本文来源公众号“程序员学长”,仅用于学术分享,侵权删,干货满满。
原文链接:快速学会一个算法,ANN
今天给大家分享一个强大的算法模型,ANN。
人工神经网络 (ANN) 是一种深度学习方法,源自人类大脑生物神经网络的概念。它由大量相互连接的人工神经元(也称为节点或单元)组成,每个神经元接收输入,进行简单处理后生成输出,并将结果传递给下一层的神经元。
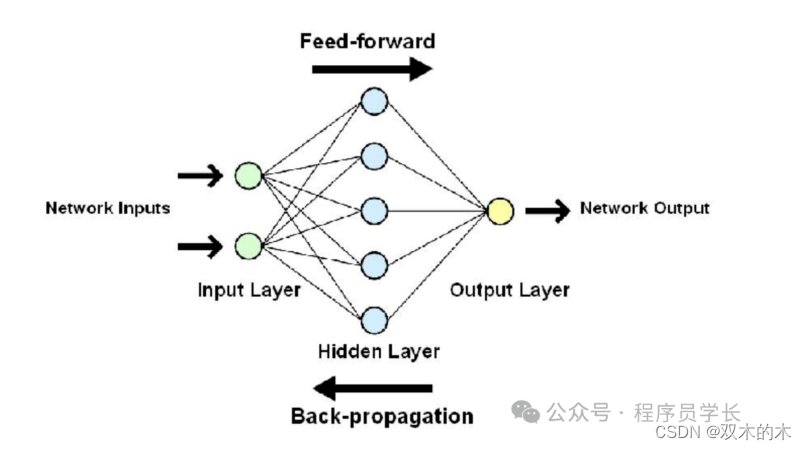
人工神经网络架构
ANN 的基本构成包括输入层、隐藏层(不止一层)和输出层。典型的「前馈网络」以单向方式处理信息,从输入到输出。由于层数众多,有时也被称为 MLP(多层感知器)。
人工神经网络的类型
-
前馈神经网络 (FNN)
这些是简单的网络,信息以单向流动,例如从输入到输出。它们用于识别数据中的模式或进行预测等任务,使其成为模式识别的理想选择。
-
卷积神经网络 (CNN)
卷积神经网络是一种专门用于处理网格状数据(如图像)的深度学习模型。CNN在图像识别、图像分类、目标检测等领域表现尤为出色。
-
循环神经网络 (RNN)
循环神经网络是一种适合处理序列数据的神经网络模型。RNN在自然语言处理、时间序列预测、语音识别等领域表现突出。其主要特点是能够利用循环结构来记住和处理序列中的上下文信息。
-
长短期记忆网络 (LSTM)
长短期记忆网络是一种特殊的循环神经网络(RNN)架构,旨在解决传统 RNN 在处理长序列时的梯度消失和梯度爆炸问题。LSTM通过引入门控机制,能够更有效地捕捉长时间的依赖关系。
-
生成对抗网络 (GAN)
生成对抗网络是一种由两个神经网络组成的深度学习模型,分别称为生成器(Generator)和判别器(Discriminator)。这两个网络通过相互对抗的方式共同训练,以生成逼真的数据样本。GAN 用于创建新内容、增强图像,甚至生成深度伪造。
人工神经网络的应用
由于其独特的特性,ANN 具有广泛的应用。
ANN 的一些重要应用包括.
-
图像处理和计算机视觉
-
图像分类和识别:用于自动标注图像内容,如人脸识别、物体检测等。
-
图像生成和修复:生成对抗网络(GAN)在生成逼真图像、图像超分辨率和图像修复中应用广泛。
-
-
自然语言处理
-
语言翻译:通过深度学习模型实现自动语言翻译,如谷歌翻译。
-
情感分析:分析文本的情感倾向,用于市场分析和客户反馈。
-
语音识别:将语音转换为文本,用于语音助手、语音输入等。
-
-
时间序列预测
-
金融市场预测:预测股票价格、外汇汇率等金融数据的未来趋势。
-
需求预测:预测商品需求量,用于库存管理和供应链优化。
-
天气预报:基于历史气象数据进行未来天气的预测。
-
案例分享
为了理解 ANN,我们将使用举世闻名的泰坦尼克号生存预测。
你可以在此处找到数据集
https://www.kaggle.com/competitions/titanic/data
该分类器将帮助我们根据各种特征预测哪些乘客在灾难中幸存下来。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from keras.models import Sequential
from keras.layers import Dense
# 加载数据
data = pd.read_csv('train.csv')
# 数据预处理
data['Age'].fillna(data['Age'].mean(), inplace=True)
data['Embarked'].fillna(data['Embarked'].mode()[0], inplace=True)
data = pd.get_dummies(data, columns=['Sex', 'Embarked'], drop_first=True)
data.drop(columns=['Name', 'Ticket', 'Cabin'], inplace=True)
# 定义特征和标签
X = data.drop(columns=['Survived'])
y = data['Survived']
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 标准化特征
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 构建ANN模型
model = Sequential()
model.add(Dense(32, input_dim=X_train.shape[1], activation='relu'))
model.add(Dense(16, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 编译模型
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型
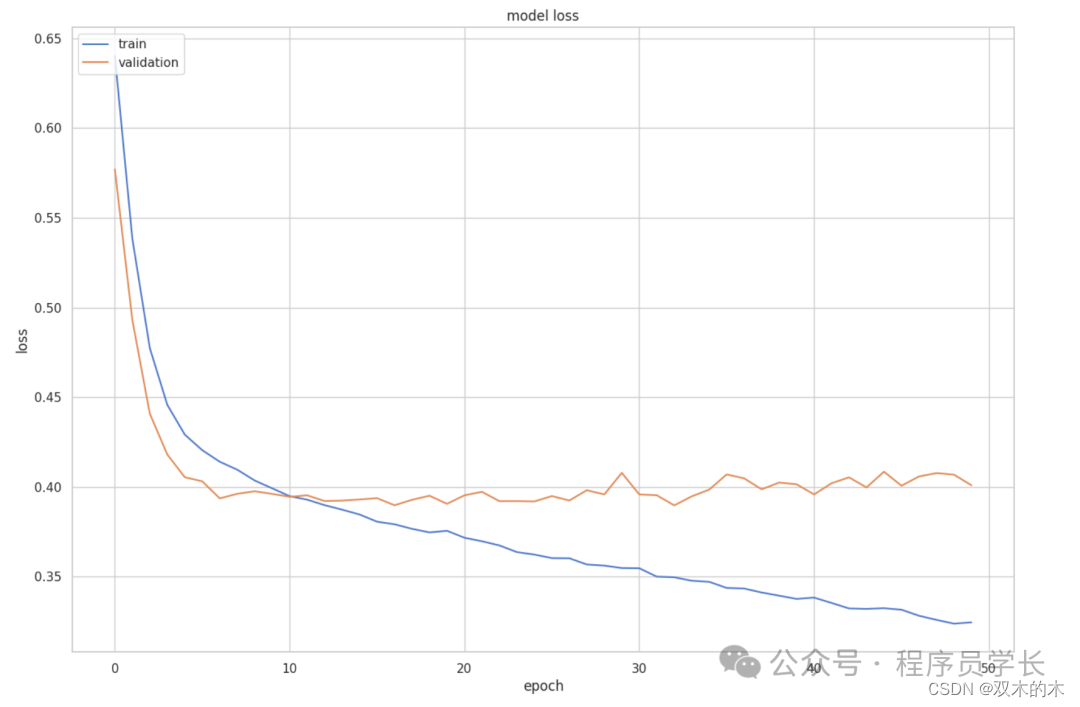
training=model.fit(X_train, y_train, epochs=50, batch_size=10, validation_split=0.2)接下了,我们看一下在训练过程中的损失变化。
plt.plot(training.history['loss'])
plt.plot(training.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()结果:
代码如下:
# 评估模型
loss, accuracy = model.evaluate(X_test, y_test)
print(f'Test Accuracy: {accuracy:.2f}')
# 预测新数据
predictions = model.predict(X_test)
predictions = (predictions > 0.5).astype(int)
print(predictions[:10])THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。