参考node_exporter-CSDN博客,球球不要断更!!!!
大致流程
1.部署promethus
可以写一个自定义的 systemd 服务启动文档,详情见自定义的 systemd 服务启动方式-CSDN博客
[root@localhost system]# sudo tee /etc/systemd/system/prometheus.service > /dev/null <<EOF
[Unit]
Description=Prometheus
# 确保 Prometheus 在网络服务启动后再启动
After=network.target
[Service]
# 以 root 用户身份运行 Prometheus 服务
User=root
Group=root
# 服务类型为 simple,表示服务的主要进程是 ExecStart 中指定的进程
Type=simple
# 启动 Prometheus,指定配置文件和数据存储路径
ExecStart=/opt/prometheus/prometheus \\
--config.file=/opt/prometheus/prometheus.yml \\
--storage.tsdb.path=/opt/prometheus/data
# 重新加载配置时发送 HUP 信号给主进程
ExecReload=/bin/kill -HUP \$MAINPID
# 服务失败时自动重启
Restart=on-failure
[Install]
# 在 multi-user.target 启动时启动此服务
WantedBy=multi-user.target
EOF加载配置文件
[root@localhost system]# sudo systemctl daemon-reload
[root@localhost system]# systemctl start prometheus2.安装alermanager后启动,配置邮件告警文件
vim /opt/alertmanager/alertmanager.yml
=====================================================================
global:
resolve_timeout: 5m
smtp_from: '15686346446@163.com' # 发件人,显示在邮件页面,显示是谁发的
smtp_smarthost: 'smtp.163.com:465' # 邮箱服务器的POP3/SMTP 主机配置 smtp.163.com 或
smtp_auth_username: 'xuziwei' # 用户名,真实发件人
smtp_auth_password: 'XCOKOJVEVXSKUYME' # 授权码
smtp_require_tls: false
templates:
- /opt/alertmanager/tmpl/*.tmpl #定义邮件模板的路径
# 设置路由规则,指定如何分组和发送警报
route:
group_by: ['alertname'] # 根据警报名称进行分组,确保同一类型的警报被归为一组
group_wait: 30s # 当一个警报组内的警报发生后,等待 30 秒,以便将它们一起发送
group_interval: 1m # 每 5 分钟发送一次警报组
repeat_interval: 1h # 如果警报仍然处于活动状态,每小时重复发送一次
receiver: 'email-notifications' # 默认使用 'email-notifications' 接收者来发送警报通知
# 定义接收者配置,包括电子邮件通知设置
receivers:
# 优先使用这里的配置规则,如果没有则去global里的设置
- name: 'email-notifications' # 接收者名称,用于路由规则中的指定
email_configs:
- to: '2228790268@qq.com' # 收件人的电子邮件地址
from: '15686346446@163.com' # 发件人的电子邮件地址
smarthost: 'smtp.163.com:25' # SMTP 服务器地址和端口
auth_username: '15686346446@163.com' # SMTP 服务器的用户名
auth_password: 'XCOKOJVEVXSKUYME' # SMTP 服务器的密码
html: '{{ template "email.html" . }}' # 使用指定的邮件模板
# 定义抑制规则,用于控制警报的触发和抑制
inhibit_rules:
- source_match:
severity: 'critical' # 匹配来自严重性为 'critical' 的警报
target_match:
severity: 'warning' # 匹配目标严重性为 'warning' 的警报
equal: ['alertname', 'dev', 'instance'] # 仅当警报名称、标签 'dev' 和 'instance' 均匹配时抑制=====================================================================
3.创建邮件模板的目录存放 --直接粘贴即可
mkdir /opt/alertmanager/tmpl/
创建邮件模版
vim /opt/alertmanager/tmpl/email.tmpl
4.重启alertmanager
[root@localhost alertmanager]# pkill alertmanager
[root@localhost alertmanager]# nohup ./alertmanager &5.设置监控项
[root@localhost alertmanager]# cd /opt/prometheus
# 创建规则文件存放目录
[root@localhost prometheus]# mkdir ./rules/
[root@localhost prometheus]# vim prometheus.yml --修改配置文件
rule_files:
- "/opt/prometheus/rules/disk.yml"6.配置监控项
[root@localhost prometheus]# vim ./rules/disk.yml
比如cpu告警等等规则
=====================================================================
groups:
- name: 'disk-usage-alerts'
# 这是告警组的名称
rules:
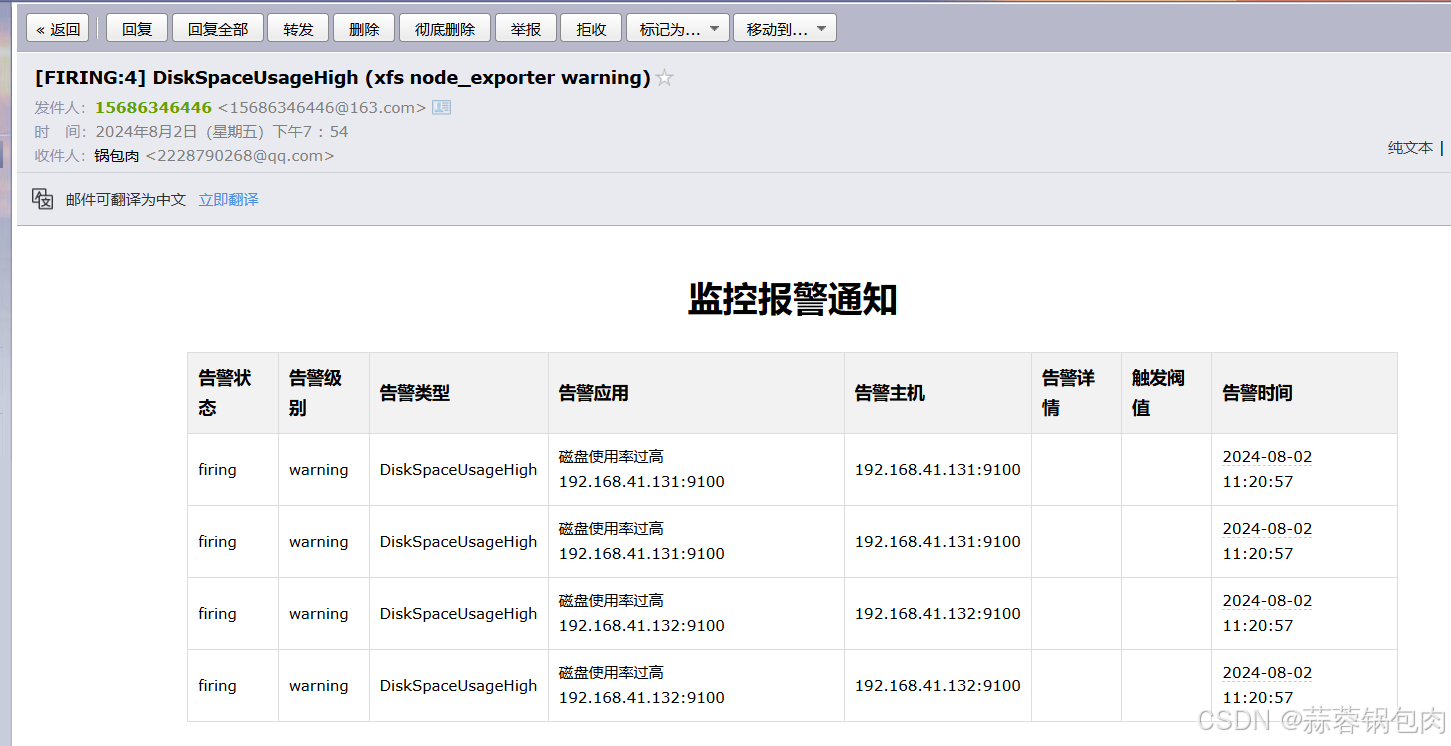
- alert: DiskSpaceUsageHigh
# 这是告警规则的名称
expr: 100 - (node_filesystem_avail_bytes / node_filesystem_size_bytes * 100) > 50
# 告警表达式检查磁盘使用率是否超过50%
for: 5m
# 如果条件持续5分钟,则触发告警
labels:
severity: 'warning'
# 为告警添加标签,指定严重性为“警告”
annotations:
summary: '磁盘使用率过高 {{ $labels.instance }}'
# 摘要注释,描述告警的内容,包括实例名称=====================================================================
7.重启prometheus
systemctl stop prometheus
systemctl start prometheus
8.访问ip+9090
9.注意时间同步
systemctl restart chronyd