原本是想借着之前学习的中断进一步拓展到网卡与中断的,标题都写好了,结果低估了其中的知识面和难度。。。。。于是调整为了网卡与Linux网络结构(上), 没错,仅仅只是上。。。我还是进一步低估了学习需要花费的时间,网络这块的确是弱项,以前都是死记硬背TCP的三次握手、四次挥手,这次正好乘着学习之际,好好从源码上理解这些概念,不过这些内容可能要放到中或者下了。。。
等这块学完了,后面才能轮到网卡与中断了。。自己期待中,努力学下去吧。
Linux内核网络设备驱动框架
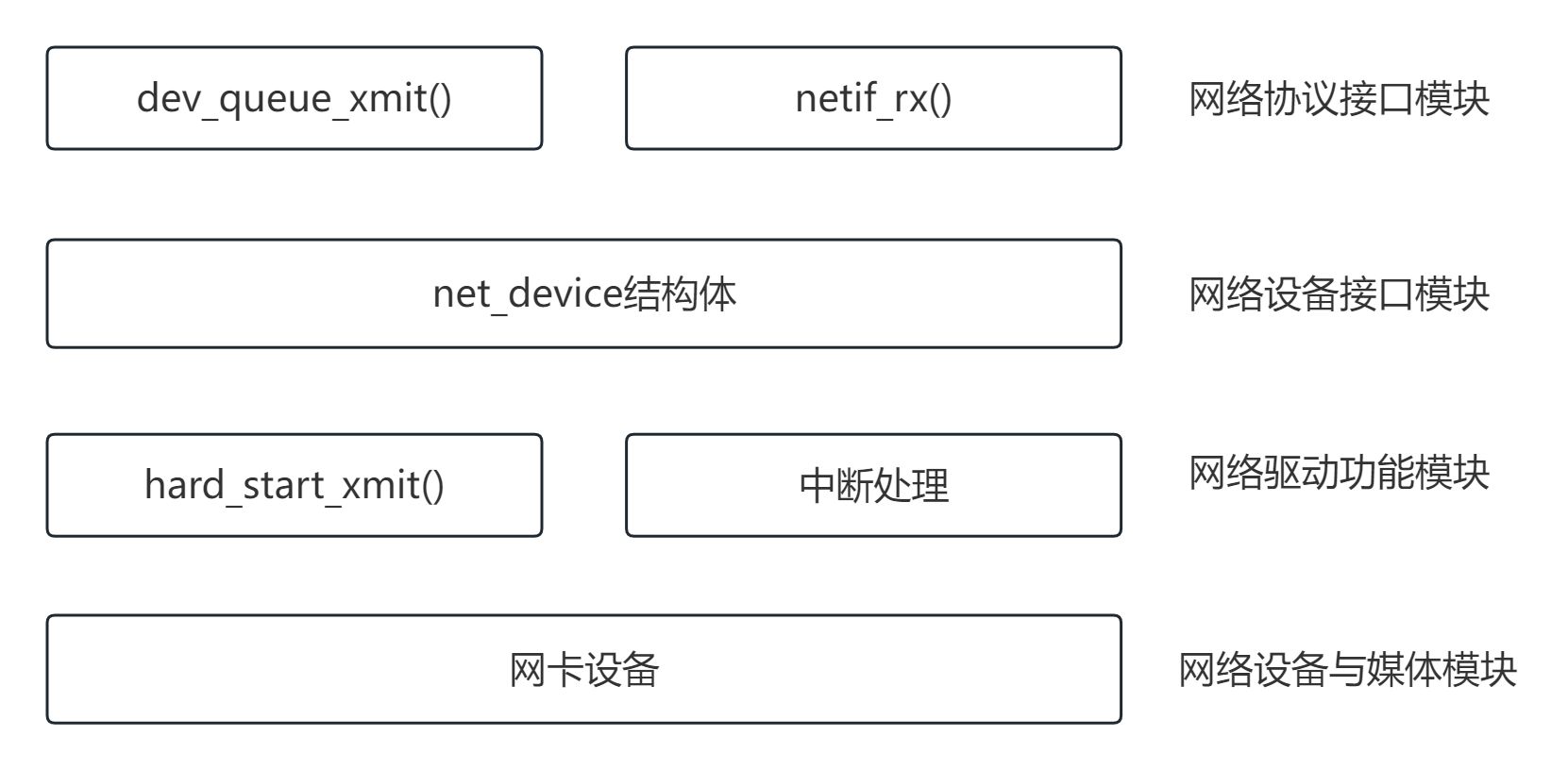
总计分成四个模块,分别为
1)网络协议接口层
主要功能给上层协议提供透明的数据包发送和接收接口,不论上层协议是ARP,还是IP,都通过dev_queue_xmit()函数发送数据,并通过netif_rx() /netif_receive_skb()函数接收数据。这一层的存在,使得上层协议独立于具体的设备。不管是发送还是接收数据包,都会使用到sk_buff结构体类型(套接字缓冲区), 主要用在网络子系统中的各层之间传输数据。
2)网络设备接口层
向协议接口层提供统一的用于描述具体网络设备属性和操作的结构体net_device,给结构体是设备驱动功能层中各函数的容器。实际上,网络设备接口层从宏观上规划了具体操作硬件设备驱动功能层的结构。
3)设备驱动功能层
设备驱动功能层的各函数是网络设备接口层net_device数据结构体的具体成员,是驱动网络设备硬件完成相应动作的程序,它通过hard_start_xmit()函数启动发送操作,并通过网络设备上的中断触发接收操作。
4)网络设备与媒介层
网络设备与媒介层是完成数据包发送和接收的物理实现,包括网络适配器和具体的传输媒介,网络适配器被设备驱动功能层中的函数在物理上驱动。对Linux系统而言,网络设备和媒介都可以是虚拟的。
在网络协议接口模块:主要功能给上层协议提供透明的数据包发送和接收接口,dev_queue_xmit()用于发送数据包,netif_rx()/netif_receive_skb()用于接收数据包。不管你发送还是接收数据包都会使用到sk_buff结构体类型(套接字缓冲区),主要用在网络子系统中的各层之间传输数据。
网络协议接口层代码
关键结构体sk_buff
sk_buff 是 Linux 内核网络栈中处理网络数据包的核心数据结构,涉及的操作包括数据包的分配、初始化、访问、处理和释放。理解 sk_buff 的结构和相关函数对于开发和调试网络驱动程序以及实现网络协议至关重要。sk_buff结构体的代码在200行左右。代码位于<include/linux/skbuff.h>
struct sk_buff {
union {
struct {
/* These two members must be first. */
struct sk_buff *next; //双向链表前一个sk_buff节点
struct sk_buff *prev; //双向链表后一个sk_buff节点
union {
struct net_device *dev; //从哪个网络设备上发送/接收
......
};
union {
struct sock *sk; //指明属于哪个socket
int ip_defrag_offset;
};
union { //数据包到达时间
ktime_t tstamp;
u64 skb_mstamp_ns; /* earliest departure time */
};
......
unsigned int len, //真真实的数据长度
data_len; //数据长度
__u16 mac_len, //数据链路层报文长度
......
__u16 inner_transport_header;
__u16 inner_network_header;
__u16 inner_mac_header;
//驱动接收的数据包的网络协议,封装由MAC头部的报文协议
__be16 protocol;
__u16 transport_header; //传输层报文头部
__u16 network_header; //网络层报文头部
__u16 mac_header; //数据链路层报文头部
......
sk_buff_data_t tail; //指向缓冲区数据的尾部
sk_buff_data_t end; //指向缓冲区的尾部
unsigned char *head, //指向缓冲区的头部
*data; //指向缓冲区数据的头部
......
};
skb_shared_info代码
skb_shared_info 结构体提供了在 sk_buff 数据包共享、分片、硬件时间戳等方面的管理能力。它通过引用计数、片段管理、时间戳和各种标志位,使得内核网络栈可以高效地处理复杂的网络数据包,特别是在支持硬件卸载和多片段数据包处理时,极大地提高了网络性能和效率。
代码位于<include/linux/skbuff.h>
struct skb_shared_info {
__u8 __unused; // 未使用的字段,可能用于对齐
__u8 meta_len; // 元数据长度
__u8 nr_frags; // 分片的数量
__u8 tx_flags; // 传输标志
unsigned short gso_size; // 大分组分片(GSO)的大小
unsigned short gso_segs; // GSO 分段数
struct sk_buff *frag_list; // 分片列表指针
struct skb_shared_hwtstamps hwtstamps; // 硬件时间戳
unsigned int gso_type; // GSO 类型
u32 tskey; // 时间戳键
atomic_t dataref; // 数据引用计数
void * destructor_arg; // 析构函数参数
skb_frag_t frags[MAX_SKB_FRAGS]; // 数据片段数组
};
常用操作函数
sk_buff使用alloc_skb/dev_alloc_skb用于动态分配。netdev_alloc_skb使用slab,可提高性能。
alloc_skb
alloc_skb 函数用于分配一个新的sk_buff 结构,这是 Linux 内核中用于网络数据包管理的基本结构。这个函数是一个内联函数,通过调用内部的__alloc_skb 函数来实际完成sk_buff 的分配。
static inline struct sk_buff *alloc_skb(unsigned int size,
gfp_t priority)
{
return __alloc_skb(size, priority, 0, NUMA_NO_NODE);
}
dev_alloc_skb
dev_alloc_skb 函数用于分配一个新的sk_buff 结构,这是 Linux 内核中用于网络数据包管理的基本结构。这个函数是一个内联函数,通过调用netdev_alloc_skb 函数来实际完成sk_buff 的分配。
static inline struct sk_buff *dev_alloc_skb(unsigned int length)
{
return netdev_alloc_skb(NULL, length);
}
netdev_alloc_skb
netdev_alloc_skb 函数用于分配一个新的sk_buff 结构,这是 Linux 内核中用于网络数据包管理的基本结构。这个函数是一个内联函数,通过调用__netdev_alloc_skb 函数来实际完成sk_buff 的分配。
static inline struct sk_buff *netdev_alloc_skb(struct net_device *dev,
unsigned int length)
{
return __netdev_alloc_skb(dev, length, GFP_ATOMIC);
}
概念注解:
代码注解中涉及到GSO,以前在排查问题过程中还曾经打开过GSO功能,因此顺便对该项技术做个mark。
GSO
GSO(Generic Segmentation Offload)是一种网络优化技术,主要用于提高网络传输效率。它允许网络协议栈在发送大数据包时推迟分片操作,将这个任务交给网络接口卡(NIC)来处理。GSO 的主要优点是在处理大数据包时,减少了 CPU 的负担,提高了网络传输性能。
GSO 的工作原理
在没有 GSO 的情况下,传输层协议(如 TCP)在发送数据时,需要将大数据包分成多个小片段,以适应网络层(如 IP)和链路层(如以太网)的 MTU(最大传输单元)限制。这一分片操作需要消耗 CPU 资源,并在数据传输路径上增加了额外的开销。
启用了 GSO 后,传输层协议可以生成一个大数据包,并将其交给网络栈。GSO 允许网络栈将这个大数据包直接交给网络接口卡,由网络接口卡在硬件层面进行分片和传输。这样,CPU 不需要进行逐包分片操作,从而提高了整体传输效率。
GSO 的关键特性
减少 CPU 开销:通过将分片操作从 CPU 转移到网络接口卡,减少了 CPU 的工作负载。
提高网络吞吐量:减少了分片操作的开销后,系统可以处理更多的数据包,从而提高了网络吞吐量。
简化软件栈:软件栈可以处理更大的数据包,减少了分片相关的复杂性。
GSO 的实现
在 Linux 内核中,GSO 是通过修改 sk_buff 结构体和相关的传输层协议实现的。sk_buff 结构体用于描述网络数据包,其中包含了 GSO 相关的字段,如 gso_size、gso_segs、gso_type 等。这些字段用于描述大数据包的大小、分段数和类型。
当一个大数据包通过传输层协议生成时,这些字段会被设置。网络栈在处理这个数据包时,会检查这些字段,并决定是否启用 GSO。如果启用了 GSO,数据包会直接传递到网络接口卡,由网络接口卡进行硬件分片和传输。
GSO 与 TSO 和 LRO 的关系
GSO 通常与其他网络优化技术一起使用,例如 TSO(TCP Segmentation Offload)和 LRO(Large Receive Offload):
TSO:类似于 GSO,但专门用于 TCP 协议。它允许网络接口卡处理 TCP 数据包的分片操作。
LRO:用于接收方向的优化,允许网络接口卡将多个小数据包合并成一个大数据包,以减少 CPU 处理开销。
网络设备接口模块常用数据结构
网络设备驱动程序只要设置net_device并注册,即可实现网络通讯功能。
net_device
net_device 结构体是 Linux 内核中用于描述网络设备的核心结构。它包含了网络设备的各种属性和操作函数,支持网络设备的初始化、配置、传输和接收数据等操作。net_device函数有近300行代码。
struct net_device {
char name[IFNAMSIZ]; //网络设备的名称
struct netdev_name_node *name_node; //网络设备名称节点
struct dev_ifalias __rcu *ifalias;
unsigned long mem_end; //共享内存的起始地址
unsigned long mem_start; //共享内存的结束地址
unsigned long base_addr; //I/O基地址
int irq; //中断号
struct list_head dev_list;
//此网络设备采用NAPI时,将NAPI结构体挂入到链表
struct list_head napi_list;
struct list_head unreg_list;
struct list_head close_list;
struct list_head ptype_all;
struct list_head ptype_specific;
......
};
NAPI结构体
NAPI数据包信息的循环流程如下:
数据接收中断发生---->关闭接收中断---->以轮询方式接收所有数据包或轮询权重耗尽---->开启接收中断---->数据接收中断发生---->......
napit结构体,通常用于网络子系统中,特别是在 Linux 内核中,用于处理网络数据包的接收。
napi_struct 主要用于优化网络中断处理,减少中断频繁导致的开销。下面是对这个结构体的详细分析:
struct napi_struct {
struct list_head poll_list; // NAPI poll 的链表节点
unsigned long state; // NAPI 状态标志
int weight; // NAPI 轮询的权重
int defer_hard_irqs_count; // 延迟硬件中断的计数
unsigned long gro_bitmask; // GRO (Generic Receive Offload) 的位掩码
int (*poll)(struct napi_struct *, int); // 指向 poll 函数的指针
#ifdef CONFIG_NETPOLL
int poll_owner; // poll 函数的拥有者标识
#endif
struct net_device *dev; // 关联的网络设备
struct gro_list gro_hash[GRO_HASH_BUCKETS]; // GRO 哈希桶,用于 GRO 数据包处理
struct sk_buff *skb; // 当前处理的网络数据包
struct list_head rx_list; // 挂起的 GRO_NORMAL 类型数据包的链表
int rx_count; // rx_list 中数据包的数量
struct hrtimer timer; // 用于定时处理的高精度定时器
struct list_head dev_list; // 网络设备链表,用于设备的管理
struct hlist_node napi_hash_node; // 用于 NAPI 的哈希表节点
unsigned int napi_id; // NAPI 的唯一标识符
KABI_RESERVE(1) // 保留字段,用于内核 ABI 兼容性
KABI_RESERVE(2)
KABI_RESERVE(3)
KABI_RESERVE(4)
};
入门级理解网络数据包传输
报文接收流程
step 1:网卡在收到数据包后,通过DMA将数据从网卡的硬件接收队列复制到操作系统的RX Ring指向的内存空间,随后产生硬中断。
step 2:网卡驱动为数据包申请sk_buff缓冲区对象后,将RX Ring所指向的内存空间复制至sk_buff对象。sk_buff对象是协议栈对报文的一种描述,此对象会贯穿整个协议栈。
step 3:驱动程序将sk_buff传递给内核协议栈,协议栈完成协议头解封装处理并根据传输层信息查询到接收此数据的socket对象,再将sk_buff对象插入socket对象的接收队列。
step 4:唤醒socket对象所属的用户态进程,在用户态进程请求网络数据时把数据从位于内核态内存空间的sk_buff对象复制到用户态内存空间。
报文发送流程
step 1:用户态应用程序执行socket发送函数,操作系统内核为要发送的数据申请sk_buff对象,并将数据从用户空间复制到sk_buff对象内
step 2:协议栈根据sk_buff对象对数据包进行协议头封装处理,并将数据包复制到TX Ring所指向的内存空间
step 3:网卡通过DMZ从TX Ring所指内存空间把封装后的数据包复制到网卡内部的发送队列TX Buf。
step 4:通过网卡固件将报文发送至外部网络。
网卡功能理解
随着当前高速网络、智能网络的建立,网卡功能也是越来越强大。传统的网卡芯片一般是ASIC架构,优点是价格便宜,但不够灵活,功能都是被写死的。因此现在开始流行智能网卡,这类网卡具有更多的卸载能力与灵活的可编程性.一般都是网卡芯片+可编程智能核的形式。可编程智能核有可分为ARM CPU核集成(SoC)、现场可编程门阵列(FPGA)、定制网络处理器采用的流处理核(P4)等三类。
一块物理网卡一般由如下几个部分组成:
网络接口芯片(NIC芯片):
控制器(Network Controller):网卡的核心部分,负责数据的处理和管理。包括数据包的收发、协议处理、错误检测和校正等功能。控制器通常内置处理器、缓存和DMA(直接内存访问)控制器,用于加速网络数据的传输。
PHY芯片(Physical Layer Chip):
物理层接口(PHY):将网络数据从数字信号转换为电气信号或光信号,以便通过物理介质(如以太网线、光纤)进行传输。PHY芯片处理数据的物理层特性,如信号调制和解调。
内存:
缓冲区(Buffers):存储临时的数据包,确保数据在发送和接收过程中的稳定性,防止数据丢失。
缓存(Cache):用于快速访问经常使用的数据,减少数据访问延迟,提高整体性能。
接口电路:
网络端口(Network Port):提供物理连接与外部网络设备的接口,如RJ45端口(以太网)或光纤接口(SFP+、QSFP+)。这些端口用于传输网络信号到网卡。
电气接口(Electrical Interface):负责信号的调节和处理,确保电信号的完整性和稳定性。
控制电路:
中断控制器(Interrupt Controller):管理网卡产生的中断信号,通知主机处理网络事件,如数据到达或传输完成,从而减少CPU负担。
状态指示灯(Status LEDs):显示网卡的工作状态,如连接状态、活动状态等,帮助用户监控网卡的运行情况。
硬件加速引擎:
RDMA引擎(Remote Direct Memory Access Engine):支持RDMA技术,允许直接在内存之间进行数据传输,减少延迟和CPU负载,适用于高性能计算和存储应用。
虚拟化引擎(Virtualization Engine):提供虚拟化支持,如SR-IOV(单根I/O虚拟化),允许多个虚拟机共享同一物理网卡,并保持高性能。
安全功能:
加密引擎(Encryption Engine):用于数据加密和解密,确保数据在传输过程中的安全性,防止数据泄露或篡改。
安全启动(Secure Boot):确保网卡固件的完整性和真实性,防止恶意固件或未经授权的代码运行。
固件和驱动程序:
固件(Firmware):内置于网卡中的程序,控制网卡的基本操作和高级功能,定期更新以提升功能和安全性。
驱动程序(Driver):安装在操作系统中的软件,负责操作系统与网卡之间的通信,支持各种操作系统如Windows、Linux等,确保网卡功能的正常运行。
网卡接收和发送数据流程
TCP/IP五层协议栈中的物理层和数据链路层协议通常集成在网卡中,操作系统负责实现网络层和传输层协议。
网卡接收和发送数据在Linux内核当中的处理流程。
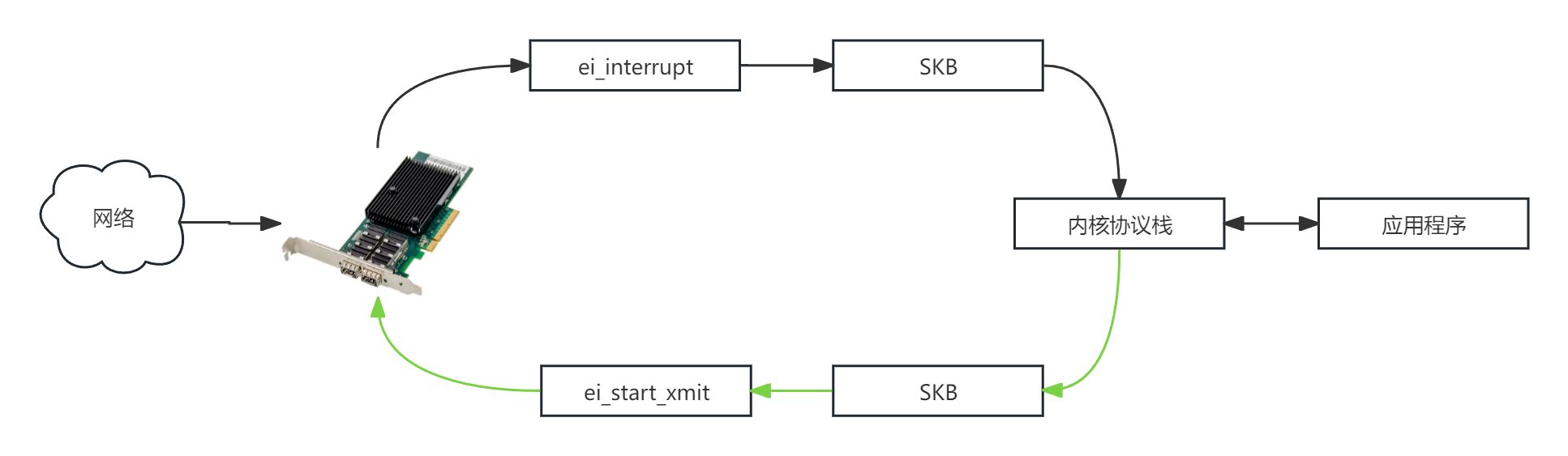
Linux内核直接把中断分为两个部分:中断上半部和中断下半部。
套接字
网卡实现了TCP/IP网络协议栈的物理层和数据链路层,网络层和传输层则由操作系统实现。从TCP/IP的网络协议栈可知,网络层使用IP地址定位网络中的主机,而传输层使用端口定位主机中的进程。在进程和协议栈之间还有着一套接口,即套接字(socket)
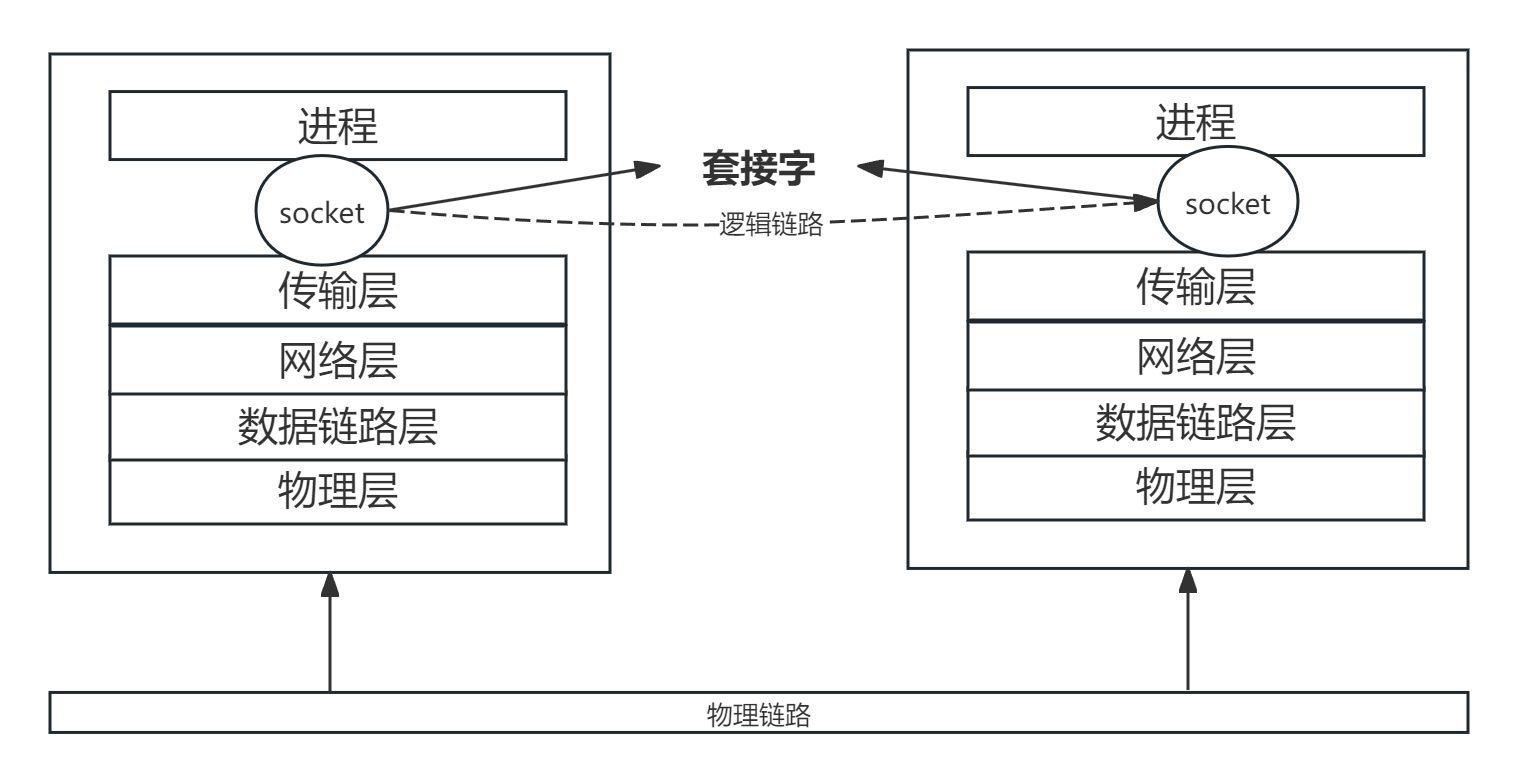
套接字(Socket)是网络编程中的一个抽象概念,它将复杂的网络通信过程简化为一个统一的接口,使得应用程序能够通过它进行数据传输。它是一种编程接口,提供了一组系统调用,使得应用程序可以方便地与网络协议栈交互。
套接字的类型有三种:
流式套接字 (SOCK_STREAM):
基于TCP协议,提供面向连接的、可靠的、按序的、无数据丢失的数据传输。使用流式套接字需要进行TCP三次握手以建立可靠连接,并通过四次挥手关闭连接。
适用于需要高可靠性的数据传输场景,如网页浏览、文件传输等。
数据报套接字 (SOCK_DGRAM):
基于UDP协议,提供无连接的、尽力而为的数据传输。
适用于实时性要求高但对数据丢失不敏感的场景,如视频会议、在线游戏等。
原始套接字 (SOCK_RAW):
允许直接访问底层协议,主要用于开发新的网络协议或需要自定义处理的场景。
套接字底层实现
内核空间与用户空间:
套接字作为用户空间与内核空间之间的桥梁,提供了一种机制,使得应用程序可以通过系统调用与内核中的网络协议栈交互。
缓冲区管理:
每个套接字都有发送和接收缓冲区,负责存储待发送和已接收的数据。这些缓冲区的管理和内存分配由操作系统负责。
协议栈集成:
套接字与操作系统中的网络协议栈紧密结合。数据从应用程序通过套接字发送后,进入协议栈,由TCP/IP协议负责分段、封装、路由和传输,最终通过网络接口发送到目标机器。
中断和上下文切换:
数据包的接收通常通过中断机制触发,当网卡接收到数据包时,会触发中断,操作系统将数据包从网卡复制到接收缓冲区,并唤醒等待数据的应用程序。
套接字的高级功能
非阻塞模式:
套接字可以配置为非阻塞模式,使得系统调用不会阻塞,适用于需要高性能和响应速度的应用程序。
多路复用:
使用select()、poll()或epoll()等系统调用,可以同时监视多个套接字的状态,实现高效的事件驱动编程。
安全性:
通过SSL/TLS协议,可以在套接字通信中加入加密和认证,确保数据传输的安全性。
socket连接
连接概念
两个主机通过TCP通讯时需要建立虚拟链路,所谓虚拟链路,是指通信双方之间的一个连接。TCP/IP下的socket使用IP地址和端口号的组合标识通信实体,即可用四元组标识:源IP、源端口、目标IP、目标端口。连接由server端和client端构成一对socket唯一标识。此外在网络应用中,一个server端可以与多个client建立连接,即建立socket。因此server端的一个socket可以绑定多个连接。遵循UNIX一切皆文件的思想,每一个socket都对应了一个文件描述符fd(FileDescriptor)。
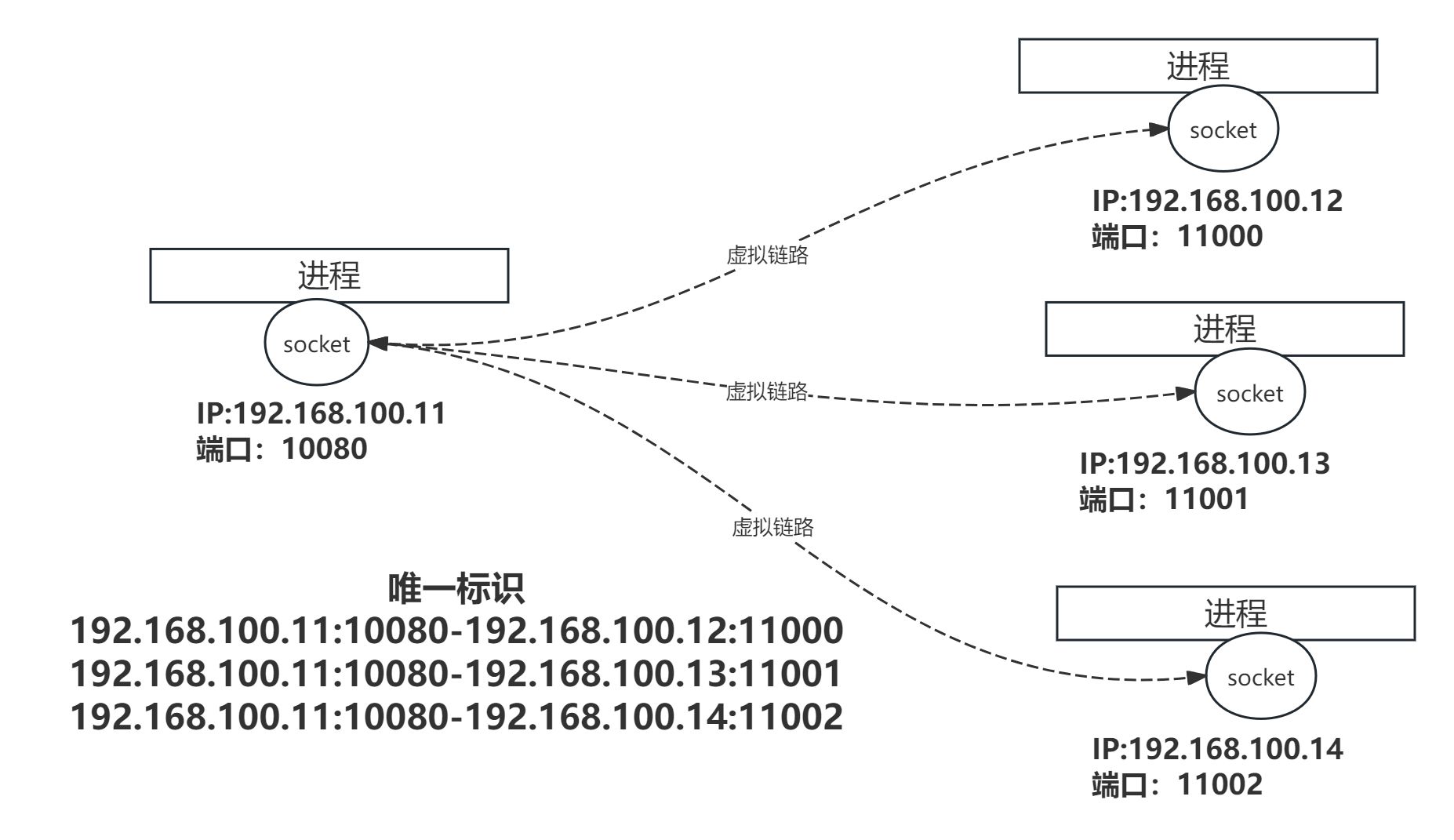
连接状态
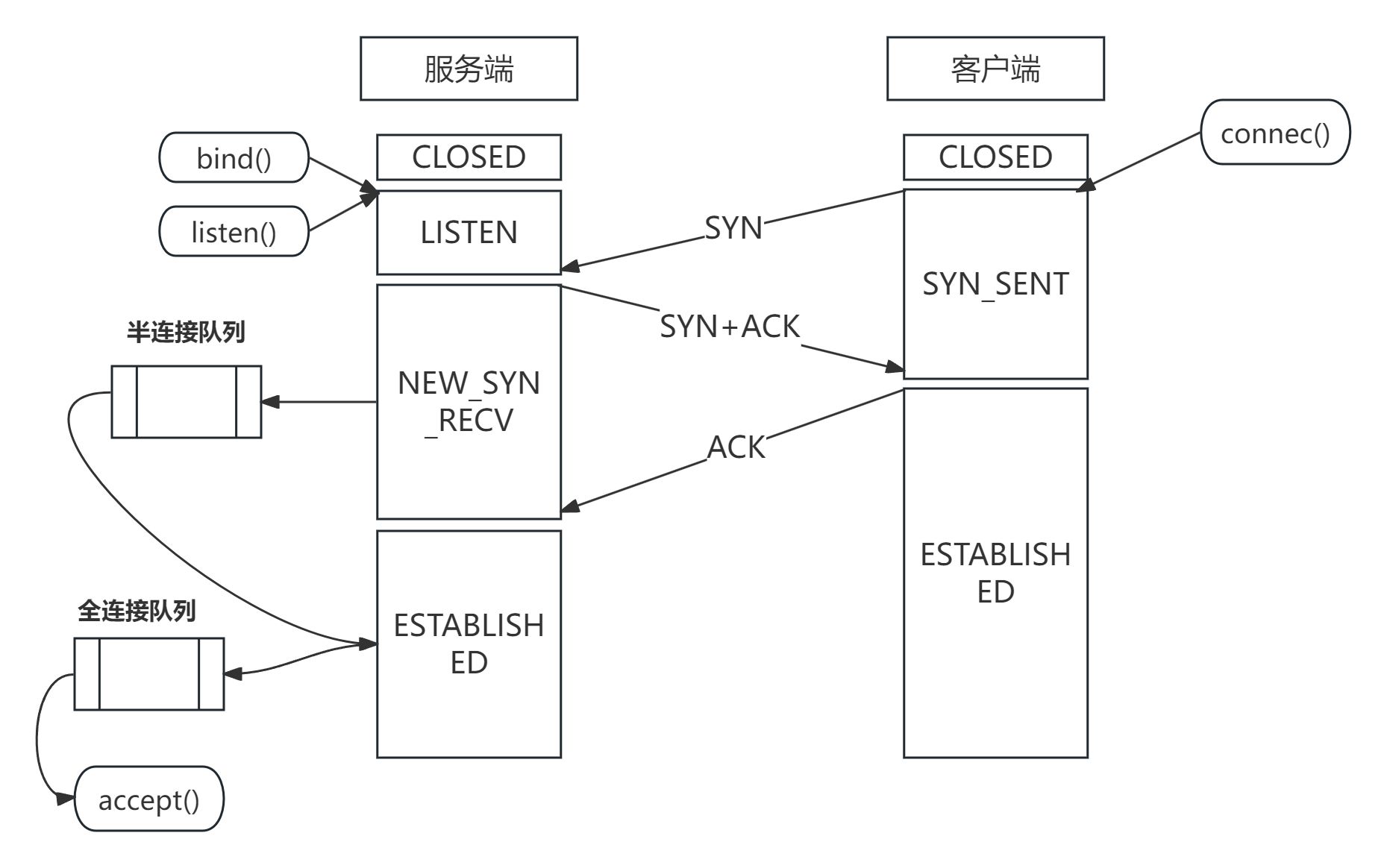
采用流式socket进行通信是,一次TCP连接的生命周期从建立到关闭有多个状态,如TCP_LISTEN、TCP_ESTABLISHED等。可参见源码部分<include/net/tcp_states.h>
enum {
TCP_ESTABLISHED = 1, // 双方建立连接后的状态
TCP_SYN_SENT, // 客户端发送 SYN 包,请求建立连接
TCP_SYN_RECV, // 服务器接收到 SYN 包,并回复 SYN+ACK 包
TCP_FIN_WAIT1, // 一方主动关闭连接,发送 FIN 包,并等待对方的 ACK
TCP_FIN_WAIT2, // 已接收到对方的 ACK,等待对方发送 FIN 包
TCP_TIME_WAIT, // 收到对方的 FIN 包,并发送 ACK,等待足够时间以确保对方接收到 ACK
TCP_CLOSE, // 连接已关闭
TCP_CLOSE_WAIT, // 收到对方的 FIN 包,等待应用程序关闭连接
TCP_LAST_ACK, // 应用程序已关闭连接,等待最后的 ACK 包
TCP_LISTEN, // 服务器在监听连接请求
TCP_CLOSING, // 双方同时关闭连接,等待所有 FIN 包和 ACK 包传输完成
TCP_NEW_SYN_RECV, // 接收到新的 SYN 包,还未完全进入 ESTABLISHED 状态
TCP_MAX_STATES // 枚举值的最大数量,用于计数
};
连接队列
单个CPU的服务器在同一时间只能处理一个连接,因此当有多个客户端尝试与服务端建立连接时,会通过两个连接队列缓存连接请求,分别为半连接队列(syns_queue)和连接队列(accept_queue)。
当服务端收到客户端的SYN(第一次握手)请求时,会创建一个socket并将其存入半连接队列。
当服务端接收到客户端的ACK(第三次握手)请求时,它会将该socket从半连接队列中取出并存入全连接队列。
最后由函数accept()从全连接队列中获取已建立连接的socket并返回。