引言
今天又带来一篇提示策略的论文笔记:TAKE A STEP BACK: EVOKING REASONING VIA ABSTRACTION IN LARGE LANGUAGE MODELS。
作者提出了回退提示(STEP-BACK PROMPTING)技术,使大模型能够进行抽象,从包含具体细节的实例中推导出高层次的概念和基本原则。通过利用这些概念和原则来指导推理,LLMs显著提高了按照正确推理路径解决问题的能力。
Step back是后退一步的意思,退一步海阔天空。这里后退一步指对原始具体问题进行更高层次的抽象,然后基于后退一步问题的答案来帮助回答原始问题。
1. 总体介绍
尽管LLM取得了重大进展,复杂的多步推理对于即便是最先进的LLMs而言依然具有挑战性。思维链等技术被引入,以生成一系列连贯的中间推理步骤,从而提高跟随正确解码路径的成功率。受到这样一个事实的启发:在面对具有挑战性的任务时,人类往往会后退并进行抽象,以获得高层次的原则来指导过程,作者提出了STEP-BACK提示,以将推理建立在抽象之上,从而降低在中间推理步骤中出错的机会。

本工作探讨了LLMs如何通过抽象与推理的两步过程来解决涉及多个低层次细节的复杂任务。第一步是通过上下文学习向LLMs展示如何后退——提示它们为特定示例推导出高层次的抽象,如概念和原则。第二步是利用推理能力基于高层次的概念和原则进行推理。
2. 回退提示
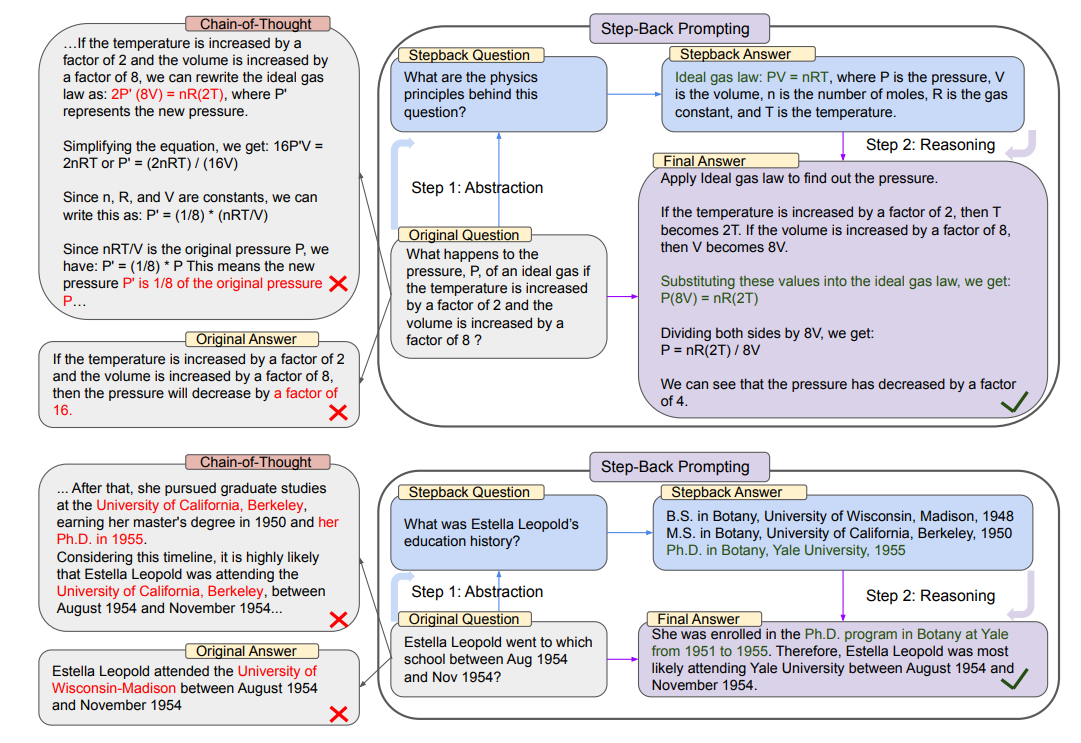
图2:回退提示的示意图,包括基于概念和原则的抽象和推理两个步骤。顶部:一个来自MMLU高中物理的例子,通过抽象检索理想气体法则的第一原理。底部:一个来自TimeQA的例子,高层次概念“教育历史”是抽象的结果。左侧:PaLM-2L未能回答原始问题。在中间推理步骤中,链式推理提示出现了错误(用红色标出)。右侧:PaLM-2L通过回退提示成功回答了问题。
回退提示的动机来源于观察到许多任务包含大量细节,而LLMs在检索相关事实以解决任务时面临困难。如图2中的第一个示例所示,对于一个物理问题“如果温度增加2倍,体积增加8倍,理想气体的压力P会发生什么变化?”,LLM在直接推理时可能偏离理想气体法则的第一原理。同样,问题“Estella Leopold在1954年8月至1954年11月期间去过哪个学校?”由于详细的时间范围限制,直接解决起来非常困难。在这两种情况下,提出一个后退(抽象)问题可以有效帮助模型解决问题。
将后退问题定义为一个源自原始问题的更高层次抽象的问题。例如,不是直接问“Estella Leopold在特定期间去过哪个学校”,我们可以问一个后退问题(图2底部),“Estella Leopold的教育历史是什么”,这是一个包含原始问题的高层次概念。在这种情况下,回答关于“Estella Leopold的教育历史”的后退问题,将提供解决“Estella Leopold在特定期间就读于哪个学校”所需的所有必要信息。前提是,后退问题通常要容易得多。在此类抽象基础上进行推理有助于避免在中间步骤中出现推理错误,比如图2(左)中链式推理的示例所示。简而言之,回退提示包含两个简单步骤:
- 抽象:首先提示LLM提出一个关于高层次概念或原则的一般性后退问题,而不是直接回答问题,并检索关于该高层次概念或原则的相关事实。每个任务的后退问题是独特的,以便检索到最相关的事实。
- 推理:基于高层次概念或原则的事实,LLM可以推理出原始问题的解决方案。作者将其称为“基于抽象的推理”(Abstraction-grounded Reasoning)。
3. 实验设置
3.1 任务
我们实验以下多样化的任务:(a)STEM,(b)知识问答,以及(c)多跳推理。
-
STEM:评估MMLU和GSM8K以进行STEM任务。MMLU包含一系列跨不同领域的基准,以评估模型的语言理解能力。由于涉及较深的推理,我们考虑MMLU的高中物理和化学部分。
-
知识问答:选择TimeQA,它包含需要复杂时效性知识的查询。还对另一个具有挑战性的开放检索问答数据集SituatedQA进行了实验,该数据集要求模型在给定时间或地理上下文的情况下回答问题。
-
多跳推理:实验了MuSiQue,这是一个通过可组合的单跳问题对创建的困难多跳推理数据集,以及StrategyQA,该数据集包含需一定策略解决的开放域问题。
3.2 模型
使用以下最先进的语言模型(LLMs):指令调优的PaLM-2L、GPT-4和Llama2-70B。
3.3 评估
传统的评估指标,如准确率和F1分数,在评估最先进LLM的生成时存在局限性,因为这些模型通常会生成难以捕捉的长格式答案。因此,使用PaLM-2L模型进行评估,通过少量示例提示模型识别目标答案与模型预测之间的等效性。
3.4 基准方法
-
PaLM-2L,PaLM-2L 1-shot:PaLM-2L直接查询问题,或者在提示中包含一个问题-答案的单一示例。
-
PaLM-2L + CoT,PaLM-2L + CoT 1-shot:PaLM-2L模型通过零样本链式推理(CoT)提示进行查询:“让我们一步一步来思考”附加到问题上。对于1-shot,在提示中提供一个问题和答案对的演示示例,其中答案采用思维链推理的风格。
-
PaLM-2L + TDB:在问题前加上“深呼吸,逐步解决这个问题。”进行零样本提示。
-
PaLM-2L + RAG:使用检索增强生成(RAG),其中检索到的段落作为上下文由LLM使用。
-
GPT-4和Llama2-70B:对所有方法在MMLU任务上运行GPT-4和Llama2-70B。此外,还在所有任务的所有基准上运行GPT-4。
不对STEM任务使用RAG,因为这些任务的内在推理性质与其他寻求事实的数据集相反。所有推理均使用贪心解码进行。
4. STEM
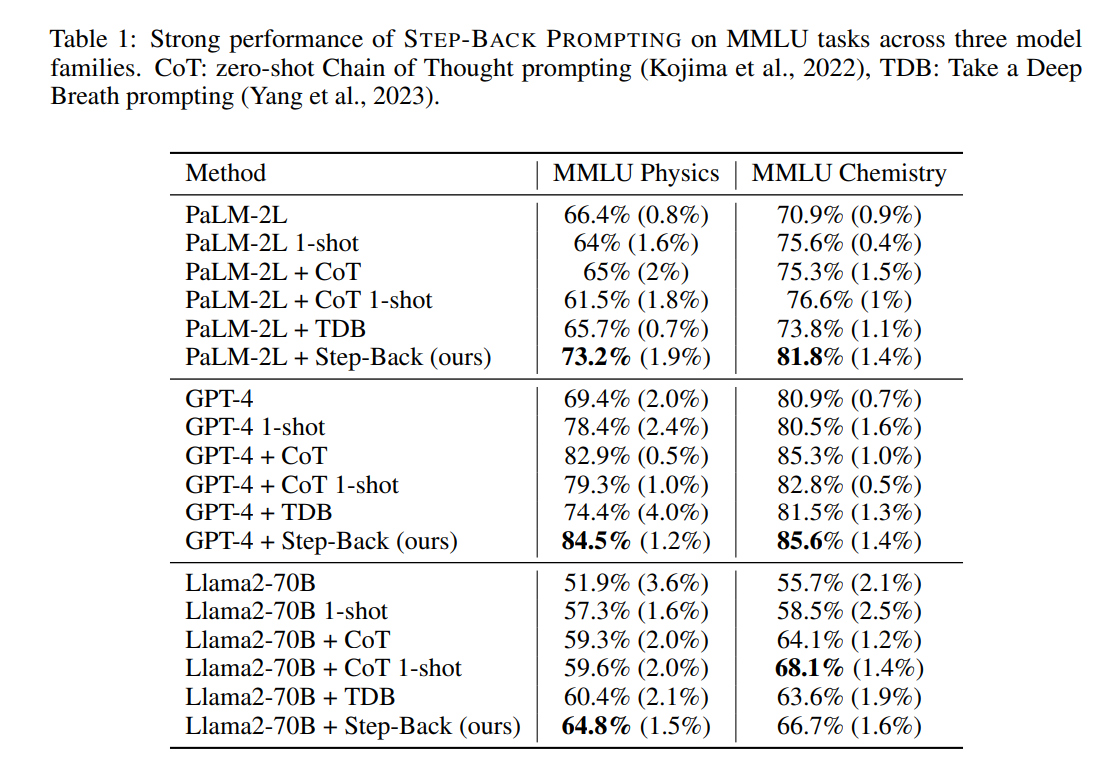
表1展示了三种模型系列:PaLM-2L、GPT-4和Llama2-70B的不同设置下的模型表现。CoT和TDB的零样本提示并未显著提高模型性能,这可能与这些任务固有的难度和深度推理有关。相比之下,STEP-BACK PROMPTING显著提高了模型性能:与PaLM-2L相比分别提升了7%和11%。STEP-BACK PROMPTING是模型无关的。
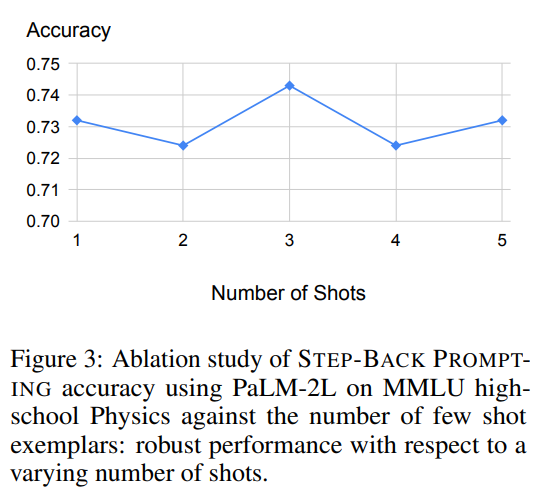
首先,在图3中,我们观察到STEP-BACK PROMPTING对用作演示的(问题,原理)对的少量样本示例数量具有较强的鲁棒性。添加超过一个示例的更多演示示例并不会带来进一步的改进。这表明,通过上下文学习提取相关的原理和概念的任务相对简单,单个演示就足够了。
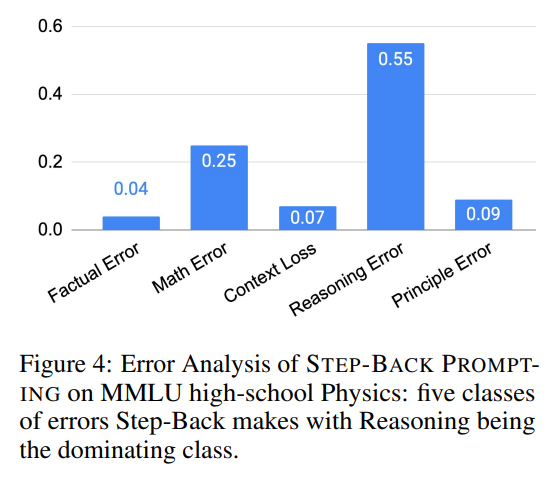
将STEP-BACK PROMPTING的预测与基线PaLM-2L模型在MMLU高中物理的表现进行比较:STEP-BACK PROMPTING纠正了基线模型20.5%的错误,同时引入了11.9%的错误。
为了进一步了解STEP-BACK PROMPTING中错误的来源,我们对测试集中的所有错误预测进行了标注,并将其分类为5类:
- 原理错误(Principle Error):错误发生在抽象步骤,模型生成的第一原理是错误或不完整的。
- 事实错误(Factual Error):当模型背诵自身的事实知识时,至少存在一个事实错误。
- 数学错误(Math Error):当涉及数学计算以推导出最终答案时,至少一个中间步骤出现数学错误。
- 上下文缺失(Context Loss):模型响应中至少存在一个错误,其中响应失去了问题的上下文,偏离了原始问题。
- 推理错误(Reasoning Error):我们将推理错误定义为模型在得出最终答案之前,在中间推理步骤中至少出现一次错误。
这五种类型的错误是在推理步骤中发生的,除了原理错误,后者指向抽象步骤的失败。如图4(右)所示,原理错误仅占模型错误的一小部分:超过90%的错误发生在推理步骤中。在推理过程中的四种错误类型中,推理错误和数学错误是主要的错误类别。
推理步骤仍然是STEP-BACK PROMPTING在执行复杂推理任务(如MMLU)时的瓶颈。特别是在MMLU物理中,推理和数学技能对于成功解决问题至关重要:即使第一原理被正确提取,深度推理和数学运算也涉及到通过典型的多步骤推理过程得出正确的最终答案。
5. 知识问答
在需要大量事实知识的问题回答基准上评估了STEP-BACK PROMPTING
首先通过上下文示例向LLMs展示如何进行抽象。图2中的“Estella Leopold的教育历史是什么”这一回退问题是通过少量示例由LLM生成的。考虑到这些查询的知识密集特性,将检索增强(RAG)与STEP-BACK PROMPTING结合使用。通过回退问题检索相关事实,这些事实作为额外的上下文为最终推理步骤提供依据。
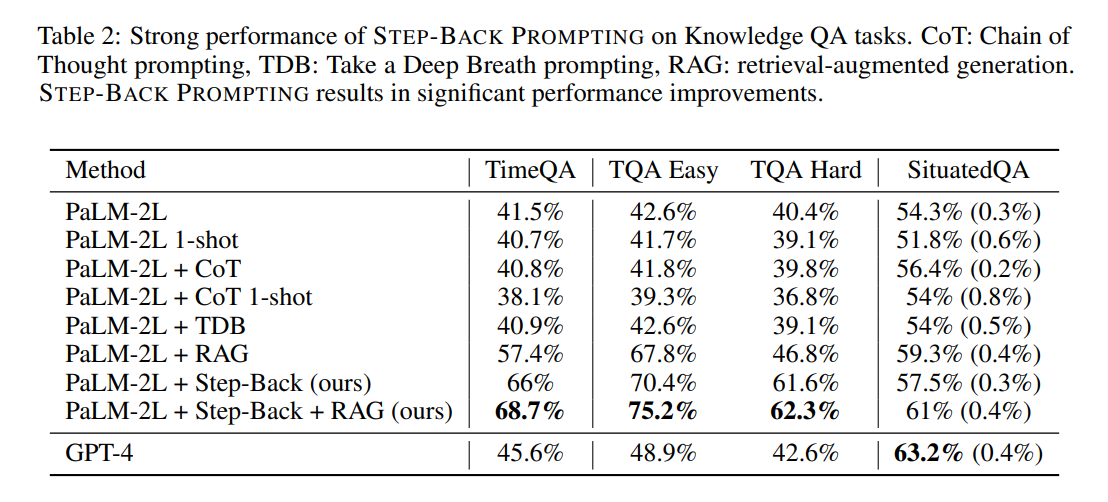
在TimeQA的测试集上评估模型。如表2所示,GPT-4和PaLM-2L的基线模型分别达到了45.6%和41.5%的准确率,突显了任务的难度。相比之下,常规的检索增强(RAG)提升了基线模型的准确率至57.4%,强调了任务的事实密集特性。Step-Back + RAG的结果显示了回归到高层次概念的有效性,从而实现了更可靠的检索增强;TimeQA的准确率达到了显著的68.7%。
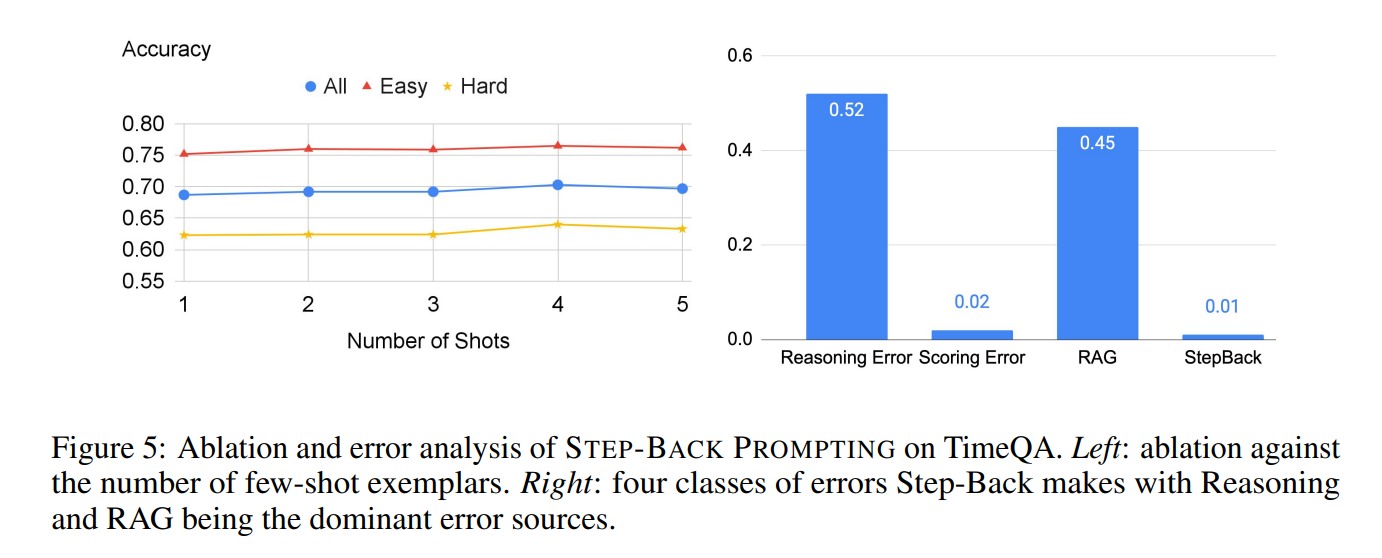
少样本消融:在图5(左)中观察到,STEP-BACK PROMPTING在TimeQA上的表现对演示中使用的示例数量稳健,这再次突显了像PaLM-2L这样的模型在上下文学习中的样本效率。
错误分析:图5(右)显示了STEP-BACK PROMPTING在TimeQA中造成的所有剩余错误的细分。
这里将错误分类为:
- StepBack:生成的回退问题对解决任务没有帮助。
- RAG:尽管回溯问题是针对性的,RAG仍无法检索到相关信息。
- 评分错误:评估模型出现了错误。
- 推理错误:检索到的上下文是相关的,但模型依然无法通过上下文推理出正确答案。
回退几乎很少失败。相反,超过一半的错误是由推理错误引起的。此外,45%的错误是由于未能检索到正确的信息,尽管回退提供的抽象使任务变得更容易。
6. 多跳推理
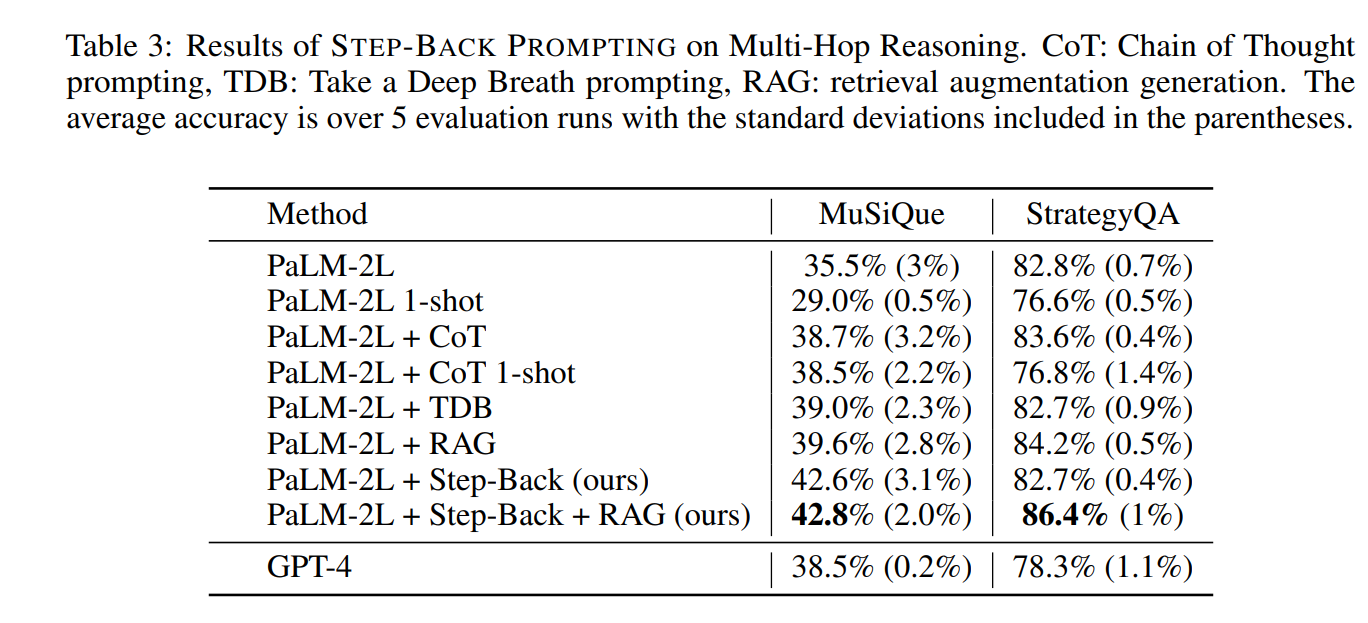
在具有挑战性的多跳推理基准MuSiQue和StrategyQA上评估了STEP-BACK PROMPTING。表3显示了在MuSiQue和StrategyQA的开发集上各种基线的表现。
在MuSiQue的情况下,CoT和TDB略微提高了模型的性能,这可以归因于此任务的内在推理特性,使得这些方法表现得很有帮助。在StrategyQA的情况下,使用CoT和TDB没有显著的性能提升,这可能是由于此任务的基线性能较高,这些提示方法的改进空间有限。通常,1-shot的表现显著低于其0-shot的方法,这可能是由于潜在的示例偏差。RAG提高了模型性能。结合抽象能力的STEP-BACK PROMPTING在所有方法中表现最佳:在MuSiQue中为42.8%,在StrategyQA中为86.4%。
7. 讨论
抽象帮助人类通过去除无关细节并提炼高层次的概念和原则来解决复杂任务,从而指导问题解决过程。STEP-BACK PROMPTING将复杂任务,如知识密集型问答、多跳推理和科学问题,分解为两个独立的步骤:抽象和推理。
尽管取得了一定成功,通过错误分析发现,推理仍然是LLMs最难掌握的技能之一:即使在STEP-BACK PROMPTING大幅度降低任务复杂性之后,推理仍然是主要的失败模式。
然而,抽象并不是在所有场景中都是必要或可能的。例如,任务可以简单到像“2000年美国总统是谁?”这样的问题,在这种情况下,没有必要退后一步去问一个高层次的问题,因为此类问题的答案显而易见。诸如“光速是多少?”这样的题目直接指向了第一原理。在这种情况下进行抽象也不会带来区别。
8. 相关工作
8.1 提示技术
少样本提示显著提升了模型在多种任务上的表现,而无需更新任何模型参数。STEP-BACK PROMPTING与思维链推理提示和草稿纸(scratchpad)处于同一类别,因为它们都具有简单性和通用性。但专注于抽象这一关键思想。也与背诵增强语言模型(e recitation-augmented language models)相关;然而,与他们的工作不同,明确地执行了回退和抽象,并根据当下任务的性质选择性地使用检索增强。
8.2 任务分解
将任务分解为更简单的任务并解决这些任务以完成原始任务一直是一种有效的方式来提高模型在复杂任务上的表现。在这方面,一些提示方法已经取得了成功。STEP-BACK PROMPTING工作则是在使问题更抽象和高层次,这与通常是原始问题的低层次分解不同。例如,对于“史蒂夫·乔布斯在1990年为哪个雇主工作?”这一通用问题,可以转化为“史蒂夫·乔布斯的就业经历是什么?”而分解则会导致子问题,如“史蒂夫·乔布斯在1990年做什么?”、“史蒂夫·乔布斯在1990年是否受雇?”以及“如果史蒂夫·乔布斯受雇,他的雇主是谁?”此外,诸如“史蒂夫·乔布斯的就业经历是什么?”这样的抽象问题通常是通用性质的,具有多对一的映射关系,因为许多问题(例如“史蒂夫·乔布斯在1990年为哪个雇主工作?”和“史蒂夫·乔布斯在2000年为哪个雇主工作?”)可以对应同一个抽象问题。这与分解不同,通常存在一对多的映射关系,而解决给定问题通常需要多个分解的子问题。
9 结论
作者引入了回退提示,作为一种简单但通用的方法,通过抽象在大型语言模型中引发深度推理。抽象帮助模型减少幻觉并更好地推理,可能反映了模型的真实特性,而这些特性在没有抽象的情况下回答原始问题时往往被隐藏。
Langchain中关于回退提示的示例代码如下:
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
system = """You are an expert at taking a specific question and extracting a more generic question that gets at \
the underlying principles needed to answer the specific question.
You will be asked about a set of software for building LLM-powered applications called LangChain, LangGraph, LangServe, and LangSmith.
LangChain is a Python framework that provides a large set of integrations that can easily be composed to build LLM applications.
LangGraph is a Python package built on top of LangChain that makes it easy to build stateful, multi-actor LLM applications.
LangServe is a Python package built on top of LangChain that makes it easy to deploy a LangChain application as a REST API.
LangSmith is a platform that makes it easy to trace and test LLM applications.
Given a specific user question about one or more of these products, write a more generic question that needs to be answered in order to answer the specific question. \
If you don't recognize a word or acronym to not try to rewrite it.
Write concise questions."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
step_back = prompt | llm | StrOutputParser()
总结
⭐ 作者提出了回退提示技术,使大模型能够进行抽象,从包含具体细节的实例中推导出高层次的概念和基本原则。通过利用这些概念和原则来指导推理,LLMs显著提高了按照正确推理路径解决问题的能力。









![[java]小程序,输出20个随机数,并统计每个随机数出现的次数](https://img-blog.csdnimg.cn/d5de42f869834b67b3e63fd13e9e4332.png)