HTTP/2.0默认长连接。选B
ABC
- 一个类可以实现多个接口,一个接口可以继承一个或多个接口:
- 这是正确的。Java 支持多重继承的变体,即一个类可以实现多个接口,以获取多个接口中定义的方法。同时,一个接口可以通过
extends关键字继承一个或多个其他接口。- 定义接口使用 interface 关键字, 实现接口使用 implements 关键字:
- 这也是正确的。在 Java 中,我们使用
interface关键字来定义一个接口,使用implements关键字来表明一个类实现了某个接口。- 接口中的方法默认是公共的(public)和抽象的(abstract),并且可以省略:
- 这个描述也是正确的。在接口中定义的所有方法默认都是
public和abstract的。由于它们默认就是public和abstract的,所以这些关键字在接口中可以省略。- 接口中的方法都是抽象的,没有方法体,且接口中不能定义静态方法:
- 这个选项部分正确,但后半部分“且接口中不能定义静态方法”是错误的。从 Java 8 开始,接口中允许定义静态方法,这些静态方法可以有方法体,并且它们不属于接口的默认方法(default methods)或抽象方法。静态方法使用
static关键字声明,并且可以用public或默认(即省略public)修饰。因此,接口中可以定义静态方法,只是这些静态方法不是抽象方法。
AB
- 可以使用布隆过滤器这种采用位图的概率数据结构来计算半连接结果的有效值:
- 这个说法是正确的。布隆过滤器(Bloom Filter)是一种概率型数据结构,用于高效地插入和查询元素是否存在。虽然它不能提供100%的准确性(可能会存在误判),但在处理大数据集时非常有效。在跨多个数据源的查询中,特别是在需要估算或过滤大量数据时,布隆过滤器可以被用来优化查询性能,例如通过减少需要详细检查的数据量。
- 不同数据源能够支持不同的查询功能:
- 这个说法也是正确的。在实际应用中,不同的数据源(如关系型数据库、NoSQL数据库、文件系统等)通常具有不同的查询能力和限制。因此,在跨多个数据源进行查询时,需要考虑到这些差异,并设计合适的查询策略。
- 如果数据源是支持SQL的数据库,那么无法在数据源上执行连接或聚集等运算:
- 这个说法是错误的。支持SQL的数据库通常都具备执行连接(JOIN)、聚集(如GROUP BY、SUM、AVG等)等复杂查询运算的能力。这些运算可以直接在数据库上执行,以提高查询效率和减少数据传输量。跨数据源查询时,如果数据源支持SQL,则应该尽可能利用这些能力来优化查询过程。
- 分布式查询优化主要可以分为1) 将数据的位置记录为数据的物理性质,2) 跟踪运算符的执行位置,3) 采用半连接运算:
- 这个说法大致正确,但更准确地说,它描述了分布式查询优化中的一些关键方面。分布式查询优化确实需要考虑数据的物理分布(即数据的位置)、运算符的执行位置以及采用合适的连接策略(如半连接)来减少数据传输和计算成本。
B不符合,right join user_profile会导致没有重复的学校也保留。
BCD
C
C
小红书笔试-选择题
news2026/2/15 6:40:34























本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1980505.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

假如家里太大了,wifi连不上了怎么办
最近有个土豪朋友抱怨,他家里太大了,一个路由器的Wi-Fi信号根本无法覆盖他们家的每个房间,都没办法上网看奥运会比赛了。(还好我是穷人,就没有这种烦恼T_T)。
然后我问他为何不用一个路由器作主路由器&…
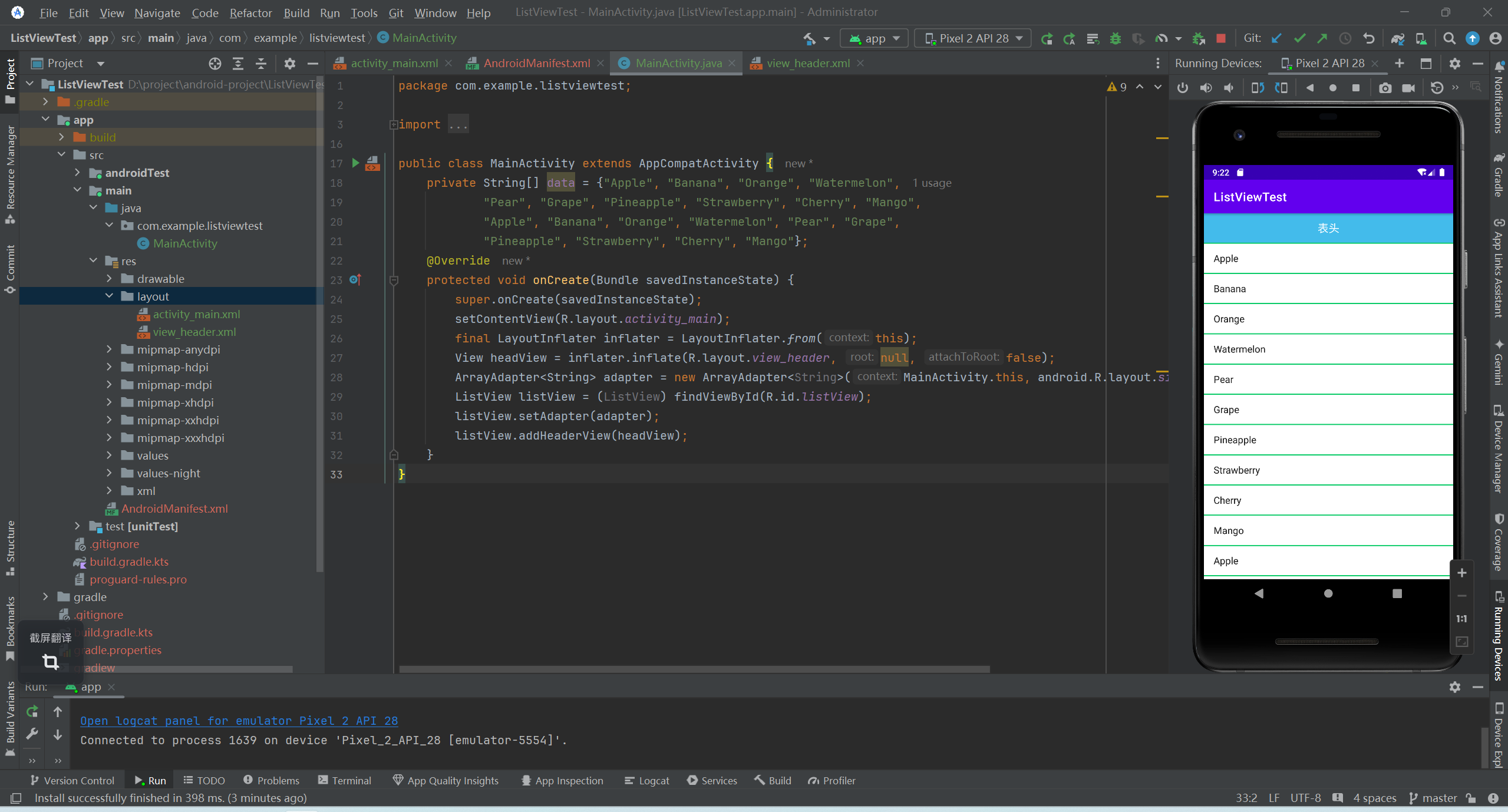
安卓常用控件ListView
文章目录 ListView的常用属性ListView的常用APIListView的简单使用 ListView是一个列表样式的 ViewGroup,将若干 item 按行排列。它是一个很基本的控件也是 Android 中最重要的控件之一。它可以实现多个 View 的垂直排列并支持滚动显示效果。 ListView的常用属性
常…

数论——绝对素数、素数筛法、埃氏筛法、欧拉筛法、最大公约数
绝对素数
绝对素数是指一个素数在其十进制表示下,无论是从左向右读还是从右向左读,所得到的数仍然是素数。
例如,13 是一个素数,从右向左读是 31,31 也是素数,所以 13 是一个绝对素数。
#include <io…

小红书无货源选品逻辑和爆品思路(图文解析)
了解用户的购物习惯、需求偏好以及日常搜索行为,是选品的重要前提。选品不是嘴巴一张这么简单的事情,是需要通过长期积累及网感来分析。记住:人-货-场,这个原则。比如明知道小红书上的年前女性用户多,你偏偏来卖一台挖…

悠易科技周文彪:创始人专注度很重要,一旦战略分散无法形成合力 | 中国广告营销行业资本报告深访④
周文彪(悠易科技CEO) 问:近年来广告营销行业主要的融资事件发生在营销技术领域。您对此有何评论? Roy:Adtech最早从2007年前后开始发展,差不多十年的时间,因为广告技术帮助企业成长,…

【时时三省】unity test 测试框架 使用 code blocks 移植(核心文件:unity.c, unity_fixture.c)
山不在高,有仙则名。水不在深,有龙则灵。 ----CSDN 时时三省
目录
1,移植介绍
2,使用 Code::Blocks 17.12 创建工程
3,搬移文件入工程目录
4,更改代码
5,向工程添加文件
6,运…

解锁PDF新姿势:2024年PDF转图片工具精选
随着数字化办公的普及和文档处理需求的日益增长,PDF转图片工具已成为日常工作中不可或缺的一部分。这些工具不仅帮助用户轻松地将PDF文件转换为图片格式,还提供了丰富的编辑、转换和批量处理功能,极大地提高了工作效率。
1.福昕PDF转换大师&…

数据结构实验报告-栈
实 验 三 报 告 一、实验目的
1.掌握栈的定义、特点、逻辑结构,理解栈的抽象数据类型。
2.熟练掌握顺序栈的结构类型定义、特点和基于顺序栈的基本运算的实现。
3.熟练掌握链栈的结构类型定义、特点和基于链栈的基本运算的实现。
4.理解递归算法执行过程中栈的…

ssh网络协议(服务名sshd,端口22)
目录
前言
配置文件(/etc/ssh/sshd_config)
配置文件内容
自己可以添加的设置:
注意!:
ssh连接登录演示
scp文件传输
登录验证方式
密码验证登录
秘钥验证登录
配置ssh密钥对验证登录
生成密钥对ÿ…


海尔、希亦、米博洗地机哪个好用?海尔、希亦、米博洗地机实测PK
洗地机相比普通清洁工具,拥有科学的设计,而且清洁技术专业,能够把地面上的污渍、灰尘、毛发等通通清理干净,保持地面光洁。比起手动清理,它还能减少地面和空气的细菌滋生,可以说是居家必备的清洁神器了。不…

C# 实现改造 GooFlow 流程图插件与数据库应用的结合
目录
关于 GooFlow
功能需求
范例运行环境
设计数据表
流程项目表
流程项目节点明细表
流程项目节点审批人表 人员信息表
示例代码
流程图主功能
设置审批人信息
运行结果演示 总结 关于 GooFlow
GooFlow 一个基于 Jquery/FontAwesome 的流程图/架构图画图插件&…

探索Python异步编程的秘境:Eventlet的魔力与魅力
文章目录 **探索Python异步编程的秘境:Eventlet的魔力与魅力**第一部分:背景与引言第二部分:Eventlet是什么?第三部分:如何安装Eventlet?第四部分:Eventlet的基本使用第五部分:Event…

如何用ai来完成数据库分析(2)
一样的前言
因一些课程设计要写长篇分析报告,这里借用ai做一篇指导教程,分上下两篇。这篇也会教如何让ai给你你想要的答案,众所周知,现在的ai并不智能,不针对各类厂家,但是放出来的确实表象如此。
但其实…

CMIP6数据处理技术教程
原文链接:CMIP6数据处理技术教程https://mp.weixin.qq.com/s?__bizMzUzNTczMDMxMg&mid2247611539&idx4&sn3eb0490b72ef694dcd41f6de0b623388&chksmfa827574cdf5fc62372bfcf188ea1ae6e41350ff8469c2940ed097244b205e0dd73f4c8832fa&token616696…

绝对干货!分享把Fildder录制的脚本导出成Jmeter脚本的方法(实测在Fiddler5中有效)
相信做过接口测试的小伙伴都面临过这样的窘境——在没有接口测试文档的情况下,进行接口的压力测试!怎么破?
通常的做法都是利用抓包工具(以fiddler为例)进行抓包,然后把抓包请求手写到压力测试工具中&…

解决Solidworks 2024运行的Windows资源极低,执行此命令可能会导致SOLIDWORKS 失败。
Solidworks Resource Monitor 可供使用的系统内存很低。请关闭一些应用程序以释放资源。即使内存十分充足,也容易出现这些提示,而我个人感觉2024版相比以前版本更容易出现这个问题,这显然是Solidworks本身的Bug。网上普遍流传的解决方法&…

再讲Langchain 提示词模板(PromptTemplate)
在LangChain 0.2中,提示词模板(Prompt Template)是一个非常重要的概念和功能。它允许我们创建结构化和可重用的提示,以便更有效地与语言模型进行交互。
提示词模板的主要作用包括: 结构化提示: 允许我们定义一个固定的提示结构,包含静态文本和动态变量。 参数化: 可以在模板中…
汽车测试-ADAS测试设备RT3000介绍及数据处理
目录 一、分析目的
二、数据采集仪器
三、数据文件
1.数据样本名词解释
2.数据应用
3.简单举例
汽车数据分析示例
1. 行驶轨迹与路径优化
2. 速度与加速度分析
3. 燃油效率与能耗分析
4. 驾驶行为与安全分析
5. 车辆维护与故障诊断
评估导航与定位的准确性。
一、…

测试工程师职业道路管理方向有哪些
目录
01测试组长
测试组长的职责及掌握技能:
测试组长需要掌握的技能:
02测试经理
测试经理具备的职责:
测试经理具备的技能:
03测试总监
测试总监具备的职责:
测试总监具备的技能: 测试工程师管理…