1,ELMo:Embedding新纪元
1.1,word2vec的局限性
word2vec:word2vec模型是一种可以用于各种任务的单词级别的表示学习。以单词stick为例子,它有非常多的意思:
v. 粘贴;粘住;被接受;(在某物中)卡住,陷住,动不了; (尤指迅速或随手)放置;戳;容忍;将…刺入(或插入); 对…不感兴趣;不再要牌 n. 棍,条,签;(飞机的)操纵杆,驾驶杆;一管,一支(胶棒等); 枝条;批评;(车辆的)变速杆,换挡杆; 枯枝;球棍;指挥棒;条状物;棍状物;柴火棍儿如果使用word2vec、GloVe的那些词嵌入,那么不管stick的上下文是什么,单词stick都将由同一个向量表示。也就是说,对一个词只有一个词嵌入,哪怕这个词其实有超级多的意思。这其实还挺蠢的。所以就有很多学者站出来说:“stick有多种意思,而它的意思则取决于他的上下文。“Let's stick to”和“he pick up a stick so that”中的stick显然是两个意思,却用了同一个词向量。为什么不根据上下文语境进行embedding呢?这样既能捕捉该语境中的含义,又捕捉其他语境信息。”
1.2,语境化词嵌入
语境化词嵌入可以根据词语在句子语境中的含义赋予词语不同的embedding。在问ELMo,stick的词嵌入是什么的时候,ELMo是不会像word2vec一样给一个肯定的答案的,因为ELMo没有对每个单词使用固定的词嵌入,而是在为每个单词计算embedding之前考虑整个句子。ELMo模型使用的是特定任务上训练好的双向LSTM(bi-LSTM)进行词嵌入。

1.3,ELMo模型结构
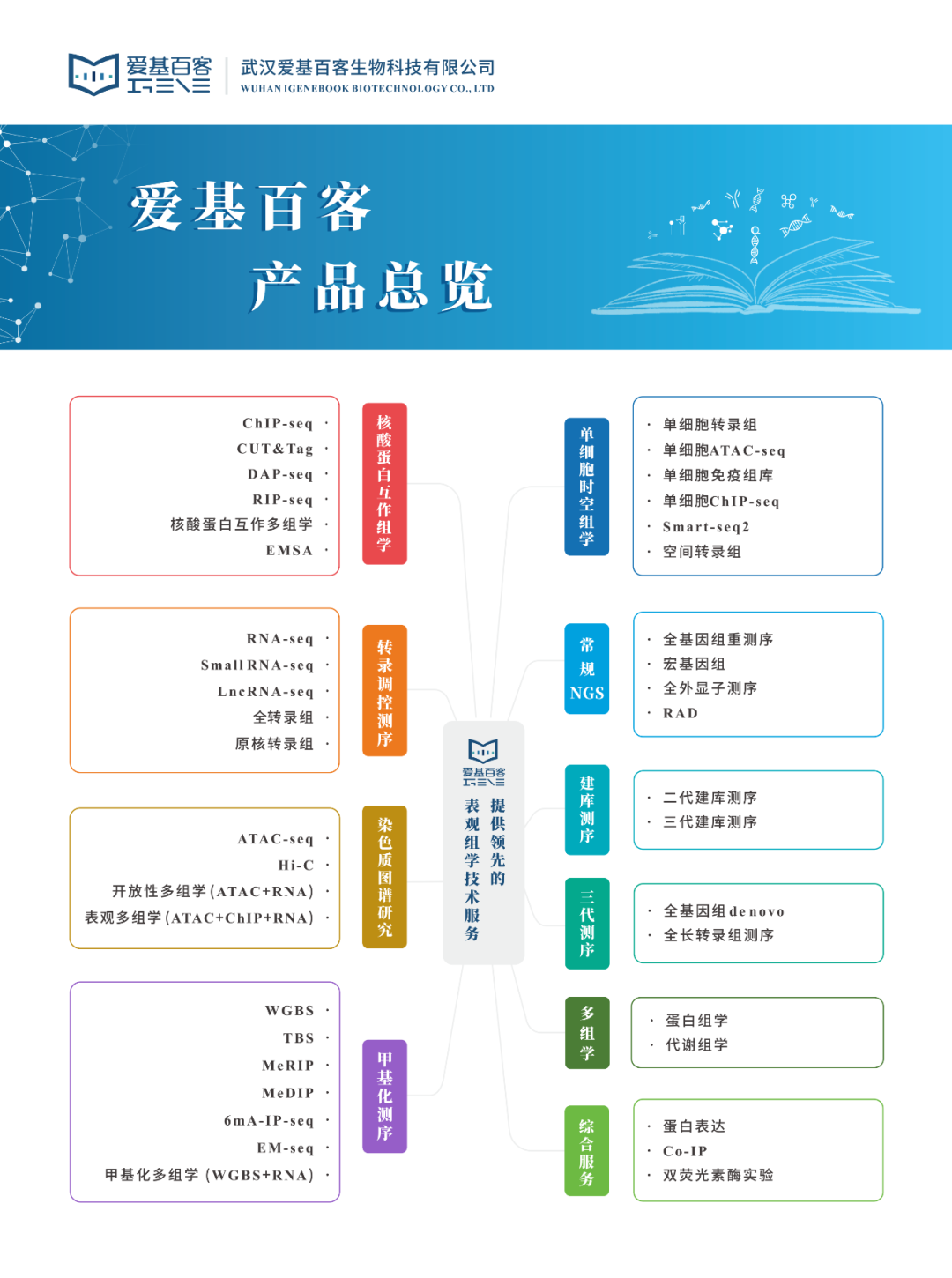
宏观上ELMo分三个主要模块:
- 最底层黄色标记的Embedding模块。
- 中间层蓝色标记的两部分双层LSTM模块。
- 最上层绿色标记的词向量表征模块。
【字符嵌入层】ELMo模型使用字符嵌入来表示每个词语,这是通过卷积神经网络来实现的。ELMo模型中的CNN主要用于从输入文本中提取字符级别的特征,这些特征可以捕捉到单词中的前缀和后缀信息,从而提高词向量的表达能力。具体来说,ELMo使用了一个具有多个卷积核的卷积层,每个卷积核对应一个不同的字符级别窗口大小,通过对输入文本进行卷积操作,可以提取出每个字符级别窗口中的特征。这些特征经过池化和拼接操作后,可以形成一个与输入文本相同长度的字符级别特征向量,作为LSTM网络的输入之一。
【双向LSTM层】ELMo模型使用双向LSTM(Bi-LTSM)来捕捉词语在上下文中的语义信息。Bi-LSTM分别从左向右和从右向左对输入序列进行扫描,可以同时考虑到前向和后向的上下文信息,从而生成上下文相关的词向量。在ELMo模型中,Bi-LSTM层由两个独立的LSTM单元组成,分别从前向和后向两个方向对输入文本进行建模,形成了两个独立的隐藏状态序列。
- 对于左半部分:给定
个
, Language Model通过前面
个位置的token序列来计算第
个token出现的概率,构成前向双层LSTM模型.
- 对于右半部分:给定
,Language Model通过后面
个位置的 token 序列来计算第
【上下文相关词向量层】ELMo模型通过将字符嵌入和双向LSTM层的输出进行拼接,并通过一个线性变换得到最终的上下文相关词向量。这些词向量可以根据输入句子的不同上下文进行调整,从而捕捉到不同上下文中词语的语义信息。
【输出层】ELMo模型可以通过在上下文相关词向量上添加任务特定的输出层,如全连接层、Softmax层等,来进行具体的NLP任务,如文本分类、命名实体识别等。因为ELMo给下游提供的是每个单词的特征形式,所以这一类预训练方法被称为"Feature-based Pre-Training"。
【缺点】ELMo在传统静态word embedding方法(Word2Vec,GloVe)的基础上提升了很多, 但是依然存在缺陷,有很大的改进余地。主要有以下两点:
- 第一点:一个很明显的缺点在于特征提取器的选择上,ELMo使用了双向双层LSTM,而不是现在横扫千军的Transformer,在特征提取能力上肯定是要弱一些的。如果ELMo的提升提取器选用Transformer,那么后来的BERT的反响将远不如当时那么火爆。
- 第二点:ELMo选用双向拼接的方式进行特征融合,这种方法肯定不如BERT一体化的双向提取特征好。

2,大预言模型基石:Transformer
2.1,基本概述
在seq2seq把Attention机制发扬光大后,NLP领域的模型的主流架构是递归神经网络(一般是LSTM)+注意力机制,后者起到一个辅助作用。然而,LSTM再怎么样都不过是一个变种RNN,难以并行训练、发挥GPU的优势这件事让他们训练效率很慢,自然不存在大力出奇迹造出一个超级大的语言模型的可能性。Transformer模型非常非常的激进,他直接抛弃了作为模型主体的RNN,只保留了注意力机制。在做NLP的任务时,CNN、RNN和Transformer相比,并行程度CNN大于Transformer远大于RNN,信息糅合能力RNN大于Transformer远大于CNN。
原版的Transformer有六个编码器和六个解码器,是一个比较深的网络结构。可以看到,最开始的时候,Transformer主要用于神经翻译任务,所以这里先用神经翻译任务举例子。如果没有编码器,那就是Decoder-Only(GPT);如果没有解码器,那就是Encoder-Only(BERT)。

【问题】编码器如何给Token编码才能做到与RNN相同的时序能力?
【答案】首先需要把输入的每个单词通过词嵌入(embedding)转化为对应的向量。在Attention is All You Need原文中,他们采用了512维的词嵌入,这里为了方便展示,用4个格子来代表512维的词向量们。
Transformer中的编码器不只采用了词嵌入本身的Embedding,还为每个词基于位置额外增加了一个Embedding(Positional Encoding),它的维度和词嵌入是一样的。最终输入给Transformer的是两个嵌入向量的和。这是因为:
- Transformer激进地放弃了自带时序处理能力的RNN,而Attention本身又是不会有时序信息的(用自注意力实现全局,不等于拥有时序信息!全局不等于时序)。
- Transformer 不采用 RNN 的结构,使用全局信息,不能利用单词的顺序信息,而顺序信息对于 NLP 来说又非常重要。所以 Transformer 中使用位置 Embedding 保存单词在序列中的相对或绝对位置。
通过Positional Encoding,模型可以确定每个单词的位置或不同单词之间的距离。而位置编码需要做到:每个位置对应的编码唯一;不论句子有多长,每两个相邻位置之间的距离都一样;所有的编码都要在一个有限的区间内,编码用到的数字不能爆炸上升(这其实真的很难做到!)。
具体的,Transformer里的位置编码:它是一个和词嵌入同维的、sin和cos交替的向量。


2.2,编码器:自注意层
【编码器:Self-Attention层 + 前馈神经网络层】6个编码器组件的结构是相同的,但是他们之间的权重是不共享的,每个编码器都可以分为2个子层。
- 编码器的输入
首先会进入一个自注意力层,这个注意力层的作用是:当要编码某个特定的词汇的时候,它会帮助编码器关注句子中的其他词汇。
- 自注意力层的输出
会传递给一个前馈神经网络,每个编码器组件都是在相同的位置使用结构相同(每个Encoder中的FFNN结构相同但参数不同)的前馈神经网络。

【三个矩阵】
- 查询矩阵(Query):用于计算注意力权重,表示当前时间步需要关注哪些位置。
- 键矩阵(Key):用于匹配查询,帮助确定输入序列中每个位置的重要性。
- 值矩阵(Value):包含实际的输入信息,在计算注意力加权和时使用。
【自注意力层】在之前的seq2seq注意力机制里,两个做点积来计算Attention Score的向量分别在编码器和解码器里,而Transformer的自注意力层里,两个做点积的向量都是源自编码器(或者解码器)。
对每一个输入的向量(512维),把它乘一个512*64的权重矩阵,最后就会得到一个64维的向量。四个格子代表了512维的向量,Q、K、V中的向量都是三个格子,三个格子代表的就是一个64维的向量。在编码器的自注意力层中,训练三个权重不共享(目的不同)的512*64的矩阵:
,
,
。对编码器的每个输入向量,都分别乘以这三个矩阵,计算出三个64维的向量:Query向量,Key向量和Value向量。
【计算注意力得分:Query和Key的点积】在Transformer的自注意力层里,假设输入的Embedding有N个:
,对于第
,进行点积的向量分别为:
以及全部N个输入对应的向量:
。以Thinking Machine个两个词的输入为例,Thinking的查询向量
会分别和句子中所有的输入
对应的Key向量做点积(可以判断向量相似度),得到Thinking这个词对于句子中的每一个词的注意力得分。
【计算注意力分布】标准的计算注意力分布的方法就是对注意力得分做一个Softmax。不过在原版的Transformer中,作者们先把注意力得分除以了一个8(Q、K、V向量的维度的根号值)。这是因为两个64维向量做点积算出来的标量还是很大的,如果不做额外的处理就直接去softmax的话,会导致Attention Distribution高度集中于当前位置的单词,但这显然不是想要的,还想知道当前的单词和其他各种单词的联系。总之,这里的除以8更多的其实是一种基于实践的工程经验。
【计算Output】既然注意力分布是一个概率密度函数,那注意力输出
其实很类似数学期望。Transformer中的自注意力层也是一样,都是数学期望的思维。上一步计算出Attention Distribution为P(Thinking)=0.88、P(Machine)=0.12,在最后会用这个概率分布乘以对应的单词的Value向量。最终单词 Thinking的输出
等于所有单词的值
根据 attention 系数的比例加在一起得到:





2.3,编码器:多头注意力机制
首先,在翻译一个特定单词的时候,模型的注意力肯定主要关注这个词自身。希望翻译这个词的时候模型多去关注上下文的其他词,但上下文联系其实也有很多种,有 it 这样的指代、are这样的单复数、were这样的时态,或者说基于不同的上下文,一个单词自身也会有不同的意义(想起ELMo还有Stick了吗?)。如果多训练几个不同的权重矩阵:
对于同一个输入Thinking Machine,有8个权重矩阵组,因此最终会产生8个Z矩阵:
将这些矩阵连接起来,形成了一个2*512维的矩阵;然后将其乘以一个产生最终输出的权重矩阵
。图中

2.4,解码器第一层:带掩码的多头自注意力层
【解码器:带掩码的Self-Attention层 + Self-Attention 层+一个前馈神经网络】解码器组件也含有前面编码器中提到的两个层,区别在于这两个层之间还夹了一个注意力层,多出来的这个自注意力层的连接了编码器输出的隐状态,起到了和seq2seq中的attention一样的作用。
在解码器中,第一个Self-Attention和编码器的第一个自注意力层也是不同的。它是一个带掩码的自注意力层,带掩码的意思就是,对于一个总共有N个单词的词序列,在翻译到第K个单词时候,这个自注意力层只能注意到第1到第K个单词,而注意不到第K+1到第N个单词。

带掩码的多头自注意力层:解码器中的自注意力层和编码器中的不太一样:在解码器中,自注意力层只允许关注已输出位置的信息。所以我们称之为“带掩码的自注意力层”。Decoder block 的第一个 Multi-Head Attention 采用了 Masked 操作,因为在翻译的过程(训练)中是顺序翻译的,即翻译完第 i 个单词,才可以翻译第 i+1 个单词。通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息,从而避免抄答案的操作(防止预测试没有答案)。
Mask操作主要是在Softmax的时候实现的:如果要翻译I have a cat为中文,我们依然可以用
和
做矩阵乘法的操作,这样会得到一个4*4的矩阵。
但是在解码器里,要做这样一个操作:
自注意力层只允许关注已输出位置的信息,所以对于已输出位置和未输出的位置的点积(上图中的黑色的位置),在softmax时会给他加上一个巨大的负值(GPT中为负一亿),好让他们在softmax后得到的结果为0。这样,在输出当前时间步的时候,解码器就不会去关注后面的单词的信息了。最终得到了一个4*64的矩阵,它会作为Query矩阵直接被输入给解码器的下一层Encoder-Decoder Attention。矩阵的第一列(I的z向量,也是下一个注意力层中 I 的查询向量)就只包含了I的信息。



2.5,解码器第二层:多头编码器-解码器注意力层
假定N为6,八头注意力:编码器首先处理输入序列,输入序列经过了6个Encoder之后,第六个编码器会输出一个张量。该张量会被平等的送给每个Decoder的第二个注意力层,并通过一个共享参数的权重矩阵
转为8个Key矩阵和8个Value矩阵。在这一层中,解码器组件使用自己的带掩码的第一层自注意力层产生的8个Z矩阵作为8种Query矩阵,并使用编码器传过来的8个Key和Value矩阵,来做前面提到过的多头自注意力的运算。在经过两个多头注意力层后,最后会经过一个全连接层,然后输出一个向量给最后的Linear和Softmax层。
Decoder输出的是一个浮点型向量,如何把它变成一个词?这就是最后一个线性层和softmax要做的事情。线性层就是一个简单的全连接神经网络,它将解码器生成的向量映射到logits向量中。然后,softmax层将这些分数转化为概率(全部为正值,加起来等于1.0),选择其中概率最大的位置的词汇作为当前时间步的输出。就像seq2seq一样,transformer的解码器中当前时间步的输出会作为下一个时间步的输入。

3,Multitask Learning
3.1,NLP预训练难题
迁移学习极大地影响了计算机视觉的发展,但现有的NLP方法仍然需要针对特定任务进行修改,并从头开始训练具体的模型NLP领域迟迟没有出现像CV一样的Inductive transfer learning的原因:
- 数据集太少(标注成本非常高;而且网络上的语言质量参差不齐,是一种挑战);
- CV的大多数任务基本都是基于分类的,而NLP领域却有很多任务,包括基本的命名实体识别任务和句法分析任务;包括基于分类的任务,如情感分析;以及基于序列的任务,如机器翻译和自然语言生成。这些任务涉及不同的数据结构和算法,很难用同一个模型、同一个权重全部概括。
- 对于数据集太少问题,可以用利用半监督学习(Semi-supervised Learning):用少量的有标签数据和大量的无标签数据进行训练,以提高模型的性能。
- 对于任务太多的问题,一个重要的解决方案就是Multitask Learning,多任务学习。
3.2,Cookie Monster
Cookie Monster的三个微调技术:
- Discriminative fine-tuning(‘Discr’) 是指在深度学习中对预训练模型进行微调,以适应新任务或数据集的过程。在这个过程中,每层的学习率被设置为不同的值。
- 斜三角学习率(Slanted triangular learning rates,STLR)是一种用于训练神经网络的学习率策略,旨在加速训练过程并提高模型性能。它首先线性增加学习率,然后根据右表线性衰减。
- 渐进式解冻(Progressive Unfreezing)是一种用于训练深度神经网络的技术,其利用了分阶段训练的方法,旨在缓解深度神经网络训练中的过拟合问题,并提高模型的性能。
- 在传统的深度神经网络训练中,通常是先对整个网络进行训练,然后再微调各个层,这种方式可能会导致网络过拟合,即模型对训练数据过于敏感,泛化能力较差。而渐进式解冻则是一种分阶段训练的方法,可以使得网络逐步地学习到数据的更多细节信息,从而降低过拟合的风险。
- 具体而言,渐进式解冻的步骤如下:1、将深度神经网络的所有层进行冻结,只训练最后一层。2、在最后一层训练收敛后,解冻前一层,继续训练倒数第二层。3、在两层训练收敛后,解冻前一层,继续训练倒数第三层。依次类推,直到所有层都被解冻并训练完成。
- 通过这种方式,渐进式解冻可以逐步增加网络的复杂度和容量,使得网络可以逐步学习到数据的更多细节信息,并逐渐适应数据的不同特征,从而提高模型的性能。此外,渐进式解冻还可以提高模型的泛化能力,并缩短训练时间,减少过拟合的风险。
训练Cookie Monster的三步:
- 在一般领域的Corpus上训练LM,以捕捉语言的一般特征(论文原作里,作者在Wikitext-103上预训练语言模型,前者由28,595篇预处理的维基百科文章和1.03亿个单词组成)。这个阶段是最昂贵的,但它只需要执行一次,并能提高下游模型的性能和收敛性。
- 在目标任务数据上使用Discr和STLR对完整的LM进行微调,以学习特定的任务特征。
- Discr背后的思想:由于不同的层捕获不同类型的信息,它们应该被微调到不同的程度。
- STLR的目的:希望模型在训练开始时能迅速收敛到参数空间的一个合适区域,然后完善其参数。
- 分类器(Classifier):在目标任务上使用渐进式解冻、"Discr "和STLR进行微调,以保留低级表征并适应高级表征(图中,阴影:解冻阶段;黑色:冻结)。
ULM-FiT是一种有效的、极其节省样本的迁移学习方法,可以应用于任何NLP任务。ULM-FiT之前,NLP领域的Fine-tuning一直存在过拟合、灾难性遗忘、数据集不够等挑战,而ULM-FiT采用了多任务学习,提出了几种新的微调技术,有效防止了灾难性的遗忘,并在不同的任务中实现了稳健的学习。NLP领域终于有了类似CV的迁移学习方法。