文章目录
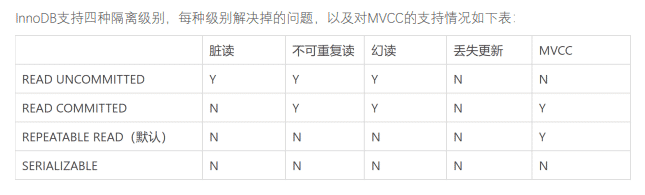
- 扁平化处理
- 扁平化处理导致的检索问题
- 解决方案:使用 nested 结构
在es的数据类型中有一个nested类型,本讲将重点讨论这个类型。
扁平化处理
PUT my_index/doc/1
{
"group" : "fans",
"user" : [
{
"first" : "John",
"last" : "Smith"
},
{
"first" : "Alice",
"last" : "White"
}
]
}

如图所示,有一个名为 my_index 的索引,其中包含一个文档,该文档有一个名为 group 的字符串字段和一个名为 user 的数组字段,该数组包含两个对象。
首先看看如何在 Elasticsearch 中处理此数据,然后讨论如何解决扁平化处理带来的挑战。
默认情况下,Elasticsearch 将尝试将数组内的对象展平。在这种情况下,Elasticsearch 可能会将 user 数组展平为以下形式:
{
"group": "fans",
"user.first": ["John", "Alice"],
"user.last": ["Smith", "White"]
}
然而,这种扁平化处理并不能很好地反映原始数据结构,因为它丢失了用户对象的上下文。
扁平化处理导致的检索问题
因此,我们在查询时会遇到下面的问题。
GET my_index/_search
{
"query": {
"bool": {
"must": [
{"match": {"user.first": "Alice"}},
{"match": {"user.last": "Smith"}}
]
}
}
}

在扁平化处理下,user 数组中的对象会被展平为单独的字段,例如 user.first 和 user.last。这意味着每个用户对象的属性都会被拆分为独立的字段,而不是作为一个整体存储。
在给定的查询中,要匹配一个 user 对象,其中 first 属性等于 “Alice”,last 属性等于 “Smith”。由于扁平化处理,user.first 和 user.last 字段分别包含 “John”、“Alice” 和 “Smith”、“White”,而不是完整的 “Alice Smith”。
在扁平化处理的情况下,这个查询可能会返回错误的结果,即使文档中不存在一个完整的 “Alice Smith” 用户。这是因为查询引擎会将 “Alice” 和 “Smith” 视为独立的关键词,而不是一个完整的姓名。因此,只要文档中存在一个 user.first 匹配 “Alice” 和一个 user.last 匹配 “Smith”,无论它们是否来自同一个用户对象,都会被视为匹配项。
对于上图中的查询,语义是要查找一个叫做“Alice Smith”的人,实际上并没有这样一个人,但是因为ES的扁平化处理,检索过程如下:
- 首先会在
user.first中查找Alice,能够匹配到一条记录 - 接着在
user.last中查找Smith,也能够匹配到
最后能查到两条记录,与预期不符。
解决方案:使用 nested 结构
为了避免这些问题,我们可以使用 nested 类型来存储 user 数组。以下是使用 nested 类型的映射定义:
PUT my_index
{
"mappings": {
"properties": {
"group": { "type": "keyword" },
"user": {
"type": "nested",
"properties": {
"first": { "type": "keyword" },
"last": { "type": "keyword" }
}
}
}
}
}
现在,我们可以将相同的数据插入到索引中,但这次使用 nested 结构:
PUT my_index/doc/1
{
"group": "fans",
"user": [
{ "first": "John", "last": "Smith" },
{ "first": "Alice", "last": "White" }
]
}
使用 nested 结构的好处在于,它可以保留数组中每个对象的完整结构。这意味着我们可以对 user 数组中的单个元素执行更复杂的查询,而不仅仅是简单的过滤。
例如,我们可以查询姓氏为 White 的用户:
GET my_index/_search
{
"query": {
"nested": {
"path": "user",
"query": {
"term": {
"user.last.keyword": "White"
}
}
}
}
}
上述查询将返回所有包含至少一个姓氏为 White 的用户。
使用 nested 结构可以帮助我们更好地处理对象数组,特别是当我们需要执行更复杂的查询时。虽然 nested 结构可能会带来更高的存储成本和查询性能影响,但它提供了更大的灵活性和准确性。