随着 Web 技术的飞速发展,用户对网站的要求越来越高,为了达到用户期望,开发者使出了浑身解数来做性能优化,包括 CDN 内容分发、图片合并、资源文件压缩、异步加载等等手段,这些手段绝大部分都是在干一件事情,那就是加快资源的加载速度,尽量减少白屏时间。而 service worker 的出现不仅能使页面达到秒开的效果,还能让网站在弱网甚至无网的情况下依然能做出很好的响应。让从前只有原生 APP 才可以做到的离线使用功能。在web页面上也能实现。
Service Worker是什么?
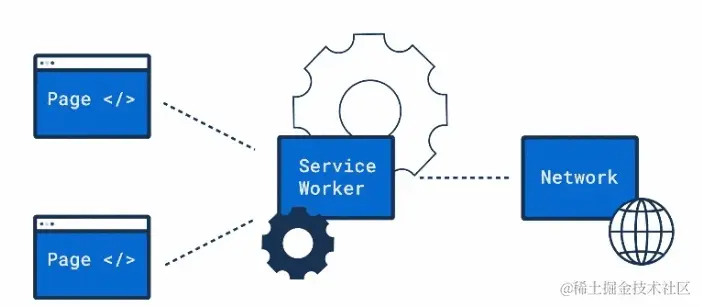
官方解释:Service Worker是一种特殊的 Web worker,是浏览器运行在后台与网页主线程独立的另一个线程,这种工作子线程的出现通常都是为了做一些比较耗费性能的计算,有需要的时候再跟主线程通信,告知主线程它的计算结果,这样将计算和渲染独立开来,从而就避免了阻塞的情况。
通俗理解:
Service Worker 是一种能够在后台运行的独立于网页的脚本,它能够拦截和处理网络请求,然后根据一些条件来决定是请求本地的缓存还是云端的服务,再把请求到的内容写入本地的缓存来管理,所以即使在突然断网的情况下它也能向用户显示内容。
特点
-
独立于主线程:运行在独立的线程中,不会阻塞或干扰主线程的运行。
-
生命周期:有明确的生命周期,包括安装、激活、运行等状态。
-
拦截网络请求:可以拦截网页的网络请求,并通过编程接口处理这些请求,比如返回缓存的数据或发起新的网络请求。
-
离线缓存:通过缓存管理,可以让应用在离线状态下仍然能正常工作。
-
推送通知:支持接收和展示推送通知,即使用户没有打开相关网页。
-
不能直接访问/操作DOM
-
需要时直接唤醒,不需要时休眠
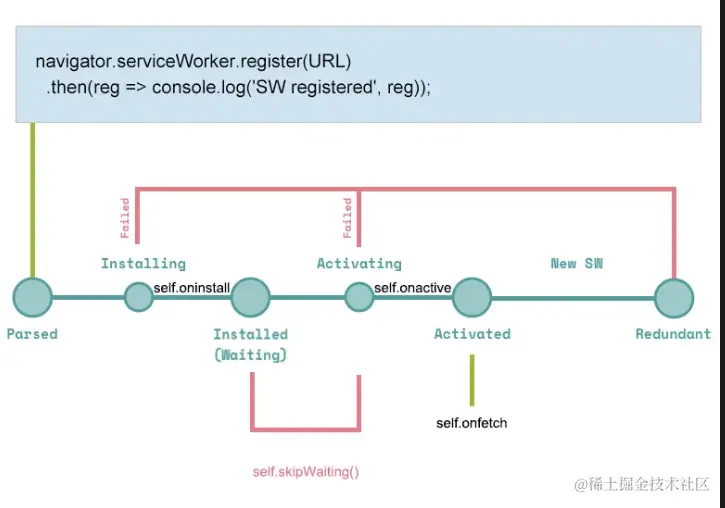
Service Worker的生命周期
-
安装(Installation):
浏览器首先下载并解析编译 Service Worker 的脚本文件。一旦解析和编译成功,Service Worker 进入安装阶段。在此阶段,可以通过监听
install事件来执行初始化操作,例如预加载和缓存资源。 -
激活(Activation):
安装完成后,Service Worker 会被激活。在此阶段,可以监听
activate事件来执行必要的清理操作,例如删除旧版本的缓存资源。 -
运行(Running):
激活后,Service Worker 持续运行在浏览器后台,等待处理来自网页的请求。它可以拦截和处理网络请求、提供离线支持等。
-
终止(Termination):
当所有包含该 Service Worker 的页面被关闭时,Service Worker 会被终止。浏览器可以根据资源利用情况随时中止它,以节省内存。
Service Worker 的基本用法
1. 注册 Service Worker
首先需要在主线程中注册 Service Worker:
if ('serviceWorker' in navigator) { // 检查浏览器是否支持 Service Worker
navigator.serviceWorker.register('/service-worker.js') // 注册 Service Worker,并指定文件路径
.then(function(registration) { // 注册成功时的回调函数
console.log('Service Worker 注册成功:', registration); // 输出成功信息和注册对象
})
.catch(function(error) { // 注册失败时的回调函数
console.log('Service Worker 注册失败:', error); // 输出错误信息
});
}navigator.serviceWorker.register 方法注册 Service Worker 时,可以传递一个可选的 scope 参数。该参数用于配置 Service Worker 的作用范围。
默认情况下,Service Worker 的作用范围是注册它的脚本的同级路径及其所有子路径。例如,若注册脚本的 URL 为 ./serviceWorker.js,则其作用范围为 ./ 路径下的所有页面。当然我们也可以通过配置 scope 参数来调整 Service Worker 的作用范围。但是此参数的值必须以/结尾。我们可以通过配置 { scope: './article/' } ,让 ServiceWorker 只作用于页面路径为 /article/ 以及子路径的页面。
注意: Service Worker 是事件驱动的,它会在特定事件触发时启动并执行相应的逻辑。为了节省内存,Service Worker 在不使用时会被浏览器休眠。一旦被休眠,它不会持久保存任何数据,因此需要在重新启动时重新获取所需的数据。
2. 安装阶段
在 service-worker.js 文件中处理安装事件,通常在此阶段主要的工作内容是缓存常用的资源:包括主页文件、样式表、脚本文件以及其他常用的文件。这样可以确保用户即使在离线状态下,也能够访问这些资源,
self.addEventListener('install', function(event) { // 监听 Service Worker 的安装事件
event.waitUntil( // 使用 event.waitUntil 来确保 Service Worker 在完成任务前不会终止
caches.open('my-cache-v1').then(function(cache) { // 打开一个名为 'my-cache-v1' 的缓存空间
return cache.addAll([ // 将指定的资源列表添加到缓存中
'/', // 缓存网站的根路径
'/index.html', // 缓存主页文件
'/styles.css', // 缓存样式表文件
'/script.js', // 缓存 JavaScript 脚本文件
'/image.png' // 缓存图片文件
]);
})
);
});3. 激活阶段
在激活阶段,我们可以清理旧的缓存。每当资源更新时,我们都需要清除掉的缓存的数据,以节省存储空间,并确保用户获取到的是最新资源。在 activate 事件中处理缓存的管理,可以防止旧的缓存干扰新的应用逻辑。
self.addEventListener('activate', function(event) { // 监听 Service Worker 的激活事件
event.waitUntil( // 使用 event.waitUntil 确保任务在 Service Worker 激活前完成
caches.keys().then(function(cacheNames) { // 获取所有缓存的名称
return Promise.all( // 等待所有删除旧缓存的操作完成
cacheNames.filter(function(cacheName) { // 过滤出不是当前版本缓存的名称
return cacheName !== 'my-cache-v1'; // 当前版本缓存的名称为 'my-cache-v1'
}).map(function(cacheName) { // 映射每个不需要的缓存名称
return caches.delete(cacheName); // 删除不再需要的缓存
})
);
})
);
});4. 拦截网络请求
我们可以在在 fetch 事件中拦截页面的网络请求并决定如何响应。它可以优先从缓存中查找匹配的资源,如果缓存中有则返回缓存的内容;否则发起网络请求获取资源。这种策略不仅可以提高我们的页面加载速度,还可以在离线的情况下提供给用户展示基本的信息。
self.addEventListener('fetch', function(event) { // 监听页面的网络请求事件
event.respondWith( // 使用 event.respondWith 来提供自定义的响应
caches.match(event.request).then(function(response) { // 在缓存中查找请求匹配的资源
return response || fetch(event.request); // 如果缓存中有匹配的资源,则返回缓存资源;否则发起网络请求
})
);
});5. 推送通知
我们还可以通过Service Worker来处理推送通知,他的优点是即使用户不在网站上也可以收到通知。当收到推送事件时,Service Worker 可以显示一条通知,通知内容可以根据推送数据或默认设置来决定。
self.addEventListener('push', function(event) { // 监听推送通知事件
const title = '推送通知'; // 定义通知的标题
const options = { // 定义通知的选项
body: event.data ? event.data.text() : '您有新消息', // 如果推送消息有数据,使用数据内容作为通知正文;否则显示默认消息
icon: '/icon.png', // 通知的图标
badge: '/badge.png' // 通知的徽章图标
};
event.waitUntil( // 确保在显示通知前完成任务
self.registration.showNotification(title, options) // 显示通知
);
});