本文翻译整理自:
https://pymupdf.readthedocs.io/en/latest/how-to-open-a-file.html
文章目录
- 一、打开文件
- 1、支持的文件类型
- 2、如何打开文件
- 打开一个错误的文件扩展名
- 3、打开远程文件
- 从云服务打开文件
- 4、以文本形式打开文件
- 例子
- 打开一个`C#`文件
- 打开一个`XML`文件
- 打开一个`JSON`文件
- 二、文本
- 1、如何提取所有文档文本
- 2、如何提取文本作为Markdown
- 3、如何从页面中提取键值对
- 4、如何从矩形中提取文本
- 5、如何以自然阅读顺序提取文本
- 6、如何从文档中提取表格内容
- 7、如何标记提取的文本
- 8、如何标记搜索文本
- 9、如何标记非水平文本
- 10、如何分析字体特征
- 12、如何插入文本
- 12.1 如何写文本行
- 12.2 如何填写文本框
- 12.3 如何用HTML文本填充框
- 如何输出HTML表和图像
- 如何输出世界语言
- 如何指定自己的字体
- 如何请求文本对齐
- 13、如何提取带有颜色的文本
- 三、图片
- 1、如何从文档页面制作图像
- 2、如何提高图像分辨率
- 3、如何创建部分像素图(剪辑)
- 4、如何将剪辑缩放到GUI窗口
- 5、如何创建或抑制注释图像
- 6、如何提取图像:非PDF文档
- 7、如何提取图像:PDF文档
- 8、如何处理图像掩码
- 9、如何制作所有图片(或文件)的PDF
- 10、如何创建矢量图像
- 11、如何转换图像
- 12、如何使用像素贴图:粘合图像
- 13、如何使用像素图:制作分形
- 14、如何与NumPy接口
- 15、如何将图像添加到PDF页面
- 16、如何使用像素图:检查文本可见性
- 四、注释
- 1、如何添加和修改注释
- 2、如何使用FreeText
- 3、使用按钮和JavaScript
- 4、如何使用墨水注释
- 五、绘图和图形
- 1、如何提取图纸
- 2、如何删除图纸
- 3、如何绘制图形
- 六、故事
- 1、如何添加具有一些格式的文本行
- 2、如何使用图片
- 3、如何阅读故事的外部HTML和CSS
- 4、如何使用故事模板输出数据库内容
- 5、如何与现有PDF集成
- 6、如何使多列布局和访问字体从包[pymupdf-fonts](https://github.com/pymupdf/pymupdf-fonts)
- 7、如何制作一个围绕预定义的“禁区”布局的布局
- 8、如何输出HTML表
- 9、如何生成目录
- 10、如何显示来自JSON数据的列表
- 11、使用替代`Story.write*()`函数
- 11.1 如何做基本布局与 Story.write()
- 11.2 如何做迭代布局的目录与`Story.write_stabilized()`
- 11.3 如何做迭代布局和创建PDF链接与`Story.write_stabilized_links()`
- 七、日志
- 示例会话1
- 示例会话2
- 八、多线程
- 九、OCR-光学字符识别
- 1、如何OCR图像
- 2、如何OCR文档页面
- 十、可选内容支持
- 1、简介:可选内容概念
- 2、PyMuPDF支持PDF可选内容
- 3、如何添加可选内容
- 4、如何定义复杂的可选内容条件
- 十一、低级接口
- 1、如何遍历[`xref`](https://pymupdf.readthedocs.io/en/latest/glossary.html#xref)表
- 2、如何处理对象流
- 3、如何处理页面内容
- 4、如何访问PDF目录
- 5、如何访问PDF文件预告片
- 6、如何访问XML元数据
- 7、如何扩展PDF元数据
- 8、如何读取和更新PDF对象
一、打开文件
1、支持的文件类型
PyMuPDF 可以打开PDF以外的文件。
支持以下文件类型:
| 文件类型 | |
|---|---|
| 文档格式 | PDF XPS EPUB MOBI FB2 CBZ SVG TXT |
| 图像格式 | 输入格式JPG/JPEG、PNG、BMP、GIF、TIFF、PNM、PGM、PBM、PPM、PAM、JXR、JPX/JP2、PSD输出格式JPG/JPEG、PNG、PNM、PGM、PBM、PPM、PAM、PSD、PS |
2、如何打开文件
要打开文件,请执行以下操作:
doc = pymupdf.open("a.pdf")
注:上面创建了一个 Document。
指令doc = pymupdf.Document("a.pdf")做的完全一样。
因此,open只是一个方便的别名,您可以在该章中找到它的完整API文档。
打开一个错误的文件扩展名
如果您的文档类型的文件扩展名错误,您仍然可以正确打开它。
假设“一些文件”实际上是一个XPS。像这样打开它:
doc = pymupdf.open("some.file", filetype="xps")
注:PyMuPDF本身不会尝试从文件内容中确定文件类型。您负责以某种方式提供文件类型信息——可以隐式地,通过文件扩展名,也可以显式地,如filetype参数所示。
有纯Python包,如filetype,可以帮助您做到这一点。
另请参阅文档章节以获取完整描述。
如果PyMuPDF遇到扩展名未知/缺失的文件,它会尝试将其作为PDF打开。
所以在这些情况下不需要额外的预防措施。
同样,对于内存文档,您只需指定doc=pymupdf.open(stream=mem_area)即可将其作为PDF文档打开。
如果您尝试打开不受支持的文件,那么PyMuPDF将抛出文件数据错误。
3、打开远程文件
对于服务器上的远程文件(即非本地文件),您需要将文件数据 流式传输 到PyMuPDF。
例如,使用如下请求库:
import pymupdf
import requests
r = requests.get('https://mupdf.com/docs/mupdf_explored.pdf')
data = r.content
doc = pymupdf.Document(stream=data)
从云服务打开文件
有关处理典型云服务上保存的文件的更多示例,请参阅这些云交互代码片段。
4、以文本形式打开文件
PyMuPDF能够将任何 纯文本文件 作为文档打开。为此,您应该为pymupdf.open函数提供filetype参数"txt"。
doc = pymupdf.open("my_program.py", filetype="txt")
通过这种方式,您可以打开各种文件类型 并执行典型的非PDF特定功能,如文本搜索、文本提取和页面呈现。
显然,一旦您呈现了txt内容,那么保存为PDF或与其他PDF文件合并是没有问题的。
例子
打开一个C#文件
doc = pymupdf.open("MyClass.cs", filetype="txt")
打开一个XML文件
doc = pymupdf.open("my_data.xml", filetype="txt")
打开一个JSON文件
doc = pymupdf.open("more_of_my_data.json", filetype="txt")
等等!
可以想象,PyMuPDF可以非常简单地打开和解释 许多基于文本的文件格式。这可以使对各种以前不可用的文件 进行数据分析 和提取 突然成为可能。
二、文本
1、如何提取所有文档文本
此脚本将采用文档文件名并从其所有文本生成一个文本文件。
文档可以是任何受支持类型。
该脚本作为命令行工具工作,它期望作为参数提供的文档文件名。它在脚本目录中生成一个名为 filename.txt 的文本文件。页面文本由换页字符分隔:
import sys, pathlib, pymupdf
fname = sys.argv[1] # get document filename
with pymupdf.open(fname) as doc: # open document
text = chr(12).join([page.get_text() for page in doc])
# write as a binary file to support non-ASCII characters
pathlib.Path(fname + ".txt").write_bytes(text.encode())
输出将是纯文本,因为它是在文档中编码的。没有努力以任何方式美化。特别是对于PDF,这可能意味着输出不是按照通常的阅读顺序,意外的换行符等等。
您有许多选择来纠正这一点-请参阅附录2:关于嵌入式文件的注意事项一章。其中包括:
- 提取HTML格式的文本并将其存储为HTML文档,因此可以在任何浏览器中查看。
- 通过
Page.get_text("blocks")提取文本 作为文本块列表。此列表的每个项目 都包含其文本的位置信息,可用于建立方便的阅读顺序。 - 通过
Page.get_text("words")提取单个单词列表。它的项目是带有位置信息的单词。使用它来确定包含在给定矩形中的文本-见下一节。
有关示例和进一步解释,请参阅以下两节。
2、如何提取文本作为Markdown
这对于RAG/LLM环境特别有用-请参阅输出为Markdown。
3、如何从页面中提取键值对
如果页面的布局在某种意义上是*“可预测”*的,那么有一种简单的方法可以快速轻松地找到给定关键字集的值 —— 而无需使用正则表达式。请参阅此示例脚本。
“可预测”在这种情况下是指:
- 每个关键字后面都跟着它的值-它们之间没有其他文本。
- 值的边界框的底部不在关键字的底部之上。
- 没有其他限制:页面布局可能固定也可能不固定,文本也可能存储为一个字符串。键和值可以彼此有任何距离。
例如,将正确识别以下五个键值对:
key1 value1
key2
value2
key3
value3 blah, blah, blah key4 value4 some other text key5 value5 ...
4、如何从矩形中提取文本
现在(v1.18.0)有不止一种方法可以实现这一点。因此,我们在PyMuPDF-实用程序存储库中创建了一个专门处理此主题的文件夹。
5、如何以自然阅读顺序提取文本
PDF文本提取的常见问题之一是,文本可能不会以任何特定的阅读顺序出现。这是PDF创建者(软件或人工)的责任。
例如,页眉可能是在单独的步骤中插入的——在文档生成之后。
在这种情况下,页眉文本将出现在页面文本提取的末尾(尽管它将由PDF查看器软件正确显示)。
例如,以下片段将向现有PDF添加一些页眉和页脚行:
doc = pymupdf.open("some.pdf")
header = "Header" # text in header
footer = "Page %i of %i" # text in footer
for page in doc:
page.insert_text((50, 50), header) # insert header
page.insert_text( # insert footer 50 points above page bottom
(50, page.rect.height - 50),
footer % (page.number + 1, doc.page_count),
)
从以这种方式修改的页面中提取的文本序列将如下所示:
- 原文
- 标题行
- 页脚线
PyMuPDF有几种方法可以重新建立一些读取顺序,甚至重新生成接近原始布局的布局:
- 使用
Page.get_text()的sort参数。它将从左上角到右下角对输出进行排序(对于XHTML、HTML和XML输出忽略)。 - 使用CLI中的
pymupdf模块:python -m pymupdf gettext ...,它会生成一个文本文件,其中文本已在保留布局模式下重新排列。许多选项可用于控制输出。
您也可以使用上述脚本进行修改。
6、如何从文档中提取表格内容
如果您在文档中看到表格,您通常不会查看嵌入的Excel或其他可识别对象之类的东西。它通常只是普通的标准文本,格式化为表格数据。
因此,从这样的页面区域中提取表格数据意味着您必须找到一种方法来识别表格区域(即其边界框),然后(1)以图形方式指示表格和列边界,以及(2)然后根据该信息提取文本。
这可能是一项非常复杂的任务,取决于线条、矩形或其他支持矢量图形的存在与否等细节。
方法Page.find_tables()为你做了所有这些,具有很高的表检测精度。它的巨大优势是没有外部库依赖项,也不需要采用人工智能或机器学习技术。它还提供了一个集成接口到众所周知的Python包,用于数据分析Pandas。
请看看示例Jupyter笔记本,它涵盖了标准情况,如一页上的多个表格或跨多个页面连接表格片段。
7、如何标记提取的文本
有一个标准的搜索函数来搜索页面上的任意文本:Page.search_for()。它返回一个Rect对象列表,这些对象围绕着找到的内容。例如,这些矩形可以用来自动插入注释,这些注释可以明显地标记找到的文本。
这种方法有优点也有缺点。优点是:
- 搜索字符串可以包含空格并换行
- 大写或小写字符被视为相等
- 检测并解决行尾的断字
- 返回也可以是Quad对象列表,以精确定位与任一轴不平行的文本-当页面旋转不为零时,也建议使用Quad输出。
但您也有其他选择:
import sys
import pymupdf
def mark_word(page, text):
"""Underline each word that contains 'text'.
"""
found = 0
wlist = page.get_text("words", delimiters=None) # make the word list
for w in wlist: # scan through all words on page
if text in w[4]: # w[4] is the word's string
found += 1 # count
r = pymupdf.Rect(w[:4]) # make rect from word bbox
page.add_underline_annot(r) # underline
return found
fname = sys.argv[1] # filename
text = sys.argv[2] # search string
doc = pymupdf.open(fname)
print("underlining words containing '%s' in document '%s'" % (word, doc.name))
new_doc = False # indicator if anything found at all
for page in doc: # scan through the pages
found = mark_word(page, text) # mark the page's words
if found: # if anything found ...
new_doc = True
print("found '%s' %i times on page %i" % (text, found, page.number + 1))
if new_doc:
doc.save("marked-" + doc.name)
此脚本使用Page.get_text("words")查找通过cli参数传递的字符串。
此方法使用空格作为分隔符将页面的文本分隔为“word”。进一步备注:
- 如果找到,包含字符串的完整单词将被标记(下划线)-不仅是搜索字符串。
- 搜索字符串可能不包含单词分隔符。默认情况下,单词分隔符是空白和不间断的空格
chr(0xA0)。如果您使用额外的分隔符,如page.get_text("words", delimiters="./,")那么这些字符也不应该包含在您的搜索字符串中。 - 如图所示,我们尊重大小写。但是这可以通过在函数mark_word中使用字符串方法
low()(甚至是正则表达式)来改变。 - 没有上限:将检测到所有事件。
- 您可以使用任何东西来标记单词:“下划线”、“突出显示”、“删除线”或“正方形”注释等。
- 这是本手册页面的示例片段,其中使用“MuPDF”作为搜索字符串。请注意,所有包含“MuPDF”的字符串都带有完整的下划线(不仅仅是搜索字符串)。
8、如何标记搜索文本
此脚本搜索文本并将其标记为:
# -*- coding: utf-8 -*-
import pymupdf
# the document to annotate
doc = pymupdf.open("tilted-text.pdf")
# the text to be marked
needle = "¡La práctica hace el campeón!"
# work with first page only
page = doc[0]
# get list of text locations
# we use "quads", not rectangles because text may be tilted!
rl = page.search_for(needle, quads=True)
# mark all found quads with one annotation
page.add_squiggly_annot(rl)
# save to a new PDF
doc.save("a-squiggly.pdf")
结果如下所示:

9、如何标记非水平文本
上一节已经展示了一个标记非水平文本的示例,该示例是通过文本搜索检测到的。
但是,文本提取 与Page.get_text() 也可以返回与x轴的非零角度的文本。
这由行字典的"dir"键的值表示:它是该角度的元组(cosine, sine)。
如果line["dir"] != (1, 0),则其所有跨度的文本旋转(相同)角度!=0。
然而,该方法返回的“bbox”只是矩形,而不是四边形。
因此,要正确标记空格文本,必须从行和空格字典中包含的数据中恢复其四边形。
使用以下实用函数(v1.18.9中的新功能)执行此操作:
span_quad = pymupdf.recover_quad(line["dir"], span)
annot = page.add_highlight_annot(span_quad) # this will mark the complete span text
如果要一次性标记完整的行或其跨度的子集,请使用以下片段(适用于v1.18.10或更高版本):
line_quad = pymupdf.recover_line_quad(line, spans=line["spans"][1:-1])
page.add_highlight_annot(line_quad)

上面的spans参数可以指定line["spans"]的任何子列表。
在上面的示例中,标记了倒数第二个跨度。如果省略,则采用完整的行。
10、如何分析字体特征
要分析PDF中文本的特征,请使用以下基本脚本作为起点:
import sys
import pymupdf
def flags_decomposer(flags):
"""Make font flags human readable."""
l = []
if flags & 2 ** 0:
l.append("superscript")
if flags & 2 ** 1:
l.append("italic")
if flags & 2 ** 2:
l.append("serifed")
else:
l.append("sans")
if flags & 2 ** 3:
l.append("monospaced")
else:
l.append("proportional")
if flags & 2 ** 4:
l.append("bold")
return ", ".join(l)
doc = pymupdf.open(sys.argv[1])
page = doc[0]
# read page text as a dictionary, suppressing extra spaces in CJK fonts
blocks = page.get_text("dict", flags=11)["blocks"]
for b in blocks: # iterate through the text blocks
for l in b["lines"]: # iterate through the text lines
for s in l["spans"]: # iterate through the text spans
print("")
font_properties = "Font: '%s' (%s), size %g, color #%06x" % (
s["font"], # font name
flags_decomposer(s["flags"]), # readable font flags
s["size"], # font size
s["color"], # font color
)
print("Text: '%s'" % s["text"]) # simple print of text
print(font_properties)
这是PDF页面和脚本输出:

12、如何插入文本
PyMuPDF提供了在新的或现有的PDF页面上插入文本的方法,具有以下功能:
- 选择字体,包括内置字体和可作为文件使用的字体
- 选择文本特征,如粗体、斜体字、字体大小、字体颜色等。
- 以多种方式定位文本:
- 作为从某一点开始的简单的面向行的输出,
- 或者将文本拟合到作为矩形提供的框中,在这种情况下,还可以选择文本对齐方式,
- 选择文本是否应该放在前景(覆盖现有内容),
- 所有文本都可以任意“变形”,即它的外观可以通过矩阵改变,以实现缩放、剪切或镜像等效果,
- 独立于变形,除此之外,文本可以旋转90度的整数倍。
以上所有内容由三种基本的Page, resp.Shape方法提供:
Page.insert_font()-为页面安装字体以供以后参考。结果反映在Document.get_page_fonts()的输出中。字体可以是:- 作为文件提供,
- 通过字体(然后使用
Font.buffer) - 已经在这个或另一个PDF中的某个地方,或者
- 是内置字体。
Page.insert_text()-写几行文本。在内部,这使用Shape.insert_text()。Page.insert_textbox()-将文本放入给定的矩形中。在这里,您可以选择文本对齐功能(左、右、居中、对齐),并控制文本是否真正合适。在内部,这使用Shape.insert_textbox()。
注:两种文本插入方法都会根据需要自动安装字体。
12.1 如何写文本行
在页面上输出一些文本行:
import pymupdf
doc = pymupdf.open(...) # new or existing PDF
page = doc.new_page() # new or existing page via doc[n]
p = pymupdf.Point(50, 72) # start point of 1st line
text = "Some text,\nspread across\nseveral lines."
# the same result is achievable by
# text = ["Some text", "spread across", "several lines."]
rc = page.insert_text(p, # bottom-left of 1st char
text, # the text (honors '\n')
fontname = "helv", # the default font
fontsize = 11, # the default font size
rotate = 0, # also available: 90, 180, 270
)
print("%i lines printed on page %i." % (rc, page.number))
doc.save("text.pdf")
使用此方法,将仅控制**行数,**使其不超出页面高度。多余的行不会被写入,实际行数将被返回。计算使用从fontsize计算的行高和36点(0.5英寸)作为底边距。
线宽被忽略。线的剩余部分将是不可见的。
但是,对于内置字体,有一些方法可以预先计算线宽——参见get_text_length()。
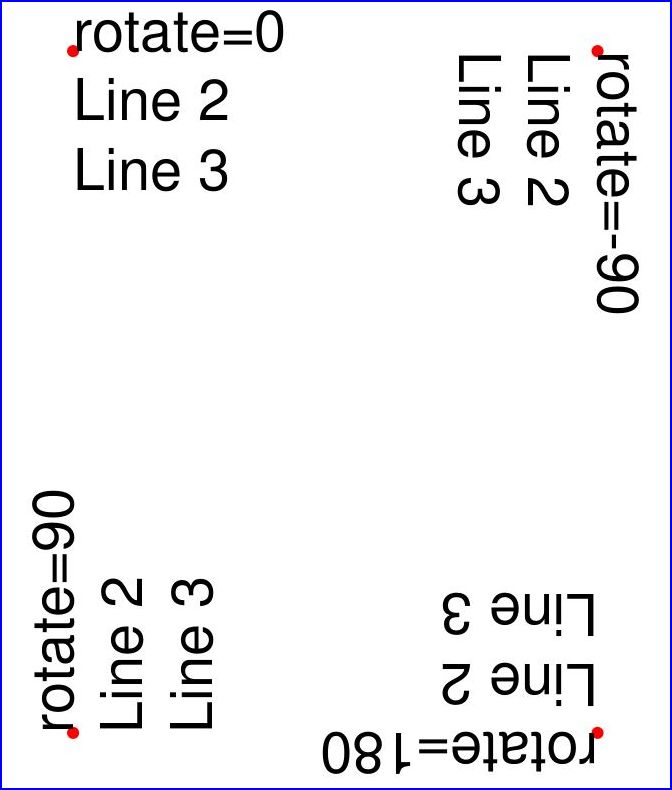
这是另一个例子。它使用四种不同的旋转选项插入4个文本字符串,从而解释了必须如何选择文本插入点才能获得所需的结果:
import pymupdf
doc = pymupdf.open()
page = doc.new_page()
# the text strings, each having 3 lines
text1 = "rotate=0\nLine 2\nLine 3"
text2 = "rotate=90\nLine 2\nLine 3"
text3 = "rotate=-90\nLine 2\nLine 3"
text4 = "rotate=180\nLine 2\nLine 3"
red = (1, 0, 0) # the color for the red dots
# the insertion points, each with a 25 pix distance from the corners
p1 = pymupdf.Point(25, 25)
p2 = pymupdf.Point(page.rect.width - 25, 25)
p3 = pymupdf.Point(25, page.rect.height - 25)
p4 = pymupdf.Point(page.rect.width - 25, page.rect.height - 25)
# create a Shape to draw on
shape = page.new_shape()
# draw the insertion points as red, filled dots
shape.draw_circle(p1,1)
shape.draw_circle(p2,1)
shape.draw_circle(p3,1)
shape.draw_circle(p4,1)
shape.finish(width=0.3, color=red, fill=red)
# insert the text strings
shape.insert_text(p1, text1)
shape.insert_text(p3, text2, rotate=90)
shape.insert_text(p2, text3, rotate=-90)
shape.insert_text(p4, text4, rotate=180)
# store our work to the page
shape.commit()
doc.save(...)
这是结果:
12.2 如何填写文本框
此脚本用文本填充4个不同的矩形,每次选择不同的旋转值:
import pymupdf
doc = pymupdf.open() # new or existing PDF
page = doc.new_page() # new page, or choose doc[n]
# write in this overall area
rect = pymupdf.Rect(100, 100, 300, 150)
# partition the area in 4 equal sub-rectangles
CELLS = pymupdf.make_table(rect, cols=4, rows=1)
t1 = "text with rotate = 0." # these texts we will written
t2 = "text with rotate = 90."
t3 = "text with rotate = 180."
t4 = "text with rotate = 270."
text = [t1, t2, t3, t4]
red = pymupdf.pdfcolor["red"] # some colors
gold = pymupdf.pdfcolor["gold"]
blue = pymupdf.pdfcolor["blue"]
"""
We use a Shape object (something like a canvas) to output the text and
the rectangles surrounding it for demonstration.
"""
shape = page.new_shape() # create Shape
for i in range(len(CELLS[0])):
shape.draw_rect(CELLS[0][i]) # draw rectangle
shape.insert_textbox(
CELLS[0][i], text[i], fontname="hebo", color=blue, rotate=90 * i
)
shape.finish(width=0.3, color=red, fill=gold)
shape.commit() # write all stuff to the page
doc.ez_save(__file__.replace(".py", ".pdf"))
上面使用了一些默认值:字体大小11和文本对齐“左”。结果将如下所示:

12.3 如何用HTML文本填充框
方法Page.insert_htmlbox()提供了一种在矩形中插入文本的更强大的方法。
这种方法接受HTML源,它不仅包含HTML,还包含样式指令,以影响字体、字体粗细(粗体)和样式(斜体字)、颜色等。
还可以混合多种字体和语言,输出HTML表以及插入图像和URI链接。
为了获得更大的样式灵活性,还可以提供额外的CSS源。
该方法基于故事类。因此,由于使用了提供这种所谓的**“文本整形”**功能的HarfBuzz库,复杂的脚本系统,如Devanagari、尼泊尔语、泰米尔语等,都得到了支持和正确编写。
输出字符所需的任何字体都会自动从Google NOTO字体库中提取-作为后备(当-可选提供的-用户字体不包含某些字形时)。
作为对此处提供的功能的一个小小的了解,我们将输出以下HTML丰富的文本:
import pymupdf
rect = pymupdf.Rect(100, 100, 400, 300)
text = """Lorem ipsum dolor sit amet, consectetur adipisici elit, sed
eiusmod tempor incidunt ut labore et dolore magna aliqua. Ut enim ad
minim veniam, quis nostrud exercitation <b>ullamco <i>laboris</i></b>
nisi ut aliquid ex ea commodi consequat. Quis aute iure
<span style="color: #f00;">reprehenderit</span>
in <span style="color: #0f0;font-weight:bold;">voluptate</span> velit
esse cillum dolore eu fugiat nulla pariatur. Excepteur sint obcaecat
cupiditat non proident, sunt in culpa qui
<a href="https://www.artifex.com">officia</a> deserunt mollit anim id
est laborum."""
doc = pymupdf.Document()
page = doc.new_page()
page.insert_htmlbox(rect, text, css="* {font-family: sans-serif;font-size:14px;}")
doc.ez_save(__file__.replace(".py", ".pdf"))
请注意如何使用“css”参数全局选择默认的“sans-serif”字体和14的字体大小。
结果将如下所示:

如何输出HTML表和图像
这是另一个使用此方法输出表格的示例。这一次,我们将在HTML源本身中包含所有样式。另请注意,包含图像是如何工作的-即使在表格单元格中:
import pymupdf
import os
filedir = os.path.dirname(__file__)
text = """
<style>
body {
font-family: sans-serif;
}
td,
th {
border: 1px solid blue;
border-right: none;
border-bottom: none;
padding: 5px;
text-align: center;
}
table {
border-right: 1px solid blue;
border-bottom: 1px solid blue;
border-spacing: 0;
}
</style>
<body>
<p><b>Some Colors</b></p>
<table>
<tr>
<th>Lime</th>
<th>Lemon</th>
<th>Image</th>
<th>Mauve</th>
</tr>
<tr>
<td>Green</td>
<td>Yellow</td>
<td><img src="img-cake.png" width=50></td>
<td>Between<br>Gray and Purple</td>
</tr>
</table>
</body>
"""
doc = pymupdf.Document()
page = doc.new_page()
rect = page.rect + (36, 36, -36, -36)
# we must specify an Archive because of the image
page.insert_htmlbox(rect, text, archive=pymupdf.Archive("."))
doc.ez_save(__file__.replace(".py", ".pdf"))
结果将如下所示:

如何输出世界语言
我们的第三个示例将演示自动多语言支持。它包括用于复杂脚本系统(如Devanagari和从右到左的语言)的自动文本整形:
import pymupdf
greetings = (
"Hello, World!", # english
"Hallo, Welt!", # german
"سلام دنیا!", # persian
"வணக்கம், உலகம்!", # tamil
"สวัสดีชาวโลก!", # thai
"Привіт Світ!", # ucranian
"שלום עולם!", # hebrew
"ওহে বিশ্ব!", # bengali
"你好世界!", # chinese
"こんにちは世界!", # japanese
"안녕하세요, 월드!", # korean
"नमस्कार, विश्व !", # sanskrit
"हैलो वर्ल्ड!", # hindi
)
doc = pymupdf.open()
page = doc.new_page()
rect = (50, 50, 200, 500)
# join greetings into one text string
text = " ... ".join([t for t in greetings])
# the output of the above is simple:
page.insert_htmlbox(rect, text)
doc.save(__file__.replace(".py", ".pdf"))
这是输出:

如何指定自己的字体
使用@font-face语句在CSS语法中定义字体文件。
对于您希望支持的字体重量和字体样式(例如粗体或斜体字)的每个组合,您需要单独的@font-face。
以下示例使用著名的MS Comic Sans字体的四种变体常规、粗体、斜体字和粗体斜体字。
由于这四个字体文件位于系统的文件夹C:/Windows/Fonts中,该方法需要一个指向该文件夹的存档定义:
"""
How to use your own fonts with method Page.insert_htmlbox().
"""
import pymupdf
# Example text
text = """Lorem ipsum dolor sit amet, consectetur adipisici elit, sed
eiusmod tempor incidunt ut labore et dolore magna aliqua. Ut enim ad
minim veniam, quis nostrud exercitation <b>ullamco <i>laboris</i></b>
nisi ut aliquid ex ea commodi consequat. Quis aute iure
<span style="color: red;">reprehenderit</span>
in <span style="color: green;font-weight:bold;">voluptate</span> velit
esse cillum dolore eu fugiat nulla pariatur. Excepteur sint obcaecat
cupiditat non proident, sunt in culpa qui
<a href="https://www.artifex.com">officia</a> deserunt mollit anim id
est laborum."""
"""
We need an Archive object to show where font files are located.
We intend to use the font family "MS Comic Sans".
"""
arch = pymupdf.Archive("C:/Windows/Fonts")
# These statements define which font file to use for regular, bold,
# italic and bold-italic text.
# We assign an arbitrary common font-family for all 4 font files.
# The Story algorithm will select the right file as required.
# We request to use "comic" throughout the text.
css = """
@font-face {font-family: comic; src: url(comic.ttf);}
@font-face {font-family: comic; src: url(comicbd.ttf);font-weight: bold;}
@font-face {font-family: comic; src: url(comicz.ttf);font-weight: bold;font-style: italic;}
@font-face {font-family: comic; src: url(comici.ttf);font-style: italic;}
* {font-family: comic;}
"""
doc = pymupdf.Document()
page = doc.new_page(width=150, height=150) # make small page
page.insert_htmlbox(page.rect, text, css=css, archive=arch)
doc.subset_fonts(verbose=True) # build subset fonts to reduce file size
doc.ez_save(__file__.replace(".py", ".pdf"))

如何请求文本对齐
此示例结合了多个要求:
- 将文字逆时针旋转90度。
- 使用包pymupdf-fonts中的字体。在这种情况下,您将看到相应的CSS定义要容易得多。
- 将文本与“证明”选项对齐。
"""
How to use a pymupdf font with method Page.insert_htmlbox().
"""
import pymupdf
# Example text
text = """Lorem ipsum dolor sit amet, consectetur adipisici elit, sed
eiusmod tempor incidunt ut labore et dolore magna aliqua. Ut enim ad
minim veniam, quis nostrud exercitation <b>ullamco <i>laboris</i></b>
nisi ut aliquid ex ea commodi consequat. Quis aute iure
<span style="color: red;">reprehenderit</span>
in <span style="color: green;font-weight:bold;">voluptate</span> velit
esse cillum dolore eu fugiat nulla pariatur. Excepteur sint obcaecat
cupiditat non proident, sunt in culpa qui
<a href="https://www.artifex.com">officia</a> deserunt mollit anim id
est laborum."""
"""
This is similar to font file support. However, we can use a convenience
function for creating required CSS definitions.
We still need an Archive for finding the font binaries.
"""
arch = pymupdf.Archive()
# We request to use "myfont" throughout the text.
css = pymupdf.css_for_pymupdf_font("ubuntu", archive=arch, name="myfont")
css += "* {font-family: myfont;text-align: justify;}"
doc = pymupdf.Document()
page = doc.new_page(width=150, height=150)
page.insert_htmlbox(page.rect, text, css=css, archive=arch, rotate=90)
doc.subset_fonts(verbose=True)
doc.ez_save(__file__.replace(".py", ".pdf"))

13、如何提取带有颜色的文本
遍历您的文本块并找到此信息所需的文本范围。
for page in doc:
text_blocks = page.get_text("dict", flags=pymupdf.TEXTFLAGS_TEXT)["blocks"]
for block in text_blocks:
for line in block["lines"]:
for span in line["spans"]:
text = span["text"]
color = pymupdf.sRGB_to_rgb(span["color"])
print(f"Text: {text}, Color: {color}")
您对此页面有任何反馈吗?
本软件按原样提供,没有明示或暗示的保证。本软件是根据许可分发的,除非根据该许可条款明确授权,否则不得复制、修改或分发。
请参阅 artifex.com 的许可信息,或联系Artifex Software Inc.,39 Mesa Street,Suite 108A,San Francisco CA 94129,United USA了解更多信息。
三、图片
1、如何从文档页面制作图像
这个小脚本将采用一个文档文件名并从其每个页面生成一个PNG文件。
文档可以是任何受支持类型。
该脚本作为命令行工具工作,它期望文件名作为参数提供。生成的图像文件(每页1个)存储在脚本的目录中:
import sys, pymupdf # import the bindings
fname = sys.argv[1] # get filename from command line
doc = pymupdf.open(fname) # open document
for page in doc: # iterate through the pages
pix = page.get_pixmap() # render page to an image
pix.save("page-%i.png" % page.number) # store image as a PNG
脚本目录现在将包含名为 page-0.png、page-1.png 等的PNG图像文件。
图片的页面尺寸为宽度和高度四舍五入为整数,例如A4纵向页面的 595 x 842 像素。
它们的x和y尺寸分辨率为 96 dpi,没有透明度。您可以更改所有这些——有关如何做到这一点,请阅读下一节。
2、如何提高图像分辨率
文档页面的图像由像素图表示,创建像素图的最简单方法是通过方法Page.get_pixmap()。
这种方法有许多选项来影响结果。其中最重要的是矩阵,它可以让你缩放、旋转、扭曲或镜像结果。
Page.get_pixmap()默认情况下将使用身份矩阵,它什么也不做。
在下面,我们对每个维度应用2的缩放系数,这将为我们生成分辨率提高四倍的图像(也大约是大小的4倍):
zoom_x = 2.0 # horizontal zoom
zoom_y = 2.0 # vertical zoom
mat = pymupdf.Matrix(zoom_x, zoom_y) # zoom factor 2 in each dimension
pix = page.get_pixmap(matrix=mat) # use 'mat' instead of the identity matrix
从版本1.19.2开始,有一种更直接的方法来设置分辨率:参数"dpi"(每英寸点数)可以用来代替"matrix"。
要创建页面的300 dpi图像,请指定pix = page.get_pixmap(dpi=300)。
除了符号简洁之外,这种方法还有一个额外的优点,那就是dpi值与图像一起保存文件——使用矩阵符号时不会自动发生。
3、如何创建部分像素图(剪辑)
您并不总是需要或想要页面的完整图像。例如,当您在GUI中显示图像并希望用页面的缩放部分填充相应的窗口时,就是这种情况。
假设您的GUI窗口有空间显示完整的文档页面,但您现在希望用页面右下角的四分之一来填充这个房间,从而使用高四倍的分辨率。
为了实现这一点,定义一个等于你想在图形用户界面中出现的面积的矩形,并称之为“剪辑”。在PyMuPDF中构造矩形的一种方法是提供两个对角线相反的角,这就是我们在这里所做的。
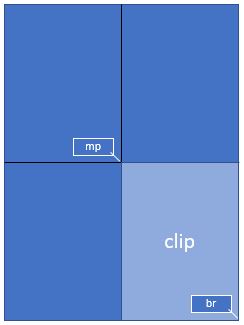
mat = pymupdf.Matrix(2, 2) # zoom factor 2 in each direction
rect = page.rect # the page rectangle
mp = (rect.tl + rect.br) / 2 # its middle point, becomes top-left of clip
clip = pymupdf.Rect(mp, rect.br) # the area we want
pix = page.get_pixmap(matrix=mat, clip=clip)
在上面,我们通过指定两个对角线相反的点来构造剪辑:页面矩形的中间点mp,以及它的右下角rect.br。
4、如何将剪辑缩放到GUI窗口
请同时阅读上一节。这次我们要计算剪辑的缩放系数,使其图像最适合给定的GUI窗口。
这意味着,图像的宽度或高度(或两者)将等于窗口尺寸。
对于以下代码片段,您需要提供GUI窗口的宽度和高度,该窗口应该接收页面的剪辑矩形。
# WIDTH: width of the GUI window
# HEIGHT: height of the GUI window
# clip: a subrectangle of the document page
# compare width/height ratios of image and window
if clip.width / clip.height < WIDTH / HEIGHT:
# clip is narrower: zoom to window HEIGHT
zoom = HEIGHT / clip.height
else: # clip is broader: zoom to window WIDTH
zoom = WIDTH / clip.width
mat = pymupdf.Matrix(zoom, zoom)
pix = page.get_pixmap(matrix=mat, clip=clip)
反过来,现在假设您有缩放因子并且需要计算拟合剪辑。
在这种情况下,我们有zoom = HEIGHT/clip.height = WIDTH/clip.width,所以我们必须设置clip.height = HEIGHT/zoom和,clip.width = WIDTH/zoom。选择页面上剪辑的左上角点tl来计算右像素图:
width = WIDTH / zoom
height = HEIGHT / zoom
clip = pymupdf.Rect(tl, tl.x + width, tl.y + height)
# ensure we still are inside the page
clip &= page.rect
mat = pymupdf.Matrix(zoom, zoom)
pix = pymupdf.Pixmap(matrix=mat, clip=clip)
5、如何创建或抑制注释图像
通常,页面的像素图也会显示页面的注释。有时,这可能不可取。
要抑制渲染页面上的注释图像,只需在Page.get_pixmap() 中指定annots=False``Page.get_pixmap()。
您也可以单独呈现注释:它们有自己的Annot.get_pixmap()方法。生成的像素图与注释矩形具有相同的维度。
6、如何提取图像:非PDF文档
与前面的部分相比,本节处理文档中包含的图像的提取,以便它们可以显示为一个或多个页面的一部分。
如果您想以文件形式或作为内存区域重新创建原始图像,您基本上有两种选择:
1)将您的文档转换为PDF,然后使用其中一种仅限PDF的提取方法。此片段将文档转换为PDF:
>>> pdfbytes = doc.convert_to_pdf() # this a bytes object
>>> pdf = pymupdf.open("pdf", pdfbytes) # open it as a PDF document
>>> # now use 'pdf' like any PDF document
2)将Page.get_text()与“dic”参数一起使用。这适用于所有文档类型。它将提取页面上显示的所有文本和图像,格式化为Python字典。每个图像都将出现在一个图像块中,其中包含元信息和二进制图像数据。有关字典结构的详细信息,请参阅TextPage。该方法同样适用于PDF文件。这将创建页面上显示的所有图像的列表:
>>> d = page.get_text("dict")
>>> blocks = d["blocks"] # the list of block dictionaries
>>> imgblocks = [b for b in blocks if b["type"] == 1]
>>> pprint(imgblocks[0])
{'bbox': (100.0, 135.8769989013672, 300.0, 364.1230163574219),
'bpc': 8,
'colorspace': 3,
'ext': 'jpeg',
'height': 501,
'image': b'\xff\xd8\xff\xe0\x00\x10JFIF\...', # CAUTION: LARGE!
'size': 80518,
'transform': (200.0, 0.0, -0.0, 228.2460174560547, 100.0, 135.8769989013672),
'type': 1,
'width': 439,
'xres': 96,
'yres': 96}
7、如何提取图像:PDF文档
与PDF中的任何其他“对象”一样,图像由交叉引用号(xref,整数)标识。如果您知道这个数字,您有两种方法可以访问图像数据:
1)用指令 pix = pymupdf.Pixmap(doc, xref) 创建图像的像素图。
这种方法非常快(个位数微秒)。像素图的属性(宽度、高度……)将反映图像的属性。在这种情况下,无法判断嵌入的原始图像具有哪种图像格式。
2)提取带有 img = doc.extract_image(xref). 的图像。
这是一个包含二进制图像数据的字典img[“image”]。还提供了许多元数据——大部分与您在图像的像素图中找到的相同。
主要区别在于字符串 img[“ext”],它指定了图像格式:除了“png”之外,还可以出现“jpeg”、“bmp”、“tiff”等字符串。
如果您想存储到磁盘,请使用此字符串作为文件扩展名。
此方法的执行速度应与语句的组合速度进行比较 pix = pymupdf.Pixmap(doc, xref);pix.tobytes()。
如果嵌入的图像是PNG格式,则 Document.extract_image() 的速度大致相同(并且二进制图像数据相同)。否则,这种方法快了几千倍,而且图像数据要小得多。
问题仍然是:“我怎么知道这些图像的‘xref’数量?”对此有两个答案:
1)“检查页面对象:” 循环浏览Page.get_images()的项目。
这是一个列表,它的项目看起来像 [xref, smask, …],包含图像的 xref。然后可以将此xref 与上述方法之一一起使用。
将此方法用于**有效(未损坏)**文档。但是要小心,同一图像可能会被多次引用(由不同的页面),因此您可能需要提供一种避免多次提取的机制。
2)“不需要知道:” 循环遍历文档的所有xrefs列表,并为每一个执行一个Document.extract_image()。
如果返回的字典为空,则继续-此xref没有图像。如果PDF损坏(无法使用页面),请注意,PDF通常包含“伪图像”(“模板蒙版”),其特殊目的是定义其他一些图像的透明度。
您可能希望提供逻辑以从提取中排除那些。还可以查看下一节。
对于这两种提取方法,都存在即用型通用脚本:
extract-from-pages.py 逐页提取图像:
并extract-from-xref.py 通过xref表提取图像:
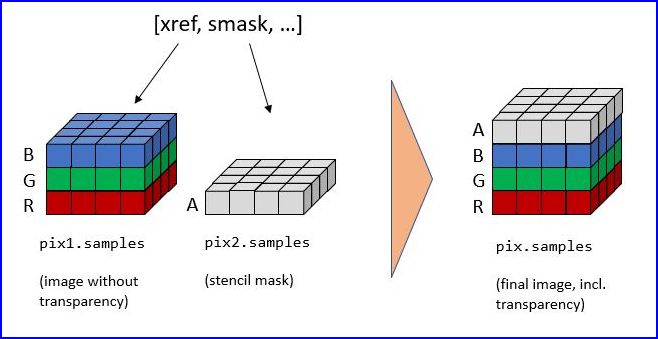
8、如何处理图像掩码
PDF中的一些图像带有图像掩码。在最简单的形式中,掩码表示作为单独图像存储的alpha(透明度)字节。
为了重建具有掩码的图像的原始图像,必须使用从掩码中获取的透明度字节来“丰富”它。
在PyMuPDF中,可以通过以下两种方式之一识别图像是否具有这样的蒙版:
- 一个项目的
Document.get_page_images()具有一般格式(xref, smask, ...),其中xref是图像的xref和smask,如果是正数,则它是掩码的xref。 - (字典)结果的
Document.extract_image()有一个键*“smask”*,它还包含任何掩码的xref(如果为正)。
如果 smask == 0 然后图片遇到通过 xref 可以如此处理。
要使用PyMuPDF恢复原始图像,必须执行以下过程:
>>> pix1 = pymupdf.Pixmap(doc.extract_image(xref)["image"]) # (1) pixmap of image w/o alpha
>>> mask = pymupdf.Pixmap(doc.extract_image(smask)["image"]) # (2) mask pixmap
>>> pix = pymupdf.Pixmap(pix1, mask) # (3) copy of pix1, image mask added
步骤(1)创建基本图像的像素图。步骤(2)对图像蒙版做同样的事情。步骤(3)添加一个alpha通道并用透明度信息填充它。
上述脚本extract-from-pages.py和extract-from-xref.py也包含此逻辑。
9、如何制作所有图片(或文件)的PDF
我们在这里展示了三个脚本,它们获取(图像和其他)文件列表并将它们全部放在一个PDF中。
方法1:将图像插入为页面
第一个将每个图像转换为具有相同尺寸的PDF页面。结果将是每个图像一页的PDF。它仅适用于支持的图像文件格式:
import os, pymupdf
import PySimpleGUI as psg # for showing a progress bar
doc = pymupdf.open() # PDF with the pictures
imgdir = "D:/2012_10_05" # where the pics are
imglist = os.listdir(imgdir) # list of them
imgcount = len(imglist) # pic count
for i, f in enumerate(imglist):
img = pymupdf.open(os.path.join(imgdir, f)) # open pic as document
rect = img[0].rect # pic dimension
pdfbytes = img.convert_to_pdf() # make a PDF stream
img.close() # no longer needed
imgPDF = pymupdf.open("pdf", pdfbytes) # open stream as PDF
page = doc.new_page(width = rect.width, # new page with ...
height = rect.height) # pic dimension
page.show_pdf_page(rect, imgPDF, 0) # image fills the page
psg.EasyProgressMeter("Import Images", # show our progress
i+1, imgcount)
doc.save("all-my-pics.pdf")
这将生成仅略大于组合图片大小的PDF。性能方面的一些数字:
上面的脚本在我的机器上需要大约1分钟的149张图片,总大小为514 MB(与生成的PDF大小大致相同)。
查看这里更完整的源代码:它提供了一个目录选择对话框,并跳过不受支持的文件和非文件条目。
注:我们可能使用Page.insert_image()而不是Page.show_pdf_page(),结果将是一个类似的文件。然而,根据图像类型,它可能存储未压缩图像。因此,必须使用保存选项通货紧缩=True来实现合理的文件大小,这极大地增加了大量图像的运行时间。因此,这里不能推荐这种替代方案。
方法 2: Embedding Files
第二个脚本embeds任意文件,而不仅仅是图像。由于技术原因,生成的PDF将只有一个(空)页面。要稍后再次访问嵌入文件,您需要一个合适的PDF查看器来显示和/或提取嵌入文件:
import os, pymupdf
import PySimpleGUI as psg # for showing progress bar
doc = pymupdf.open() # PDF with the pictures
imgdir = "D:/2012_10_05" # where my files are
imglist = os.listdir(imgdir) # list of pictures
imgcount = len(imglist) # pic count
imglist.sort() # nicely sort them
for i, f in enumerate(imglist):
img = open(os.path.join(imgdir,f), "rb").read() # make pic stream
doc.embfile_add(img, f, filename=f, # and embed it
ufilename=f, desc=f)
psg.EasyProgressMeter("Embedding Files", # show our progress
i+1, imgcount)
page = doc.new_page() # at least 1 page is needed
doc.save("all-my-pics-embedded.pdf")
这是迄今为止最快的方法,它也产生了尽可能小的输出文件大小。上面的图片在我的机器上需要20秒,产生了510 MB的PDF大小。看这里有一个更完整的源代码:它提供了一个目录选择对话框,并跳过了非文件条目。
方法3:附加文件
实现此任务的第三种方法是通过页面注释附加文件,完整源代码见此处。
这与之前的脚本具有相似的性能,并且它也产生了相似的文件大小。它将生成PDF页面,其中显示每个附加文件的“文件附件”图标。
注:嵌入和附加方法都可用于任意文件-而不仅仅是图像。
注:我们强烈建议使用很棒的包PySimpleGUI来显示可能运行很长时间的任务的进度表。它是纯Python,使用Tkinter(没有额外的GUI包),只需要一行代码!
10、如何创建矢量图像
从文档页面创建图像的常用方法是Page.get_pixmap()。
像素图代表光栅图像,因此您必须在创建时决定其质量(即分辨率)。以后不能更改。
PyMuPDF还提供了一种以SVG格式(可缩放的矢量图形,用XML语法定义)创建页面矢量图像的方法。
SVG图像在缩放级别上保持精确(当然,嵌入其中的任何光栅图形元素除外)。
指令 svg=page.get_svg_image(矩阵=pymupdf. Identity)传递一个UTF-8字符串svg,该字符串可以以扩展名“.svg”存储。
11、如何转换图像
就像其他功能一样,PyMuPDF的图像转换很容易。在许多情况下,它可以避免使用其他图形包,如PIL/Pillow。
尽管如此,与枕头的接口几乎是微不足道的。
| 输入格式 | 输出格式 | 描述 |
|---|---|---|
| BMP | . | Windows位图 |
| JPEG格式 | JPEG格式 | 联合摄影专家组 |
| JXR | . | JPEG扩展范围 |
| JPX/JP2 | . | JPEG 2000 |
| GIF | . | 图形交换格式 |
| TIFF | . | 标记图像文件格式 |
| 巴布亚新几内亚 | 巴布亚新几内亚 | 便携式网络图形 |
| PNM | PNM | Portable Anymap |
| PGM | PGM | Portable Graymap |
| PBM | PBM | Portable Bitmap |
| PPM | PPM | Portable Pixmap |
| PAM | PAM | Portable Arbitrary Map |
| . | PSD | Adobe Photoshop Document |
| . | PS | Adobe Postscript |
The general scheme is just the following two lines:
pix = pymupdf.Pixmap("input.xxx") # any supported input format
pix.save("output.yyy") # any supported output format
Remarks
pymupdf.Pixmap(arg)的 input 参数 可以是文件 或包含图像的bytes / io.BytesIO对象。- 除了输出文件,您还可以通过
pix.tobytes(“yyy”)创建一个bytes对象并传递它。 - 当然,输入和输出格式必须在色彩空间和透明度方面兼容。如果需要调整,Pixmap类包含电池。
注:将JPEG转换为Photoshop:
pix = pymupdf.Pixmap("myfamily.jpg")
pix.save("myfamily.psd")
注:将JPEG转换为 Tkinter PhotoImage。任何 RGB/no-alpha 图像的工作原理都完全相同。
转换为便携式Anymap格式(PPM、PGM等)之一就可以了,因为所有Tkinter版本都支持它们:
import tkinter as tk
pix = pymupdf.Pixmap("input.jpg") # or any RGB / no-alpha image
tkimg = tk.PhotoImage(data=pix.tobytes("ppm"))
注:将带有 alpha 的PNG转换为 Tkinter PhotoImage。这需要在我们进行PPM转换之前删除alpha字节:
import tkinter as tk
pix = pymupdf.Pixmap("input.png") # may have an alpha channel
if pix.alpha: # we have an alpha channel!
pix = pymupdf.Pixmap(pix, 0) # remove it
tkimg = tk.PhotoImage(data=pix.tobytes("ppm"))
12、如何使用像素贴图:粘合图像
这展示了如何将像素图用于纯粹的图形、非文档目的。该脚本读取一个图像文件并创建一个新图像,该图像由3*4个原始图块组成:
import pymupdf
src = pymupdf.Pixmap("img-7edges.png") # create pixmap from a picture
col = 3 # tiles per row
lin = 4 # tiles per column
tar_w = src.width * col # width of target
tar_h = src.height * lin # height of target
# create target pixmap
tar_pix = pymupdf.Pixmap(src.colorspace, (0, 0, tar_w, tar_h), src.alpha)
# now fill target with the tiles
for i in range(col):
for j in range(lin):
src.set_origin(src.width * i, src.height * j)
tar_pix.copy(src, src.irect) # copy input to new loc
tar_pix.save("tar.png")
这是输入图片:

这是输出:

13、如何使用像素图:制作分形
这是另一个创建Sierpinski的地毯的Pixmap示例——将康托集推广到二维的分形。
给定一个方形地毯,标记其9个子suqares(3乘以3)并剪掉中间的那个。以相同的方式对待其余8个子正方形中的每一个,并继续无穷大。
最终结果是一个面积为零、分形维数为1.8928的集合……
此脚本通过降低到一个像素的颗粒度来创建它作为PNG的近似图像。要提高图像精度,请更改n(精度)的值:
import pymupdf, time
if not list(map(int, pymupdf.VersionBind.split("."))) >= [1, 14, 8]:
raise SystemExit("need PyMuPDF v1.14.8 for this script")
n = 6 # depth (precision)
d = 3**n # edge length
t0 = time.perf_counter()
ir = (0, 0, d, d) # the pixmap rectangle
pm = pymupdf.Pixmap(pymupdf.csRGB, ir, False)
pm.set_rect(pm.irect, (255,255,0)) # fill it with some background color
color = (0, 0, 255) # color to fill the punch holes
# alternatively, define a 'fill' pixmap for the punch holes
# this could be anything, e.g. some photo image ...
fill = pymupdf.Pixmap(pymupdf.csRGB, ir, False) # same size as 'pm'
fill.set_rect(fill.irect, (0, 255, 255)) # put some color in
def punch(x, y, step):
"""Recursively "punch a hole" in the central square of a pixmap.
Arguments are top-left coords and the step width.
Some alternative punching methods are commented out.
"""
s = step // 3 # the new step
# iterate through the 9 sub-squares
# the central one will be filled with the color
for i in range(3):
for j in range(3):
if i != j or i != 1: # this is not the central cube
if s >= 3: # recursing needed?
punch(x+i*s, y+j*s, s) # recurse
else: # punching alternatives are:
pm.set_rect((x+s, y+s, x+2*s, y+2*s), color) # fill with a color
#pm.copy(fill, (x+s, y+s, x+2*s, y+2*s)) # copy from fill
#pm.invert_irect((x+s, y+s, x+2*s, y+2*s)) # invert colors
return
#==============================================================================
# main program
#==============================================================================
# now start punching holes into the pixmap
punch(0, 0, d)
t1 = time.perf_counter()
pm.save("sierpinski-punch.png")
t2 = time.perf_counter()
print ("%g sec to create / fill the pixmap" % round(t1-t0,3))
print ("%g sec to save the image" % round(t2-t1,3))
结果应该如下所示:

14、如何与NumPy接口
这展示了如何从numpy数组创建PNG文件(比大多数其他方法快几倍):
import numpy as np
import pymupdf
#==============================================================================
# create a fun-colored width * height PNG with pymupdf and numpy
#==============================================================================
height = 150
width = 100
bild = np.ndarray((height, width, 3), dtype=np.uint8)
for i in range(height):
for j in range(width):
# one pixel (some fun coloring)
bild[i, j] = [(i+j)%256, i%256, j%256]
samples = bytearray(bild.tostring()) # get plain pixel data from numpy array
pix = pymupdf.Pixmap(pymupdf.csRGB, width, height, samples, alpha=False)
pix.save("test.png")
15、如何将图像添加到PDF页面
有两种方法可以将图像添加到PDF页面:Page.insert_image()和Page.show_pdf_page()。这两种方法有共同点,但也有区别。
| 判据 | Page.insert_image() | Page.show_pdf_page() |
|---|---|---|
| 可展示内容 | 图像文件、内存中的图像、像素图 | PDF页面 |
| 显示分辨率 | 图像分辨率 | 向量化(光栅页面内容除外) |
| 旋转 | 0、90、180或270度 | 任意角度 |
| 裁剪 | 否(仅限完整图像) | 是的 |
| 保持长宽比 | 是(默认选项) | 是(默认选项) |
| 透明度(水印) | 取决于图像 | 取决于页面 |
| 位置/放置 | 缩放以适应目标矩形 | 缩放以适应目标矩形 |
| 性能 | 自动防止重复; | 自动防止重复; |
| 多页图片支持 | 不知道. | 是的 |
| 易用性 | 简单、直观; | 简单、直观; 可用于所有文档类型 (包括图像!)转换为 PDF通过Document.convert_to_pdf() |
基本代码模式的Page.insert_image()。确切地说一个参数文件名/流/像素图必须给出,如果不重新插入现有的图像:
page.insert_image(
rect, # where to place the image (rect-like)
filename=None, # image in a file
stream=None, # image in memory (bytes)
pixmap=None, # image from pixmap
mask=None, # specify alpha channel separately
rotate=0, # rotate (int, multiple of 90)
xref=0, # re-use existing image
oc=0, # control visibility via OCG / OCMD
keep_proportion=True, # keep aspect ratio
overlay=True, # put in foreground
)
基本代码模式Page.show_pdf_page()。源和目标PDF必须是不同的Document对象(但可以从同一个文件打开):
page.show_pdf_page(
rect, # where to place the image (rect-like)
src, # source PDF
pno=0, # page number in source PDF
clip=None, # only display this area (rect-like)
rotate=0, # rotate (float, any value)
oc=0, # control visibility via OCG / OCMD
keep_proportion=True, # keep aspect ratio
overlay=True, # put in foreground
)
16、如何使用像素图:检查文本可见性
给定的一段文字在页面上是否真的可见取决于许多因素:
- 文本不被另一个对象覆盖,但可能具有与背景相同的颜色,即白色对白色等。
- 文本可能被图像或矢量图形覆盖。检测到这一点是一项重要的能力,例如发现严重匿名的法律文件。
- 文本是隐藏创建的。OCR工具通常使用此技术将识别的文本存储在页面上的不可见图层中。
以下显示了如何检测上面的情况1或情况2。如果覆盖对象是单色:
pix = page.get_pixmap(dpi=150) # make page image with a decent resolution
# the following matrix transforms page to pixmap coordinates
mat = page.rect.torect(pix.irect)
# search for some string "needle"
rlist = page.search_for("needle")
# check the visibility for each hit rectangle
for rect in rlist:
if pix.color_topusage(clip=rect * mat)[0] > 0.95:
print("'needle' is invisible here:", rect)
方法Pixmap.color_topusage()返回一个元组(ratio, pixel),其中 0<比率<=1,像素是颜色的像素值。请注意,我们只创建一次像素图。如果有多个命中矩形,这可以节省大量流转时长。
上面代码的逻辑是:如果针的矩形是(“几乎”:>95%)单色,那么文本就不可见。可见文本的典型结果返回背景的颜色(大部分是白色)和大约0.7到0.8的比率,例如(0.685, b'xffxffxff')。
四、注释
1、如何添加和修改注释
在PyMuPDF中,可以通过Page方法添加新的注解,一旦注解存在,就可以在很大程度上使用Annot类的方法进行修改。
注释只能插入PDF页面-其他文档类型不支持注释插入。
与许多其他工具相比,注释的初始插入只有最少数量的属性。我们让程序员来设置属性,如作者、创建日期或主题。
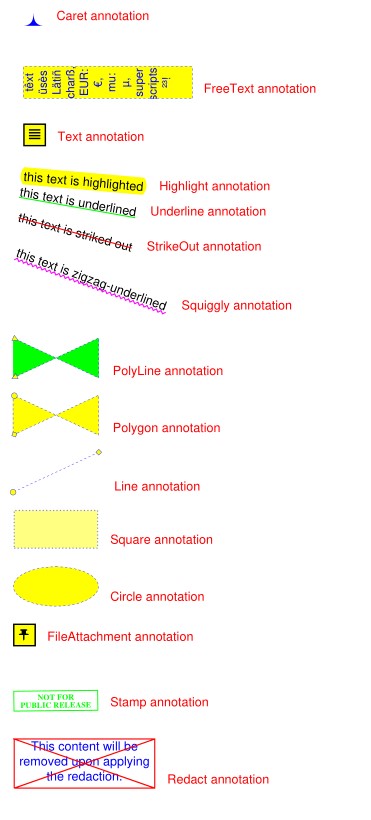
作为这些功能的概述,请查看以下脚本,该脚本使用大多数可用注释填充PDF页面。查看接下来的部分以了解更多特殊情况:
# -*- coding: utf-8 -*-
"""
***------
Demo script showing how annotations can be added to a PDF using PyMuPDF.
It contains the following annotation types:
Caret, Text, FreeText, text markers (underline, strike-out, highlight,
squiggle), Circle, Square, Line, PolyLine, Polygon, FileAttachment, Stamp
and Redaction.
There is some effort to vary appearances by adding colors, line ends,
opacity, rotation, dashed lines, etc.
Dependencies
***------
PyMuPDF v1.17.0
***------
"""
from __future__ import print_function
import gc
import sys
import pymupdf
print(pymupdf.__doc__)
if pymupdf.VersionBind.split(".") < ["1", "17", "0"]:
sys.exit("PyMuPDF v1.17.0+ is needed.")
gc.set_debug(gc.DEBUG_UNCOLLECTABLE)
highlight = "this text is highlighted"
underline = "this text is underlined"
strikeout = "this text is striked out"
squiggled = "this text is zigzag-underlined"
red = (1, 0, 0)
blue = (0, 0, 1)
gold = (1, 1, 0)
green = (0, 1, 0)
displ = pymupdf.Rect(0, 50, 0, 50)
r = pymupdf.Rect(72, 72, 220, 100)
t1 = u"têxt üsès Lätiñ charß,\nEUR: €, mu: µ, super scripts: ²³!"
def print_descr(annot):
"""Print a short description to the right of each annot rect."""
annot.parent.insert_text(
annot.rect.br + (10, -5), "%s annotation" % annot.type[1], color=red
)
doc = pymupdf.open()
page = doc.new_page()
page.set_rotation(0)
annot = page.add_caret_annot(r.tl)
print_descr(annot)
r = r + displ
annot = page.add_freetext_annot(
r,
t1,
fontsize=10,
rotate=90,
text_color=blue,
fill_color=gold,
align=pymupdf.TEXT_ALIGN_CENTER,
)
annot.set_border(width=0.3, dashes=[2])
annot.update(text_color=blue, fill_color=gold)
print_descr(annot)
r = annot.rect + displ
annot = page.add_text_annot(r.tl, t1)
print_descr(annot)
# Adding text marker annotations:
# first insert a unique text, then search for it, then mark it
pos = annot.rect.tl + displ.tl
page.insert_text(
pos, # insertion point
highlight, # inserted text
morph=(pos, pymupdf.Matrix(-5)), # rotate around insertion point
)
rl = page.search_for(highlight, quads=True) # need a quad b/o tilted text
annot = page.add_highlight_annot(rl[0])
print_descr(annot)
pos = annot.rect.bl # next insertion point
page.insert_text(pos, underline, morph=(pos, pymupdf.Matrix(-10)))
rl = page.search_for(underline, quads=True)
annot = page.add_underline_annot(rl[0])
print_descr(annot)
pos = annot.rect.bl
page.insert_text(pos, strikeout, morph=(pos, pymupdf.Matrix(-15)))
rl = page.search_for(strikeout, quads=True)
annot = page.add_strikeout_annot(rl[0])
print_descr(annot)
pos = annot.rect.bl
page.insert_text(pos, squiggled, morph=(pos, pymupdf.Matrix(-20)))
rl = page.search_for(squiggled, quads=True)
annot = page.add_squiggly_annot(rl[0])
print_descr(annot)
pos = annot.rect.bl
r = pymupdf.Rect(pos, pos.x + 75, pos.y + 35) + (0, 20, 0, 20)
annot = page.add_polyline_annot([r.bl, r.tr, r.br, r.tl]) # 'Polyline'
annot.set_border(width=0.3, dashes=[2])
annot.set_colors(stroke=blue, fill=green)
annot.set_line_ends(pymupdf.PDF_ANNOT_LE_CLOSED_ARROW, pymupdf.PDF_ANNOT_LE_R_CLOSED_ARROW)
annot.update(fill_color=(1, 1, 0))
print_descr(annot)
r += displ
annot = page.add_polygon_annot([r.bl, r.tr, r.br, r.tl]) # 'Polygon'
annot.set_border(width=0.3, dashes=[2])
annot.set_colors(stroke=blue, fill=gold)
annot.set_line_ends(pymupdf.PDF_ANNOT_LE_DIAMOND, pymupdf.PDF_ANNOT_LE_CIRCLE)
annot.update()
print_descr(annot)
r += displ
annot = page.add_line_annot(r.tr, r.bl) # 'Line'
annot.set_border(width=0.3, dashes=[2])
annot.set_colors(stroke=blue, fill=gold)
annot.set_line_ends(pymupdf.PDF_ANNOT_LE_DIAMOND, pymupdf.PDF_ANNOT_LE_CIRCLE)
annot.update()
print_descr(annot)
r += displ
annot = page.add_rect_annot(r) # 'Square'
annot.set_border(width=1, dashes=[1, 2])
annot.set_colors(stroke=blue, fill=gold)
annot.update(opacity=0.5)
print_descr(annot)
r += displ
annot = page.add_circle_annot(r) # 'Circle'
annot.set_border(width=0.3, dashes=[2])
annot.set_colors(stroke=blue, fill=gold)
annot.update()
print_descr(annot)
r += displ
annot = page.add_file_annot(
r.tl, b"just anything for testing", "testdata.txt" # 'FileAttachment'
)
print_descr(annot) # annot.rect
r += displ
annot = page.add_stamp_annot(r, stamp=10) # 'Stamp'
annot.set_colors(stroke=green)
annot.update()
print_descr(annot)
r += displ + (0, 0, 50, 10)
rc = page.insert_textbox(
r,
"This content will be removed upon applying the redaction.",
color=blue,
align=pymupdf.TEXT_ALIGN_CENTER,
)
annot = page.add_redact_annot(r)
print_descr(annot)
doc.save(__file__.replace(".py", "-%i.pdf" % page.rotation), deflate=True)
此脚本应导致以下输出:
2、如何使用FreeText
这个脚本展示了几种处理“FreeText”注释的方法:
# -*- coding: utf-8 -*-
import pymupdf
# some colors
blue = (0,0,1)
green = (0,1,0)
red = (1,0,0)
gold = (1,1,0)
# a new PDF with 1 page
doc = pymupdf.open()
page = doc.new_page()
# 3 rectangles, same size, above each other
r1 = pymupdf.Rect(100,100,200,150)
r2 = r1 + (0,75,0,75)
r3 = r2 + (0,75,0,75)
# the text, Latin alphabet
t = "¡Un pequeño texto para practicar!"
# add 3 annots, modify the last one somewhat
a1 = page.add_freetext_annot(r1, t, color=red)
a2 = page.add_freetext_annot(r2, t, fontname="Ti", color=blue)
a3 = page.add_freetext_annot(r3, t, fontname="Co", color=blue, rotate=90)
a3.set_border(width=0)
a3.update(fontsize=8, fill_color=gold)
# save the PDF
doc.save("a-freetext.pdf")
结果如下所示:

3、使用按钮和JavaScript
从MuPDF v1.16开始,“FreeText”注释不再支持泰晤士报-Roman、Helvetica或Courier字体的粗体或斜体字版本。
非常感谢您我们的用户@kurokawaikki,他贡献了以下脚本来规避这一限制。
"""
Problem: Since MuPDF v1.16 a 'Freetext' annotation font is restricted to the
"normal" versions (no bold, no italics) of Times-Roman, Helvetica, Courier.
It is impossible to use PyMuPDF to modify this.
Solution: Using Adobe's JavaScript API, it is possible to manipulate properties
of Freetext annotations. Check out these references:
https://www.adobe.com/content/dam/acom/en/devnet/acrobat/pdfs/js_api_reference.pdf,
or https://www.adobe.com/devnet/acrobat/documentation.html.
Function 'this.getAnnots()' will return all annotations as an array. We loop
over this array to set the properties of the text through the 'richContents'
attribute.
There is no explicit property to set text to bold, but it is possible to set
fontWeight=800 (400 is the normal size) of richContents.
Other attributes, like color, italics, etc. can also be set via richContents.
If we have 'FreeText' annotations created with PyMuPDF, we can make use of this
JavaScript feature to modify the font - thus circumventing the above restriction.
Use PyMuPDF v1.16.12 to create a push button that executes a Javascript
containing the desired code. This is what this program does.
Then open the resulting file with Adobe reader (!).
After clicking on the button, all Freetext annotations will be bold, and the
file can be saved.
If desired, the button can be removed again, using free tools like PyMuPDF or
PDF XChange editor.
Note / Caution:
***--
The JavaScript will **only** work if the file is opened with Adobe Acrobat reader!
When using other PDF viewers, the reaction is unforeseeable.
"""
import sys
import pymupdf
# this JavaScript will execute when the button is clicked:
jscript = """
var annt = this.getAnnots();
annt.forEach(function (item, index) {
try {
var span = item.richContents;
span.forEach(function (it, dx) {
it.fontWeight = 800;
})
item.richContents = span;
} catch (err) {}
});
app.alert('Done');
"""
i_fn = sys.argv[1] # input file name
o_fn = "bold-" + i_fn # output filename
doc = pymupdf.open(i_fn) # open input
page = doc[0] # get desired page
# --------
# make a push button for invoking the JavaScript
# --------
widget = pymupdf.Widget() # create widget
# make it a 'PushButton'
widget.field_type = pymupdf.PDF_WIDGET_TYPE_BUTTON
widget.field_flags = pymupdf.PDF_BTN_FIELD_IS_PUSHBUTTON
widget.rect = pymupdf.Rect(5, 5, 20, 20) # button position
widget.script = jscript # fill in JavaScript source text
widget.field_name = "Make bold" # arbitrary name
widget.field_value = "Off" # arbitrary value
widget.fill_color = (0, 0, 1) # make button visible
annot = page.add_widget(widget) # add the widget to the page
doc.save(o_fn) # output the file
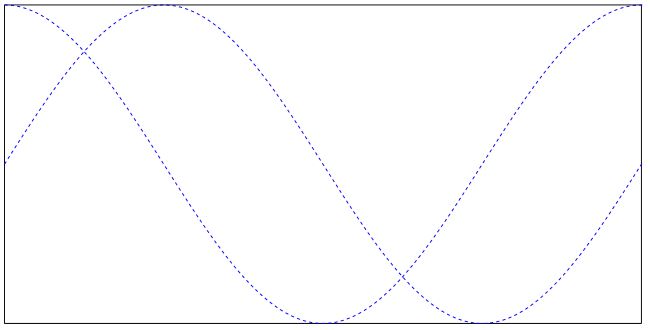
4、如何使用墨水注释
墨水注释用于包含手绘涂鸦。一个典型的例子可能是您的签名由名字和姓氏组成的图像。
从技术上讲,墨水注释被实现为点列表的列表。每个点列表被视为连接点的连续线。不同的点列表代表注释的独立线段。
以下脚本使用两条数学曲线(正弦和余弦函数图)作为线段创建墨水注释:
import math
import pymupdf
#----
# preliminary stuff: create function value lists for sine and cosine
#----
w360 = math.pi * 2 # go through full circle
deg = w360 / 360 # 1 degree as radians
rect = pymupdf.Rect(100,200, 300, 300) # use this rectangle
first_x = rect.x0 # x starts from left
first_y = rect.y0 + rect.height / 2. # rect middle means y = 0
x_step = rect.width / 360 # rect width means 360 degrees
y_scale = rect.height / 2. # rect height means 2
sin_points = [] # sine values go here
cos_points = [] # cosine values go here
for x in range(362): # now fill in the values
x_coord = x * x_step + first_x # current x coordinate
y = -math.sin(x * deg) # sine
p = (x_coord, y * y_scale + first_y) # corresponding point
sin_points.append(p) # append
y = -math.cos(x * deg) # cosine
p = (x_coord, y * y_scale + first_y) # corresponding point
cos_points.append(p) # append
#----
# create the document with one page
#----
doc = pymupdf.open() # make new PDF
page = doc.new_page() # give it a page
#----
# add the Ink annotation, consisting of 2 curve segments
#----
annot = page.addInkAnnot((sin_points, cos_points))
# let it look a little nicer
annot.set_border(width=0.3, dashes=[1,]) # line thickness, some dashing
annot.set_colors(stroke=(0,0,1)) # make the lines blue
annot.update() # update the appearance
page.draw_rect(rect, width=0.3) # only to demonstrate we did OK
doc.save("a-inktest.pdf")
这是结果:
五、绘图和图形
注:当这里提到术语“绘图”或“图形”时,我们指的是“矢量图形”或“线条艺术”。
因此,请将这些术语视为同义词!
PDF文件支持基本绘图操作作为其语法的一部分。这些是矢量图形,包括基本的几何对象,如线、曲线、圆形、矩形,包括指定颜色。
此类操作的语法在Adobe PDF参考资料第643页的“运算符摘要”中定义。为PDF页面指定这些运算符发生在其contents对象中。
PyMuPDF通过其Shape类实现了大部分可用功能,这与其他包(例如reportlab)中的“画布”等概念相当。
一个形状总是作为一个页面的子页面创建,通常使用一个指令,如shape = page.new_shape()。该类定义了许多在页面区域执行绘图操作的方法。例如,last_point = shape.draw_rect(rect)沿着适当定义的rect = pymupdf.Rect(...)的边界绘制一个矩形。
返回的last_point 始终是绘图操作结束的点(“最后一点”)。每个这样的基本绘图都需要一个后续的Shape.finish()来“关闭”它,但是可能有多个绘图有一个通用的finish()方法。
事实上,Shape.finish() 定义了一组前面的绘制操作来形成一个潜在的相当复杂的图形对象。PyMuPDF在shapes_and_symbols.py中提供了几个预定义的图形来演示这是如何工作的。
如果导入此脚本,也可以直接使用其图形,如下例所示:
# -*- coding: utf-8 -*-
"""
Created on Sun Dec 9 08:34:06 2018
@author: Jorj
@license: GNU AFFERO GPL V3
Create a list of available symbols defined in shapes_and_symbols.py
This also demonstrates an example usage: how these symbols could be used
as bullet-point symbols in some text.
"""
import pymupdf
import shapes_and_symbols as sas
# list of available symbol functions and their descriptions
tlist = [
(sas.arrow, "arrow (easy)"),
(sas.caro, "caro (easy)"),
(sas.clover, "clover (easy)"),
(sas.diamond, "diamond (easy)"),
(sas.dontenter, "do not enter (medium)"),
(sas.frowney, "frowney (medium)"),
(sas.hand, "hand (complex)"),
(sas.heart, "heart (easy)"),
(sas.pencil, "pencil (very complex)"),
(sas.smiley, "smiley (easy)"),
]
r = pymupdf.Rect(50, 50, 100, 100) # first rect to contain a symbol
d = pymupdf.Rect(0, r.height + 10, 0, r.height + 10) # displacement to next rect
p = (15, -r.height * 0.2) # starting point of explanation text
rlist = [r] # rectangle list
for i in range(1, len(tlist)): # fill in all the rectangles
rlist.append(rlist[i-1] + d)
doc = pymupdf.open() # create empty PDF
page = doc.new_page() # create an empty page
shape = page.new_shape() # start a Shape (canvas)
for i, r in enumerate(rlist):
tlist[i][0](shape, rlist[i]) # execute symbol creation
shape.insert_text(rlist[i].br + p, # insert description text
tlist[i][1], fontsize=r.height/1.2)
# store everything to the page's /Contents object
shape.commit()
import os
scriptdir = os.path.dirname(__file__)
doc.save(os.path.join(scriptdir, "symbol-list.pdf")) # save the PDF
这是脚本的结果:

1、如何提取图纸
- v1.18.0中的新功能
页面发出的绘图命令(矢量图形)可以提取为字典列表。有趣的是,这适用于所有支持的文档类型——不仅仅是PDF:所以你也可以将它用于XPS、EPUB和其他。
页面方法,Page.get_drawings()访问绘图命令并将它们转换为Python字典列表。每个字典——称为“路径”——代表一个单独的绘图——它可能像一条线一样简单,也可能像代表前一节形状之一的线和曲线的复杂组合。
这个路径字典的设计使得Shape类及其方法可以很容易地使用它。下面是一个带有一个路径的页面的示例,它在矩形Rect(100, 100, 200, 200)内绘制一个带红色边框的黄色圆圈:
>>> pprint(page.get_drawings())
[{'closePath': True,
'color': [1.0, 0.0, 0.0],
'dashes': '[] 0',
'even_odd': False,
'fill': [1.0, 1.0, 0.0],
'items': [('c',
Point(100.0, 150.0),
Point(100.0, 177.614013671875),
Point(122.38600158691406, 200.0),
Point(150.0, 200.0)),
('c',
Point(150.0, 200.0),
Point(177.61399841308594, 200.0),
Point(200.0, 177.614013671875),
Point(200.0, 150.0)),
('c',
Point(200.0, 150.0),
Point(200.0, 122.385986328125),
Point(177.61399841308594, 100.0),
Point(150.0, 100.0)),
('c',
Point(150.0, 100.0),
Point(122.38600158691406, 100.0),
Point(100.0, 122.385986328125),
Point(100.0, 150.0))],
'lineCap': (0, 0, 0),
'lineJoin': 0,
'opacity': 1.0,
'rect': Rect(100.0, 100.0, 200.0, 200.0),
'width': 1.0}]
>>>
注:您需要(至少)4 Bézier曲线(3阶)以可接受的精度绘制圆。有关背景知识,请参阅维基百科文章。
以下是提取页面绘图并在新页面上重新绘制它们的代码片段:
import pymupdf
doc = pymupdf.open("some.file")
page = doc[0]
paths = page.get_drawings() # extract existing drawings
# this is a list of "paths", which can directly be drawn again using Shape
# ------
#
# define some output page with the same dimensions
outpdf = pymupdf.open()
outpage = outpdf.new_page(width=page.rect.width, height=page.rect.height)
shape = outpage.new_shape() # make a drawing canvas for the output page
# ----
# loop through the paths and draw them
# ----
for path in paths:
# --
# draw each entry of the 'items' list
# --
for item in path["items"]: # these are the draw commands
if item[0] == "l": # line
shape.draw_line(item[1], item[2])
elif item[0] == "re": # rectangle
shape.draw_rect(item[1])
elif item[0] == "qu": # quad
shape.draw_quad(item[1])
elif item[0] == "c": # curve
shape.draw_bezier(item[1], item[2], item[3], item[4])
else:
raise ValueError("unhandled drawing", item)
# -------
# all items are drawn, now apply the common properties
# to finish the path
# -------
shape.finish(
fill=path["fill"], # fill color
color=path["color"], # line color
dashes=path["dashes"], # line dashing
even_odd=path.get("even_odd", True), # control color of overlaps
closePath=path["closePath"], # whether to connect last and first point
lineJoin=path["lineJoin"], # how line joins should look like
lineCap=max(path["lineCap"]), # how line ends should look like
width=path["width"], # line width
stroke_opacity=path.get("stroke_opacity", 1), # same value for both
fill_opacity=path.get("fill_opacity", 1), # opacity parameters
)
# all paths processed - commit the shape to its page
shape.commit()
outpdf.save("drawings-page-0.pdf")
可以看出,与Shape类有很高的一致性。有一个例外:出于技术原因,lineCap在这里是一个包含3个数字的元组,而在Shape(和PDF)中它是一个整数。所以我们只取该元组的最大值。
以下是由前面的脚本创建的示例页面的输入和输出之间的比较:

注:如图所示,图形的重建并不完美。从这个版本开始,将不会复制以下方面:
- 页面定义可能很复杂,包括不显示/隐藏某些区域以保持它们不可见的说明。
Page.get_drawings()-它将始终返回所有路径。
注:您可以使用路径列表来制作自己的列表,例如页面上的所有线条或所有矩形,并按标准(如页面上的颜色或位置等)进行子选择。
2、如何删除图纸
要删除绘图/矢量图形,我们必须对绘图的边界框使用编辑注释,然后添加并应用编辑以删除它。
以下代码显示了删除页面上找到的第一幅绘图的示例:
paths = page.get_drawings()
rect = paths[0]["rect"] # rectangle of the 1st drawing
page.add_redact_annot(rect)
page.apply_redactions(0,2,1) # potentially set options for any of images, drawings, text
注:见Page.apply_redactions()了解可以发送的参数选项——您可以将删除选项应用于注释区域绑定的图像、绘图和文本对象。
3、如何绘制图形
绘制图形就像调用您可能想要的Drawing Method类型一样简单。您可以直接在页面或形状对象中绘制图形。
例如,要画一个圆:
# Draw a circle on the page using the Page method
page.draw_circle((center_x, center_y), radius, color=(1, 0, 0), width=2)
# Draw a circle on the page using a Shape object
shape = page.new_shape()
shape.draw_circle((center_x, center_y), radius)
shape.finish(color=(1, 0, 0), width=2)
shape.commit(overlay=True)
可以使用Shape对象来组合多个图纸,这些图纸应该接收由Shape.finish()指定的公共属性。
六、故事
本文档展示了故事的一些典型用例。
正如教程中提到的,可以使用最多三个输入源创建故事:HTML、CSS和档案——所有这些都是可选的,并且可以分别以编程方式提供。
以下示例将展示使用这些输入的组合。
注:这些配方的许多源代码都包含在docs文件夹中作为示例。
1、如何添加具有一些格式的文本行
这是不可避免的“Hello World”示例。我们将展示两种变体:
- 使用现有的HTML源[1]创建,可能来自任何地方。
- 使用Python API创建。
使用现有HTML源[1]的变体-在这种情况下定义为脚本中的常量:
import pymupdf
HTML = """
<p style="font-family: sans-serif;color: blue">Hello World!</p>
"""
MEDIABOX = pymupdf.paper_rect("letter") # output page format: Letter
WHERE = MEDIABOX + (36, 36, -36, -36) # leave borders of 0.5 inches
story = pymupdf.Story(html=HTML) # create story from HTML
writer = pymupdf.DocumentWriter("output.pdf") # create the writer
more = 1 # will indicate end of input once it is set to 0
while more: # loop outputting the story
device = writer.begin_page(MEDIABOX) # make new page
more, _ = story.place(WHERE) # layout into allowed rectangle
story.draw(device) # write on page
writer.end_page() # finish page
writer.close() # close output file
注:上述效果(无衬线和蓝色文本)可以通过使用单独的CSS源来实现,如下所示:
import pymupdf
CSS = """
body {
font-family: sans-serif;
color: blue;
}
"""
HTML = """
<p>Hello World!</p>
"""
# the story would then be created like this:
story = pymupdf.Story(html=HTML, user_css=CSS)
Python API变体-一切都是以编程方式创建的:
:
import pymupdf
MEDIABOX = pymupdf.paper_rect("letter")
WHERE = MEDIABOX + (36, 36, -36, -36)
story = pymupdf.Story() # create an empty story
body = story.body # access the body of its DOM
with body.add_paragraph() as para: # store desired content
para.set_font("sans-serif").set_color("blue").add_text("Hello World!")
writer = pymupdf.DocumentWriter("output.pdf")
more = 1
while more:
device = writer.begin_page(MEDIABOX)
more, _ = story.place(WHERE)
story.draw(device)
writer.end_page()
writer.close()
这两种变体将产生相同的输出PDF。
2、如何使用图片
图像可以在提供的HTML源中引用,或者对所需图像的引用也可以通过Python API存储。无论如何,这需要使用存档,它指的是可以找到图像的地方。
注:故事不支持嵌入HTML源中的二进制内容的图像。
我们从上面扩展我们的“Hello World”示例,并在文本之后显示我们星球的图像。假设图像的名称为“world. jpg”并且存在于脚本的文件夹中,那么这是上述Python API变体的修改版本:
import pymupdf
MEDIABOX = pymupdf.paper_rect("letter")
WHERE = MEDIABOX + (36, 36, -36, -36)
# create story, let it look at script folder for resources
story = pymupdf.Story(archive=".")
body = story.body # access the body of its DOM
with body.add_paragraph() as para:
# store desired content
para.set_font("sans-serif").set_color("blue").add_text("Hello World!")
# another paragraph for our image:
with body.add_paragraph() as para:
# store image in another paragraph
para.add_image("world.jpg")
writer = pymupdf.DocumentWriter("output.pdf")
more = 1
while more:
device = writer.begin_page(MEDIABOX)
more, _ = story.place(WHERE)
story.draw(device)
writer.end_page()
writer.close()
3、如何阅读故事的外部HTML和CSS
这些案例相当简单。
作为一般建议,HTML和CSS源应该作为二进制文件读取和解码,然后再在故事中使用它们。Pythonpathlib.Path提供了方便的方法来做到这一点:
import pathlib
import pymupdf
htmlpath = pathlib.Path("myhtml.html")
csspath = pathlib.Path("mycss.css")
HTML = htmlpath.read_bytes().decode()
CSS = csspath.read_bytes().decode()
story = pymupdf.Story(html=HTML, user_css=CSS)
4、如何使用故事模板输出数据库内容
此脚本演示如何使用HTML模板报告SQL数据库内容。
数据库SQL示例包含两个表:
- 表“电影”包含每部电影的一行,字段为“标题”、“导演”和(发行)“年份”。
- 表“演员”包含每个演员和电影标题的一行(字段(演员)“名称”和(电影)“标题”)。
故事DOM由一部电影的模板组成,该模板报告电影数据以及演员名单。
文件:
docs/samples/filmfestival-sql.pydocs/samples/filmfestival-sql.db
5、如何与现有PDF集成
因为DocumentWriter只能写入新文件,所以故事不能放在现有页面上。
基本思想是让DocumentWriter输出到内存中的PDF。故事完成后,我们重新打开这个内存PDF,并通过方法将其页面放在现有页面上所需的位置Page.show_pdf_page()。
文件:
docs/samples/showpdf-page.py
6、如何使多列布局和访问字体从包pymupdf-fonts
此脚本输出包含文本和多个图像并使用2列页面布局的文章(取自Wikipedia)。
此外,使用包pymupdf-字体中的两个“Ubuntu”字体系列,而不是默认为Base-14字体。
这里使用的另一个功能是所有数据——图像和文章HTML——共同存储在一个ZIP文件中。
文件:
docs/samples/quickfox.pydocs/samples/quickfox.zip
7、如何制作一个围绕预定义的“禁区”布局的布局
这是一个演示脚本,使用PyMuPDF的Story类将文本输出为具有两列页面布局的PDF。
该脚本演示了以下功能:
- 围绕现有(“目标”)PDF图像布局文本。
- 根据一些全局参数,识别每个页面上的区域,这些区域可用于接收故事布局的文本。
- 这些全局参数不存储在目标PDF中的任何位置,因此必须以某种方式提供:
- 每页边框的宽度。
- 用于文本的字体大小。此值确定提供的文本是否适合目标PDF(固定)页面的空格。它不能以任何方式预测。如果目标PDF没有足够的页面,脚本将以异常结束,如果不是所有页面都至少收到一些文本,则打印警告消息。在这两种情况下,FONTSIZE值都可以更改(浮点值)。
- 文本使用2列页面布局。
- 布局将创建一个临时(内存)PDF。其生成的页面内容(文本)用于覆盖相应的目标页面。如果文本需要的页面比目标PDF中可用的页面多,则会引发异常。如果不是所有目标页面都至少收到一些文本,则会打印警告。
- 该脚本在其自己的文件夹中读取“image e-no-go. pdf”。这是“目标”PDF。它包含2个页面,每个页面有2个图像(来自原始文章),这些图像位于创建广泛的整体测试覆盖率的位置。否则页面是空的。
- 该脚本生成“quickfox-image-no-go. pdf”,其中包含原始页面和图像位置,但在它们周围布置了原始文章文本。
文件:
docs/samples/quickfox-image-no-go.pydocs/samples/quickfox-image-no-go.pdfdocs/samples/quickfox.zip
8、如何输出HTML表
支持输出HTML表如下:
- 支持平面表格布局(“行x列”),不支持“colspan”/“rowspan”属性。
- 表头标签th支持属性“范围”,值为“行”或“列”。适用文本默认为粗体。
- 列宽是根据列内容自动计算的。它们不能直接设置。
- 表格单元格可能包含将在列宽计算魔术中考虑的图像。
- 行高是根据行内容自动计算的——在需要的地方导致多行行。
- 表格行的潜在多行将始终保持在一页上(分别为“所在”矩形)并且不被拆分。
- 表格标题行仅显示在第一页/“其中”矩形上。
- 当直接在HTML表元素中给出时,“style”属性将被忽略。表及其元素的样式必须单独进行,在CSS源代码中或在样式标记中。
- 不支持和忽略tr元素的样式。因此,不支持表范围的网格或交替的行背景颜色。然而,以下示例脚本之一显示了处理此限制的简单方法。
文件:
docs/samples/table01.py此脚本反映了基本功能。docs/samples/national-capitals.py高级脚本使用简单的附加代码扩展表输出选项:- 模拟重复标题行的多页输出
- 交替的表行背景颜色
- 由网格线分隔的表格行和列
- 动态生成/填充来自SQL数据库的数据的表行
9、如何生成目录
此脚本列出了脚本目录中所有Python脚本的源代码。
文件:
docs/samples/code-printer.py
它具有以下功能:
- 在文档开头单独编号的页面上自动生成目录(TOC)-使用专门的故事。
- 每页使用3个单独的故事对象:页眉故事、页脚故事和用于打印Python源代码的故事。
- 页脚会自动更改以显示当前Python文件的名称。
- 使用
Story.element_positions()收集TOC和页脚动态调整的数据。这是故事输出过程和脚本之间双向通信的一个例子。 - 带有Python源代码的主PDF由其DocumentWriter写入内存。然后使用另一个故事/DocumentWriter对为TOC页面创建(内存)PDF。最后,连接这两个PDF并将结果存储到磁盘。
10、如何显示来自JSON数据的列表
此示例采用一些JSON数据输入,用于填充故事。它还包含一些可视文本格式并显示如何添加链接。
文件:
docs/samples/json-example.py
11、使用替代Story.write*()函数
使用Story.write*()函数提供了不同的方法 故事功能,无需调用代码来实现 调用Story.place()和Story.draw()等的循环 必须提供至少一个rectfn()回调的费用。
11.1 如何做基本布局与 Story.write()
Story.write() : https://pymupdf.readthedocs.io/en/latest/story-class.html#Story.write
该脚本将其自己的源代码的多个副本排列成每页四个矩形。
文件:
docs/samples/story-write.py
11.2 如何做迭代布局的目录与Story.write_stabilized()
Story.write_stabilized() : https://pymupdf.readthedocs.io/en/latest/story-class.html#Story.write_stabilized
此脚本动态创建html内容,添加基于 在具有非零.heading值的ElementPoption项目上。
内容部分位于文档的开头,因此对内容的修改可能会更改文档其余部分的页码,这反过来又会导致内容部分的页码不正确。
所以剧本使用Story.write_stabilized()反复放置东西 直到事情稳定。
文件:
docs/samples/story-write-stabilized.py
11.3 如何做迭代布局和创建PDF链接与Story.write_stabilized_links()
此脚本类似于“如何使用”中描述的脚本 Story.write_stabilized()"上面,除了生成的PDF也 包含与原始html中的内部链接相对应的链接。
这是通过使用Story.write_stabilized_links();这是轻微的 不同于 Story.write_stabilized():
- 它不需要DocumentWriter
writerarg。 - 它返回一个PDFDocument实例。
原因有点复杂;例如 DocumentWriter不一定是一个PDF作家,所以不真正工作 在特定于PDF的API中。
文件:
docs/samples/story-write-stabilized-links.py
七、日志
从版本1.19.0开始,更新PDF文档时可以记录日志。
日志记录是一种日志记录机制,它允许恢复或重新应用对PDF的更改。类似于现代数据库系统中的LUW“逻辑工作单元”,人们可以将一组更新分组为一个“操作”。在MuPDF日志记录中,操作扮演LUW的角色。
注:与数据库系统中的LUW实现相比,MuPDF日志记录发生在每个文档级别。不支持跨多个PDF同时更新:必须在这里建立自己的逻辑。
- 必须通过文档方法启用日志。可以对现有或新文档进行日志记录。只能通过关闭文件来禁用日志记录。
- 一旦启用,每个更改都必须在操作内部发生——否则会引发异常。操作通过文档方法启动和停止。在这两个调用之间发生的更新形成LUW,因此可以一起回滚或重新应用,或者用MuPDF术语“撤消”表示“重做”。
- 在任何时候,都可以查询日志状态:日志是否处于活动状态,记录了多少次操作,是否可以“撤消”或“重做”,日志内部的当前位置等。
- 日志可以保存到文件中或从文件中加载。这些是文档方法。
- 加载日志文件时,会检查与文档的兼容性,并在成功时自动启用日志。
- 对于正在记录的现有PDF,可以使用一种特殊的新保存方法:
Document.save_snapshot()。这执行一个特殊的增量保存,包括迄今为止所有记录的更新。如果它的日志同时保存(紧接在文档快照之后),那么文档和日志是同步的,以后可以一起使用撤消或重做操作或继续记录的更新——就像没有中断一样。 - 快照PDF在各个方面都是有效的PDF并且完全可用。但是,如果文档在不使用其日志文件的情况下以任何方式更改,则将发生去同步,并且日志将变得不可用。
- 快照文件的结构类似于增量更新。然而,内部日志逻辑要求,保存必须发生在一个新文件上。因此,用户应该开发一个文件命名约定来支持原始PDF之间的可识别关系,如
original.pdf及其快照集,如original-snap1.pdf/original-snap1.log,original-snap2.pdf/original-snap2.log等。
示例会话1
描述:
- 创建一个新的PDF并启用日志。然后添加一个页面和一些文本行——每个都作为一个单独的操作。
- 在日志中导航,撤消和重做这些更新并显示状态和文件结果:
>>> import pymupdf
>>> doc=pymupdf.open()
>>> doc.journal_enable()
>>> # try update without an operation:
>>> page = doc.new_page()
mupdf: No journalling operation started
... omitted lines
RuntimeError: No journalling operation started
>>> doc.journal_start_op("op1")
>>> page = doc.new_page()
>>> doc.journal_stop_op()
>>> doc.journal_start_op("op2")
>>> page.insert_text((100,100), "Line 1")
>>> doc.journal_stop_op()
>>> doc.journal_start_op("op3")
>>> page.insert_text((100,120), "Line 2")
>>> doc.journal_stop_op()
>>> doc.journal_start_op("op4")
>>> page.insert_text((100,140), "Line 3")
>>> doc.journal_stop_op()
>>> # show position in journal
>>> doc.journal_position()
(4, 4)
>>> # 4 operations recorded - positioned at bottom
>>> # what can we do?
>>> doc.journal_can_do()
{'undo': True, 'redo': False}
>>> # currently only undos are possible. Print page content:
>>> print(page.get_text())
Line 1
Line 2
Line 3
>>> # undo last insert:
>>> doc.journal_undo()
>>> # show combined status again:
>>> doc.journal_position();doc.journal_can_do()
(3, 4)
{'undo': True, 'redo': True}
>>> print(page.get_text())
Line 1
Line 2
>>> # our position is now second to last
>>> # last text insertion was reverted
>>> # but we can redo / move forward as well:
>>> doc.journal_redo()
>>> # our combined status:
>>> doc.journal_position();doc.journal_can_do()
(4, 4)
{'undo': True, 'redo': False}
>>> print(page.get_text())
Line 1
Line 2
Line 3
>>> # line 3 has appeared again!
示例会话2
描述:
-
与之前类似,但在撤消一些操作后,我们现在添加了不同的更新。这将导致:
-
永久删除未完成的日记条目
-
新的更新操作将成为新的最后一个条目。
>>> doc=pymupdf.open() >>> doc.journal_enable() >>> doc.journal_start_op("Page insert") >>> page=doc.new_page() >>> doc.journal_stop_op() >>> for i in range(5): doc.journal_start_op("insert-%i" % i) page.insert_text((100, 100 + 20*i), "text line %i" %i) doc.journal_stop_op()>>> # combined status info: >>> doc.journal_position();doc.journal_can_do() (6, 6) {'undo': True, 'redo': False}>>> for i in range(3): # revert last three operations doc.journal_undo() >>> doc.journal_position();doc.journal_can_do() (3, 6) {'undo': True, 'redo': True}>>> # now do a different update: >>> doc.journal_start_op("Draw some line") >>> page.draw_line((100,150), (300,150)) Point(300.0, 150.0) >>> doc.journal_stop_op() >>> doc.journal_position();doc.journal_can_do() (4, 4) {'undo': True, 'redo': False}>>> # this has changed the journal: >>> # previous last 3 text line operations were removed, and >>> # we have only 4 operations: drawing the line is the new last one
八、多线程
MuPDF没有对线程的集成支持-称自己为“线程无关”。虽然确实存在在MuPDF中仍然使用线程的棘手可能性,但PyMuPDF的基线结果是:
不支持Python线程。
在Python线程环境中使用PyMuPDF会导致主线程阻塞。
但是,可以选择以多种方式使用Python的多重处理模块。
如果您希望加速大型文档的面向页面的处理,请使用此脚本作为起点。它应该至少是相应顺序处理的两倍。
这是一个更复杂的示例,涉及主进程(显示GUI)和对文档进行PyMuPDF访问的子进程之间的进程间通信。
九、OCR-光学字符识别
PyMuPDF集成了对OCR(光学字符识别)的支持。可以将OCR用于图像(通过Pixmap类)和文档页面。
该功能目前基于 Tesseract-OCR,必须作为单独的应用程序安装-请参阅安装章节。
1、如何OCR图像
必须首先将支持的图像转换为Pixmap。然后可以将Pixmap保存为1页PDF。此页面将看起来像具有相同宽度和高度的原始图像。它将包含一层由Tesseract识别的文本。
PDF可以通过其中一种方法生成Pixmap.pdfocr_save()或Pixmap.pdfocr_tobytes(),作为磁盘上的文件或内存中的PDF。
可以用通常的文本提取和搜索方法提取和搜索文本(Page.get_text()、Page.search_for()等)。还请注意以下重要事实和先决条件:
- 将图像转换为Pixmap时,请确认颜色空间为RGB,alpha为
False(无透明度)。必要时转换原始Pixmap。 - 所有文本都使用Tesseract自己的
GlyphLessFont写成“隐藏”,这是一种单行距字体,度量标准与Courier相当。 - 所有文本都具有常规和黑色的属性(即没有粗体、没有斜体字、没有关于原始字体的信息)。
- Tesseract无法识别矢量图形(即没有图纸/线条艺术)。
这种方法也被推荐用于OCR完整的扫描PDF:
- 以所需的分辨率将每个页面渲染到Pixmap中
- 将生成的1页PDF附加到输出PDF
2、如何OCR文档页面
任何受支持的文档页面都可以进行OCR编辑——可以是完整的页面,也可以仅是页面上的图像区域。
因为光学字符识别比标准文本提取慢大约一千倍,所以我们确保每页只做一次光学字符识别,并将结果存储在文本页面中。使用此文本页面进行所有后续提取和文本搜索将以PyMuPDF通常的最高速度进行。
要对文档页面进行OCR,请遵循以下方法:
- 确定OCR是否需要/是否有益。可以使用许多标准来做出此决定,例如:
- 页面完全被图片覆盖
- 页面上不存在文本
- 数千个小矢量图形(表示模拟文本)
- OCR页面并将结果存储在TextPage对象中,使用
tp = page.get_textpage_ocr(...)。 - 在所有后续文本提取和搜索中,通过
textpage=tp参数引用生成的TextPage。
十、可选内容支持
本文档解释了PyMuPDF对PDF概念“可选内容”的支持。
1、简介:可选内容概念
PDF中的可选内容是一种根据某些条件显示或隐藏文档部分的方法:在使用支持的PDF使用者(查看器)或以编程方式时可以设置为ON或OFF的参数。
此功能在CAD图纸、分层图稿、地图和多语言文档等项目中很有用。典型用途包括显示或隐藏复杂矢量图形的细节,如地理地图、技术设备、建筑设计等,包括在不同缩放级别之间自动切换。其他用例可能是在屏幕上显示文档而不是打印文档时自动显示不同的细节级别。
特殊的PDF对象,即所谓的可选内容组(OCG)用于定义这些不同的内容层。
将OCG分配给“普通”PDF对象(如文本或图像)会导致该对象可见或隐藏,具体取决于分配的OCG的当前状态。
为了简化PDF可选内容的整体配置定义,OCG可以组织成更高级别的分组,称为OC配置。每个配置都是OCG的集合,以及每个OCG所需的初始可见性状态。选择这些配置之一(通过PDF查看器或以编程方式)会导致整个文档中所有受影响的PDF对象的可见性发生相应变化。
除默认配置外,OC配置是可选的。
有关更多说明和其他背景,请参阅PDF规格手册。
2、PyMuPDF支持PDF可选内容
PyMuPDF完全支持查看、定义、更改和删除选项内容组、配置、维护OCG对PDF对象的分配以及以编程方式在OC配置和每个OCG的可见性状态之间切换。
3、如何添加可选内容
这就像将可选内容组OCG添加到PDF:Document.add_ocg()一样简单。
如果以前PDF根本没有OC支持,则此时将自动完成所需的设置(例如定义默认OC配置)。
该方法返回创建的OCG的xref。使用此xref将您希望依赖于此OCG状态的任何PDF对象与之关联(标记)。例如,您可以在页面上插入图像并像这样引用xref:
img_xref = page.insert_image(rect, filename="image.file", oc=xref)
如果要将现有图像置于OCG的控制之下,则必须首先找出图像的xref编号(此处称为img_xref),然后执行doc.set_oc(img_xref, xref)。在此之后,如果OCG的状态分别为“ON”、“OFF”,则图像将在整个文档的任何地方(in-)可见。您也可以使用此方法分配不同的OCG。
要从图像中删除OCG,请执行doc.set_oc(img_xref, 0)。
可以将单个OCG分配给多个PDF对象以控制它们的可见性。
4、如何定义复杂的可选内容条件
可以建立复杂的逻辑条件来满足复杂的可见性需求。
例如,您可能想要创建一个多语言文档,以便用户可以根据需要在语言之间切换。
请看看这个Jupyter笔记本,并根据需要执行它。
当然,您的需求甚至可能更复杂,并且涉及多个带有ON/OFF状态的OCG,这些状态通过某种逻辑关系连接起来——但它应该会给您一个印象,告诉您什么是可能的,以及如何规划您的下一步。
十一、低级接口
有许多方法可以在相当低的级别上访问和操作PDF文件。诚然,“低级”和“正常”功能之间的明确区别并不总是可能的或取决于个人口味。
这也可能发生,以前被认为是低级的功能后来被评估为正常界面的一部分。这发生在v1.14.0中的类工具-您现在可以在类一章中找到它作为一个项目。
这是一个留档的问题,你只在留档的哪一章找到你要找的东西。一切都是可用的,并且总是通过同一个界面。
1、如何遍历xref表
PDF的xref表是文件中定义的所有对象的列表。此表可能很容易包含数千个条目——例如,手册Adobe PDF参考有127,000个对象。表条目“0”是保留的,不得触摸。 以下脚本循环遍历xref表并打印每个对象的定义:
>>> xreflen = doc.xref_length() # length of objects table
>>> for xref in range(1, xreflen): # skip item 0!
print("")
print("object %i (stream: %s)" % (xref, doc.xref_is_stream(xref)))
print(doc.xref_object(xref, compressed=False))
这会产生以下输出:
object 1 (stream: False)
<<
/ModDate (D:20170314122233-04'00')
/PXCViewerInfo (PDF-XChange Viewer;2.5.312.1;Feb 9 2015;12:00:06;D:20170314122233-04'00')
>>
object 2 (stream: False)
<<
/Type /Catalog
/Pages 3 0 R
>>
object 3 (stream: False)
<<
/Kids [ 4 0 R 5 0 R ]
/Type /Pages
/Count 2
>>
object 4 (stream: False)
<<
/Type /Page
/Annots [ 6 0 R ]
/Parent 3 0 R
/Contents 7 0 R
/MediaBox [ 0 0 595 842 ]
/Resources 8 0 R
>>
...
object 7 (stream: True)
<<
/Length 494
/Filter /FlateDecode
>>
...
PDF对象定义是一个普通的ASCII字符串。
2、如何处理对象流
除了对象定义之外,某些对象类型还包含其他数据。示例是描述页面外观的图像、字体、嵌入文件或命令。
这些类型的对象称为“流对象”。PyMuPDF允许通过方法读取对象的流Document.xref_stream(),对象的xref作为参数。也可以使用Document.update_stream()写回流的修改版本。
假设以下代码片段出于任何原因想要读取PDF的所有流:
>>> xreflen = doc.xref_length() # number of objects in file
>>> for xref in range(1, xreflen): # skip item 0!
if stream := doc.xref_stream(xref):
# do something with it (it is a bytes object or None)
# e.g. just write it back:
doc.update_stream(xref, stream)
Document.xref_stream()自动返回解压缩为bytes对象的流-并且Document.update_stream()如果有益的话会自动压缩它。
3、如何处理页面内容
一个PDF页面可以有零个或多个contents对象。这些是描述什么出现在页面上的位置和方式的流对象(如文本和图像)。它们是用一种特殊的迷你语言编写的,例如在Adobe PDF参考资料第643页的“附录A-操作员摘要”一章中。
每个PDF阅读器应用程序都必须能够解释内容语法以重现页面的预期外观。
如果提供了多个contents对象,则必须按照指定的顺序解释它们,就好像它们是作为几个对象的串联提供的一样。
拥有多个contents对象有很好的技术论据:
- 仅仅添加新的
contents对象比维护一个大的对象(这需要为每次更改读取、解压缩、修改、重新压缩和重写它)要容易得多,也快得多。 - 使用增量更新时,修改后的大
contents对象会膨胀更新增量,因此很容易抵消增量保存的效率。
例如,PyMuPDF在方法中添加新的小contents对象Page.insert_image()、Page.show_pdf_page()和Shape方法。
然而,也有单个 contents对象是有益的情况:它比多个较小的对象更容易解释和更可压缩。
以下是组合页面多个内容的两种方法:
>>> # method 1: use the MuPDF clean function
>>> page.clean_contents() # cleans and combines multiple Contents
>>> xref = page.get_contents()[0] # only one /Contents now!
>>> cont = doc.xref_stream(xref)
>>> # this has also reformatted the PDF commands
>>> # method 2: extract concatenated contents
>>> cont = page.read_contents()
>>> # the /Contents source itself is unmodified
干净的函数Page.clean_contents()不仅仅是粘合contents对象:它还纠正和优化页面的PDF运算符语法,并消除与页面对象定义的任何不一致之处。
4、如何访问PDF目录
这是PDF的中心(“根”)对象。它作为到达其他重要对象的起点,它还包含一些PDF的全局选项:
>>> import pymupdf
>>> doc=pymupdf.open("PyMuPDF.pdf")
>>> cat = doc.pdf_catalog() # get xref of the /Catalog
>>> print(doc.xref_object(cat)) # print object definition
<<
/Type/Catalog % object type
/Pages 3593 0 R % points to page tree
/OpenAction 225 0 R % action to perform on open
/Names 3832 0 R % points to global names tree
/PageMode /UseOutlines % initially show the TOC
/PageLabels<</Nums[0<</S/D>>2<</S/r>>8<</S/D>>]>> % labels given to pages
/Outlines 3835 0 R % points to outline tree
>>
注:此处插入缩进、换行符和注释仅用于澄清目的,通常不会出现。有关PDF曲库的更多信息,请参阅Adobe PDF参考资料第71页的第7.7.2节。
5、如何访问PDF文件预告片
PDF文件的尾部是位于文件末尾的dictionary。它包含特殊对象和指向其他重要信息的指针。参见Adobe PDF参考资料第42页。以下是概述:
| 钥匙 | 类型 | 价值 |
|---|---|---|
| 尺寸 | int | 交叉引用表中的条目数+1。 |
| 上一篇 | int | 偏移到上一个xref部分(表示增量更新)。 |
| 根 | 字典 | (间接)指向曲库的指针。见上一节。 |
| 加密 | 字典 | 指向加密对象的指针(仅限加密文件)。 |
| 信息 | 字典 | (间接)指向信息(元数据)的指针。 |
| 身份证 | 数组 | 由两个字节字符串组成的文件标识符。 |
| XRefStm | int | 交叉引用流的偏移。参见Adobe PDF参考资料第49页。 |
访问此信息通过PyMuPDF与Document.pdf_trailer()或,等效地,通过Document.xref_object()使用-1而不是有效的xref号码。
>>> import pymupdf
>>> doc=pymupdf.open("PyMuPDF.pdf")
>>> print(doc.xref_object(-1)) # or: print(doc.pdf_trailer())
<<
/Type /XRef
/Index [ 0 8263 ]
/Size 8263
/W [ 1 3 1 ]
/Root 8260 0 R
/Info 8261 0 R
/ID [ <4339B9CEE46C2CD28A79EBDDD67CC9B3> <4339B9CEE46C2CD28A79EBDDD67CC9B3> ]
/Length 19883
/Filter /FlateDecode
>>
>>>
6、如何访问XML元数据
除了标准的元数据格式外,PDF还可能包含XML元数据。事实上,大多数PDF查看器或修改软件在保存PDF时都会添加此类信息(Adobe、Nitro PDF、PDF-XChange等)。
PyMuPDF无法直接解释或更改此信息,因为它不包含XML功能。然而,XML元数据存储为stream对象,因此可以读取、使用适当的软件修改和写回。
>>> xmlmetadata = doc.get_xml_metadata()
>>> print(xmlmetadata)
<?xpacket begin="\ufeff" id="W5M0MpCehiHzreSzNTczkc9d"?>
<x:xmpmeta xmlns:x="adobe:ns:meta/" x:xmptk="3.1-702">
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
...
omitted data
...
<?xpacket end="w"?>
使用一些XML包,可以解释和/或修改XML数据,然后存储回来。如果PDF以前没有XML元数据,以下方法也有效:
>>> # write back modified XML metadata:
>>> doc.set_xml_metadata(xmlmetadata)
>>>
>>> # XML metadata can be deleted like this:
>>> doc.del_xml_metadata()
7、如何扩展PDF元数据
属性Document.metadata的设计使其以相同的方式适用于所有受支持的文档类型:它是一个Python字典,具有一组固定的键值对。相应地,Document.set_metadata()只接受标准键。
但是,PDF可能包含无法像这样访问的项目。此外,可能有理由存储其他信息,如版权。这里有一种使用PyMuPDF低级函数处理任意元数据项的方法。
例如,查看一些PDF的标准元数据输出:
# -------
# standard metadata
# -------
pprint(doc.metadata)
{'author': 'PRINCE',
'creationDate': "D:2010102417034406'-30'",
'creator': 'PrimoPDF http://www.primopdf.com/',
'encryption': None,
'format': 'PDF 1.4',
'keywords': '',
'modDate': "D:20200725062431-04'00'",
'producer': 'macOS Version 10.15.6 (Build 19G71a) Quartz PDFContext, '
'AppendMode 1.1',
'subject': '',
'title': 'Full page fax print',
'trapped': ''}
使用以下代码查看元数据对象中存储的所有项目:
# -------
# metadata including private items
# -------
metadata = {} # make my own metadata dict
what, value = doc.xref_get_key(-1, "Info") # /Info key in the trailer
if what != "xref":
pass # PDF has no metadata
else:
xref = int(value.replace("0 R", "")) # extract the metadata xref
for key in doc.xref_get_keys(xref):
metadata[key] = doc.xref_get_key(xref, key)[1]
pprint(metadata)
{'Author': 'PRINCE',
'CreationDate': "D:2010102417034406'-30'",
'Creator': 'PrimoPDF http://www.primopdf.com/',
'ModDate': "D:20200725062431-04'00'",
'PXCViewerInfo': 'PDF-XChange Viewer;2.5.312.1;Feb 9 '
"2015;12:00:06;D:20200725062431-04'00'",
'Producer': 'macOS Version 10.15.6 (Build 19G71a) Quartz PDFContext, '
'AppendMode 1.1',
'Title': 'Full page fax print'}
# ---
# note the additional 'PXCViewerInfo' key - ignored in standard!
# ---
反之亦然,您也可以在PDF中存储私有元数据项。您有责任确保这些项符合PDF规范——尤其是它们必须是(unicode)字符串。有关详细信息和注意事项,请参阅Adobe PDF参考资料第14.3节(第548页):
what, value = doc.xref_get_key(-1, "Info") # /Info key in the trailer
if what != "xref":
raise ValueError("PDF has no metadata")
xref = int(value.replace("0 R", "")) # extract the metadata xref
# add some private information
doc.xref_set_key(xref, "mykey", pymupdf.get_pdf_str("北京 is Beijing"))
#
# after executing the previous code snippet, we will see this:
pprint(metadata)
{'Author': 'PRINCE',
'CreationDate': "D:2010102417034406'-30'",
'Creator': 'PrimoPDF http://www.primopdf.com/',
'ModDate': "D:20200725062431-04'00'",
'PXCViewerInfo': 'PDF-XChange Viewer;2.5.312.1;Feb 9 '
"2015;12:00:06;D:20200725062431-04'00'",
'Producer': 'macOS Version 10.15.6 (Build 19G71a) Quartz PDFContext, '
'AppendMode 1.1',
'Title': 'Full page fax print',
'mykey': '北京 is Beijing'}
要删除选定的键,请使用doc.xref_set_key(xref, "mykey", "null")。如下一节所述,字符串“null”是相当于Python的None的PDF。具有该值的键将被视为未指定,并在垃圾收集中物理删除。
8、如何读取和更新PDF对象
也存在精细、优雅的方法来访问和操作选定的PDFdictionary键。
Document.xref_get_keys()返回xref对象的PDF键:
In [1]: import pymupdf
In [2]: doc = pymupdf.open("pymupdf.pdf")
In [3]: page = doc[0]
In [4]: from pprint import pprint
In [5]: pprint(doc.xref_get_keys(page.xref))
('Type', 'Contents', 'Resources', 'MediaBox', 'Parent')
- 与完整的对象定义比较:
In [6]: print(doc.xref_object(page.xref))
<<
/Type /Page
/Contents 1297 0 R
/Resources 1296 0 R
/MediaBox [ 0 0 612 792 ]
/Parent 1301 0 R
>>
- 单键也可以通过
Document.xref_get_key()直接访问。该值始终是一个字符串以及类型信息,有助于解释它:
In [7]: doc.xref_get_key(page.xref, "MediaBox")
Out[7]: ('array', '[0 0 612 792]')
- 以下是上述页面键的完整列表:
In [9]: for key in doc.xref_get_keys(page.xref):
...: print("%s = %s" % (key, doc.xref_get_key(page.xref, key)))
...:
Type = ('name', '/Page')
Contents = ('xref', '1297 0 R')
Resources = ('xref', '1296 0 R')
MediaBox = ('array', '[0 0 612 792]')
Parent = ('xref', '1301 0 R')
- 未定义的键查询返回
('null', 'null')-PDF对象类型null对应于Python中的None。类似于布尔值true和false。 - 让我们为页面定义添加一个新键,将其旋转设置为90度(您知道实际上存在
Page.set_rotation()为此?):
In [11]: doc.xref_get_key(page.xref, "Rotate") # no rotation set:
Out[11]: ('null', 'null')
In [12]: doc.xref_set_key(page.xref, "Rotate", "90") # insert a new key
In [13]: print(doc.xref_object(page.xref)) # confirm success
<<
/Type /Page
/Contents 1297 0 R
/Resources 1296 0 R
/MediaBox [ 0 0 612 792 ]
/Parent 1301 0 R
/Rotate 90
>>
- 此方法也可用于通过将其值设置为
null从xref字典中删除键:以下将从页面中删除轮换规范:doc.xref_set_key(page.xref, "Rotate", "null")。同样,要从页面中删除所有链接、注释和字段,请使用doc.xref_set_key(page.xref, "Annots", "null")。因为Annots根据定义是一个数组,使用语句设置en空数组doc.xref_set_key(page.xref, "Annots", "[]")在这种情况下会做同样的工作。 - PDF字典可以分层嵌套。在下面的页面对象定义中,Font和
XObject都是Resources的子字典:
In [15]: print(doc.xref_object(page.xref))
<<
/Type /Page
/Contents 1297 0 R
/Resources <<
/XObject <<
/Im1 1291 0 R
>>
/Font <<
/F39 1299 0 R
/F40 1300 0 R
>>
>>
/MediaBox [ 0 0 612 792 ]
/Parent 1301 0 R
/Rotate 90
>>
- 上述情况是支持的方法
Document.xref_set_key()和Document.xref_get_key():使用类似路径的表示法指向所需的键。例如,要检索上面键Im1的值,请在键参数中指定它"上面"的完整字典链:"Resources/XObject/Im1":
In [16]: doc.xref_get_key(page.xref, "Resources/XObject/Im1")
Out[16]: ('xref', '1291 0 R')
- 路径表示法也可以用来直接设置一个值:使用以下内容让
Im1指向不同的对象:
In [17]: doc.xref_set_key(page.xref, "Resources/XObject/Im1", "9999 0 R")
In [18]: print(doc.xref_object(page.xref)) # confirm success:
<<
/Type /Page
/Contents 1297 0 R
/Resources <<
/XObject <<
/Im1 9999 0 R
>>
/Font <<
/F39 1299 0 R
/F40 1300 0 R
>>
>>
/MediaBox [ 0 0 612 792 ]
/Parent 1301 0 R
/Rotate 90
>>
请注意,这里不会进行任何语义检查:如果PDF没有xref 9999,此时不会检测到它。
- 如果一个键不存在,它将通过设置其值来创建。此外,如果任何中间键也不存在,它们也将根据需要创建。以下将在现有字典
A的几个级别下创建一个数组D。中间字典B和C会自动创建:
In [5]: print(doc.xref_object(xref)) # some existing PDF object:
<<
/A <<
>>
>>
In [6]: # the following will create 'B', 'C' and 'D'
In [7]: doc.xref_set_key(xref, "A/B/C/D", "[1 2 3 4]")
In [8]: print(doc.xref_object(xref)) # check out what happened:
<<
/A <<
/B <<
/C <<
/D [ 1 2 3 4 ]
>>
>>
>>
>>
- 设置键值时,基本的PDF语法检查将由MuPDF完成。例如,只能在字典下方创建新键。以下尝试在先前创建的数组
D下方创建一些新的字符串项E:
In [9]: # 'D' is an array, no dictionary!
In [10]: doc.xref_set_key(xref, "A/B/C/D/E", "(hello)")
mupdf: not a dict (array)
--- ... ---
RuntimeError: not a dict (array)
- 如果某个更高级别的键是“间接”对象,即xref,则也不可能创建键。换句话说,xrefs只能直接修改,不能通过引用它们的其他对象隐式修改:
In [13]: # the following object points to an xref
In [14]: print(doc.xref_object(4))
<<
/E 3 0 R
>>
In [15]: # 'E' is an indirect object and cannot be modified here!
In [16]: doc.xref_set_key(4, "E/F", "90")
mupdf: path to 'F' has indirects
--- ... ---
RuntimeError: path to 'F' has indirects
谨慎:这些是专家功能!对于是否指定了有效的PDF对象、xrefs等没有验证。与其他低级方法一样,存在渲染PDF或部分PDF无法使用的风险。
2024-08-03(六)







![[翻译] Asset Administration Shells](https://i-blog.csdnimg.cn/direct/41ce485b4c6d41ffa720e73b4d5ec559.png)