图数据库技术是AI走向强人工智能的必经之路和重器!因为图数据库(含知识图谱)最大限度还原(模拟)了人的思维和思考方式。
—— 摘自孙宇熙《图数据库原理、架构与应用》
前言:
博物馆文物馆藏管理和观众服务是文化遗产保护和传播的重要方面。嬴图GraphRAG(Graph Retrieval-Augmented Generation)将知识图谱、检索增强生成(RAG)和大型语言模型(LLM)结合起来,可显著提升博物馆文物信息管理和观众互动体验。本文探讨GraphRAG在博物馆文物馆藏中的具体应用及其优势。
大英博物馆正上新展国宝级珍品《女史箴图》。众所知,顾恺之作品大都已佚或无存,大英博物馆之馆藏也仅是唐代摹本。
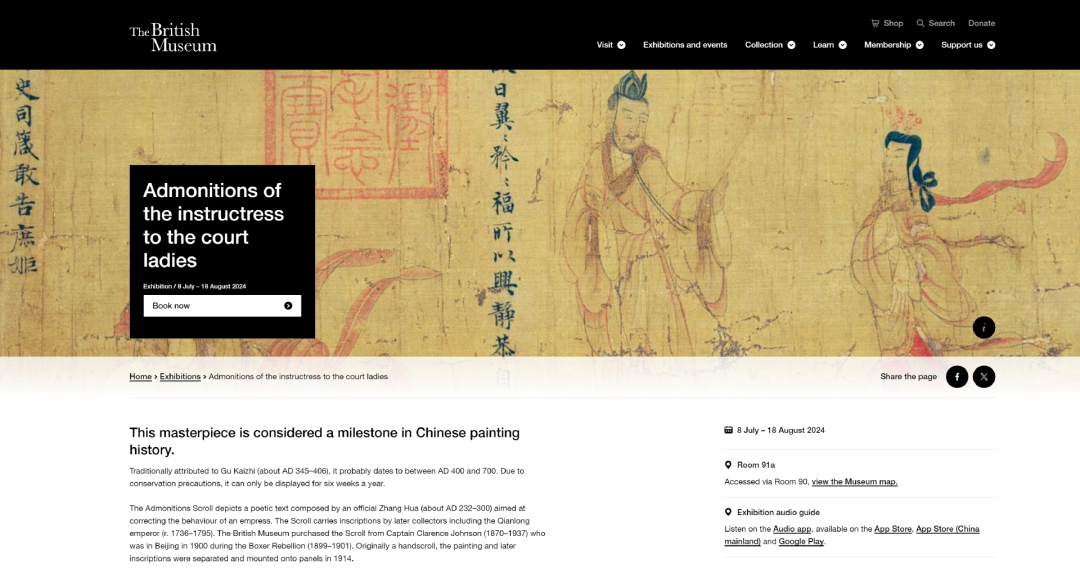
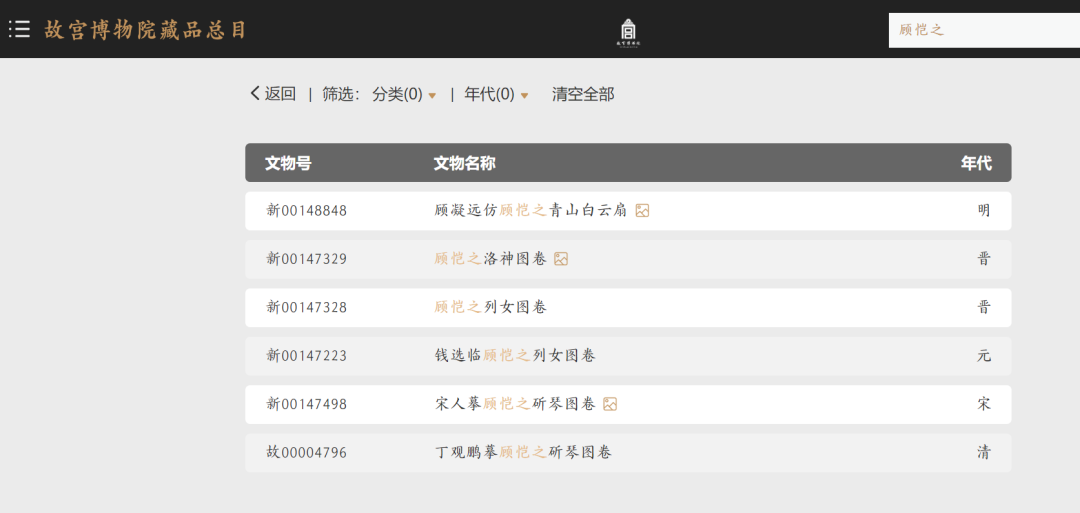
转登故宫博物院之官网一查“画祖”东晋顾恺之的藏品有几何呢?见下图:
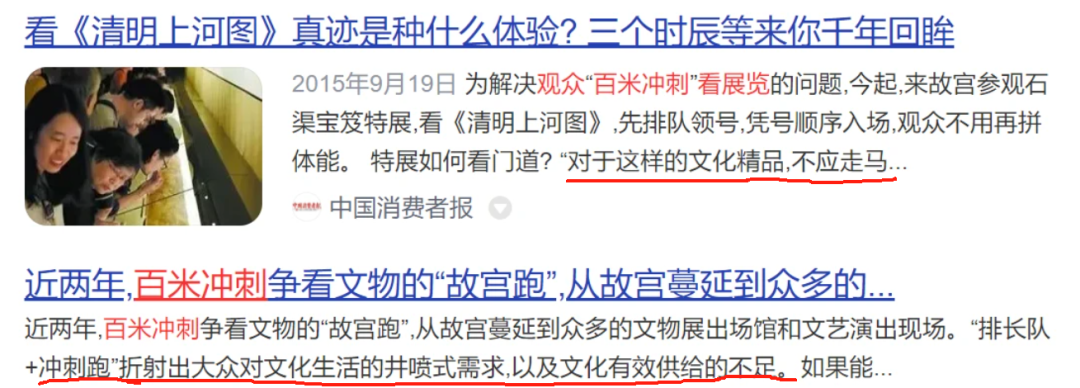
世人素有对书画的痴迷,无论是2015年故宫博物院(北京)展出《清明上河图》《五牛图》《伯远帖》时引起的“故宫跑”(见上图),还是台北博物院展出《富山春居图》时的观潮,又或日本曾展出颜真卿《祭侄文书》真迹时引发的争议…… 均可见人们对文化精神需求上的日益增长和展陈资源上的局限及供给不足……
此次大英博物馆出于人流考量和文物保护,明文规定了展厅内不设讲解,游人需靠“智能音频进行导览”。
当然,如果是精心制作的音频,观展效果一样不会打折扣,但很多素喜逛博物馆的朋友大都有过糟糕的体验——太多博物馆的音频内容极差,观众扫码后,只是听到照本宣科的一小段内容,且晦涩干瘪,毫无任何增量知识的获取,这无疑是对观展研习的一次浪费(尤其是针对青少年来说)更别提能够启迪心智了……
显然,这也是目前国内外博物馆普遍存在的一个现状与面临痛点:
· 数据的多样性和复杂性
文物数据包括文字说明、图片、音频、视频等多种形式,数据量大且复杂,管理和检索难度较高。
· 文物信息管理
博物馆拥有大量的文物,这些文物涉及丰富的历史、文化和艺术背景。如何有效管理和展示这些文物信息是一个重大挑战。
· 观众互动需求
观众在参观博物馆时,希望能够获取详细而准确的文物信息,并与展品进行互动。传统的展示和导览设备难以满足观众个性化的需求。
那么,如何用技术手段解决以上问题呢?不仅提升观众的观展体验,还能够满足个性化获取知识的需求?
嬴图的GraphRAG(Graph Retrieval-Augmented Generation),其将知识图谱、检索增强生成(RAG)和大型语言模型(LLM)结合起来,这一技术在处理复杂知识结构和生成自然语言回答方面表现出色,完全适用于博物馆文物馆藏管理和观众服务。
-
个性化导览:根据观众的兴趣和查询历史,提供个性化的文物讲解内容。
-
自然语言交互:观众可以通过语音或文字与导览系统互动,提出问题并获取即时回答。
嬴图GraphRAG在博物馆文物馆藏中的应用
1、 构建文物知识图谱
知识图谱是GraphRAG的基础,通过图结构将文物、历史事件、文化背景等知识节点和关系组织起来。
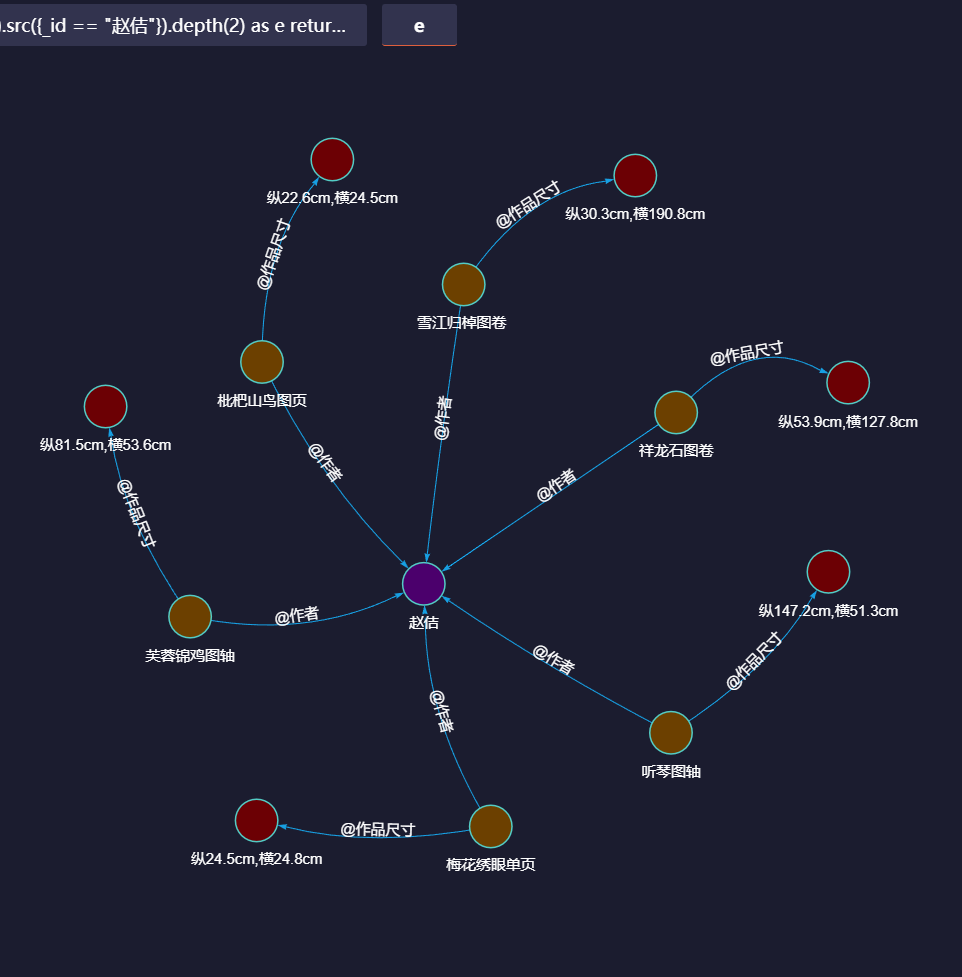
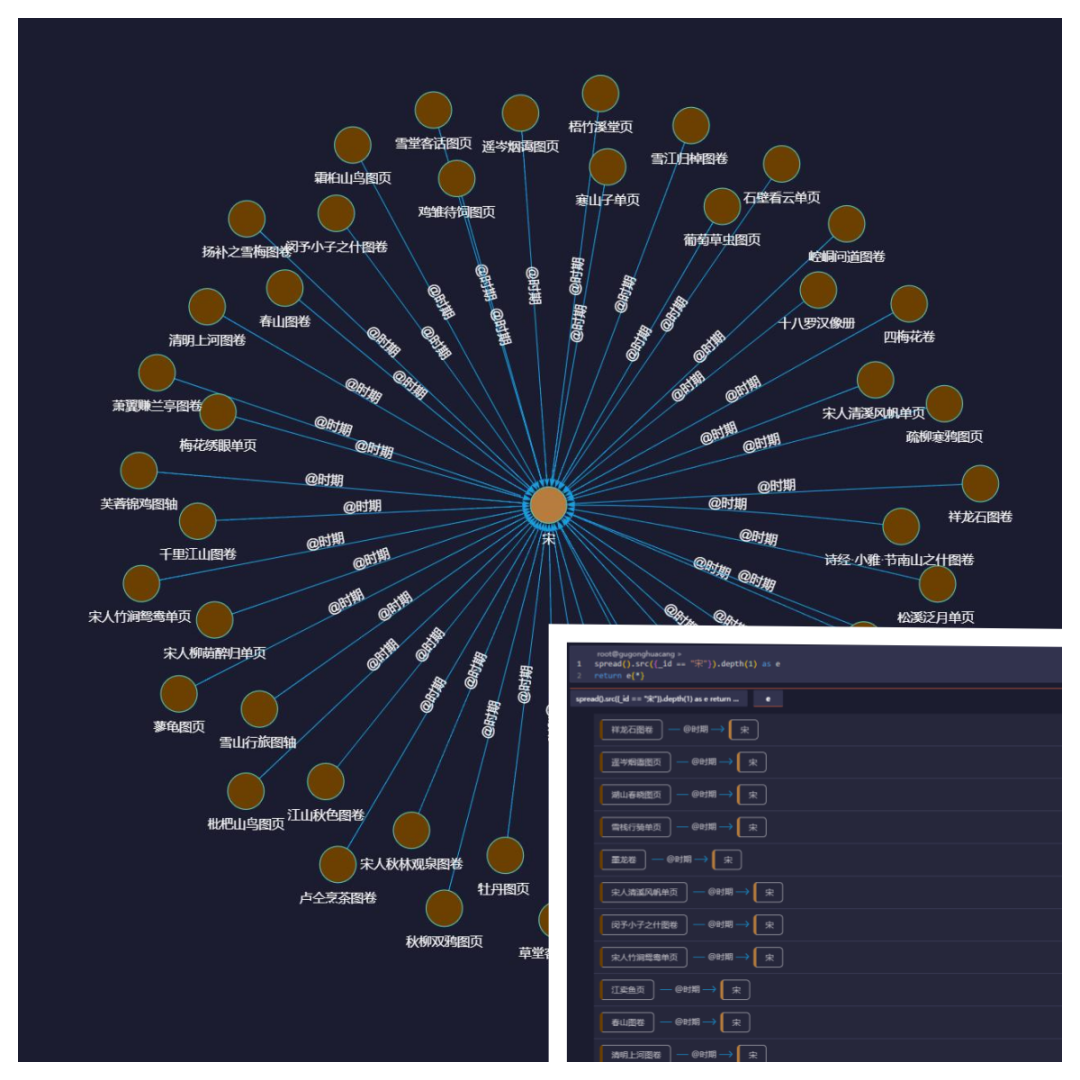
如上图所示,通过嬴图高可视化工具,我们可以直观地看到在故宫博物馆中,宋徽宗赵佶的传世之作一共有6件,且每一件的名称(如《芙蓉锦鸡图轴》)、尺寸(如纵81.5cm、横53.6cm)均有展示。【更多了解可阅读:走进嬴图Manager之高可视化】
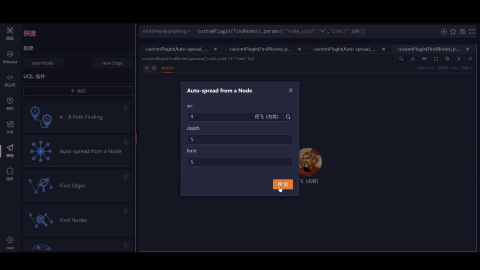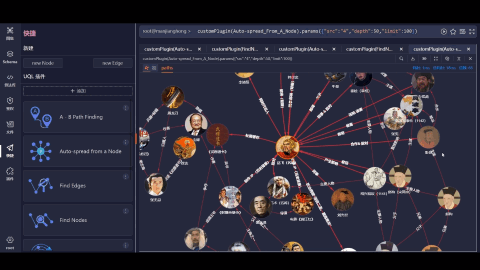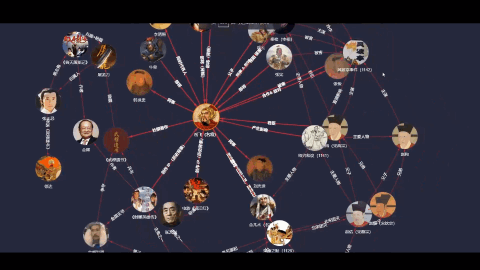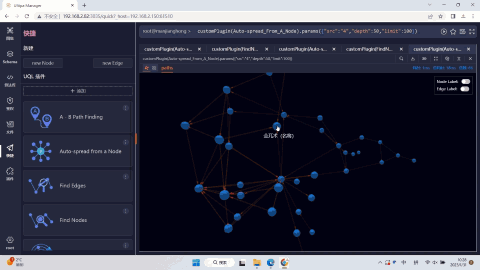
图数据库是以节点(Node)和边(Edge)的形式存储数据,非常适合表示复杂的关系网络且建模非常灵活。如下图所示,图数据库以其强大的底层引擎能力,将复杂的、海量的文物之间的关联、历史事件的时间线或考古、人文等信息全部呈现出来,构成一张庞大的、无远弗届的知识图谱——这是图技术模拟人类大脑思维方式的一种高维展示。【更多了解可阅读:图数据库知识点系列之图思维方式】
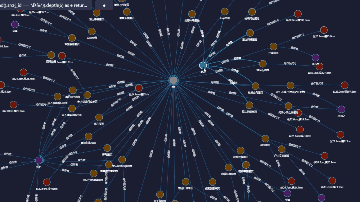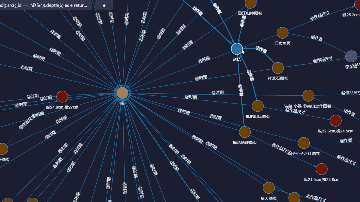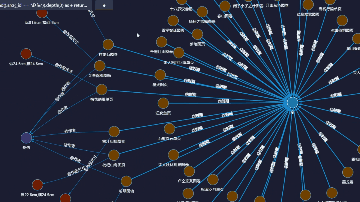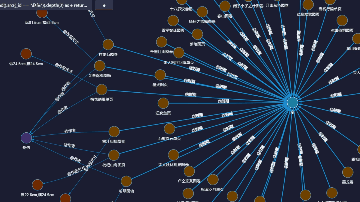
如:我们在上图中,不仅可以直观地看到以赵佶为节点所展开的所有书画作品,也可以看到故宫博物馆藏有宋朝的藏品共计45件,当然,我们还可以切换成2D形式(右下角)进行查询。(数据集采自故宫名画记:https://minghuaji.dpm.org.cn/paint/list))
另,当以赵佶为节点展开后,还可以查询到有关其更多的知识,包括人物与人物、人物与事件、事件与事件之间庞大的关联网络。如下图,赵佶和张艺谋之间有什么关系?简单组网即可查询出来:
宋徽宗赵佶(父)(君) —宋高宗赵构(子)(君) — 名将岳飞(臣) —《满江红》 电影 — 张艺谋导演

值得一提的是,构建高质量的文物知识图谱需要大量的数据处理和算法支持。目前大家所看到的知识图谱构建,大部分只是徒有其表,仅仅是围绕NLP和可视化呈现这两部分,并没有底层算力的支撑,所以并不具备解决深度查询、计算时效性与结果可解释性等能力。因此,这也是很多问答系统(如大家熟知的聊天机器人)回答质量差、答非所问或根本无法回答的原因,更不用提可以个性化、针对性地为观众答疑解惑了。
2、文物信息检索与增强生成
智能回答生成是一种结合了图结构和检索增强生成(Graph-based Retrieval-Augmented Generation)技术,通过将知识图谱(Knowledge Graph)与生成模型相结合,快速定位并提供相关文物信息,提升生成文本的准确性和信息丰富度,博物馆可以实现准确的信息融合和答案生成,为观众提供自然、准确的文物知识,提升观众体验。
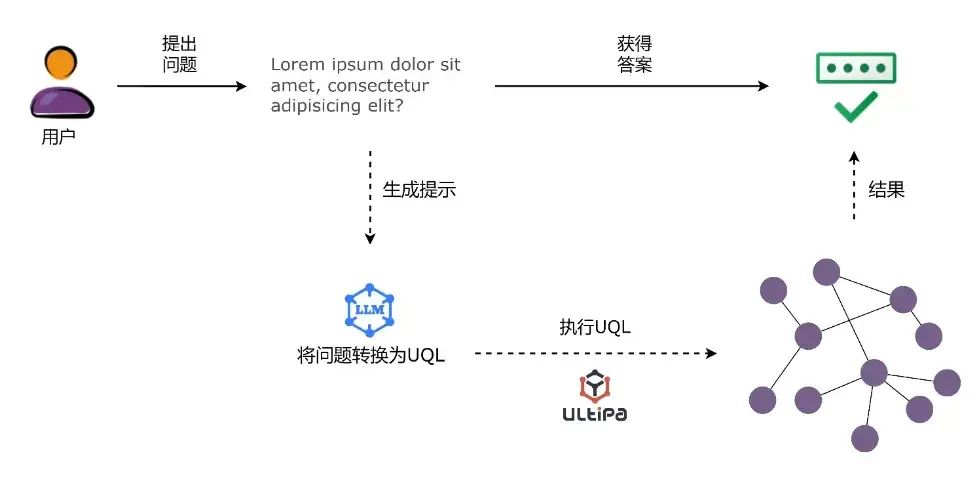
此外,嬴图专门设计的ChatGraph插件能帮助用户以对话的方式与图数据进行互动。鉴于大模型能够很好地理解自然语言,嬴图利用它从自然语言问题中提取信息,并将问题转化为准确的嬴图GQL语句,然后通过结合大模型的文本理解能力和图的结构化推理能力,能够整体增强AI系统的功能性、智能性和可解释性。
· 文物信息检索:根据观众的查询,从知识图谱中检索相关文物信息和背景资料。
· 信息融合:将检索到的信息输入到生成模型中,结合上下文生成准确的回答。
· 答案生成:通过LLM生成符合自然语言的回答,为观众提供详细而准确的文物信息。
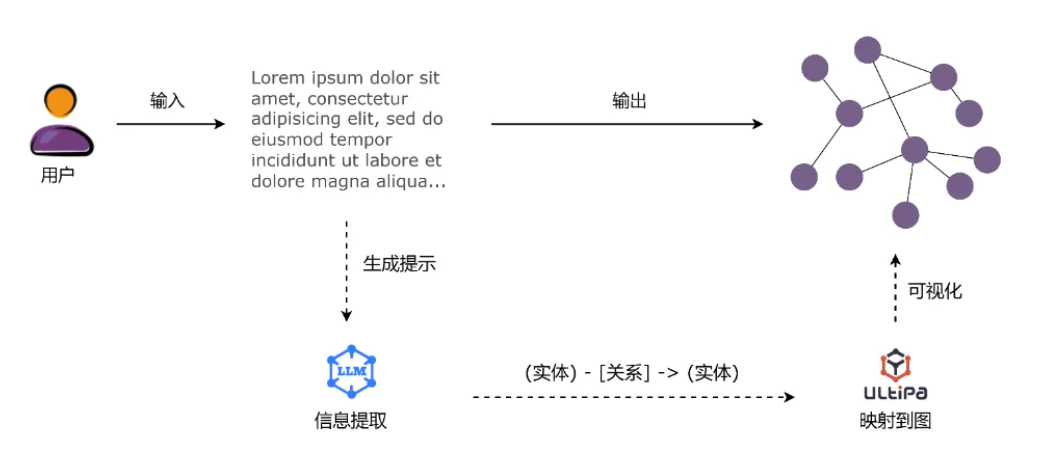
此外,在图的建模中,嬴图专门设计了Graph Extractor,它可以使用LLM自然语言处理技术识别文物实体(如文物名称、作者、年代)和关系抽取(如所属朝代、出土地)等。
-
将文档解析为节点
-
使用 LLM 从文本中提取信息并可手动定义关系
-
为每个节点生成嵌入
如此自动化快速的图构建能力和算法优化,大大提升了图的质量和查询效率。【更多了解,可阅读:嬴图 | LLM+Graph:大语言模型与图数据库技术的协同】
小结
GraphRAG通过结合知识图谱、检索增强生成和大型语言模型,为博物馆文物馆藏管理和观众服务提供了创新的解决方案。它不仅提升了文物信息管理的效率和准确性,实现全面而系统的知识管理,还为观众提供了个性化、智能化、自然准确的互动体验。
嬴图GraphRAG技术还可以应用于虚拟博物馆和在线展览。观众通过虚拟导览平台,可以远程参观博物馆,体验智能导览和互动服务,获取全面的文物信息。随着技术的不断发展,嬴图GraphRAG在博物馆领域的应用将继续拓展,为文化遗产保护和传播做出更大的贡献。(文/ Emma 、Jason)