的⽤户进程所需的数据部分。
- 当⽤户进程把 1 个字节⼤⼩的数据写进⽂件时,⽂件系统则找到需要写⼊数据的数据块的位置,然后
修改数据块中对应的部分,最后再把数据块写回磁盘。
所以说,⽂件系统的基本操作单位是数据块
7.文件如何存储的
⽂件的数据是要存储在硬盘上⾯的,数据在磁盘上的存放⽅式,就像程序在内存中存放的⽅式那样,有以
下两种:
-
连续空间存放⽅式
-
⾮连续空间存放⽅式
其中,⾮连续空间存放⽅式⼜可以分为「链表⽅式」和「索引⽅式」。
不同的存储⽅式,有各⾃的特点,重点是要分析它们的存储效率和读写性能,接下来分别对每种存储⽅式
说⼀下。
01连续空间存放方式
连续空间存放⽅式顾名思义,⽂件存放在磁盘「连续的」物理空间中。这种模式下,⽂件的数据都是紧密
相连,读写效率很⾼,因为⼀次磁盘寻道就可以读出整个⽂件。
使⽤连续存放的⽅式有⼀个前提,必须先知道⼀个⽂件的⼤⼩,这样⽂件系统才会根据⽂件的⼤⼩在磁盘
上找到⼀块连续的空间分配给⽂件。
所以,⽂件头⾥需要指定「起始块的位置」和「⻓度」,有了这两个信息就可以很好的表示⽂件存放⽅式
是⼀块连续的磁盘空间。
注意,此处说的⽂件头,就类似于 Linux 的 inode。

连续空间存放的⽅式虽然读写效率⾼,但是有「磁盘空间碎⽚」和「⽂件⻓度不易扩展」的缺陷。
如下图,如果⽂件 B 被删除,磁盘上就留下⼀块空缺,这时,如果新来的⽂件⼩于其中的⼀个空缺,我们
就可以将其放在相应空缺⾥。但如果该⽂件的⼤⼩⼤于所有的空缺,但却⼩于空缺⼤⼩之和,则虽然磁盘
上有⾜够的空缺,但该⽂件还是不能存放。当然了,我们可以通过将现有⽂件进⾏挪动来腾出空间以容纳
新的⽂件,但是这个在磁盘挪动⽂件是⾮常耗时,所以这种⽅式不太现实。
另外⼀个缺陷是⽂件⻓度扩展不⽅便,例如上图中的⽂件 A 要想扩⼤⼀下,需要更多的磁盘空间,唯⼀的
办法就只能是挪动的⽅式,前⾯也说了,这种⽅式效率是⾮常低的。
那么有没有更好的⽅式来解决上⾯的问题呢?答案当然有,既然连续空间存放的⽅式不太⾏,那么我们就
改变存放的⽅式,使⽤⾮连续空间存放⽅式来解决这些缺陷
02 非连续空间存放
⾮连续空间存放⽅式分为「链表⽅式」和「索引⽅式」
链表的⽅式存放是离散的,不⽤连续的,于是就可以消除磁盘碎⽚,可⼤⼤提⾼磁盘空间的利⽤率,同时
⽂件的⻓度可以动态扩展。根据实现的⽅式的不同,链表可分为「隐式链表」和「显式链接」两种形式。
⽂件要以「隐式链表」的⽅式存放的话,实现的⽅式是⽂件头要包含「第⼀块」和「最后⼀块」的位置,
并且每个数据块⾥⾯留出⼀个指针空间,⽤来存放下⼀个数据块的位置,这样⼀个数据块连着⼀个数据
块,从链头开是就可以顺着指针找到所有的数据块,所以存放的⽅式可以是不连续的。

隐式链表的存放⽅式的缺点在于⽆法直接访问数据块,只能通过指针顺序访问⽂件,以及数据块指针消耗
了⼀定的存储空间。隐式链接分配的稳定性较差,系统在运⾏过程中由于软件或者硬件错误导致链表中的
指针丢失或损坏,会导致⽂件数据的丢失。
如果取出每个磁盘块的指针,把它放在内存的⼀个表中,就可以解决上述隐式链表的两个不⾜。那么,这
种实现⽅式是「显式链接」,它指把⽤于链接⽂件各数据块的指针,显式地存放在内存的⼀张链接表中,
该表在整个磁盘仅设置⼀张,每个表项中存放链接指针,指向下⼀个数据块号。
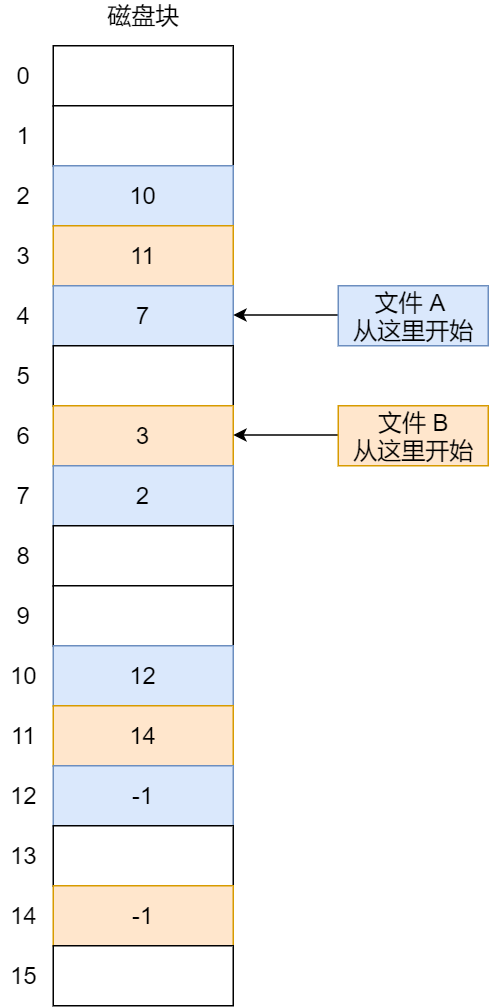
对于显式链接的⼯作⽅式,我们举个例⼦,⽂件 A 依次使⽤了磁盘块 4、7、2、10 和 12 ,⽂件 B 依次使
⽤了磁盘块 6、3、11 和 14 。利⽤下图中的表,可以从第 4 块开始,顺着链⾛到最后,找到⽂件 A 的全
部磁盘块。同样,从第 6 块开始,顺着链⾛到最后,也能够找出⽂件 B 的全部磁盘块。最后,这两个链都
以⼀个不属于有效磁盘编号的特殊标记(如 -1 )结束。内存中的这样⼀个表格称为**⽂件分配表(**File
Allocation Table**,FAT)**。
由于查找记录的过程是在内存中进⾏的,因⽽不仅显著地提⾼了检索速度,⽽且⼤⼤减少了访问磁盘的次
数。但也正是整个表都存放在内存中的关系,它的主要的缺点是不适⽤于⼤磁盘。
⽐如,对于 200GB 的磁盘和 1KB ⼤⼩的块,这张表需要有 2 亿项,每⼀项对应于这 2 亿个磁盘块中的⼀
个块,每项如果需要 4 个字节,那这张表要占⽤ 800MB 内存,很显然 FAT ⽅案对于⼤磁盘⽽⾔不太合
适。
链表的⽅式解决了连续分配的磁盘碎⽚和⽂件动态扩展的问题,但是不能有效⽀持直接访问(FAT除外),
索引的⽅式可以解决这个问题。
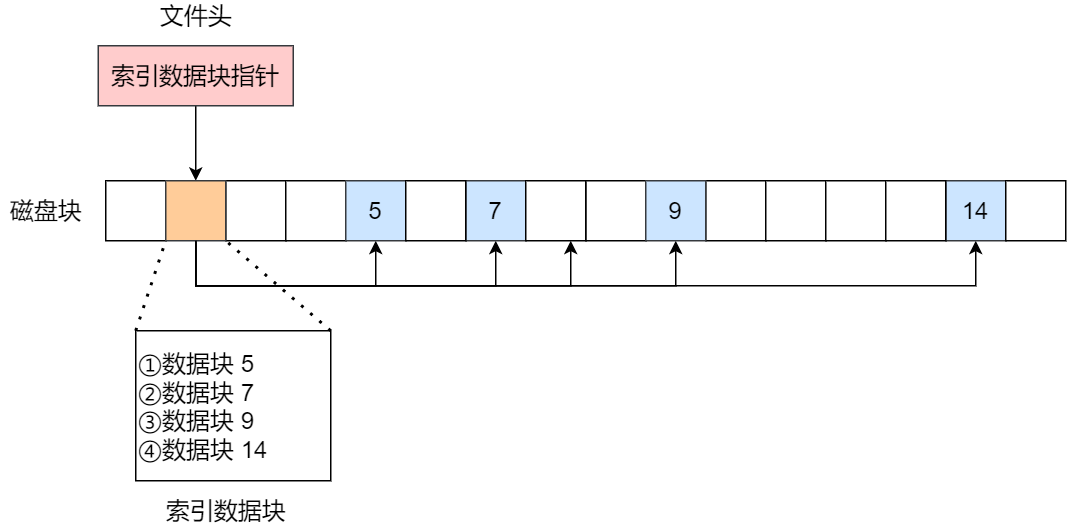
索引的实现是为每个⽂件创建⼀个「索引数据块」,⾥⾯存放的是指向⽂件数据块的指针列表,说⽩了就
像书的⽬录⼀样,要找哪个章节的内容,看⽬录查就可以。
另外,⽂件头需要包含指向「索引数据块」的指针,这样就可以通过⽂件头知道索引数据块的位置,再通
过索引数据块⾥的索引信息找到对应的数据块。
创建⽂件时,索引块的所有指针都设为空。当⾸次写⼊第 i 块时,先从空闲空间中取得⼀个块,再将其地
址写到索引块的第 i 个条⽬
索引的⽅式优点在于:
⽂件的创建、增⼤、缩⼩很⽅便;
不会有碎⽚的问题;
⽀持顺序读写和随机读写;
由于索引数据也是存放在磁盘块的,如果⽂件很⼩,明明只需⼀块就可以存放的下,但还是需要额外分配
⼀块来存放索引数据,所以缺陷之⼀就是存储索引带来的开销。
如果⽂件很⼤,⼤到⼀个索引数据块放不下索引信息,这时⼜要如何处理⼤⽂件的存放呢?我们可以通过
组合的⽅式,来处理⼤⽂件的存。
先来看看链表 + 索引的组合,这种组合称为「链式索引块」,它的实现⽅式是在索引数据块留出⼀个存放
下⼀个索引数据块的指针,于是当⼀个索引数据块的索引信息⽤完了,就可以通过指针的⽅式,找到下⼀
个索引数据块的信息。那这种⽅式也会出现前⾯提到的链表⽅式的问题,万⼀某个指针损坏了,后⾯的数
据也就会⽆法读取了
还有另外⼀种组合⽅式是索引 + 索引的⽅式,这种组合称为「多级索引块」,实现⽅式是通过⼀个索引块
来存放多个索引数据块,⼀层套⼀层索引,像极了俄罗斯套娃是吧。
8.unix文件如何存储的
我们先把前⾯提到的⽂件实现⽅式,做个⽐较

那早期 Unix ⽂件系统是组合了前⾯的⽂件存放⽅式的优点,如下图:
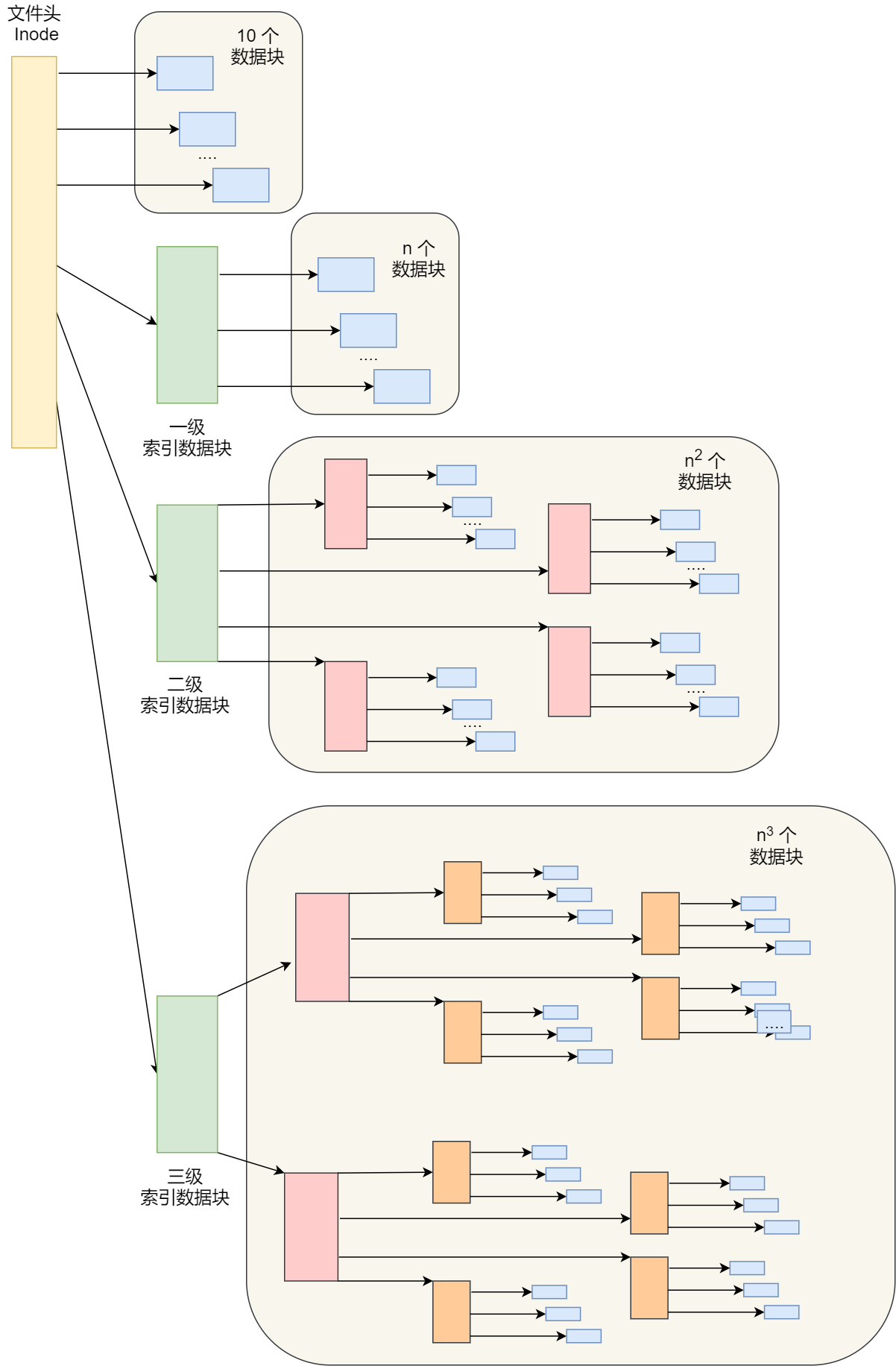
它是根据⽂件的⼤⼩,存放的⽅式会有所变化:
如果存放⽂件所需的数据块⼩于 10 块,则采⽤直接查找的⽅式;
如果存放⽂件所需的数据块超过 10 块,则采⽤⼀级间接索引⽅式;如果前⾯两种⽅式都不够存放⼤⽂件,则采⽤⼆级间接索引⽅式;
如果⼆级间接索引也不够存放⼤⽂件,这采⽤三级间接索引⽅式;
那么,⽂件头(Inode)就需要包含 13 个指针:
10 个指向数据块的指针;
第 11 个指向索引块的指针;
第 12 个指向⼆级索引块的指针;
第 13 个指向三级索引块的指针;
所以,这种⽅式能很灵活地⽀持⼩⽂件和⼤⽂件的存放
对于⼩⽂件使⽤直接查找的⽅式可减少索引数据块的开销;
对于⼤⽂件则以多级索引的⽅式来⽀持,所以⼤⽂件在访问数据块时需要⼤量查询;
这个⽅案就⽤在了 Linux Ext 2/3 ⽂件系统⾥,虽然解决⼤⽂件的存储,但是对于⼤⽂件的访问,需要⼤量
的查询,效率⽐较低。
为了解决这个问题,Ext 4 做了⼀定的改变,具体怎么解决的,本⽂就不展开了。
9.如何对空闲空间进行管理
前⾯说到的⽂件的存储是针对已经被占⽤的数据块组织和管理,接下来的问题是,如果我要保存⼀个数据
块,我应该放在硬盘上的哪个位置呢?难道需要将所有的块扫描⼀遍,找个空的地⽅随便放吗?
那这种⽅式效率就太低了,所以针对磁盘的空闲空间也是要引⼊管理的机制,接下来介绍⼏种常⻅的⽅
法:
- 空闲表法
空闲表法就是为所有空闲空间建⽴⼀张表,表内容包括空闲区的第⼀个块号和该空闲区的块个数,注意,
这个⽅式是连续分配的。如下图

当请求分配磁盘空间时,系统依次扫描空闲表⾥的内容,直到找到⼀个合适的空闲区域为⽌。当⽤户撤销
⼀个⽂件时,系统回收⽂件空间。这时,也需顺序扫描空闲表,寻找⼀个空闲表条⽬并将释放空间的第⼀
个物理块号及它占⽤的块数填到这个条⽬中。
这种⽅法仅当有少量的空闲区时才有较好的效果。因为,如果存储空间中有着⼤量的⼩的空闲区,则空闲
表变得很⼤,这样查询效率会很低。另外,这种分配技术适⽤于建⽴连续⽂件。
-
空闲链表法
我们也可以使⽤「链表」的⽅式来管理空闲空间,每⼀个空闲块⾥有⼀个指针指向下⼀个空闲块,这样也
能很⽅便的找到空闲块并管理起来。如下图
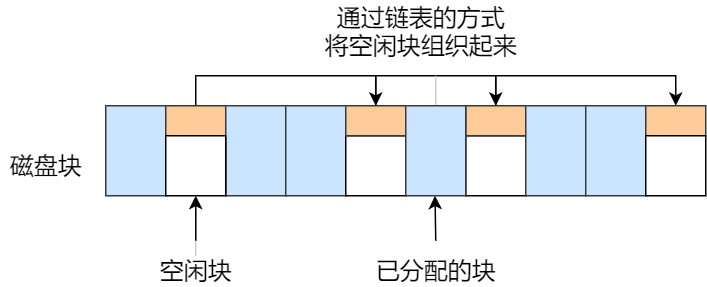
能很⽅便的找到空闲块并管理起来。如下图:
当创建⽂件需要⼀块或⼏块时,就从链头上依次取下⼀块或⼏块。反之,当回收空间时,把这些空闲块依
次接到链头上。这种技术只要在主存中保存⼀个指针,令它指向第⼀个空闲块。其特点是简单,但不能随机访问,⼯作效
率低,因为每当在链上增加或移动空闲块时需要做很多 I/O 操作,同时数据块的指针消耗了⼀定的存储空
间。
空闲表法和空闲链表法都不适合⽤于⼤型⽂件系统,因为这会使空闲表或空闲链表太⼤。
- 位图法
位图是利⽤⼆进制的⼀位来表示磁盘中⼀个盘块的使⽤情况,磁盘上所有的盘块都有⼀个⼆进制位与之对
应。
当值为 0 时,表示对应的盘块空闲,值为 1 时,表示对应的盘块已分配。它形式如下:
在 Linux ⽂件系统就采⽤了位图的⽅式来管理空闲空间,不仅⽤于数据空闲块的管理,还⽤于 inode 空闲
块的管理,因为 inode 也是存储在磁盘的,⾃然也要有对其管理。
10.文件系统的结构是什么样的
前⾯提到 Linux 是⽤位图的⽅式管理空闲空间,⽤户在创建⼀个新⽂件时,Linux 内核会通过 inode 的位图
找到空闲可⽤的 inode,并进⾏分配。要存储数据时,会通过块的位图找到空闲的块,并分配,但仔细计
算⼀下还是有问题的。
数据块的位图是放在磁盘块⾥的,假设是放在⼀个块⾥,⼀个块 4K,每位表示⼀个数据块,共可以表示
4 * 1024 * 8 = 2^15 个空闲块,由于 1 个数据块是 4K ⼤⼩,那么最⼤可以表示的空间为 2^15 * 4 *
1024 = 2^27 个 byte,也就是 128M。
也就是说按照上⾯的结构,如果采⽤「⼀个块的位图 + ⼀系列的块」,外加「⼀个块的 inode 的位图 + ⼀
系列的 inode 的结构」能表示的最⼤空间也就 128M,这太少了,现在很多⽂件都⽐这个⼤。
在 Linux ⽂件系统,把这个结构称为⼀个块组,那么有 N 多的块组,就能够表示 N ⼤的⽂件。
下图给出了 Linux Ext2 整个⽂件系统的结构和块组的内容,⽂件系统都由⼤量块组组成,在硬盘上相继排
布:

最前⾯的第⼀个块是引导块,在系统启动时⽤于启⽤引导,接着后⾯就是⼀个⼀个连续的块组了,块组的
内容如下:
超级块,包含的是⽂件系统的重要信息,⽐如 inode 总个数、块总个数、每个块组的 inode 个数、每
个块组的块个数等等。
块组描述符,包含⽂件系统中各个块组的状态,⽐如块组中空闲块和 inode 的数⽬等,每个块组都包
含了⽂件系统中「所有块组的组描述符信息」。
数据位图和 inode 位图, ⽤于表示对应的数据块或 inode 是空闲的,还是被使⽤中。
inode 列表,包含了块组中所有的 inode,inode ⽤于保存⽂件系统中与各个⽂件和⽬录相关的所有元
数据。
数据块,包含⽂件的有⽤数据。
你可以会发现每个块组⾥有很多重复的信息,⽐如超级块和块组描述符表,这两个都是全局信息,⽽且⾮
常的重要,这么做是有两个原因:
如果系统崩溃破坏了超级块或块组描述符,有关⽂件系统结构和内容的所有信息都会丢失。如果有冗
余的副本,该信息是可能恢复的。
通过使⽂件和管理数据尽可能接近,减少了磁头寻道和旋转,这可以提⾼⽂件系统的性能。
不过,Ext2 的后续版本采⽤了稀疏技术。该做法是,超级块和块组描述符表不再存储到⽂件系统的每个块
组中,⽽是只写⼊到块组 0、块组 1 和其他 ID 可以表示为 3、 5、7 的幂的块组中。
11.目录是如何存储的
在前⾯,我们知道了⼀个普通⽂件是如何存储的,但还有⼀个特殊的⽂件,经常⽤到的⽬录,它是如何保
存的呢?
基于 Linux ⼀切皆⽂件的设计思想,⽬录其实也是个⽂件,你甚⾄可以通过 vim 打开它,它也有 inode,
inode ⾥⾯也是指向⼀些块。和普通⽂件不同的是,普通⽂件的块⾥⾯保存的是⽂件数据,⽽⽬录⽂件的块⾥⾯保存的是⽬录⾥⾯⼀项
⼀项的⽂件信息。
在⽬录⽂件的块中,最简单的保存格式就是列表,就是⼀项⼀项地将⽬录下的⽂件信息(如⽂件名、⽂件
inode、⽂件类型等)列在表⾥。
列表中每⼀项就代表该⽬录下的⽂件的⽂件名和对应的 inode,通过这个 inode,就可以找到真正的⽂件。

通常,第⼀项是「 . 」,表示当前⽬录,第⼆项是「 … 」,表示上⼀级⽬录,接下来就是⼀项⼀项的⽂件
名和 inode。
如果⼀个⽬录有超级多的⽂件,我们要想在这个⽬录下找⽂件,按照列表⼀项⼀项的找,效率就不⾼了。
于是,保存⽬录的格式改成哈希表,对⽂件名进⾏哈希计算,把哈希值保存起来,如果我们要查找⼀个⽬
录下⾯的⽂件名,可以通过名称取哈希。如果哈希能够匹配上,就说明这个⽂件的信息在相应的块⾥⾯。
Linux 系统的 ext ⽂件系统就是采⽤了哈希表,来保存⽬录的内容,这种⽅法的优点是查找⾮常迅速,插⼊
和删除也较简单,不过需要⼀些预备措施来避免哈希冲突。
⽬录查询是通过在磁盘上反复搜索完成,需要不断地进⾏ I/O 操作,开销较⼤。所以,为了减少 I/O 操
作,把当前使⽤的⽂件⽬录缓存在内存,以后要使⽤该⽂件时只要在内存中操作,从⽽降低了磁盘操作次
数,提⾼了⽂件系统的访问速度。
12.什么是软链接和硬链接
有时候我们希望给某个⽂件取个别名,那么在 Linux 中可以通过硬链接(Hard Link) 和软链接
(Symbolic Link) 的⽅式来实现,它们都是⽐较特殊的⽂件,但是实现⽅式也是不相同的。
硬链接是多个⽬录项中的「索引节点」指向⼀个⽂件,也就是指向同⼀个 inode,但是 inode 是不可能跨
越⽂件系统的,每个⽂件系统都有各⾃的 inode 数据结构和列表,所以硬链接是不可⽤于跨⽂件系统的。
由于多个⽬录项都是指向⼀个 inode,那么只有删除⽂件的所有硬链接以及源⽂件时,系统才会彻底删除
该⽂件。

软链接相当于重新创建⼀个⽂件,这个⽂件有独⽴的 inode,但是这个⽂件的内容是另外⼀个⽂件的路
径,所以访问软链接的时候,实际上相当于访问到了另外⼀个⽂件,所以软链接是可以跨⽂件系统的,甚
⾄⽬标⽂件被删除了,链接⽂件还是在的,只不过指向的⽂件找不到了⽽已。

文件IO
⽂件的读写⽅式各有千秋,对于⽂件的 I/O 分类也⾮常多,常⻅的有
缓冲与⾮缓冲 I/O
直接与⾮直接 I/O
阻塞与⾮阻塞 I/O VS 同步与异步 I/O
接下来,分别对这些分类讨论讨论
13.什么是缓冲与非缓冲IO
⽂件操作的标准库是可以实现数据的缓存,那么根据「是否利⽤标准库缓冲」,可以把⽂件 I/O 分为缓冲
I/O 和⾮缓冲 I/O:
缓冲 I/O,利⽤的是标准库的缓存实现⽂件的加速访问,⽽标准库再通过系统调⽤访问⽂件。
⾮缓冲 I/O,直接通过系统调⽤访问⽂件,不经过标准库缓存。
这⾥所说的「缓冲」特指标准库内部实现的缓冲。
⽐⽅说,很多程序遇到换⾏时才真正输出,⽽换⾏前的内容,其实就是被标准库暂时缓存了起来,这样做
的⽬的是,减少系统调⽤的次数,毕竟系统调⽤是有 CPU 上下⽂切换的开销的。
14.什么是直接与非直接IO
我们都知道磁盘 I/O 是⾮常慢的,所以 Linux 内核为了减少磁盘 I/O 次数,在系统调⽤后,会把⽤户数据
拷⻉到内核中缓存起来,这个内核缓存空间也就是「⻚缓存」,只有当缓存满⾜某些条件的时候,才发起
磁盘 I/O 的请求。
那么,根据是「否利⽤操作系统的缓存」,可以把⽂件 I/O 分为直接 I/O 与⾮直接 I/O:
直接 I/O,不会发⽣内核缓存和⽤户程序之间数据复制,⽽是直接经过⽂件系统访问磁盘。
⾮直接 I/O,读操作时,数据从内核缓存中拷⻉给⽤户程序,写操作时,数据从⽤户程序拷⻉给内核
缓存,再由内核决定什么时候写⼊数据到磁盘。
如果你在使⽤⽂件操作类的系统调⽤函数时,指定了 O_DIRECT 标志,则表示使⽤直接 I/O。如果没有
设置过,默认使⽤的是⾮直接 I/O。
15.如果⽤了⾮直接 I/O 进⾏写数据操作,内核什么情况下才会把缓存数据写⼊到磁盘?
以下⼏种场景会触发内核缓存的数据写⼊磁盘:
在调⽤ write 的最后,当发现内核缓存的数据太多的时候,内核会把数据写到磁盘上;
⽤户主动调⽤ sync ,内核缓存会刷到磁盘上;
当内存⼗分紧张,⽆法再分配⻚⾯时,也会把内核缓存的数据刷到磁盘上;
内核缓存的数据的缓存时间超过某个时间时,也会把数据刷到磁盘上;
16.阻塞与⾮阻塞 I/O VS 同步与异步 I/O
阻塞 I/O,当⽤户程序执⾏ read ,线程会被阻塞,⼀直等到内核数据准备好,并把数据从内核
缓冲区拷⻉到应⽤程序的缓冲区中,当拷⻉过程完成, read 才会返回。
注意,阻塞等待的是「内核数据准备好」和「数据从内核态拷⻉到⽤户态」这两个过程。过程如下图:

知道了阻塞 I/O ,来看看⾮阻塞 I/O,⾮阻塞的 read 请求在数据未准备好的情况下⽴即返回,可以继续往
下执⾏,此时应⽤程序不断轮询内核,直到数据准备好,内核将数据拷⻉到应⽤程序缓冲区, read 调⽤
才可以获取到结果。过程如下图:

注意,这⾥最后⼀次 read 调⽤,获取数据的过程,是⼀个同步的过程,是需要等待的过程。这⾥的同步指
的是内核态的数据拷⻉到⽤户程序的缓存区这个过程。
举个例⼦,访问管道或 socket 时,如果设置了 O_NONBLOCK 标志,那么就表示使⽤的是⾮阻塞 I/O 的
⽅式访问,⽽不做任何设置的话,默认是阻塞 I/O。
应⽤程序每次轮询内核的 I/O 是否准备好,感觉有点傻乎乎,因为轮询的过程中,应⽤程序啥也做不了,
只是在循环。
为了解决这种傻乎乎轮询⽅式,于是 I/O 多路复⽤技术就出来了,如 select、poll,它是通过 I/O 事件分
发,当内核数据准备好时,再以事件通知应⽤程序进⾏操作
这个做法⼤⼤改善了应⽤进程对 CPU 的利⽤率,在没有被通知的情况下,应⽤进程可以使⽤ CPU 做其他
的事情。
下图是使⽤ select I/O 多路复⽤过程。注意, read 获取数据的过程(数据从内核态拷⻉到⽤户态的过
程),也是⼀个同步的过程,需要等待

实际上,⽆论是阻塞 I/O、⾮阻塞 I/O,还是基于⾮阻塞 I/O 的多路复⽤都是同步调⽤。因为它们在 read
调⽤时,内核将数据从内核空间拷⻉到应⽤程序空间,过程都是需要等待的,也就是说这个过程是同步
**的,如果内核实现的拷⻉效率不⾼,**read 调⽤就会在这个同步过程中等待⽐较⻓的时间。
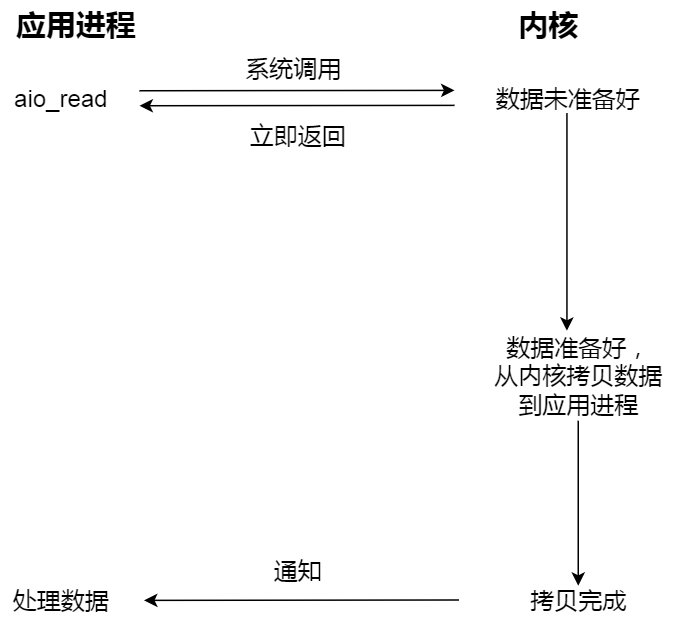
当我们发起 aio_read 之后,就⽴即返回,内核⾃动将数据从内核空间拷⻉到应⽤程序空间,这个拷⻉过
程同样是异步的,内核⾃动完成的,和前⾯的同步操作不⼀样,应⽤程序并不需要主动发起拷⻉动作。过
程如下图:
 、
、
下⾯这张图,总结了以上⼏种 I/O 模型
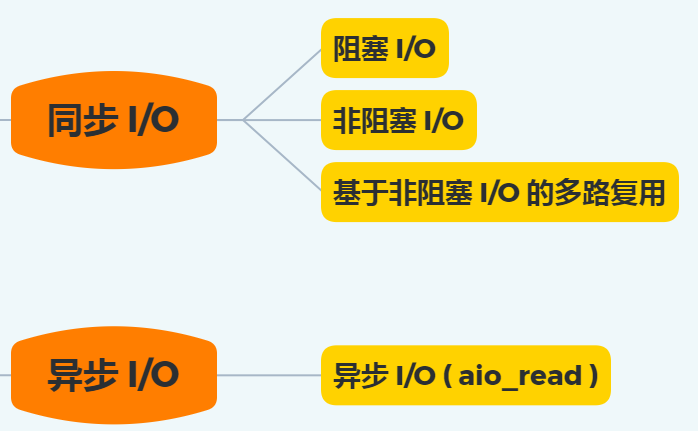
在前⾯我们知道了,I/O 是分为两个过程的:
- 数据准备的过程
- 数据从内核空间拷⻉到⽤户进程缓冲区的过程
阻塞 I/O 会阻塞在「过程 1 」和「过程 2」,⽽⾮阻塞 I/O 和基于⾮阻塞 I/O 的多路复⽤只会阻塞在「过程
2」,所以这三个都可以认为是同步 I/O。
异步 I/O 则不同,「过程 1 」和「过程 2 」都不会阻塞。






![P5677 [GZOI2017] 配对统计(线段树爆改莫队)](https://img-blog.csdnimg.cn/img_convert/b7c0b912489a4b46638cd9ae312f3cc6.png)