基于ChatGLM-6B第一版,要注意还有ChatGLM2-6B以及ChatGLM3-6B
PrefixEncoder
作用:在微调时(以P-Tuning V2为例),方法训练时冻结模型的全部参数,只激活PrefixEncoder的参数。
其源码如下,整体来看是比较简单的。
class PrefixEncoder(torch.nn.Module):
def __init__(self, config):
super().__init__()
self.prefix_projection = config.prefix_projection
if self.prefix_projection:
# 使用一个两层(线性层)的MLP编码prefix
self.embedding = torch.nn.Embedding(config.pre_seq_len, config.hidden_size)
self.trans = torch.nn.Sequential(
torch.nn.Linear(config.hidden_size, config.hidden_size),
torch.nn.Tanh(),
torch.nn.Linear(config.hidden_size, config.num_layers * config.hidden_size * 2)
)
else:
self.embedding = torch.nn.Embedding(config.pre_seq_len, config.num_layers * config.hidden_size * 2)
def forward(self, prefix: torch.Tensor):
if self.prefix_projection:
prefix_tokens = self.embedding(prefix)
past_key_values = self.trans(prefix_tokens)
else:
past_key_values = self.embedding(prefix)
return past_key_values
为什么源码注释中会说到MLP?定位追溯:
self.mlp = GLU(
hidden_size,
inner_hidden_size=inner_hidden_size,
bias=use_bias,
layer_id=layer_id,
params_dtype=params_dtype,
empty_init=empty_init
)
def default_init(cls, *args, **kwargs):
return cls(*args, **kwargs)
class GLU(torch.nn.Module):
def __init__(self, hidden_size, inner_hidden_size=None,
layer_id=None, bias=True, activation_func=gelu, params_dtype=torch.float, empty_init=True):
super(GLU, self).__init__()
if empty_init:
init_method = skip_init
else:
init_method = default_init
self.layer_id = layer_id
self.activation_func = activation_func
# Project to 4h.
self.hidden_size = hidden_size
if inner_hidden_size is None:
inner_hidden_size = 4 * hidden_size
self.inner_hidden_size = inner_hidden_size
self.dense_h_to_4h = init_method(
torch.nn.Linear,
self.hidden_size,
self.inner_hidden_size,
bias=bias,
dtype=params_dtype,
)
# Project back to h.
self.dense_4h_to_h = init_method(
torch.nn.Linear,
self.inner_hidden_size,
self.hidden_size,
bias=bias,
dtype=params_dtype,
)
def forward(self, hidden_states):
"""
hidden_states: [seq_len, batch, hidden_size]
"""
# [seq_len, batch, inner_hidden_size]
intermediate_parallel = self.dense_h_to_4h(hidden_states)
intermediate_parallel = self.activation_func(intermediate_parallel)
output = self.dense_4h_to_h(intermediate_parallel)
return output
# 转载请备注出处:https://www.cnblogs.com/zhiyong-ITNote/
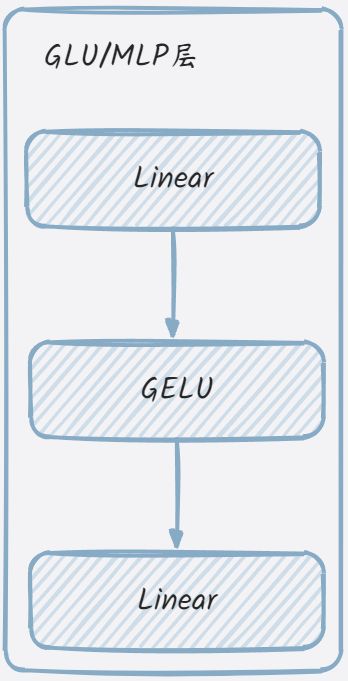
init_method对应到default_init,这个函数的作用与直接调用类构造函数相同,但它提供了一种更灵活的方式来创建类的实例,因为它可以接受任意数量的位置参数和关键字参数。在Pytorch中,用于模块化的构造函数。从源码分析来看,GLU/MLP类就是构造了两个线性层与gelu激活函数,其结构可简化如下:
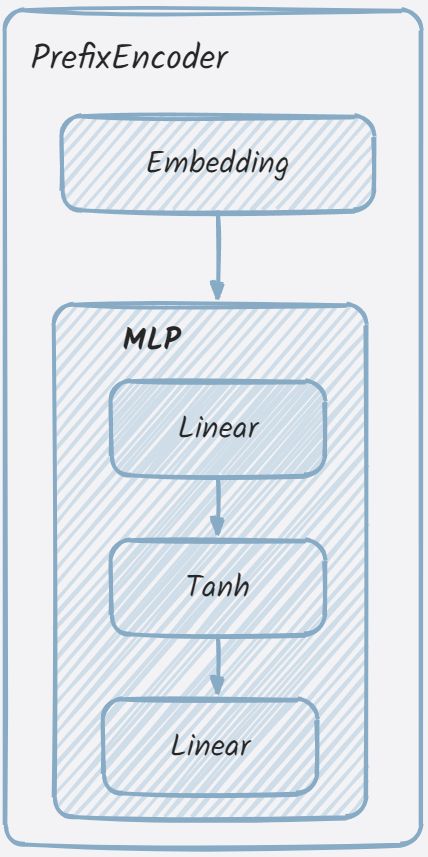
从PrefixEncoder类的初始化方法来看,其就是embedding层与MLP的组合。其结构可简化如下:
Q:在这里还有一个问题,从哪里可以定位溯源到微调时禁用了全部的参数,只激活PrefixEncoder的参数并调用了该类?
激活函数与位置编码
代码简单明了,RoPE的理论知识可以多了解。
attention_fn
伪代码表示为:
def attention_fn(
self,
query_layer,
key_layer,
value_layer,
attention_mask,
hidden_size_per_partition,
layer_id,
layer_past=None,
scaling_attention_score=True,
use_cache=False,
):
xxxx
标准的注意力机制计算公式如下:

多头注意力就是将多个单头注意力的结果拼接起来,再点乘一个新的权重参数。

attention_fn函数实现了注意力的核心计算过程(即上述数学表达式),包括计算注意力分数、注意力概率和上下文层。这些计算对于实现许多自然语言处理任务,如语言建模、命名实体识别等,都是非常重要的。
SelfAttention
伪代码表示为:
class SelfAttention(torch.nn.Module):
xxxx
attention_mask_func将注意力掩码应用于Transformer模型中的注意力得分中。
@staticmethod
def attention_mask_func(attention_scores, attention_mask):
attention_scores.masked_fill_(attention_mask, -10000.0)
return attention_scores
apply_rotary_pos_emb_index函数为Q,K注入了RoPE位置信息,然后调用attention_fn计算注意力概率、上下文层表示,并得到返回值。这些都是在forward函数中调用处理的。
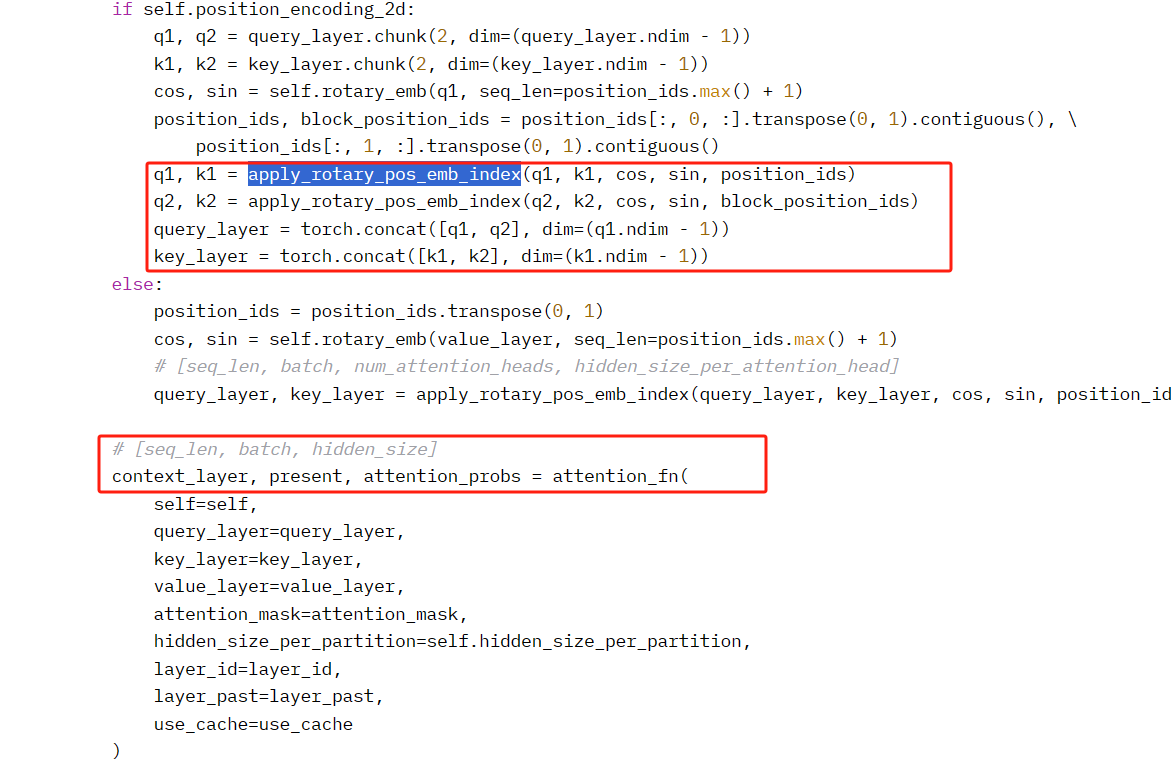
最后还调用了dense对上下文表示做线性计算,返回输出。
GLU
GLU也可以理解为是MLP,在后面版本的ChatGLM中,去掉了GLU类的定义声明,直接换成了MLP。在上面已经写过不再赘述。
GLMBlock
一般都会把GLMBlock对应为transformer结构的实现。从其构造函数来看,主要是拼接各个层到一起。
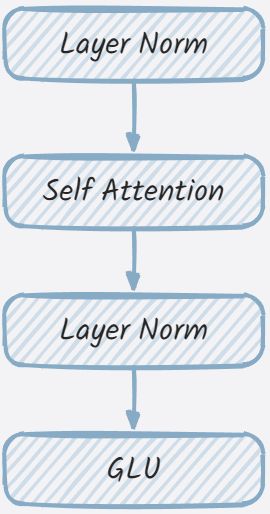
从代码来看,中间有两次的残差连接,如下所示
# Residual connection.
alpha = (2 * self.num_layers) ** 0.5
hidden_states = attention_input * alpha + attention_output
mlp_input = self.post_attention_layernorm(hidden_states)
# MLP.
mlp_output = self.mlp(mlp_input)
# Second residual connection.
output = mlp_input * alpha + mlp_output
最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】