HTTP协议
HTTP协议(HyperText Transfer Protocol,超文本传输协议)是互联网上应用最为广泛的一种网络协议,它基于TCP/IP通信协议来传送数据,规定了浏览器与服务器之间数据传输的规则,确保数据能够在网络源头到达目的。
主要用于从万维网(WWW)服务器传输超文本到本地浏览器的传送协议。
特点
- 无连接:HTTP协议不需要在客户端和服务器之间建立持久的连接,每次请求都是独立的,处理完成后连接就被关闭。这种特性减少了网络开销,但也可能导致每次请求都需要进行TCP三次握手和四次挥手过程。
- 无状态:HTTP协议对事务的处理没有记忆能力,每次请求都需要提供完整的请求信息。服务器不会保存任何客户端请求的状态信息,这有助于减轻服务器的负担,但也要求客户端必须包含足够的信息以便服务器识别和处理请求。
- 面向对象:HTTP协议可以传输任何类型的数据对象,包括但不限于HTML文档、图片、视频等。
- 无阻塞:HTTP协议不会限制客户端的请求数量和大小,使得服务器可以处理大量的请求。这种特性使得HTTP协议成为互联网上数据传输的重要基石。
- 可缓存:HTTP协议允许客户端缓存服务器响应的内容,以提高响应速度和减少网络流量。客户端在请求资源时,会首先检查本地缓存中是否存在所需资源,如果存在则直接使用缓存资源,否则才向服务器发送请求。
URL
URL(Uniform Resource Locator,统一资源定位符)是互联网上用于标识和定位资源的一种字符串表示方式,也就是我们常说的 “网址” 。
URL能够唯一地确定互联网上的资源,包括网页、图片、视频、文档等。通过URL,用户可以访问互联网上的各种资源,而浏览器则负责解析URL并将用户请求的资源展示给用户。
格式
协议类型://服务器地址[:端口号]/资源路径[?查询参数]
- 协议类型:指定了访问资源所使用的协议,如HTTP、HTTPS、FTP等。HTTP和HTTPS是最常用的协议类型,分别代表超文本传输协议和超文本传输安全协议。
- 服务器地址:可以是域名(如www.example.com)或IP地址(如192.0.2.1)。域名是易于记忆和使用的字符串,通过DNS(域名系统)可以解析为对应的IP地址。
- 端口号:可选部分,用于指定服务器上特定服务的端口。HTTP协议的默认端口是80,HTTPS协议的默认端口是443。如果访问的是默认端口,则端口号可以省略。
- 资源路径:指定了服务器上资源的具体位置。路径可以是绝对路径(从根目录开始)或相对路径(相对于当前目录)。
- 查询参数:可选部分,用于向服务器传递额外的信息,如搜索条件、用户偏好等。查询参数以?开头,后跟一个或多个参数,参数之间以&分隔。每个参数由参数名和参数值组成,二者之间以=分隔。
举例:
https://www.example.com/path/to/resource?param1=value1¶m2=value2
在这个URL中,https是协议类型,www.example.com是服务器地址,/path/to/resource是资源路径,?param1=value1¶m2=value2是查询参数。
HTTP与TCP之间的联系
HTTP是一种应用层协议,主要用于在客户端和服务器之间传输超文本数据;
TCP是一种传输层协议,位于网络层和应用层之间。它负责在通信双方之间建立可靠的连接,并确保数据在传输过程中的完整性和可靠性。
HTTP协议在传输数据时依赖于TCP协议。HTTP请求和响应的报文都是通过TCP连接在客户端和服务器之间传输的。
由于TCP提供了可靠的传输服务,HTTP可以专注于定义请求和响应的格式,而不用担心数据在传输过程中会丢失或损坏。
当客户端需要向服务器请求数据时,它会首先通过TCP协议与服务器建立连接。
连接建立后,客户端会按照HTTP协议的规范构造请求报文,并通过TCP连接发送给服务器。
服务器收到请求后,会解析请求报文,并按照HTTP协议的规范构造响应报文,然后通过TCP连接发送给客户端。
传输完成后,TCP连接可以被关闭或保持打开状态以供后续请求使用。
HTTP的方法
HTTP协议定义了多种请求方法,这些方法用于指定客户端希望服务器执行的操作类型。
常见的几种方法:
-
GET
用途:用于请求服务器发送资源。如果请求的资源是文本,则保持原样返回;如果是程序,则返回执行后的结果。
特点:GET请求可以被缓存,有长度限制(不同浏览器和服务器有所不同),请求参数通过URL传递,且GET请求是安全的(指非修改信息,如数据库方面的信息)。 -
POST
用途:用于向指定资源提交数据进行处理(如提交表单或上传文件)。
特点:POST请求的数据被包含在请求体中,不会被缓存(除非手动设置),对数据长度没有限制,且POST请求是不安全的,因为它可以修改服务器上的资源。 -
HEAD
用途:类似于GET请求,但服务器在响应中只返回头部信息,不返回实体的主体部分。常用于获取报头信息,如内容类型、文档的最后修改时间等。 -
PUT
用途:用于上传文件或向服务器传送数据以取代指定的文档内容。
特点:PUT请求要求请求报文的主体中包含文件内容,并将其保存在请求URI指定的位置。 -
TRACE
用途:用于回显服务器收到的请求,主要用于测试或诊断。
特点:TRACE请求会原样返回服务器收到的请求信息,有助于开发者了解请求在传输过程中是否被篡改。 -
CONNECT
用途:HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
特点:CONNECT方法要求在与代理服务器通信时建立隧道,并实现用隧道协议进行TCP通信。 -
PATCH
用途:用于对资源进行部分修改。
特点:PATCH请求相比PUT请求更为灵活,因为它允许只更新资源的部分字段。
HTTP常见的header
请求头
Host:指定目标服务器的域名或IP地址,是HTTP/1.1中强制要求的字段。
User-Agent:标识发送请求的应用程序或用户代理的信息,包括浏览器的名称和版本、操作系统等。
Accept:指定客户端接受哪些类型的数据,如HTML、JSON、XML等。
Content-Type:在POST或PUT请求中,指定发送的数据类型,如application/json、application/x-www-form-urlencoded等。
Content-Length:指定POST或PUT请求中发送的数据的长度。
Cookie:包含由服务器发送的cookie信息,这些信息在后续的请求中自动包含,以便服务器识别用户或保存状态信息。
Authorization:用于向服务器提供身份验证信息,如Bearer token或Basic authentication。
Referer:指定原始URL,即从哪个URL页面跳转到了当前页面,有助于分析用户行为。
Accept-Encoding:请求头,表示客户端支持的内容编码类型,如gzip、deflate等,用于告诉服务器客户端支持的数据压缩格式。
响应头
Content-Type:响应的数据类型,如text/html; charset=utf-8,表示响应体的MIME类型及字符集。
Content-Length:响应体的长度,以字节为单位。
Cache-Control:指示浏览器如何缓存响应内容,如no-cache、max-age=3600等,控制缓存的有效期和缓存策略。
Expires:设置缓存过期时间,与Cache-Control配合使用,指定缓存内容的过期时间。
Content-Encoding:如果为文本、HTML信息,则使用的编码方式,但这里的编码方式通常指压缩方式,如gzip。
Set-Cookie:服务器在响应头中设置cookie,用于在客户端保存状态信息,如会话ID等。
ETag:响应头中的一个标识符,用于校验资源的状态是否发生变化,常用于缓存验证。
Server:服务器名,表示处理请求的服务器软件的名称和版本号。
Date:当前服务器日期,表示响应生成的日期和时间。
HTTP状态码
HTTP状态码是由HTTP服务器响应客户端请求时返回的一系列数字代码,用于表示请求的结果。
1xx(信息性状态码):表示请求已被接收,继续处理。
100 Continue:客户端应继续其请求。
101 Switching Protocols:服务器根据客户端的请求切换协议。例如,将HTTP协议切换至更高级的协议。
2xx(成功状态码):表示请求已成功被服务器接收、理解、并接受。
200 OK:请求成功。
201 Created:请求成功并且服务器创建了新的资源。
202 Accepted:请求已接受,但处理尚未完成。
203 Non-Authoritative Information:服务器已成功处理了请求,但返回的实体头部元信息不是在原始服务器上有效的确定集合,而是来自本地或者第三方的拷贝。
204 No Content:服务器成功处理了请求,但没有返回任何内容。
205 Reset Content:服务器成功处理了请求,且没有返回任何内容,但是与204响应不同,返回此状态码的响应要求请求方重置文档视图。
206 Partial Content:服务器成功处理了部分GET请求。
3xx(重定向状态码):表示需要客户端采取进一步的操作才能完成请求。
300 Multiple Choices:被请求的资源有一系列可供选择的回馈信息,每个都有自己特定的地址和浏览器驱动的视图,用户代理(如Web浏览器)或用户本身可以选择一个地址进行访问。
301 Moved Permanently:请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个URI之一。
302 Found:请求的资源现在临时从不同的URI响应请求。
303 See Other:对应当前请求的响应可以在另一个URI上被找到,而且客户端应当采用GET的方式访问那个资源。
304 Not Modified:如果客户端发送了一个带条件的GET请求且该请求已被允许,而文档的内容(自上次访问以来或者根据请求的条件)并没有改变,则服务器应当返回这个状态码。
305 Use Proxy:被请求的资源必须通过指定的代理才能被访问。
307 Temporary Redirect:请求的资源现在临时从不同的URI响应请求。
4xx(客户端错误状态码):表示请求包含错误语法或无法完成请求。
400 Bad Request:服务器无法理解请求的格式,客户端不应当尝试再次使用相同的内容发起请求。
401 Unauthorized:请求未授权。
403 Forbidden:服务器理解请求客户端的请求,但是拒绝执行此请求。
404 Not Found:服务器无法根据客户端的请求找到资源(网页)。
405 Method Not Allowed:请求行中指定的请求方法不能被用于请求相应的资源。
408 Request Timeout:请求超时。
410 Gone:请求的资源已永久删除,且不会再得到的。
415 Unsupported Media Type:请求的格式不受请求页面的支持。
5xx(服务器错误状态码):表示服务器在处理请求的过程中遇到了错误。
500 Internal Server Error:服务器遇到了一个未曾预料到的情况,导致其无法完成对请求的处理。
501 Not Implemented:服务器不支持当前请求所需要的某个功能。
502 Bad Gateway:作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应。
503 Service Unavailable:由于临时的服务器维护或者过载,服务器当前无法处理请求。
504 Gateway Timeout:作为网关或者代理的服务器没有及时从上游服务器收到请求。
HTTP的请求与响应格式
HTTP请求
客户端向服务器发送请求时,请求报文包含请求行、请求头(Header)和请求体(Body)三部分。请求行指定了请求的方法(如GET、POST等)、请求的URL和HTTP协议版本。请求头包含了客户端的一些信息,如User-Agent、Accept等。请求体则包含了要发送给服务器的数据。

用下面例子解释:

GET就是请求的方法, HTTP/1.1 是版本号 , 换行符为 /r/n
下面均为请求报头的内容;形式均为请求报头: 内容值
HTTP响应
服务器收到客户端的请求后,会返回一个响应报文给客户端。响应报文包含状态行、响应头(Header)和响应体(Body)三部分。状态行包含了HTTP版本、状态码和状态消息,用于告知客户端请求是否成功以及请求的结果。响应头包含了服务器的一些信息,如Content-Type、Content-Length等。响应体则包含了服务器返回给客户端的数据。


首行为版本号 状态码 描述
下面均为请求报头的内容;形式均为请求报头: 内容值
建立一个简单的http服务器
Http.hpp
将得到的报文进行处理,需要分出报头的内容,逐一分析,分析后将结果打包好返回给浏览器
#pragma once
#include<iostream>
#include <string>
#include<string.h>
#include <vector>
#include<memory>
#include<fstream>
#include<unordered_map>
#include <sstream>
#include<functional>
#include"Log.hpp"
static const std::string sep = "\r\n"; //换行符
static const std::string header_sep = ": "; //头部与内容分隔符
static const std::string wwwroot = "wwwroot"; //保存所有资源的目录
static const std::string homepage = "index.html";//默认首页
static const std::string httpversion = "HTTP/1.0"; //默认版本号
static const std::string space = " "; //响应状态行的分隔符
static const std::string filesuffixsep = "."; //取出后缀名的分隔符
static const std::string args_sep = "?"; //取出网址中输入内容的分隔符
class HttpRequest;
class HttpResponse;
//需求服务处理函数-指针
using func_t = std::function<std::shared_ptr<HttpResponse>(std::shared_ptr<HttpRequest>)>;
class HttpRequest
{
private:
// \r\n正文
std::string GetOneline(std::string &reqstr)
{
if (reqstr.empty())
return reqstr;
auto pos = reqstr.find(sep);//找到换行符
if (pos == std::string::npos)
return std::string();
std::string line = reqstr.substr(0, pos);//获取到每一行的报文
reqstr.erase(0, pos + sep.size());//删除掉原先行
return line.empty() ? sep : line;//如果是空行就直接返回换行符
}
//分析报头信息
bool ParseHeaderHelper(const std::string &line, std::string *k, std::string *v)
{
auto pos = line.find(header_sep);//找到分隔符
if (pos == std::string::npos)
return false;
*k = line.substr(0, pos);//取出字段名
*v = line.substr(pos + header_sep.size());
return true;
}
public:
HttpRequest(): _blank_line(sep), _path(wwwroot)
{}
//序列化
void Serialize()
{
}
//反序列化
void Derialize(std::string &reqstr)
{
_req_line = GetOneline(reqstr); //请求行
while (true)
{
std::string line = GetOneline(reqstr);
if (line.empty())
break;
else if (line == sep)
{
_req_text = reqstr; //正文部分
break;
}
else
{
_req_header.emplace_back(line); //报头
}
}
std::cout<<"\nText:"<<_req_text<<endl;
ParseReqLine(); //分析请求行
ParseHeader(); //分析报头
}
void Print()
{
std::cout << "===" << _req_line << std::endl;
for (auto &header : _req_header)
{
std::cout << "***" << header << std::endl;
}
std::cout << _blank_line;
std::cout << _req_text << std::endl;
std::cout << "method ### " << _method << std::endl;
std::cout << "url ### " << _url << std::endl;
std::cout << "path ### " << _path << std::endl;
std::cout << "httpverion ### " << _version << std::endl;
for(auto &header : _headers)
{
std::cout << "@@@" << header.first << " - " << header.second << std::endl;
}
}
//分析请求行
bool ParseReqLine()
{
if (_req_line.empty())
return false;
std::stringstream ss(_req_line);
ss >> _method >> _url >> _version;//将方法,url,版本号依次分割
// /index.html?use=zhangsan&passwd=123456
if (strcasecmp("get", _method.c_str()) == 0)//方法是get,网址获取对应参数
{
auto pos = _url.find(args_sep);//找到分隔符
if (pos != std::string::npos)
{
LOG(INFO, "change begin, url: %s\n", _url.c_str());
_args = _url.substr(pos + args_sep.size());//获取参数
_url.resize(pos);//分割后,恢复原本的长度
LOG(INFO, "change done, url: %s, _args: %s\n", _url.c_str(), _args.c_str());
}
}
_path += _url;
LOG(DEBUG, "url: %s\n", _url.c_str());
// 判断一下是不是请求的/ -- wwwroot/
if(_path[_path.size()-1] == '/')
{
_path += homepage;
}
auto pos = _path.rfind(filesuffixsep);//从后往前找分隔符
if(pos == std::string::npos)//默认首页
{
_suffix = ".unkonwn";
}
else//取出后缀名
{
_suffix = _path.substr(pos);
}
LOG(INFO, "client wang get %s, _suffix: %s\n", _path.c_str(), _suffix.c_str());
return true;
}
//分析报头
bool ParseHeader()
{
for (auto &header : _req_header)//通过循环依次找出字段名和对应内容
{
// Connection: keep-alive
std::string k, v;
if(ParseHeaderHelper(header, &k, &v))
{
_headers.insert(std::make_pair(k, v));//存储在_headers中
}
}
return true;
}
std::string Path()
{
return _path;
}
std::string Suffix()
{
return _suffix;
}
bool IsExec()//判断输入参数是在url或者正文中
{
return !_args.empty() || !_req_text.empty();
}
std::string Args()
{
return _args;
}
std::string Text()
{
return _req_text;
}
std::string Method()
{
return _method;
}
~HttpRequest()
{
}
private:
// 原始协议内容
std::string _req_line; //请求行
std::vector<std::string> _req_header; //报头
std::string _blank_line; //空白行
std::string _req_text; // 请求正文
// 期望解析的结果
std::string _method; //方法
std::string _url; //URL
std::string _path; //路径
std::string _args;//网址中的输入内容
std::string _suffix; //后缀
std::string _version; //版本
std::unordered_map<std::string, std::string> _headers; //报头每行的存储的字段名与对应字段
};
class HttpResponse
{
public:
HttpResponse():_version(httpversion), _blank_line(sep)
{}
~HttpResponse()
{}
//增加状态行的状态
void AddStatusLine(int code, const std::string &desc)
{
_code = code;
_desc = desc; //根据对应的状态码取对应描述
}
//增加报头
void AddHeader(const std::string &k, const std::string &v)
{
LOG(DEBUG, "AddHeader: %s->%s\n", k.c_str(), v.c_str());
_headers[k] = v;
}
//添加正文部分
void AddText(const std::string &text)
{
_resp_text = text;
}
//序列化
std::string Serialize()
{
std::string _status_line = _version + space + std::to_string(_code) + space + _desc + sep;//状态行整合
for(auto &header : _headers)//报头整合
{
_resp_header.emplace_back(header.first + header_sep + header.second + sep);
}
// 序列化(将每一行字符串串起来)
std::string respstr = _status_line;
for(auto &header : _resp_header)
{
respstr += header;
}
respstr += _blank_line;
respstr += _resp_text;
return respstr;
}
private:
// 构建应答的必要字段
std::string _version; //版本号
int _code; //状态码
std::string _desc; //状态码描述
std::unordered_map<std::string, std::string> _headers; //报头
// 应答的结构化字段
std::string _status_line; //状态行
std::vector<std::string> _resp_header; //回应报头
std::string _blank_line; //空白行
std::string _resp_text; //响应正文
};
class Factory
{
public:
//创建需求
static std::shared_ptr<HttpRequest> BuildHttpRequest()
{
return std::make_shared<HttpRequest>();
}
//创建响应
static std::shared_ptr<HttpResponse> BuildHttpResponose()
{
return std::make_shared<HttpResponse>();
}
};
class HttpServer
{
public:
HttpServer()
{
//常见的对应类型和状态码
_mime_type.insert(std::make_pair(".html", "text/html"));
_mime_type.insert(std::make_pair(".css", "text/css"));
_mime_type.insert(std::make_pair(".js", "application/x-javascript"));
_mime_type.insert(std::make_pair(".png", "image/png"));
_mime_type.insert(std::make_pair(".jpg", "image/jpeg"));
_mime_type.insert(std::make_pair(".unknown", "text/html"));
_code_to_desc.insert(std::make_pair(100, "Continue"));
_code_to_desc.insert(std::make_pair(200, "OK"));
_code_to_desc.insert(std::make_pair(301, "Moved Permanently"));
_code_to_desc.insert(std::make_pair(302, "Found"));
_code_to_desc.insert(std::make_pair(404, "Not Found"));
_code_to_desc.insert(std::make_pair(500, "Internal Server Error"));
}
//增加报头
void AddHandler(const std::string functionname, func_t f)
{
std::string key = wwwroot + functionname; // wwwroot/login
_funcs[key] = f;//不同函数对应不同处理(关键值也不同)
}
//读取文件内容
std::string ReadFileContent(const std::string &path, int *size)
{
// 要按照二进制打开
std::ifstream in(path, std::ios::binary);
if(!in.is_open())
{
return std::string();
}
in.seekg(0, in.end);//改变当前指针位置,到流末尾
int filesize = in.tellg();//读取文件开头到指针位置的偏移量(总大小)
in.seekg(0, in.beg);//改变当前指针位置,到流开始
std::string content;
content.resize(filesize);
in.read((char*)content.c_str(), filesize); //文件流输入到content中
in.close();
*size = filesize;
return content;
}
std::string HandlerHttpRequest(std::string req)
{
#ifdef TEST
std::cout<<"-----------------------"<<std::endl;
std::cout<<req;
std::string response = "HTTP/1.0 200 OK\r\n"; // 404 NOT Found
response += "\r\n";
response += "<html><body><h1>hello,Linux!</h1></body></html>";
return response;
#else
std::cout << "---------------------------------------" << std::endl;
std::cout << req;
std::shared_ptr<HttpRequest> request = Factory::BuildHttpRequest();
request->Derialize(req); //反序列化
//重定向
//auto response = Factory::BuildHttpResponose();//建立响应
//std::string newurl = "https://www.baidu.com/"; //重定向网址
//int code=0;
// if (request->Path() == "wwwroot/redir") //重定向到新网页
// {
// code = 301;
// response->AddStatusLine(code, _code_to_desc[code]);
// response->AddHeader("Location", newurl);
// }
if(request->IsExec()) //获取到参数时
{
auto response = _funcs[request->Path()](request);//让需求服务函数处理后返回对应值
return response->Serialize();
}
else//正常情况
{
auto response = Factory::BuildHttpResponose();
int code=200;
int contentsize = 0;
std::string text = ReadFileContent(request->Path(), &contentsize);//读取文件内容
if (text.empty()) //找不到对应网页时(404)
{
//code = 404;
response->AddStatusLine(code, _code_to_desc[code]); //增加状态行
std::string text404 = ReadFileContent("wwwroot/404.html", &contentsize); //直接重新读取对应文件内容
response->AddHeader("Content-Length", std::to_string(contentsize));//增加报头
response->AddHeader("Content-Type", _mime_type[".html"]);
response->AddText(text404);
}
else//正常情况
{
std::string suffix = request->Suffix(); //读取后缀
response->AddStatusLine(200,_code_to_desc[200]); //增加状态行的状态码
response->AddHeader("Content-Length", std::to_string(contentsize));//增加内容长度的报头
// http协议已经给我们规定好了不同文件后缀对应的Content-Type
response->AddHeader("Content-Type", _mime_type[suffix]);//内容类型
response->AddText(text);//内容
}
return response->Serialize();//将结果返回给客户端,显示到浏览器中
}
#endif
}
~HttpServer(){}
private:
std::unordered_map<std::string, std::string> _mime_type;//类型对应
std::unordered_map<int, std::string> _code_to_desc; //状态码与描述
std::unordered_map<std::string, func_t> _funcs;// 不同服务对应不同函数
};
Main.cc
#include"Http.hpp"
#include"TcpServer.hpp"
void Usage(std::string proc)
{
std::cout << "Usage:\n\t" << proc << " local_port\n"
<< std::endl;
}
//登录函数
std::shared_ptr<HttpResponse> Login(std::shared_ptr<HttpRequest> req)
{
LOG(DEBUG, "=========================\n");
std::string userdata;
if (req->Method() == "GET")//方法get返回对应参数
{
userdata = req->Args();
}
else if (req->Method() == "POST")//方法post返回对应内容
{
userdata = req->Text();
}
else
{
}
// 处理数据了
LOG(DEBUG, "enter data handler, data is : %s\n", userdata.c_str());
//处理完作出答应
auto response = Factory::BuildHttpResponose();
response->AddStatusLine(200, "OK");
response->AddHeader("Content-Type", "text/html");
response->AddText("<html><h1>handler data done</h1></html>");
LOG(DEBUG, "=========================\n");
return response;
}
int main(int argc,char *argv[])
{
if (argc != 2)
{
Usage(argv[0]);
return 1;
}
uint16_t port=std::stoi(argv[1]);
HttpServer httpservice;
// 仿照路径,来进行功能路由!
httpservice.AddHandler("/login", Login);
// httpservice.AddHandler("/register", Login);
// httpservice.AddHandler("/s", Search);
//由于HandlerHttpRequest函数是类中声明的,需要有对应的指针,所以需要进行bind一个HttpServer类的地址
TcpServer tcpsvr(port,std::bind(&HttpServer::HandlerHttpRequest,&httpservice,placeholders::_1));
tcpsvr.Loop();
return 0;
}
TcpServer.hpp
#include <iostream>
#include <string>
#include <functional>
#include <sys/types.h> /* See NOTES */
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <cstring>
#include <pthread.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <memory>
#include"InetAddr.hpp"
#include"Socket.hpp"
#include"Log.hpp"
using namespace socket_ns;
class TcpServer;
//通过function模板来完成对客户端的服务
using http_t = std::function<std::string(std::string request)>;
class ThreadData
{
public:
ThreadData(socket_sptr fd, InetAddr addr, TcpServer *s):sockfd(fd), clientaddr(addr), self(s)
{}
public:
socket_sptr sockfd;
InetAddr clientaddr;
TcpServer *self;
};
class TcpServer
{
public:
TcpServer(int port, http_t service)
: _localaddr("0", port),
_listenSock(std::make_unique<TcpSocket>()),
_service(service),
_isrunning(false)
{
_listenSock->BuildListenSocket(_localaddr);
}
static void* HandlerSock(void* args)
{
pthread_detach(pthread_self());
ThreadData *td = static_cast<ThreadData *>(args);
std::string response,request;
ssize_t n=td->sockfd->Recv(&request);//接收客户端的请求
if(n>0)
{
//通过回调函数的形式,调用函数HandlerHttpRequest,并获取到返回值
response=td->self->_service(request);
td->sockfd->Send(response);//将结果发送回给客户端
}
close(td->sockfd->SockFd());
delete td;
return nullptr;
}
void Loop()
{
_isrunning=true;
while(_isrunning)
{
InetAddr peeraddr; //接收客户端的地址信息
socket_sptr normalsock=_listenSock->Accepter(&peeraddr);
if(normalsock==nullptr)
continue;
pthread_t t;
ThreadData* td=new ThreadData(normalsock,peeraddr,this);
pthread_create(&t,nullptr,HandlerSock,td);
}
_isrunning=false;
}
private:
InetAddr _localaddr;//本地地址
std::unique_ptr<Socket> _listenSock;
bool _isrunning;
http_t _service;
};
网页资源
index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>I am title</title>
</head>
<body>
<h1>这是首页</h1>
<p>this is my first make http</p>
<a href="/2.html">点我进入登陆页面</a><br>
<a href="/redir">点我进行重定向</a><br>
<a href="/a/b/c.html">点我测试404</a><br>
<img src="/image/1.png" alt="test">
</body>
</html>
404.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>(404) The page you were looking for doesn't exist.</title>
<link rel="stylesheet" type="text/css" href="//cloud.typography.com/746852/739588/css/fonts.css" />
<style type="text/css">
html,
body {
margin: 0;
padding: 0;
height: 100%;
}
body {
font-family: "Whitney SSm A", "Whitney SSm B", "Helvetica Neue", Helvetica, Arial, Sans-Serif;
background-color: #2D72D9;
color: #fff;
-moz-font-smoothing: antialiased;
-webkit-font-smoothing: antialiased;
}
.error-container {
text-align: center;
height: 100%;
}
@media (max-width: 480px) {
.error-container {
position: relative;
top: 50%;
height: initial;
-webkit-transform: translateY(-50%);
-ms-transform: translateY(-50%);
transform: translateY(-50%);
}
}
.error-container h1 {
margin: 0;
font-size: 130px;
font-weight: 300;
}
@media (min-width: 480px) {
.error-container h1 {
position: relative;
top: 50%;
-webkit-transform: translateY(-50%);
-ms-transform: translateY(-50%);
transform: translateY(-50%);
}
}
@media (min-width: 768px) {
.error-container h1 {
font-size: 220px;
}
}
.return {
color: rgba(255, 255, 255, 0.6);
font-weight: 400;
letter-spacing: -0.04em;
margin: 0;
}
@media (min-width: 480px) {
.return {
position: absolute;
width: 100%;
bottom: 30px;
}
}
.return a {
padding-bottom: 1px;
color: #fff;
text-decoration: none;
border-bottom: 1px solid rgba(255, 255, 255, 0.6);
-webkit-transition: border-color 0.1s ease-in;
transition: border-color 0.1s ease-in;
}
.return a:hover {
border-bottom-color: #fff;
}
</style>
</head>
<body>
<div class="error-container">
<h1>404</h1>
<p class="return">Take me back to <a href="/">designernews.co</a></p>
</div>
</body>
</html>
1.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
</head>
<body>
<div id="container" style="width:500px">
<h1>这是内容网页</h1>
<a href="/">点我回到首页</a>
<div id="header" style="background-color:#FFA500;">
<h1 style="margin-bottom:0;">网页的主标题</h1>
</div>
<div id="menu" style="background-color:#FFD700;height:200px;width:100px;float:left;">
<b>菜单</b><br>
HTML<br>
CSS<br>
JavaScript
</div>
<div id="content" style="background-color:#EEEEEE;height:200px;width:400px;float:left;">
内容就在这里</div>
<div id="footer" style="background-color:#FFA500;clear:both;text-align:center;">
Copyright © W3Cschools.com</div>
</div>
</body>
</html>
2.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>2</title>
</head>
<body>
<h1>我是登陆网页</h1>
<form name="input" action="/login" method="get">
用户名: <input type="text" name="user">
密码: <input type="password" name="password">
<input type="submit" value="提交">
</form>
<a href="/1.html">点我到内容页面</a>
<img src="/image/2.png" alt="test">
</body>
</html>
图片任意两张即可
结果
通过浏览器输入对应的IP地址和端口号进行访问


加上对应内容:

如果在服务端加上一些数据,客户端通过获取数据来访问对应资源:



解析路径时都会在wwwroot目录下取寻找;


http()客户端请求时,服务端为什么要获取对应的后缀名去找对应的value值
在HTTP客户端请求中,服务端通过请求的资源路径(URL)中的后缀名(如html、.css、js、jpg 等)来识别客户端想要获取的资源类型,并据此查找并返回相应的内容,这主要是基于以下几个原因:
- 1.内容类型识别:不同的文件后缀名通常代表不同类型的资源。服务器通过识别这些后缀名,可以确定客户端请求的资源类型(如文本、图片、脚本、样式表等),并据此设置HTTP响应的Content-Type头部。这个头部信息对于客户端来说非常重要,因为它告诉客户端如何正确解析和展示接收到的数据。
- 2.路由与分发:在复杂的Web应用中,服务器可能需要将请求分发到不同的处理程序或应用组件中。虽然现代Web框架和服务器软件可能使用更复杂的路由机制(如基于URL路径的路由),但文件后缀名在某些情况下仍然可以作为路由决策的一部分,尤其是在静态文件服务中。
- 3.静态文件服务:对于静态文件(如HTML、CSS、JavaScript文件、图片等),服务器通常会根据请求的文件名(包括后缀名)直接在文件系统中查找对应的文件,并将文件内容作为响应体返回给客户端。在这种情况下,文件后缀名直接决定了要查找和返回的文件。
- 4.安全性与缓存:文件后缀名有时也用于实现特定的安全策略或缓存策略。例如,服务器可能根据文件类型设置不同的缓存策略,或者对某些类型的文件执行额外的安全检查。
- 5.兼容性与标准化:文件后缀名作为互联网上的一个广泛使用的约定,有助于保持不同系统和平台之间的兼容性和标准化。尽管它们不是强制性的,但遵循这些约定有助于减少错误和误解。
重定向

重定向只需要在响应的报头加上Location这种header,加上对应重定向的新的网址即可;

测试404网页

当判断到读取的内容为空时,那么直接在返回的网址改为对应的404网页的网址,那么客户端拿到的就是一个404的网页了;

Get与Post


如果是通过Get来获取资源时,那么解析时需要分解在url中的参数;
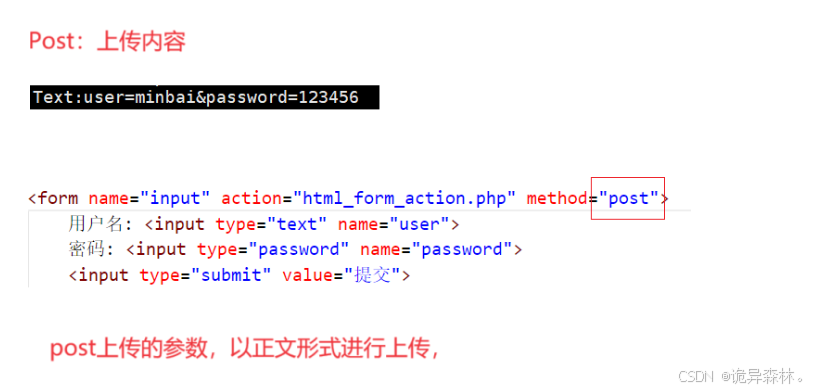
结论
HTTP协议广泛应用于Web开发中,用于浏览器与服务器之间的数据传输。无论是访问网页、下载文件还是提交表单数据等场景,都离不开HTTP协议的支持。同时,随着Web技术的不断发展,HTTP协议也在不断演进和优化,以更好地满足现代网络通信的需求。
















![[算法]归并排序(C语言实现)](https://i-blog.csdnimg.cn/direct/3f6dd2ec230e455890cdf8bee5a9bea1.png)