本文还发布在我的 medium 和 掘金 上
这篇文章让我们看看MySQL中count(*)和count(column_name)有什么区别。也许你知道它们都是计算结果行数的,那么在使用的时候如何选择呢。

我在MySQL库中创建了一个t_hero表
CREATE TABLE `t_hero` (
`id` int NOT NULL,
`name` char(10) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
往表里插入了6条数据,如下
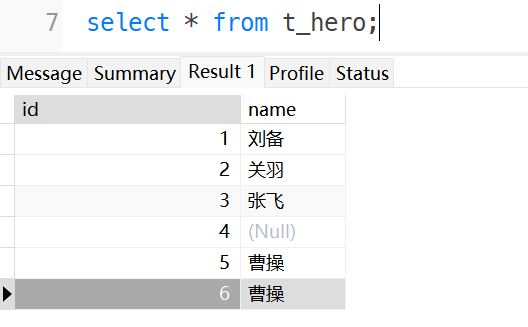
然后使用count(*)、count(distinct column)和count(column)查询
SELECT COUNT(*), 'COUNT(*) ' FROM t_hero
UNION
SELECT COUNT(name), 'COUNT(name)' from t_hero
UNION
SELECT COUNT(DISTINCT name), 'COUNT(DISTINCT name)'from t_hero;
输出结果
6 COUNT(*)
5 COUNT(name)
4 COUNT(DISTINCT name)
因此,可以得出结论:
- 要计算查询返回的行数,请执行以下操作:
select count(*) from table; - 计算查询返回的非 null 值的数量:
select count(column) from table; - 计算查询返回的不同值的数量:
select count(distinct column) from table;