0.简介
蒙特卡洛方法利用当前状态之后每一步奖励而不使用任何价值估计,时序差分算法则只利用当前状态的奖励以及对下一状态的价值估计。
蒙特卡洛算法是无偏的,但是它的每一步的状态转移具有不确定性,同时每一步状态采取的动作所得到的不一样的奖励最终会累计起来,从而极大影响最终的状态估计,因而其方差较大。
时序差分算法只采用了一步状态转移以及使用了一步奖励,因而具有非常小的方差;但是它由于用到了下一状态的价值估计而不是其真实价值,故而有偏。
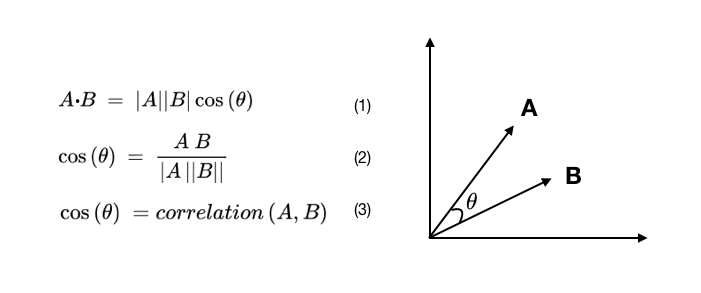
多步时序差分算法则结合了二者的优势,其使用n步奖励以及之后的状态的价值估计,其公式为:

多步Sarsa算法伪代码如下所示:

1.导入相关库
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm2.悬崖漫步环境实现环节
class cliffwalkingenv():
def __init__(self,colnum,rownum,stepreward,cliffreward,initx,inity):
self.colnum=colnum
self.rownum=rownum
self.stepreward=stepreward
self.cliffrreward=cliffreward
self.initx=initx
self.inity=inity
def step(self,action):
change=[[0,-1],[0,1],[-1,0],[1,0]]
self.x=min(self.colnum-1,max(0,self.x+change[action][0]))
self.y=min(self.rownum-1,max(0,self.y+change[action][1]))
next_state=self.y*self.colnum+self.x
reward=self.stepreward
done=False
if self.y==self.rownum-1 and self.x>0:
done=True
if self.x!=self.colnum-1:
reward=self.cliffrreward
return next_state,reward,done
def reset(self):
self.x=self.initx
self.y=self.inity
return self.y*self.colnum+self.x3.在Sarsa算法基础上进行修改,引入多步时序差分计算,实现多步(n步)Sarsa算法
class nstep_sarsa():
""" n步Sarsa算法 "" """
def __init__(self,n,colnum,rownum,alpha,gamma,epsilon,actionnum=4):
self.n=n
self.colnum=colnum
self.rownum=rownum
self.alpha=alpha
self.gamma=gamma
self.epsilon=epsilon
self.actionnum=actionnum
self.qtable=np.zeros([self.colnum*self.rownum,self.actionnum])
self.statelist=[]#保存之前的状态
self.actionlist=[]#保存之前的动作
self.rewardlist=[]#保存之前的奖励
def takeaction(self,state):
if np.random.random()<self.epsilon:
action=np.random.randint(self.actionnum)
else:
action=np.argmax(self.qtable[state])
return action
def bestaction(self,state):#打印策略
qmax=np.max(self.qtable[state])
a=[0 for _ in range(self.actionnum)]
for k in range(self.actionnum):
if self.qtable[state][k]==qmax:
a[k]=1
return a
def update(self,s0,a0,r,s1,a1,done):
self.statelist.append(s0)
self.actionlist.append(a0)
self.rewardlist.append(r)
if len(self.statelist)==self.n:#若保存的数据可以进行n步更新
G=self.qtable[s1][a1]#得到Q(s(n+t),a(n+t))
for i in reversed(range(self.n)):
G=self.gamma*G+self.rewardlist[i]#不断向前计算每一步的回报
if done and i>0:#如果到达终止状态,最后几步虽然长度不够n步,也将其进行更新
s=self.statelist[i]
a=self.actionlist[i]
self.qtable[s][a]+=self.alpha*(G-self.qtable[s][a])
s=self.statelist.pop(0)
a=self.actionlist.pop(0)
self.rewardlist.pop(0)
self.qtable[s][a]+=self.alpha*(G-self.qtable[s][a])#n步Sarsa的主要更新步骤
if done:
self.statelist=[]
self.actionlist=[]
self.rewardlist=[]
4.最终通过算法寻找的最优策略的显示
def printagent(agent,env,actionmeaning,disaster=[],end=[]):
for i in range(env.rownum):
for j in range(env.colnum):
if (i*env.colnum+j) in disaster:
print('****',end=' ')
elif (i*env.colnum+j) in end:
print('EEEE',end=' ')
else:
a=agent.bestaction(i*env.colnum+j)
pistr=''
for k in range(len(actionmeaning)):
pistr+=actionmeaning[k] if a[k]>0 else 'o'
print('%s'%pistr,end=' ')
print()5.相关参数设置
ncol=12#悬崖漫步环境中的网格环境列数
nrow=4#悬崖漫步环境中的网格环境行数
step_reward=-1#每步的即时奖励
cliff_reward=-100#悬崖的即时奖励
init_x=0#智能体在环境中初始位置的横坐标
init_y=nrow-1#智能体在环境中初始位置的纵坐标
n_step=5#5步Sarsa算法
alpha=0.1#价值估计更新的步长
epsilon=0.1#epsilon-贪婪算法的探索因子
gamma=0.9#折扣衰减因子
num_episodes=500#智能体在环境中运行的序列总数
tqdm_num=10#进度条的数量
printreturnnum=10#打印回报的数量
actionmeaning=['↑','↓','←','→']#上下左右表示符6.程序主体部分实现
np.random.seed(0)
returnlist=[]
env=cliffwalkingenv(colnum=ncol,rownum=nrow,stepreward=step_reward,cliffreward=cliff_reward,initx=init_x,inity=init_y)
agent=nstep_sarsa(n=n_step,colnum=ncol,rownum=nrow,alpha=alpha,gamma=gamma,epsilon=epsilon,actionnum=4)
for i in range(tqdm_num):
with tqdm(total=int(num_episodes/tqdm_num),desc='Iteration %d'% i) as pbar:#tqdm进度条功能
for episode in range(int(num_episodes/tqdm_num)):#每个进度条的序列数
episodereturn=0
state=env.reset()
action=agent.takeaction(state)
done=False
while not done:
nextstate,reward,done=env.step(action)
nextaction=agent.takeaction(nextstate)
episodereturn+=reward#这里回报计算不进行折扣因子衰减
agent.update(state,action,reward,nextstate,nextaction,done)
state=nextstate
action=nextaction
returnlist.append(episodereturn)
if (episode+1)%printreturnnum==0:#每printreturnnum条序列打印一下这printreturnnum条序列的平均回报
pbar.set_postfix({'episode':'%d'%(num_episodes/tqdm_num*i+episode+1),'return':'%.3f'%(np.mean(returnlist[-printreturnnum:]))})
pbar.update(1)
episodelist=list(range(len(returnlist)))
plt.plot(episodelist,returnlist)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('{}-step Sarsa on{}'.format(n_step,'Cliff Walking'))
plt.show()
print('{}步Sarsa算法最终收敛得到的策略为:'.format(n_step))
printagent(agent=agent,env=env,actionmeaning=actionmeaning,disaster=list(range(37,47)),end=[47])
7.实现效果与数据
Iteration 0: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 626.45it/s, episode=50, return=-26.500]
Iteration 1: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 3128.16it/s, episode=100, return=-35.200]
Iteration 2: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 2781.15it/s, episode=150, return=-20.100]
Iteration 3: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 2182.42it/s, episode=200, return=-27.200]
Iteration 4: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 2634.94it/s, episode=250, return=-19.300]
Iteration 5: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 2638.69it/s, episode=300, return=-27.400]
Iteration 6: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 2638.86it/s, episode=350, return=-28.000]
Iteration 7: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 2281.37it/s, episode=400, return=-36.500]
Iteration 8: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 2785.10it/s, episode=450, return=-27.000]
Iteration 9: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 2642.51it/s, episode=500, return=-19.100]

5步Sarsa算法最终收敛得到的策略为:
ooo→ ooo→ ooo→ ooo→ ooo→ ooo→ ooo→ ooo→ ooo→ ooo→ ooo→ o↓oo
↑ooo ↑ooo ↑ooo oo←o ↑ooo ↑ooo ↑ooo ↑ooo ooo→ ooo→ ↑ooo o↓oo
ooo→ ↑ooo ↑ooo ↑ooo ↑ooo ↑ooo ↑ooo ooo→ ooo→ ↑ooo ooo→ o↓oo
↑ooo **** **** **** **** **** **** **** **** **** **** EEEE
8.总结
通过实验我们可以发现5步Sarsa算法的收敛性比单步Sarsa算法更快,此时多步Sarsa算法得到的策略会在最远离悬崖的一边行走,以保证最大的安全性。关于单步Sarsa算法在悬崖漫步中的实现效果见我另一篇博客:强化学习时序差分算法之Sarsa算法——以悬崖漫步环境为例。