1,GPT
1.1,GPT结构
GPT is short for Generative Pretrained Transformer。其实GPT和BERT的区别就写在他们的脸上。GPT是Generative的,目的就是要生成。它是一个预训练的Transformer,因为目的就是要生成,所以是Decoder-Only的Auto-Regressive架构。相比之下,Bert的论文名字叫
BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding。它是很深很深的、双向的Transformer编码器的堆叠,目的是自然语言理解。
模型 论文 模型参数 范式与创新点 评价与意义 GPT Improving Language Understanding by Generative Pre-Training 12层解码器,768维词嵌入,12个注意力头 预训练+微调,创新点在于Task-specific input transformations。 很快被Encoder-only的BERT击败,但自回归的技术路线的选择注定了GPT的难度更大,但天花板会更高。 GPT-2 Language Models are Unsupervised Multitask Learners 15亿参数 预训练+Prompt+Predict,创新点在于Zero-shot 被BERT Large横扫SOTA后,OpenAI未能给出很好的回应。Zero-shot新颖度拉满,但事实更像树模型性能拉胯,实用性低,只好以0S为卖点。 GPT-3 Language Models are Few-Shot Learners 1750亿参数 预训练+Prompt+Predict,创新点在于in-context learning 开创性提出in-context learning概念,是Prompting真正的祖师爷。In-context learning(ICL)是Prompting范式发展的第一阶段。 Codex Evaluating Large Language Models Trained on Code 3亿参数和12亿参数 预训练+Fine-tuning。Fine-tune就是真香。 技术上没什么复杂的,爬完Github的代码用于训练更是极具争议。ChatGPT和GPT-4的代码生成能力很强,Codex功不可没。有人认为ChatGPT能进行复杂的reasoning是因为它学习了这些代码。
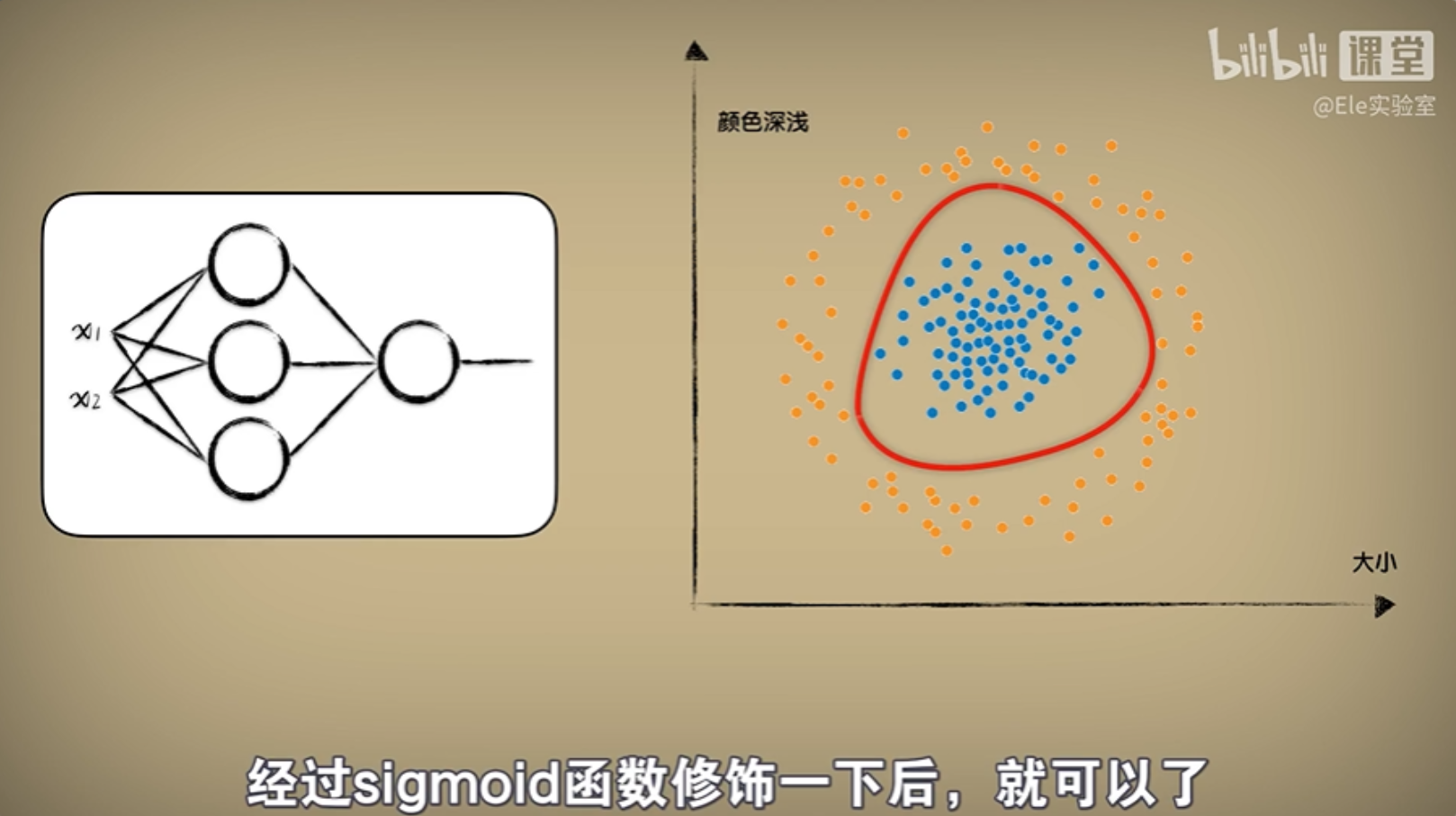
GPT其实并不是一种新型架构,结构类似于只有解码器的Transformer。事实上,它无非是堆叠了12个Transformer的解码器!OpenAI GPT模型是在Google BERT模型之前提出的,与BERT最大的区别在于GPT采用了传统的语言模型方法进行预训练,即使用单词的上文来预测单词,而BERT是采用了双向上下文的信息共同来预测单词。正是因为训练方法上的区别, 使得GPT更擅长处理自然语言生成任务(NLG),而BERT更擅长处理自然语言理解任务(NLU)。案例:给过去6天的股价,预测明天的股价 VS 给前后各三天的股价,预测中间的那一天股价。
经典的Transformer Decoder Block包含3个子层,分别是Masked Multi-Head Attention层,Encoder-Decoder Attention层,以及最后的一个全连接层。GPT是一个Decoder-Only的结构,根本就没有编码器,自然无从从编码器中获得Key和Value啦~因此,在Decoder-Only的魔改Transformer中,往往会取消第二个Encoder-decoder Attention子层,只保留Masked Multi-Head Attention层,和Feed Forward层。这样一来,其实Encoder和Decoder的唯一差别就是,第一个多头自注意力层有没有带掩码了。如果没带掩码那就是Encoder,如果带了掩码那就是Decoder。
- Embedding:词嵌入+位置编码。
- 带掩码的多头自注意力机制,让当前时间步和后续时间步的信息的点积在被softmax后都为零。
- 输出的向量输入给一个全连接层,而后再输出给下一个Decoder。
- GPT有12个Decoder,经过他们后最终的向量经过一个logit的linear层、一个softmax层,就输出了一个下一个词的概率分布函数。
- 输出的词会作为下一个词的输入。


1.2,GPT的训练范式
GPT的训练范式是:预训练+Fine-Tuning
【预训练】GPT模型的预训练任务为标准的n-gram语言模型任务:Transformer的解码器本身就是一个语言模型。给定一个没有标注的语料库
,让Transformer解码器去做下一个词预测。目标函数/损失函数为:
根据前面的k个词(k is the size of the context window)输出下一个词的条件概率。k 是一个超参数,而后面
的就是模型参数。其实对这里的k的更直观的理解方法是神经网络的输入序列的长度。序列越长,网络能看到的东西越多。把这个k堆的很大也是让模型变强的一个重要方式。
【微调范式】OpenAI对预训练好的解码器们在多种有监督任务上进行实验,包括自然语言推理、问答、语义相似度和文本分类。论文中讲述了把将预训练好的Transformers用于序列分类任务。在预训练完了之后,得到了模型的参数,并将其用于针对下游任务的有监督训练。假设有一个标注好了的数据集
,其中有词序列
,并且告诉了这个词序列的标注是
。具体的做法是,把
的
(768维),然后利用这个张量乘一个权重矩阵
(768*分类类目数),就得到了一个与分类的类目数字同维度的向量。对于这个向量做Softmax,就得到了
目标是最大化以下目标函数:
这是一个非常标准的分类任务的目标函数。虽然在微调的时候只关心这个目标函数,但其实可以把分类任务和语言模型任务两个预训练任务一起做!
1.3,GPT的创新点
接下来的问题是怎么把NLP里面那些很不一样的各种子任务都去用这样的微调范式去表达,即序列+标注。
- Classification 分类:可以看到,有两个特殊符号(Start和Extract)加了一个线性层。
- Entailment :大概的意思是:给一个前提(Premise),然后提出一个假设(Hypothesis),让模型去判断这个假设是和被前提蕴涵了、和前提冲突了还是和前提无关。看起来像是在玩逻辑推断,本质上其实是给你两段文本(用特殊符号分开),然后做一个三分类的问题。
Premise:你说的对,但是《原神》是由米哈游自主研发的一款全新开放世界冒险游戏。游戏发生在一个被称作「提瓦特」的幻想世界,在这里,被神选中的人将被授予「神之眼」,导引元素之力。 Hypothesis:1、你是对的。2、你读四大名著不读红楼梦。3、游戏发生在海拉鲁王国。 Output:1、包含 2、中立 3、冲突。
- Similarity 相似:判断两段文字是不是相似。相似是一个对称关系,A和B相似,那么B和A也是相似的;先有Text1+分隔符+Text2,再有Text2+分隔符+Text1,两个序列分别经过Transformers后,各自得到输出的向量;把它按元素加到一起,然后送给一个线性层。这也是一个二分类问题。
- Multiple Choice多选题:多个序列,每个序列都由相同的问题Context和不同的Answer构成。如果有N个答案,就构造N个序列。每个QA序列都各自经过Transformers和线性层,对每个答案都计算出一个标量;最后经过softmax生成一个各个答案的概率密度分布。这是一个N分类问题。
通过这样的方法,这四个自任务就都变成了序列+标注的形式。尽管各自的形式还是稍微有一些不一样,但不管输入形式如何、输出构造如何,中间的Transformer他是不会变的。不管怎样,都不去改图中的Transformer的模型结构,这是GPT和之前工作的区别,也是这篇文章的一个核心卖点。
2,GPT-2
2.1,多任务学习
现在的语言模型泛化能力比较差,在一个训练集、一个训练任务上训练出来的参数很难直接用到下一个模型里。因此,目前大多数模型都是Narrow Expert,而不是Competent Generalists。OpenAI希望朝着能够执行许多任务的更通用的系统发展--最终不需要为每个任务手动创建和标记训练数据集。这其实能想到2000~2010年很火,但在NLP一直没什么应用的多任务学习。
多任务学习(Multi-Task Learning, MTL)是一种机器学习方法,它可以通过同时学习多个相关的任务来提高模型的性能和泛化能力。与单任务学习只针对单个任务进行模型训练不同,多任务学习通过共享模型的部分参数来同时学习多个任务,从而可以更有效地利用数据,提高模型的预测能力和效率。
在NLP中,一个统一的多任务基础模型可以很方便地进行模型迁移、模型部署,并且对这个基础模型的不断改进,可以不断提高下游模型的性能,有可能达到持续学习、持续提升的目的,而如果每个新的子模型都重新学习的话,相当于利用不到基础模型长期学习到的知识。
但是,NLP领域有很多任务,比如序列标注、命名实体识别是一类;对整个句子的分类是一类;还有就是seq2seq的机器翻译、自动摘要等,要怎样将这些不同的任务统一到一个模型中呢?
答案是,可以把所有NLP任务统一成QA任务!机器翻译转换为QA任务就是问这个句子翻译成另一种语言是什么句子,句子情感分类就是问这个句子表达的是积极还是消极的含义,自动摘要就是要求机器帮你写一段摘要。所有NLP任务都可以转换为QA任务。具体的,应该满足如下的条件:
- 必须对所有任务一视同仁,也就是喂给模型的数据不能包含这条数据具体是哪个任务,不能告诉模型这条数据是要做NMT,另一条数据要做情感分类。
- 模型也不能包含针对不同任务的特殊模块。给模型输入一段词序列,模型必须学会自己辨别这段词序列要求的不同的任务类型,并且进行内部切换,执行不同的操作。
因此,论文的作者提出了一个新的多任务问题回答网络(Multitask Question Answering Network, MQAN),该网络在没有任何特定任务模块或参数的情况下联合学习decaNLP的所有任务。MQAN具体是怎么做的这里先不展开讲了,但把各种下游子任务都转换为QA任务,并且让模型通过告诉他的自然语言(Prompt!!!)去自动执行不同的操作,从而完成任务的想法真的非常天才,也是GPT-2的关键。
2.2,从Zero-Shot到Prompting
GPT-2 最大的改变是,OpenAI 抛弃了前面“无监督预训练+有监督微调”的模式,而是开创性地引入了 Zero-shot 的技术,即预训练结束后,不需要改变大模型参数即可让它完成各种各样的任务!Zero-shot的含义在于,在预训练做下游任务时,不需要任何额外的标注信息,自然也不去改模型参数。这听起来非常离谱,自然也需要一些额外的细节。
模型在自然语言上进行预训练,到了给下游任务做微调的时候,引入了很多模型之前从来没有见过的特殊符号的。参考下图,中间的Delim(间隔符,能够让模型知道这个符号前的是context而该符号之后的是Answer)就是一个特殊符号,是针对这个具体的任务专门设计的,模型之间在预训练的时候可是从来都没有见过。也就说,对于下游任务,给GPT的输入进行了特殊的构造,加入了开始符、结束符、分割符。这些符号,模型要在微调的过程中慢慢认识。
如果想要做Zero-short Learning,即不做任何额外的下游任务训练的话,就没办法让模型去临时学习这些针对特定任务的构造了。因此,在构造下游任务的输入的时候,就不能引入特殊的符号,而是要让整个下游任务的输入和之前在预训练的时候看到的文本形式一样。简言之,输入的形式应该更像自然语言。

【Prompting】既然输入的形式也要更像自然语言,那么有没有办法,让模型通过自然语言,去知道现在要去执行什么任务呢?例如,我对模型说:把这段话翻译成英文:都什么年代,还在抽传统香烟。然后模型就知道了,这是一个翻译任务,而且冒号后面的部分就是我想让他翻译的文本。这样就不需要让模型认识新的特殊符号了,模型只要能读懂我对他的指示就行。
But as exemplified in McCann et al. (2018), language provides a flexible way to specify tasks, inputs, and outputs, all as a sequence of symbols. For example, a translation training example can be written as the sequence (translate to french, english text, french text). Likewise, a reading comprehension training example can be written as (answer the question, document, question, answer)。也就是说,实现Zero-shot learning的前提就是,得能够做到不需要针对下游的任务,给模型的输入结构做专门的设计;而是只需要给模型指示,也就是提示词(Prompt)就好了。
【问题】为什么只需要写Prompt就可以自动实现下游的任务的预测?
【答案】OpenAI推测,当数据量足够大、模型能力足够强的时候(GPT 3),语言模型会学会推测并执行用自然语言提出的任务,因为这样可以更好的实现下一词预测。
3,GPT-3
3.1,GPT3的模型架构
GPT模型指出,如果用Transformer的解码器和大量的无标签样本去预训练一个语言模型,然后在子任务上提供少量的标注样本做微调,就可以很大的提高模型的性能。
GPT-2则是更往前走了一步,说在子任务上不去提供任何相关的训练样本,而是直接用一个足够大的预训练模型去理解用自然语言表达的子任务要求,并基于此做预测。但正如前面提到的,GPT-2的性能太差,新意度高而有效性低。
GPT-3这篇文章其实就该来解决有效性低的问题。Zero-shot的概念很诱人,但是还是太苛刻了。哪怕是人,去学习一个任务也是需要样本的,而机器却往往需要大量的标注样本去fine-tune。那有没有可能做到这样:给预训练好的语言模型一点样本。用这有限的一丁点样本,语言模型就可以迅速学会下游的任务?GPT-3的工作非常强调不对模型的权重做更新,毕竟1750亿参数,实在是太大了。【GPT3模型架构】GPT-3和GPT-2是一样的,都是解码器的堆积,不过用到了一个叫Sparse Transformer的架构。Sparse Transformer是一种旨在处理高维、稀疏和长序列数据的Transformer拓展版。相比于传统的Transformer架构,Sparse Transformer通过在自注意力机制中引入稀疏性,减少了网络中计算的数量,从而可以处理更长的序列数据。在处理高维、稀疏数据时,Sparse Transformer可以避免对所有输入的位置进行计算,只计算与当前位置相关的位置,从而提高了计算效率。
【上下文学习】GPT-3是不会做梯度下降、更改模型参数的。那么,它是怎么做的呢?——只做预测,不做训练!希望Transformer在做前向推理的时候,能够通过注意力机制,从给他的输入之中抽取出有用的信息,从而进行预测任务,而预测出来的结果其实也就是任务指示了。这么一来,GPT-3是一个1750亿参数的有ICL能力的模型。为了体现ICL,OpenAI用三个方法来评估他:
- Few Shot Learning(FS):用自然语言告诉模型任务;对每个子任务,提供10~100个训练样本。
- One-shot Learning(1S):用自然语言告诉模型任务,而后只给该任务提供1个样本。
- Zero-shot learning(0S):用自然语言告诉模型任务,但一个样本都不给。
【优点】这种训练方式避免了对下游的任务做Fine-tune。Tune一个模型还是很麻烦的,对于每一个新任务,都需要准备足够的样本,调好超参数(批大小、学习率等),选择各种学习方法(想起Cookie Monster了吗?),而且训练模型这件事本身就要求得有GPU。相比之下,GPT-3的范式面对新任务时,只需要去让模型做预测,即前向传播,就可以了,模型就会直接把结果返回。这对新任务特别友好。
【缺点】如果真的有很多训练样本,该怎么办?GPT-3的输入窗口长度毕竟是有限的,不可能无限的堆叠example的数量——例如,如果是训练翻译任务,随随便便就可以找到巨量的样本。这种时候Tune出来的模型效果就很可能会比在有限的窗口数内输入的few-shot examples差。简言之,有限的输入窗口限制了利用海量数据的能力。Transformer 变得越来越深,越来越宽,但在长序列上训练它们仍然很困难。研究人员遇到的一个基本问题是,Transformer 的注意力层在序列长度方面是按二次方比例增长:就是说从 32k 长度增加到 64k 长度,成本不只增加 2 倍,而是增加了 4 倍。
3.2,GPT3模型的局限性 Limitations
- 长文本生成能力还是很弱。如果要让GPT-3生成长文本的话,可能写了几段后,再往后就又往回写第一第二段的重复的东西了。如果想要让GPT-3在无监督的情况下帮你写小说,可以说这压根就不可能,因为他没有不断的往前推剧情的能力。不过,如果你在输入中告诉了GPT你的上下文,让它来补全上下文中间的一段故事,他可能就会做的特别好。
- GPT-3对 "如果我把奶酪放进冰箱,它会融化吗?"这类问题有困难。基于物理等世界尝试的逻辑推理能力可能还不够。
- 学习的时候做不到像人类这样盯着材料的重点学。例如,一句话中实词的占比可能很小,语言模型的大量学习都是去学习虚词,如“a”、“the”、“to”等,毕竟语言模型还是对所有词语都一视同仁的。
- GPT-3还是单模态的,只能做文字。OpenAI的梦想是实现多模态的AGI,不仅可以输出文字,也想进行多模态生成。这是后面GPT-4要做的事情。
- 可解释性差。你不会知道从一个输入到一个漂亮的输出的过程中,是模型的哪些权重发挥了作用。
- 可能会输出有害的、有偏见的内容,和人类的价值观或者社会主义核心价值观不对齐。OpenAI调查了GPT对性别的偏见、对种族的一些偏见等。例如,A man is ___的下一词预测,和A woman is ____的下一词预测的比较,可能会非常不一样。
3.3,Codex
所以,How did GPT-3 get there?在走向ChatGPT时代的过程中,人们对GPT-3都做了些什么?
GPT-3即使没有怎么被训练用于代码生成,依然可以输出一些简单的代码,不过整体性能非常低罢了。那么,如果说给模型数量可观的代码,是不是这个模型就可以在代码生成上取得比较好的效果,甚至实现帮助程序员完成代码,作为一个辅助工具的作用?Codex就是这个思想。OpenAI团队收集了Github上所有的不重复的python代码,总计179GB(这引起了广泛的抨击),并对收集的代码进行了简单过滤,去掉了过大的文件(>1MB)和过长的代码(>100行或单行超过1000个字符),形成了一个数据集。利用这些数据集,他们Fine-tune了一个GPT3模型。Codex是一个用来自GitHub上的公开的代码作为训练数据集,对GPT-3做一个会改变权重的Fine-tuning,从而让他具有生成代码的能力的拓展版GPT-3模型。它生成代码的能力依然是来自于语言模型的下一词预测,它是预训练LM被fine-tune后实现的针对代码生成的下游应用。

4,Prompt
提示技术 | Prompt Engineering Guide
【代码分析】
我希望你能够充当代码解释器,请分析以下Python代码片段,并完成以下任务,以帮助新人更好地理解项目: 1. 功能说明:解释代码的主要功能,描述它实现了哪些关键操作。 2. 方法解读:解释代码中方法的逻辑结构,描述方法内的流程走向。 2. 潜在问题识别:指出代码中可能存在的Bug或潜在的改进点,例如性能瓶颈、代码逻辑错误或代码风格问题。 3. 优化建议:提供优化代码的建议,具体说明如何提高代码的性能、可读性或可维护性。 代码:{{code}} 结果用中文回复。