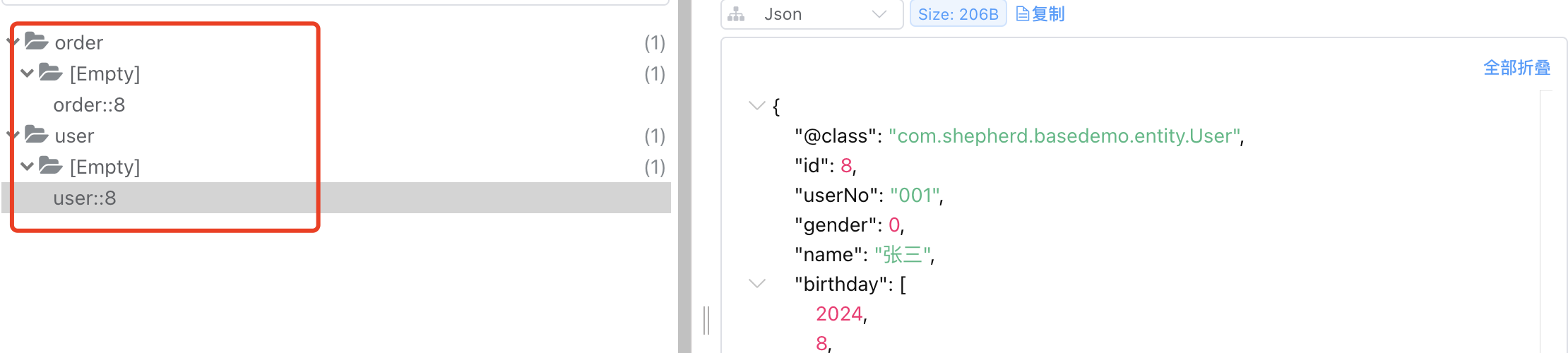
对图片/视频中的人脸进行检测,并绘制人脸框。然后对检测到的人脸进行关键点识别,并进行绘制。最后根据人脸关键点,裁剪出人脸,判断该人脸的表情。
基于此,分别使用retina进行人脸检测,PFLD进行人脸关键点识别,emotion-ferplus-8进行人脸表情的分类,它是基于微软的 FER+ 数据集训练的CNN分类网络,准确率约62%。



模型地址在文末...
代码如下,有详细的注释,注意修改一下自己的模型地址。
import sys
import os
import cv2
import numpy as np
import argparse
import logging.config
from torchvision import transforms
# 添加路径一次即可
sys.path.append('/data/ai/FaceSDK')
from core.image_cropper.arcface_cropper.FaceRecImageCropper import FaceRecImageCropper
from models.model_pipline import ModelLoader
# 配置日志
mpl_logger = logging.getLogger('matplotlib')
mpl_logger.setLevel(logging.WARNING)
logging.config.fileConfig("/data/ai/FaceSDK/config/logging.conf")
logger = logging.getLogger('api')
# 初始化模型加载器,加载模型
model_path = '/data/ai/FaceSDK/models'
model_loader = ModelLoader(model_path)
# 获取需要的模型处理器
faceDetModelHandler = model_loader.get_face_det_model_handler() # 人脸检测
faceAlignModelHandler = model_loader.get_face_align_model_handler() # 人脸对齐
face_cropper = FaceRecImageCropper() # 人脸裁剪
emo_model = cv2.dnn.readNetFromONNX('/data/ai/FaceSDK/models/emotion-ferplus-8.onnx') # 加载onnx人脸表情模型
logger.info(f"人脸表情识别模型加载成功....")
# 定义情感字典
emotion_dict = {
0: 'neutral',
1: 'happiness',
2: 'surprise',
3: 'sadness',
4: 'anger',
5: 'disgust',
6: 'fear'
}
def emotion_process(image_name, image):
dets = faceDetModelHandler.inference_on_image(image) # 人脸检测
face_nums = dets.shape[0]
bboxs = dets
for i in range(face_nums):
box = list(map(int, bboxs[i]))
cv2.rectangle(image, (box[0], box[1]), (box[2], box[3]), (0, 0, 255), 2) # 绘制人脸检测框
landmarks = faceAlignModelHandler.inference_on_image(image, bboxs[i])
for (x, y) in landmarks.astype(np.int32):
cv2.circle(image, (x, y), 2, (255, 0, 0), -1) # 绘制人脸关键点
landmarks_list = []
for (x, y) in landmarks.astype(np.int32):
landmarks_list.extend((x, y))
cropped_image = face_cropper.crop_image_by_mat(image, landmarks_list) # 裁剪人脸
# 调整尺寸并转换为单通道灰度图像
cropped_image = cv2.resize(cropped_image, (64, 64))
cropped_image = cv2.cvtColor(cropped_image, cv2.COLOR_RGB2GRAY) # 转换为灰度图像
blob = cv2.dnn.blobFromImage(cropped_image, scalefactor=1.0, size=(64, 64), mean=(0, 0, 0), swapRB=False,
crop=False)
# 确保输入张量的形状正确
if blob.shape[1:] != (1, 64, 64):
logger.error(f"Incorrect blob shape: {blob.shape[1:]}. Expected (1, 64, 64).")
continue
emo_model.setInput(blob)
try:
output = emo_model.forward()
except Exception as e:
logger.error(f"Error during model inference: {e}")
continue
pred = emotion_dict[list(output[0]).index(max(output[0]))] # 推理人脸表情
# 绘制情感标签
cv2.putText(
image,
pred,
(box[0], box[1] - 10),
cv2.FONT_HERSHEY_SIMPLEX,
0.8,
(215, 5, 247),
2,
lineType=cv2.LINE_AA
)
return image
def process_image(image_path, result_folder):
image_name = os.path.basename(image_path)
try:
image = cv2.imread(image_path, cv2.IMREAD_COLOR)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
processed_image = emotion_process(image_name, image)
result_path = os.path.join(result_folder, image_name)
cv2.imwrite(result_path, cv2.cvtColor(processed_image, cv2.COLOR_RGB2BGR))
logger.info(f"Result saved for image: {image_name}")
except Exception as e:
logger.error(f"Error processing image {image_path}: {e}")
def process_video(video_path, result_folder):
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
logger.error(f"Error opening video file {video_path}")
return
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
size = (frame_width, frame_height)
result_path = os.path.join(result_folder, 'result_video.avi')
result = cv2.VideoWriter(result_path, cv2.VideoWriter_fourcc(*'MJPG'), 10, size)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
processed_frame = emotion_process('frame', frame_rgb)
result.write(cv2.cvtColor(processed_frame, cv2.COLOR_RGB2BGR))
cap.release()
result.release()
logger.info(f"Result video saved to {result_path}")
def process_folder(folder_path, result_folder):
for image_name in os.listdir(folder_path):
image_path = os.path.join(folder_path, image_name)
process_image(image_path, result_folder)
def main(args):
# 检查并创建结果文件夹
if not os.path.exists(args.result_folder):
os.makedirs(args.result_folder)
if os.path.isdir(args.src):
process_folder(args.src, args.result_folder)
elif args.src.lower().endswith(('.mp4', '.avi', '.mov')):
process_video(args.src, args.result_folder)
else:
process_image(args.src, args.result_folder)
if __name__ == '__main__':
parser = argparse.ArgumentParser(description="Detect Face Emotion")
parser.add_argument('--src', type=str, required=True, help='path to detect data (image, video, or folder)')
parser.add_argument('--result_folder', type=str, required=True, help='path to save results')
args = parser.parse_args()
main(args)
运行脚本
python emotion_pipline.py --src /data/ai/FaceSDK/emotion/test\
--result_folder /data/ai/FaceSDK/emotion/result仓库地址:GitHub - JDAI-CV/FaceX-Zoo: A PyTorch Toolbox for Face Recognition















![[VBA]使用VBA在Excel中 操作 形状shape 对象](https://i-blog.csdnimg.cn/direct/a05e4b9e76b642ac906cd766e9258cd8.png)