Mysql的存储引擎
- 十三、Mysql的存储引擎
- 一、什么是存储引擎
- 二、存储引擎的常见功能
- 三、存储引擎的种类及特性对比
- 1、存储引擎的种类
- 2、常见存储引擎的特性对比
- 3、查看存储引擎
- 四、InnoDB存储引擎
- 1、InnoDB存储引擎介绍
- 2、InnoDB存储引擎的优点
- 3、InnoDB与MyISAM的区别
- 4、存储引擎查看
- 4.1使用 SELECT 确认会话存储引擎
- 4.2 存储引擎(不代表生产操作)
- 4.3 SHOW 确认每个表的存储引擎:
- 4.4 INFORMATION_SCHEMA 确认每个表的存储引擎
- 4.5 修改一个表的存储引擎
- 4.6 平常处理过的MySQL问题--碎片处理
- 4.7扩展:如何批量修改存储引擎
- 5、InnoDB存储引擎物理存储结构
- 6、表空间
- 6.1共享表空间
- 6.2独立表空间
- 6.3案例说明
十三、Mysql的存储引擎
一、什么是存储引擎
存储引擎是MySQL数据库用来处理不同表类型的SQL操作的组件。是数据库底层软件组件,数据库管理系统使用数据引擎进行创建、查询、更新和删除数据操作。不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能,使用不同的存储引擎还可以获得特定的功能。
MySQL 的核心就是存储引擎。
简单来说存储引擎相当于linux的文件系统,只不过比文件系统强大
二、存储引擎的常见功能
1、数据读写
2、数据安全和一致性
3、提高性能
4、热备份
5、自动故障恢复
6、高可用方面支持
等等
三、存储引擎的种类及特性对比
1、存储引擎的种类
Oracle MySQL
InnoDB
MyISAM
MEMORY
ARCHIVE
FEDERATED
EXAMPLE
BLACKHOLE
MERGE
NDBCLUSTER
CSV
2、常见存储引擎的特性对比
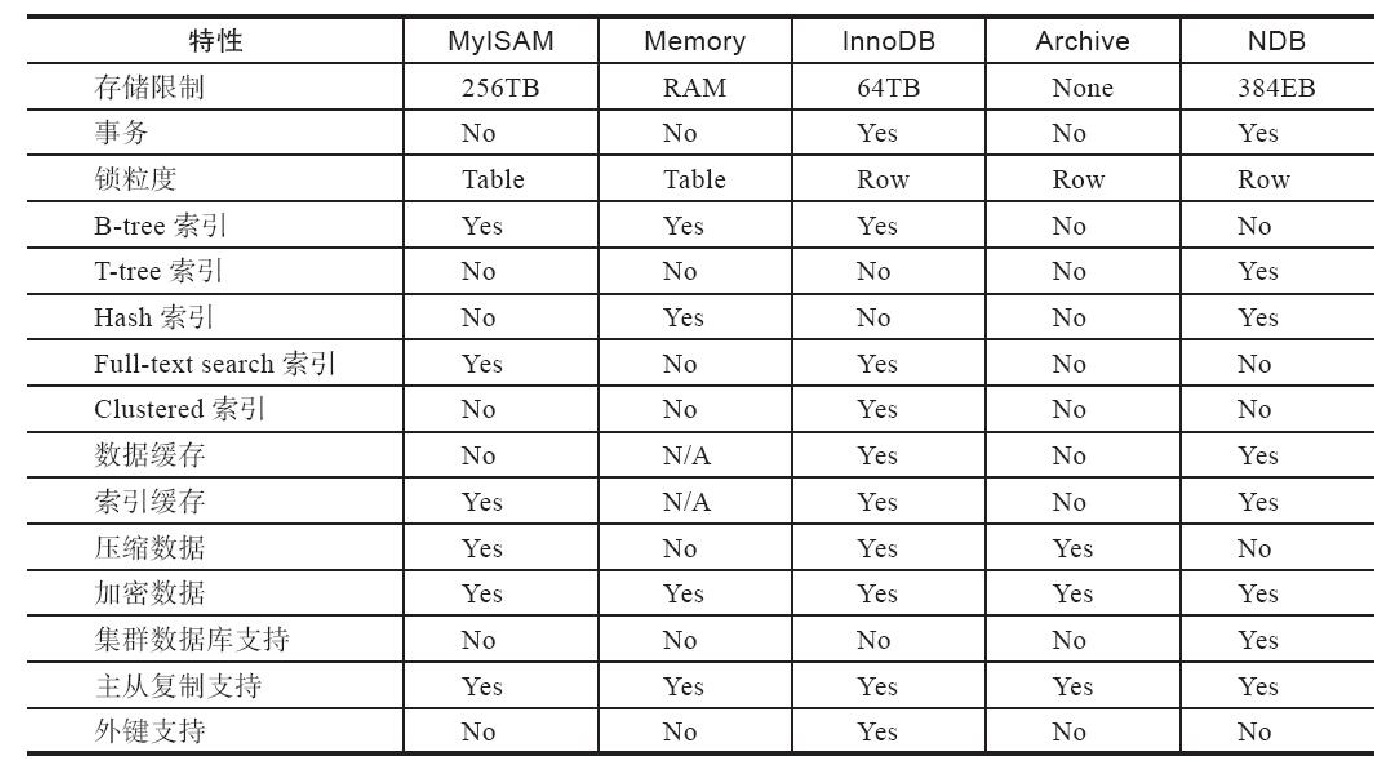
3、查看存储引擎
show engines;
存储引擎是作用在表上的,也就意味着,不同的表可以有不同的存储引擎类型。
PerconaDB:默认是XtraDB
MariaDB:默认是InnoDB
其他的存储引擎支持:
TokuDB
RocksDB
MyRocks
以上三种存储引擎的共同点:压缩比较高,数据插入性能极高
现在很多的NewSQL,使用比较多的功能特性.
四、InnoDB存储引擎
1、InnoDB存储引擎介绍
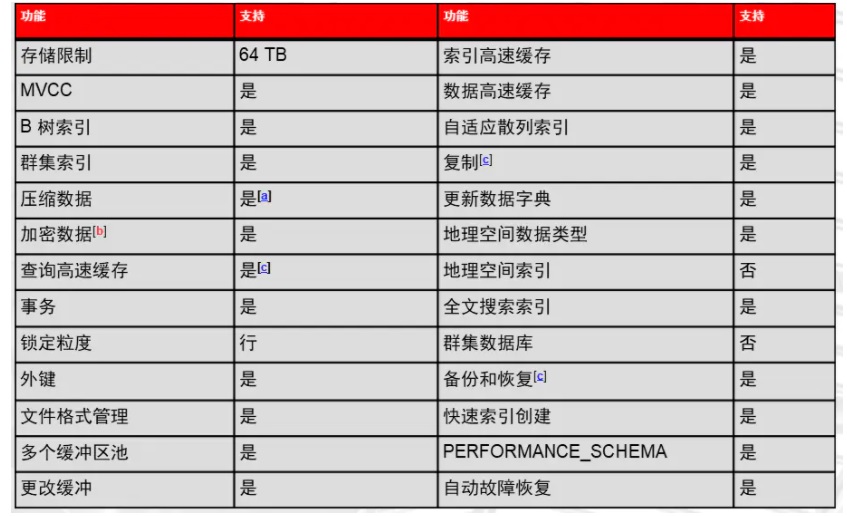
在MySQL5.5版本之后,默认的存储引擎,提供高可靠性和高性能。
2、InnoDB存储引擎的优点
1)、事务(Transaction)
2)、MVCC(Multi-Version Concurrency Control多版本并发控制)
3)、行级锁(Row-level Lock)
4)、ACSR(Auto Crash Safey Recovery)自动的故障安全恢复
5)、支持热备份(Hot Backup)
6)、Replication: Group Commit , GTID (Global Transaction ID) ,多线程(Multi-Threads-SQL )
3、InnoDB与MyISAM的区别
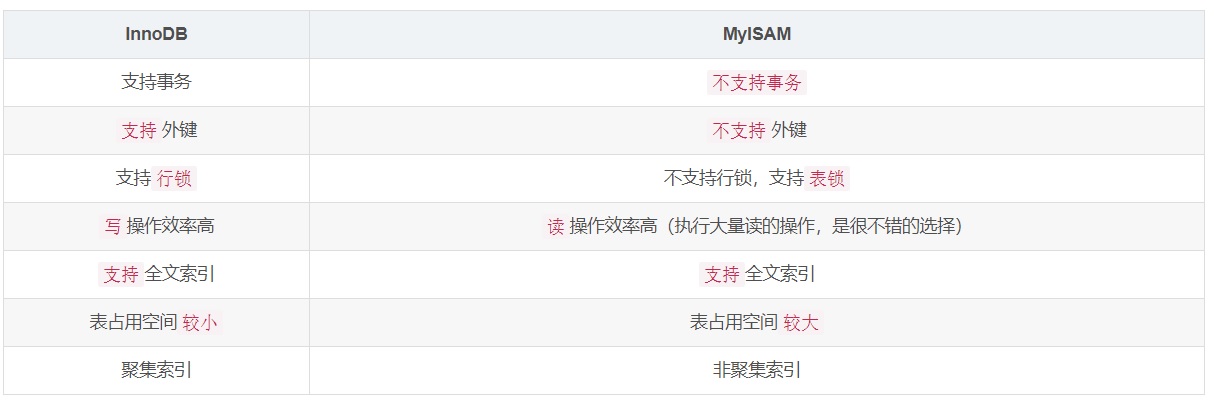
1. MyISAM不支持事务,书摘
摘自《高性能MySQL》
InnoDB:MySQL默认的事务型引擎,也是最重要和使用最广泛的存储引擎。它被设计成为大量的短期事务,短期事务大部分情况下是正常提交的,很少被回滚。InnoDB的性能与自动崩溃恢复的特性,使得它在非事务存储需求中也很流行。除非有非常特别的原因需要使用其他的存储引擎,否则应该优先考虑InnoDB引擎。
MyISAM:在MySQL 5.1 及之前的版本,MyISAM是默认引擎。MyISAM提供的大量的特性,包括全文索引、压缩、空间函数(GIS)等,但MyISAM并不支持事务以及行级锁,而且一个毫无疑问的缺陷是崩溃后无法安全恢复。正是由于MyISAM引擎的缘故,即使MySQL支持事务已经很长时间了,在很多人的概念中MySQL还是非事务型数据库。尽管这样,它并不是一无是处的。对于只读的数据,或者表比较小,可以忍受修复操作,则依然可以使用MyISAM(但请不要默认使用MyISAM,而是应该默认使用InnoDB)
2. MyISAM表锁与InnoDB行锁的区别
在MySQL中,表级锁有两种模式:表共享读锁,表独占写锁。也就是说对于MyISAM引擎的表,多个用户可以对同一个表发起读的请求,但是如果一个用户对表进行写操作,那么则会阻塞其他用户对这个表的读和写。
InnoDB引擎的表是通过索引项来加锁实现的,即只有通过索引条件检索数据的时候,InnoDB才会使用行级锁,否则也会使用表级锁。
3. 在物理空间的存储
所有数据库的文件都在data目录下,一个文件夹对应一个数据库,本质是文件的存储
InnoDB在数据库中只存在一个*.frm文件,以及上级目录下的ibdata文件
MyISAM在磁盘上存储成三个文件
*.frm(存储表定义)
MYD(MyData,数据文件)
MYI(MyIndex,索引文件)
4. 是否保存数据库表中表的具体行数
InnoDB 中不保存表的具体行数,也就是说,执行select count(*) from table 时,InnoDB要扫描一遍整个表来计算有多少行,但是MyISAM只要简单的读出保存好的行数即可。
4、存储引擎查看
4.1使用 SELECT 确认会话存储引擎
SELECT @@default_storage_engine;
4.2 存储引擎(不代表生产操作)
会话级别(仅影响当前会话):
set default_storage_engine=innodb;
全局级别(仅影响新会话):
set global default_storage_engine=innodb;
重启之后,所有参数均失效.
如果要永久生效:
写入配置文件
vim /etc/my.cnf
[mysqld]
default_storage_engine=innodb
存储引擎是表级别的,每个表创建时可以指定不同的存储引擎,但是我们建议统一为innodb.
4.3 SHOW 确认每个表的存储引擎:
SHOW CREATE TABLE City\G;
SHOW TABLE STATUS LIKE 'CountryLanguage'\G
4.4 INFORMATION_SCHEMA 确认每个表的存储引擎
[world]>select table_schema,table_name ,engine from information_schema.tables where table_schema not in ('sys','mysql','information_schema','performance_schema');
Master [world]>show table status;
Master [world]>show create table city;
4.5 修改一个表的存储引擎
[king]>alter table ywx engine innodb;
注意:此命令我们经常使用他,进行innodb表的碎片整理
4.6 平常处理过的MySQL问题–碎片处理
环境:centos7.4,MySQL 5.7.20,InnoDB存储引擎
业务特点:数据量级较大,经常需要按月删除历史数据.
问题:磁盘空间占用很大,不释放
处理方法:
以前:将数据逻辑导出,手工drop表,然后导入进去
现在:
对表进行按月进行分表(partition,中间件)
业务替换为truncate方式
4.7扩展:如何批量修改存储引擎
需求:将zabbix库中的所有表,innodb替换为tokudb
select concat("alter table zabbix.",table_name," engine tokudb;") from
information_schema.tables where table_schema='zabbix' into outfile '/tmp/tokudb.sql';
5、InnoDB存储引擎物理存储结构
在数据目录中(ll /data/mysql/data)
[root@vm01 ~]# ll /data/mysql/
total 1049852
-rw-r----- 1 mysql mysql 56 Nov 2 22:15 auto.cnf
-rw-r----- 1 mysql mysql 455 Nov 12 05:55 ib_buffer_pool
-rw-r----- 1 mysql mysql 79691776 Nov 14 18:32 ibdata1
-rw-r----- 1 mysql mysql 50331648 Nov 14 18:32 ib_logfile0
-rw-r----- 1 mysql mysql 50331648 Nov 13 04:54 ib_logfile1
-rw-r----- 1 mysql mysql 12582912 Nov 14 18:31 ibtmp1
drwxr-x--- 2 mysql mysql 4096 Nov 2 22:15 mysql
-rw-r----- 1 mysql mysql 5042 Nov 12 05:55 mysql-bin.000001
-rw-r----- 1 mysql mysql 882012661 Nov 14 18:32 mysql-bin.000002
-rw-r----- 1 mysql mysql 38 Nov 12 05:55 mysql-bin.index
drwxr-x--- 2 mysql mysql 56 Nov 14 18:07 oldboy
drwxr-x--- 2 mysql mysql 8192 Nov 2 22:15 performance_schema
drwxr-x--- 2 mysql mysql 152 Nov 11 00:30 school
drwxr-x--- 2 mysql mysql 8192 Nov 2 22:15 sys
-rw-r----- 1 mysql mysql 38020 Nov 4 05:13 vm01.err
-rw-r----- 1 mysql mysql 6 Nov 12 05:55 vm01.pid
drwxr-x--- 2 mysql mysql 144 Nov 14 18:32 world
drwxr-x--- 2 mysql mysql 52 Nov 10 05:19 ywx
ibdata1:系统数据字典信息(统计信息),UNDO表空间等数据
ib_logfile0 ~ ib_logfile1: REDO日志文件,事务日志文件。
ibtmp1: 临时表空间磁盘位置,存储临时表
frm:存储表的列信息
ibd:表的数据行和索引
6、表空间
6.1共享表空间
需要将所有数据存储到同一个表空间中 ,管理比较混乱
5.5版本出现的管理模式,也是默认的管理模式。
5.6版本以,共享表空间保留,只用来存储:数据字典信息,undo,临时表。
5.7 版本,临时表被独立出来了
8.0版本,undo也被独立出去了
具体变化参考官方文档:
https://dev.mysql.com/doc/refman/5.6/en/innodb-architecture.html
https://dev.mysql.com/doc/refman/5.7/en/innodb-architecture.html
https://dev.mysql.com/doc/refman/8.0/en/innodb-architecture.html
共享表空间设置
共享表空间设置(在搭建MySQL时,初始化数据之前设置到参数文件中)
[(none)]>select @@innodb_data_file_path;
[(none)]>show variables like '%extend%';
将下面2行写入my.cnf文件
innodb_data_file_path=ibdata1:512M:ibdata2:512M:autoextend
innodb_autoextend_increment=64
#先使用定义了的512M的ibdata1,满了再使用定义的512M的ibdata2,再满了就ibdata2每次自增长64M的空间
#注意:ibdata1为固定的512M空间不会再增长
6.2独立表空间
[root@vm01 ~]# cd /data/mysql/world/
[root@vm01 world]# ls
city.frm city.ibd country.frm country.ibd countrylanguage.frm countrylanguage.ibd db.opt
从5.6,默认表空间不再使用共享表空间,替换为独立表空间。
主要存储的是用户数据
存储特点为:一个表一个ibd文件,存储数据行和索引信息
基本表结构元数据存储:xxx.frm
最终结论:
元数据 数据行+索引
mysql表数据 =(ibdataX+frm)+ibd(段、区、页)
DDL DML+DQL
MySQL的存储引擎日志:
Redo Log: ib_logfile0 ib_logfile1,重做日志
Undo Log: ibdata1 ibdata2(存储在共享表空间中),回滚日志
临时表:ibtmp1,在做join union操作产生临时数据,用完就自动
独立表空间设置
db01 [(none)]>select @@innodb_file_per_table;
+-------------------------+
| @@innodb_file_per_table |
+-------------------------+
| 1 |
+-------------------------+
alter table city dicard tablespace;
#删除表空间
alter table city import tablespace;
#导入表空间
6.3案例说明
案例背景:
硬件及软件环境:
联想服务器(IBM)
磁盘500G 没有raid
centos 6.8
mysql 5.6.33 innodb引擎 独立表空间
备份没有,日志也没开
开发用户专用库:
jira(bug追踪) 、 confluence(内部知识库) ------>LNMT
故障描述:
断电了,启动完成后“/” 只读
fsck 重启,系统成功启动,mysql启动不了。
结果:confulence库在 , jira库不见了
求助内容:
求助:
这种情况怎么恢复?
我问:
有备份没
求助:
连二进制日志都没有,没有备份,没有主从
我说:
没招了,jira需要硬盘恢复了。
求助:
1、jira问题拉倒中关村了
2、能不能暂时把confulence库先打开用着
将生产库confulence,拷贝到1:1虚拟机上/var/lib/mysql,直接访问时访问不了的
问:有没有工具能直接读取ibd
我说:我查查,最后发现没有
一个方法
表空间迁移:
create table xxx
alter table confulence.t1 discard tablespace;
alter table confulence.t1 import tablespace;
虚拟机测试可行。
处理问题思路:
confulence库中一共有107张表。
1、创建107和和原来一模一样的表。
他有2016年的历史库,我让他去他同时电脑上 mysqldump备份confulence库
mysqldump -uroot -ppassw0rd -B confulence --no-data >test.sql
拿到你的测试库,进行恢复
到这步为止,表结构有了。
2、表空间删除。
select concat('alter table ',table_schema,'.'table_name,' discard tablespace;') from information_schema.tables where table_schema='confluence' into outfile '/tmp/discad.sql';
source /tmp/discard.sql
执行过程中发现,有20-30个表无法成功。主外键关系
很绝望,一个表一个表分析表结构,很痛苦。
set foreign_key_checks=0 跳过外键检查。
把有问题的表表空间也删掉了。
3、拷贝生产中confulence库下的所有表的ibd文件拷贝到准备好的环境中
select concat('alter table ',table_schema,'.'table_name,' import tablespace;') from information_schema.tables where table_schema='confluence' into outfile '/tmp/discad.sql';
4、验证数据
表都可以访问了,数据挽回到了出现问题时刻的状态(2-8)
p/discad.sql’;
source /tmp/discard.sql
执行过程中发现,有20-30个表无法成功。主外键关系
很绝望,一个表一个表分析表结构,很痛苦。
set foreign_key_checks=0 跳过外键检查。
把有问题的表表空间也删掉了。
3、拷贝生产中confulence库下的所有表的ibd文件拷贝到准备好的环境中
select concat(‘alter table ‘,table_schema,’.‘table_name,’ import tablespace;’) from information_schema.tables where table_schema=‘confluence’ into outfile ‘/tmp/discad.sql’;
4、验证数据
表都可以访问了,数据挽回到了出现问题时刻的状态(2-8)




![[每周一更]-(第21期):什么是RPC?](https://img-blog.csdnimg.cn/8da0fa88284246739efdd771ef8aeb07.png#pic_center)


![[附源码]java毕业设计日常饮食健康推荐平台](https://img-blog.csdnimg.cn/f77f468786864b6e8d5fb42b280f8a60.png)