在 Llama-3.1 模型发布之前,开源模型与闭源模型的性能之间一直存在较大的差距,尤其是在长上下文理解能力上。
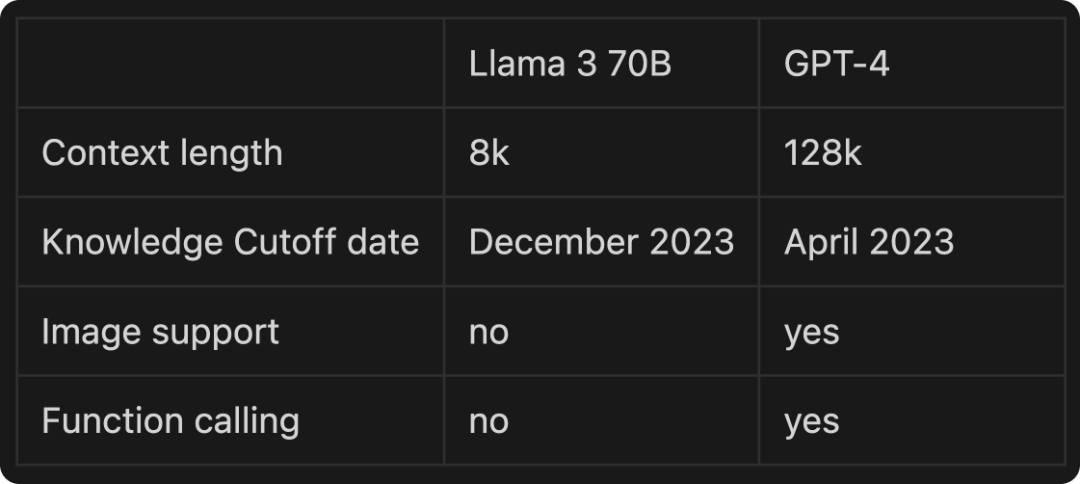
大模型的上下文处理能力是指模型能够处理的输入和输出 Tokens 的总数。这个长度有一个限制,超过这个限制的内容会被模型忽略。一般而言,开源大模型的上下文长度普遍较短,例如 Llama3 的上下文长度为 8K;而闭源模型的上下文长度则要比开源模型长的多,例如 OpenAI 的 GPT-4 Turbo 支持 128K 的上下文长度。这意味着闭源模型能够一次处理更多的信息,从而在复杂任务中表现出更强的能力。
最近 NVIDIA 研究团队在开源模型 Llama-3 的基础上,通过一系列创新技术,将其上下文长度从原来的 8K 扩展到了 128K,将 Llama-3 的上下文长度扩展到原始的 16 倍。在长上下文理解能力上,扩展之后的 Llama3-ChatQA-2-70B 模型甚至超越了 GPT-4。
研究团队使用经过处理的 SlimPajama 数据集生成了 100 亿个 token 的 128K 长度的数据集。为了适应较长的上下文,研究人员将 RoPE 的基频从 500K 提升到了 150M。在后训练阶段,研究团队设计三阶段的指令微调过程,增强模型的指令遵循能力、检索增强生成(RAG)性能和长上下文理解能力。
通过将这些技术结合,NVIDIA 将 Llama-3 的上下文长度从 8K 扩展到了 128K,极大提升了模型的理解能力。
论文标题:ChatQA 2: Bridging the Gap to Proprietary LLMs in Long Context and RAG Capabilities
论文链接:https://arxiv.org/pdf/2407.14482

为什么要提升大模型的上下文长度?
我们知道,大模型的上下文长度越长,其计算过程中消耗的资源也就越多,看起来扩展大模型的上下文是一件耗时耗力的工作。很多读者就会好奇,为什么要扩展大模型的上下文长度呢?

扩展上下问长度具有以下优势:
-
提升长文本理解能力:更长的上下文使模型能够处理和理解更长的文档、对话和代码段,对于文档摘要、长篇对话分析等任务至关重要。
-
增强多步骤推理:长上下文允许模型在单次推理中保持更多信息,有助于解决复杂的多步骤问题,例如数学证明或者复杂的逻辑推理任务。
-
提高生成内容的连贯性:对于长文本生成任务,更长的上下文让模型能够保持更好的主题一致性和逻辑连贯性。
-
减少信息丢失:短上下文模型在处理长文本时需要多次切分和处理,容易造成信息丢失。长上下文可以减少这种信息损失。
总之,扩展大模型的上下文长度能够让模型处理面对复杂任务时得心应手。
然而,开源模型和闭源模型在上下文长度上存在明显差距。例如开源的Llama-3 只支持 8K 的上下文长度,而闭源的 GPT-4 Turbo 已经达到了 128K。
为了缩小这一差距,NVIDIA 研究团队以开源模型 Llama-3 为基础,通过一系列技术创新,将其上下文长度从 8K 扩展到了 128K,使 Llama-3 的上下文长度获得了 16 倍的提升。
研究人员为扩展之后的模型命名为 Llama3-ChatQA-2-70B,该模型在长上下文理解能力上达到了 GPT-4 的水平,在某些任务上甚至超过了 GPT-4。
除此之外,研究团队还探索了长上下文模型和检索增强生成(RAG) 技术的结合,为不同应用场景提供了更灵活的选择。
如何提升模型上下文长度?
NVIDIA团队采用了一系列创新技术来扩展Llama-3的上下文长度。
研究团队首先对模型进行继续预训练。味了提升预训练质量,其在 SlimPajama 数据集上采样并生成了总计 100 亿个 Token 的 128K 长度训练数据。
为了适应更长的上下文,研究人员将 RoPE 的基频从 500K 提升到 150M。
经过研究发现使用特殊字符 <s> 来分割不同文档比使用传统的 <BOS> 和 <EOS> 更有效。

在后训练(post-training)阶段,研究团队设计了一个三阶段的指令微调过程:
-
使用高质量的指令遵循数据集微调模型;
-
使用对话 QA 数据集微调模型;
-
专注于长上下文数据集,涵盖 32K 以下及 32K-128K。
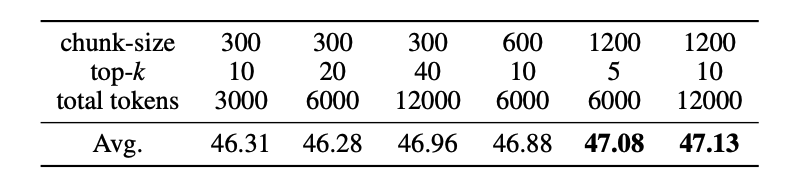
为了进一步提升模型在实际应用中的表现,团队还探索了长上下文检索器与长上下文模型的结合。他们使用 E5-mistral embedding 模型作为检索器,通过实验发现,在总token数固定的情况下,使用更大的块大小(chunk size)能够获得更好的效果。
通过这些技术,NVIDIA 将 Llama-3 的上下文长度从 8K 提升到了 128K,弥补了开源模型在上下文长度方面和闭源模型的差距。不仅如此,扩展上下文长度之后,Llama3-ChatQA-2-70B 在上下文理解能力上的表现甚至超越了 GPT-4。
实验结果
NVIDIA 团队设计了一系列全面的实验来评估 Llama3-ChatQA-2-70B 模型的性能。这些实验涵盖了不同长度的上下文任务,从短文本到超长文本,并与多个顶级模型进行了对比。
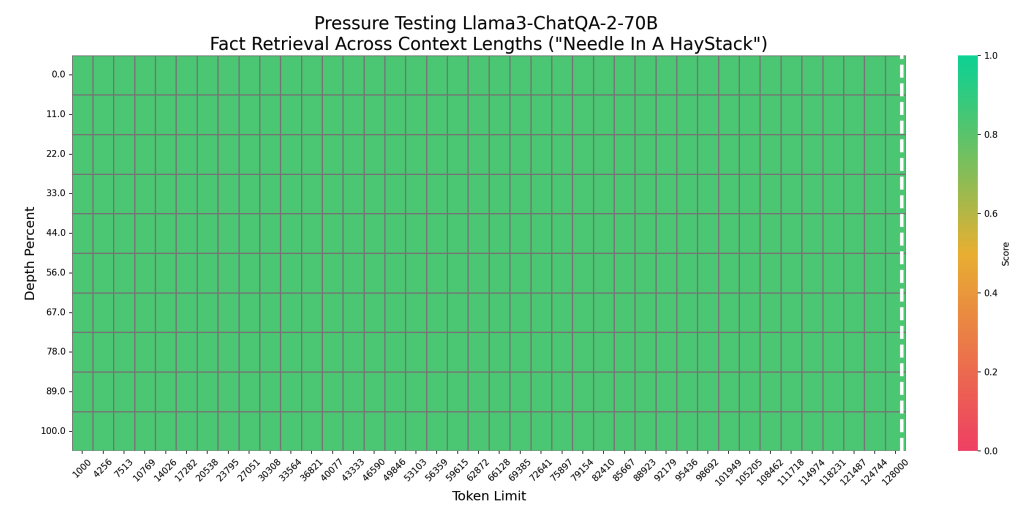
首先,在"大海捞针"测试中,Llama3-ChatQA-2-70B 在 128K token 长度内实现了 100% 的准确率,证明了其出色的长上下文检索能力。
对于超过 100K token 的长上下文任务,团队使用了 InfiniteBench 基准测试,在长文本摘要(En.Sum)、长文本问答(En.QA)、长文本多项选择(En.MC)和长文本对话(En.Dia)四个任务上进行测试。
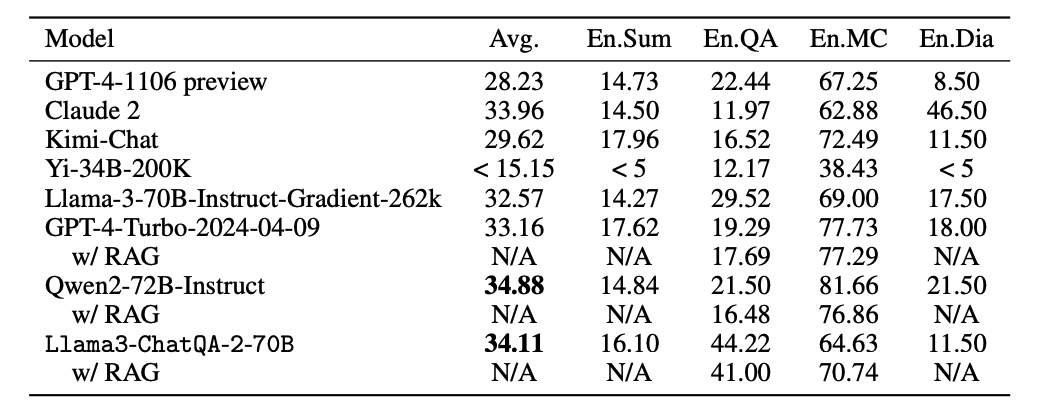
Llama3-ChatQA-2-70B 的平均得分为34.11,优于 GPT-4-Turbo-2024-04-09(33.16)和 Claude 2(33.96),仅略低于 Qwen2-72B-Instruct(34.88)。特别是在 En.QA 任务中,Llama3-ChatQA-2-70B 以 44.22 的得分领先于其他模型。
初次之外,研究团队还在 32K 以内的中等长度上下文任务上进行测试。Llama3-ChatQA-2-70B 的平均得分为 47.37,虽然低于 GPT-4-Turbo-2024-04-09(51.93)和 Qwen2-72B-Instruct(49.94),但仍优于 Llama-3-70B-Instruct-Gradient-262k(40.51)。
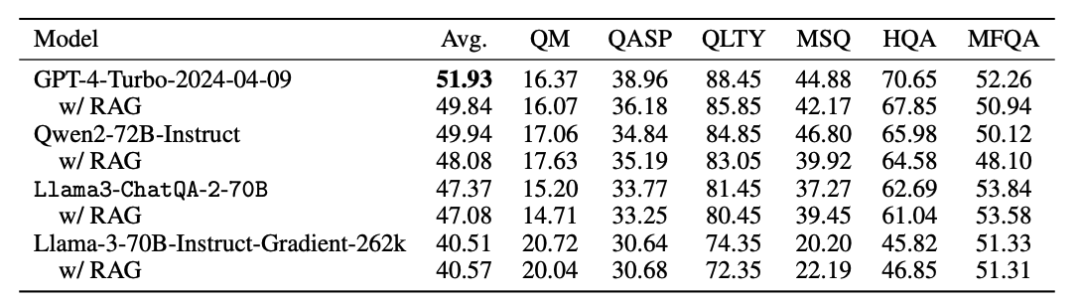
对于4K以内的短文本任务,团队使用了 ChatRAG Bench。Llama3-ChatQA-2-70B 超过了 GPT-4-Turbo-2024-04-09和 Qwen2-72B-Instruct。
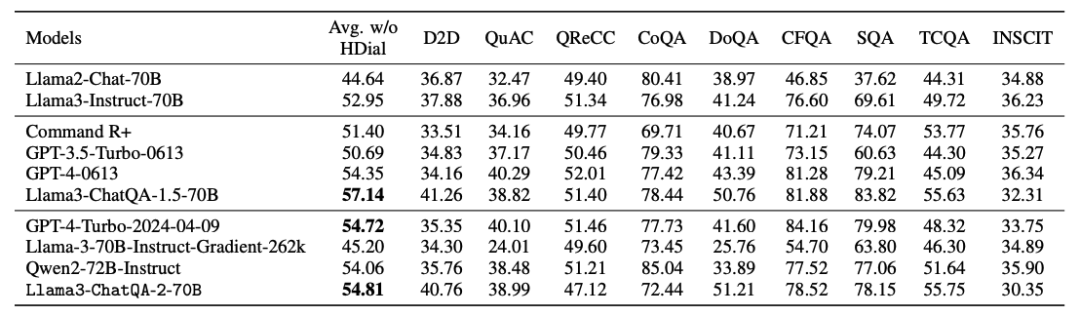
团队还比较了检索增强生成(RAG)与直接使用长上下文模型的效果。在32K以内的任务中,直接使用长上下文模型略优于 RAG 方法。

然而对于超过100K的任务,RAG 方法优于直接使用长上下文模型。

总结
长上下文对于提升大模型的理解能力有重要的作用,NVIDIA 通过将多种技术结合将 Llama-3 的上下文长度从 8K 扩展到 128K,弥补了在上下文长度层面与闭源模型的差距。
扩展长度之后的模型 Llama3-ChatQA-2-70B 在长上下文理解任务上超越了 GPT-4等闭源模型。同时研究也揭示了在特定场景下 RAG 技术的优势,为不同应用提供了更灵活的选择。




















