Transformer发展 之 GPT系列模型结构
我按照Transformer的发展路线来学习入门
Transformer–BERT—GPT—DETR—ViT—Swin ViT / DeiT
上一篇写了Transformer,听了李宏毅和李沐老师的课一下子就懂了,今天学习GPT-123
核心思想:
GPT和BERT的区别
还在于目标函数的选取,GPT预测未来,BERT预测中间(完形填空)
GPT核心思想
:无标签文本数据预训练+有标签数据微调
GPT-2核心思想
:只用无标签数据进行预训练,让模型自己学会解决多任务问题
GPT-3核心思想
:不进行梯度更新或者微调,仅使用个别示例与模型进行文本交互,使用参数量更大的模型,大力出奇迹!!!
GPT
简单总结一下:
paper
:Improving Language Understanding by Generative Pre-Training
问题背景
:
无标签的文本很多,但是针对特定任务的有标签文本数据很稀少,导致针对特定任务来训练一个准确的模型很有挑战。
解决方法
:
在无标签数据上训练一个语言模型,在下游具体任务上用有标签数据进行微调
核心思想
:预训练+微调
主要步骤
:采用两段式训练。第一个阶段是利用语言模型进行预训练(无监督形式),第二阶段通过 Fine-tuning 的模式解决下游任务(监督模式下),有点类似于迁移学习
模型主要架构
:
1.无监督预训练:
假设输入一个无标签文本U,里面向量为u1…un,GPT使用一个语言模型来极大化这个似然函数,这个语言模型是12层的Transformer中Decoder部分堆叠在一起,这个似然函数(第一个式子)就是在这个语言模型下预测第i个词出现的概率,每次拿K(K为滑动窗口)个连续的词来预测K个词后面那个词的概率,然后选取概率最高的,就是下一个词最可能出现的。后面几个式子相当于Transformer的Decoder数学表达式,具体不懂看Transformer

2.微调:
当预训练后,作者将预训练好的参数直接迁移到下游任务中来。下游任务数据集表示为C,其中数据集中的每一个数据含有一系列的token:x1…xm,标签为y。将这些数据送到预训练好参数的transformer decoder中,将得到的结果用softmax进行分类,得到最后的结果。
作者发现,在做微调时,加入了两个损失函数,一个是预训练时的损失函数L1,一个是分类的损失函数L2。

3.具体任务:
在下游任务输入时,此处还加入了开始符,结束符,间隔符。
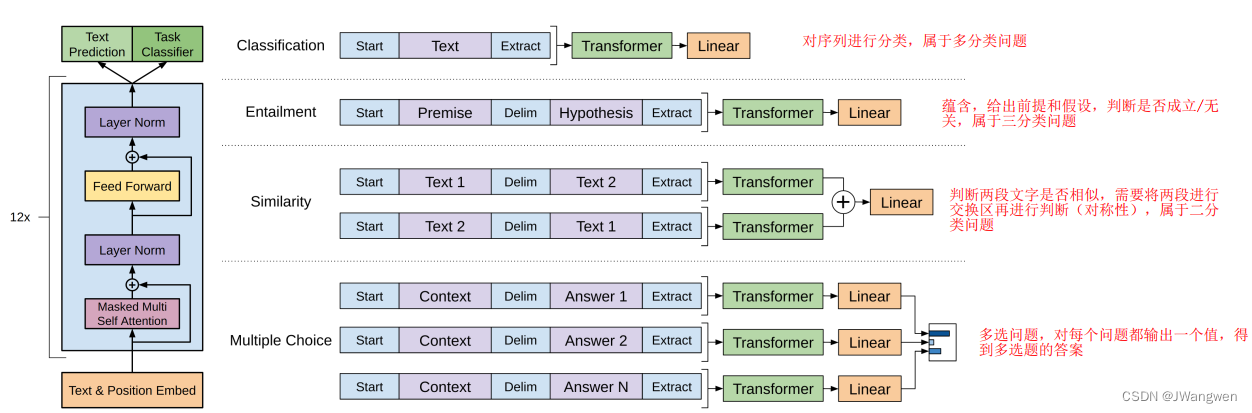
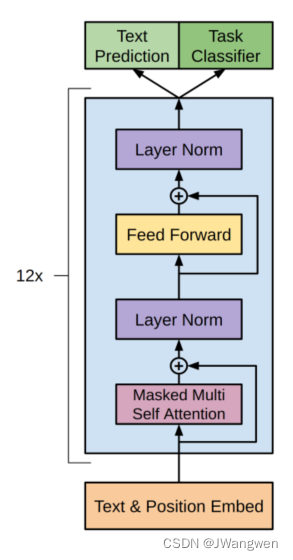
模型结构
:
是12层的Transformer-Decoder,并只保留了masked self-attention,这样做是为了保证只保留了masked self-attention,预测第k个词时,只能看见k-1个词的内容。
另外,作者在position encoding上做了调整,使用了可学习的位置编码,不同于transformer的三角函数位置编码
GPT-2
简单总结一下:
paper
:Language Models are Unsupervised Multitask Learners
问题背景
:
使用预训练+微调的方式虽然能解决带标签文本稀少的问题,但是在针对具体任务时,仍然是需要重新训练,泛化性比较差,不能广泛应用。
解决方法
:
与GPT-1不同,GPT-2彻底放弃微调阶段,仅通过大规模多领域的数据预训练,让模型在Zero-shot Learning的设置下自己学会解决多任务的问题语言模型.
核心思想
:在做到下游任务的时候,会用一个叫做zero-shot的设定,zero-shot是说,在做到下游任务的时候,不需要下游任务的任何标注信息,那么也不需要去重新训练已经预训练好的模型。这样子的好处是我只要训练好一个模型,在任何地方都可以用,实现从已知领域到未知领域的迁移学习。
模型主要架构
:
在输入方面:
为了实现zero-shot,下游任务的输入就不能像GPT那样在构造输入时加入开始、中间和结束的特殊字符,这些是模型在预训练时没有见过的,而是应该和预训练模型看到的文本一样,更像一个自然语言。
并且可以把输入构造成,翻译prompt+英语+法语;或问答prompt+文档+问题+答案,可以把前面不同的prompt当做是特殊分割符。

模型Demo
:
GPT2的文本生成能力很强大,有兴趣可以通过这个工具来体验一下
AllenAI GPT-2 Explorer(https://gpt2.apps.allenai.org/?text=Joel%20is)
GPT-3
简单总结一下:
paper
:Language Models are Unsupervised Multitask Learners
问题背景
:
1.每个子任务需要用相关的数据集做微调,因此相关数据集需要标注,否则很难取得不错的效果,而标注数据的成本又是很高的。
2.作者认为虽然fine tuning效果很好,但是还是需要很多标签数据,而且会导致模型学到一些虚假的特征,造成过拟合,使模型泛化性能变差。
解决方法
:
与GPT-1,GPT-2不同,GPT3在应用时不进行梯度更新或者微调,仅使用任务说明和个别示例与模型进行文本交互,并且使用更大的模型,大力出奇迹。
模型主要架构
:
明确地定义了用于评估 GPT-3 的不同设定,包括 zero-shot、one-shot 和 few-shot。

GPT提出了一种in-context learning的方法,就是给出任务的描述和一些参考案例的情况下,模型能根据当前任务描述、参数案例明白到当前的语境,即使在下游任务和预训练的数据分布不一致情况下,模型也能表现很好。注意的是,GPT并没有利用实例进行Fine-tune,而是让案例作为一种输入的指导,帮助模型更好的完成任务。
模型主要和GPT-2相同,区别在于 GPT-3 在 transformer 的各层上都使用了交替密集和局部带状稀疏的注意力模式,类似于 Sparse Transformer。
few-shot
在inference time,只给模型某个特定任务的说明和一些示例,但不进行权重更新
one-shot
在inference time,只给模型某个特定任务的说明和一个示例,不进行权重更新
zero-shot
在inference time,只给模型某个特定任务的说明,不给示例,不进行权重更新
最后,GPT系列的局限性也是前面提到的,只能往前看,不能双向学习。
Related:
GPT系列模型详解
笔记:李沐老师GPT系列讲解
沐神学习笔记:GPT,GPT-2,GPT-3



















