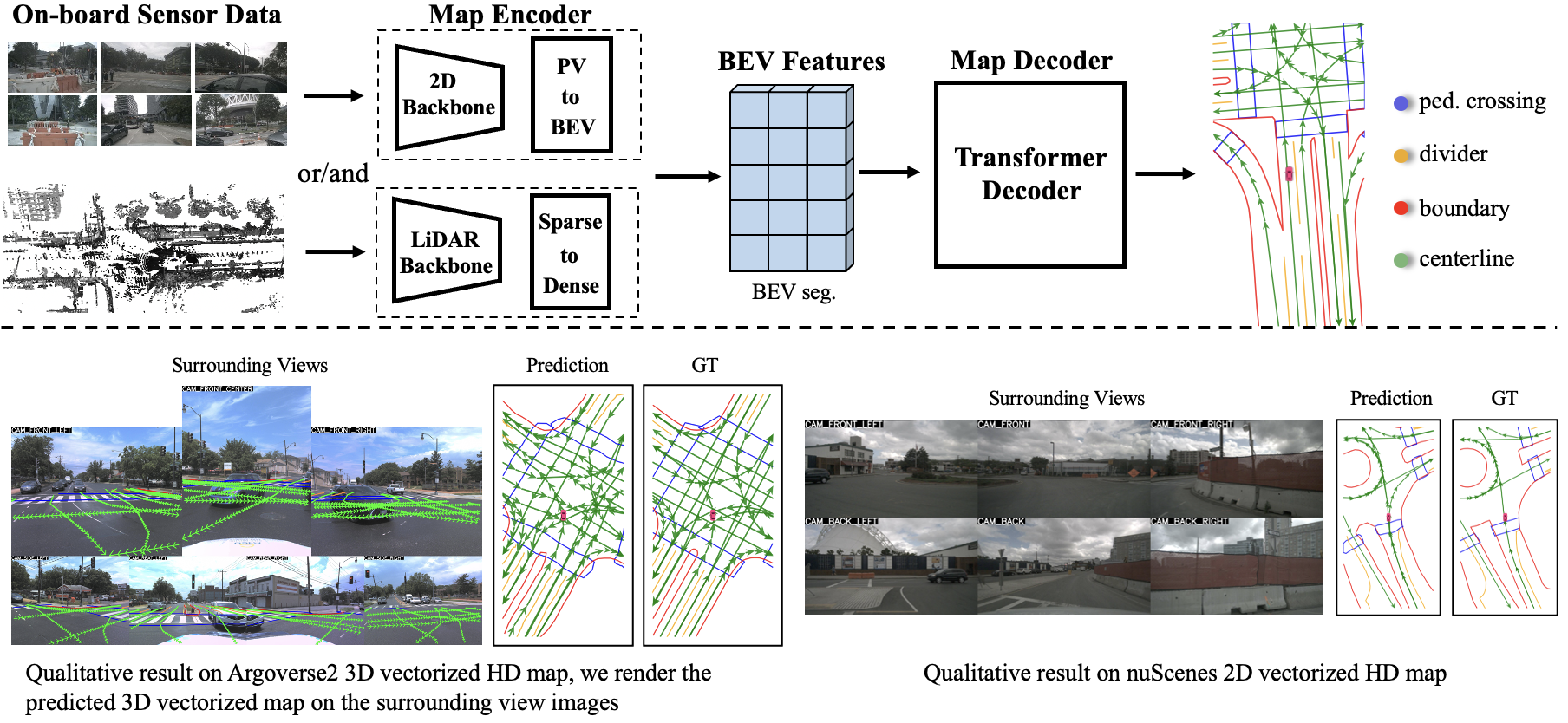
决策树节点分裂:探索不同的标准与方法
决策树是一种广泛用于分类和回归任务的机器学习算法。其核心思想是通过一系列简单的规则(即节点分裂)将数据集划分为不同的子集,直到满足某种停止条件为止。在节点分裂过程中,选择最优的分裂标准和方法是构建高效决策树的关键。本文将详细介绍决策树节点分裂的不同标准与方法,具体到源码示例,帮助您深入理解和应用这些技术。
一、决策树的基本概念
决策树是一种树形结构,其中每个内部节点表示一个特征(属性)上的测试,每个分支表示测试结果的一个值,每个叶节点表示一个类别或数值(决策结果)。决策树的构建过程通常包括以下几个步骤:
- 选择最优分裂特征和分裂点:在每个节点选择一个最优的特征及其相应的分裂点,以最大化子集的纯度。
- 递归地构建子树:对每个子集递归地应用上述步骤,直到满足停止条件(如最大树深、最小样本数等)。
二、常见的节点分裂标准
在决策树中,节点分裂标准是衡量分裂后子集纯度的指标。常见的节点分裂标准包括:
- 信息增益(Information Gain):衡量通过分裂某个特征能够减少多少不确定性。基于熵(Entropy)的概念。
- 信息增益比(Information Gain Ratio):对信息增益进行归一化处理,以避免偏向多值特征。
- 基尼指数(Gini Index):衡量一个样本随机分类到某个类别的概率。
- 方差减少(Variance Reduction):主要用于回归树,衡量分裂后目标变量的方差减少量。
1. 信息增益
信息增益是基于熵的概念来衡量特征分裂前后信息的不确定性减少程度。熵的定义如下:
[ H(D) = - \sum_{i=1}^{k} p_i \log_2(p_i) ]
其中,(p_i) 是类别 (i) 的概率。信息增益定义为:
[ IG(D, A) = H(D) - \sum_{v \in V} \frac{|D_v|}{|D|} H(D_v) ]
其中,(D) 是数据集,(A) 是特征,(V) 是特征 (A) 的取值集合,(D_v) 是特征 (A) 取值为 (v) 的子集。
2. 信息增益比
信息增益比对信息增益进行归一化处理,以减少其对多值特征的偏向。定义为:
[ GR(D, A) = \frac{IG(D, A)}{H(A)} ]
其中,(H(A)) 是特征 (A) 的固有值(Intrinsic Value),定义为:
[ H(A) = - \sum_{v \in V} \frac{|D_v|}{|D|} \log_2 \left( \frac{|D_v|}{|D|} \right) ]
3. 基尼指数
基尼指数用于衡量数据集的不纯度,定义为:
[ Gini(D) = 1 - \sum_{i=1}^{k} p_i^2 ]
其中,(p_i) 是类别 (i) 的概率。特征 (A) 的基尼指数定义为:
[ Gini(D, A) = \sum_{v \in V} \frac{|D_v|}{|D|} Gini(D_v) ]
4. 方差减少
方差减少主要用于回归树,用于衡量目标变量的方差减少量,定义为:
[ \Delta Var = Var(D) - \sum_{v \in V} \frac{|D_v|}{|D|} Var(D_v) ]
其中,(Var(D)) 是数据集 (D) 中目标变量的方差。
三、决策树的实现
接下来,我们将通过 Python 代码实现一个简单的决策树算法,探索不同的分裂标准和方法。
1. 数据集准备
首先,我们准备一个示例数据集用于测试。这里使用经典的鸢尾花数据集(Iris Dataset)。
from sklearn.datasets import load_iris
import pandas as pd
# 加载鸢尾花数据集
iris = load_iris()
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target
2. 决策树节点类
我们定义一个决策树节点类,用于存储节点信息和实现节点分裂逻辑。
import numpy as np
class DecisionTreeNode:
def __init__(self, gini=None, num_samples=None, num_samples_per_class=None, predicted_class=None):
self.gini = gini
self.num_samples = num_samples
self.num_samples_per_class = num_samples_per_class
self.predicted_class = predicted_class
self.feature_index = 0
self.threshold = 0
self.left = None
self.right = None
def __str__(self):
return f"DecisionTreeNode(gini={self.gini}, num_samples={self.num_samples}, num_samples_per_class={self.num_samples_per_class}, predicted_class={self.predicted_class})"
3. 决策树类
接下来,我们定义一个决策树类,包含构建树的逻辑和节点分裂标准的实现。
class DecisionTreeClassifier:
def __init__(self, max_depth=None):
self.max_depth = max_depth
self.tree = None
def fit(self, X, y):
self.n_classes_ = len(set(y))
self.n_features_ = X.shape[1]
self.tree = self._grow_tree(X, y)
def predict(self, X):
return [self._predict(inputs) for inputs in X]
def _gini(self, y):
m = len(y)
return 1.0 - sum((np.sum(y == c) / m) ** 2 for c in np.unique(y))
def _grow_tree(self, X, y, depth=0):
num_samples_per_class = [np.sum(y == i) for i in range(self.n_classes_)]
predicted_class = np.argmax(num_samples_per_class)
node = DecisionTreeNode(
gini=self._gini(y),
num_samples=len(y),
num_samples_per_class=num_samples_per_class,
predicted_class=predicted_class,
)
if depth < self.max_depth:
idx, thr = self._best_split(X, y)
if idx is not None:
indices_left = X[:, idx] < thr
X_left, y_left = X[indices_left], y[indices_left]
X_right, y_right = X[~indices_left], y[~indices_left]
node.feature_index = idx
node.threshold = thr
node.left = self._grow_tree(X_left, y_left, depth + 1)
node.right = self._grow_tree(X_right, y_right, depth + 1)
return node
def _best_split(self, X, y):
m, n = X.shape
if m <= 1:
return None, None
num_parent = [np.sum(y == c) for c in range(self.n_classes_)]
best_gini = 1.0 - sum((num / m) ** 2 for num in num_parent)
best_idx, best_thr = None, None
for idx in range(n):
thresholds, classes = zip(*sorted(zip(X[:, idx], y)))
num_left = [0] * self.n_classes_
num_right = num_parent.copy()
for i in range(1, m):
c = classes[i - 1]
num_left[c] += 1
num_right[c] -= 1
gini_left = 1.0 - sum((num_left[x] / i) ** 2 for x in range(self.n_classes_))
gini_right = 1.0 - sum((num_right[x] / (m - i)) ** 2 for x in range(self.n_classes_))
gini = (i * gini_left + (m - i) * gini_right) / m
if thresholds[i] == thresholds[i - 1]:
continue
if gini < best_gini:
best_gini = gini
best_idx = idx
best_thr = (thresholds[i] + thresholds[i - 1]) / 2
return best_idx, best_thr
def _predict(self, inputs):
node = self.tree
while node.left:
if inputs[node.feature_index] < node.threshold:
node = node.left
else:
node = node.right
return node.predicted_class
4
. 测试决策树
我们使用鸢尾花数据集来测试我们实现的决策树。
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 划分训练集和测试集
X = df.iloc[:, :-1].values
y = df.iloc[:, -1].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练决策树
tree = DecisionTreeClassifier(max_depth=3)
tree.fit(X_train, y_train)
# 预测并评估
y_pred = tree.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy * 100:.2f}%")
5. 可视化决策树
为了更直观地展示决策树的结构,我们可以使用图形化工具来可视化决策树。这里使用 graphviz 库。
import graphviz
def export_graphviz(tree, feature_names):
dot_data = []
def recurse(node, depth):
indent = " " * depth
if node.left:
dot_data.append(f"{indent}{feature_names[node.feature_index]} < {node.threshold:.2f}")
recurse(node.left, depth + 1)
dot_data.append(f"{indent}else {feature_names[node.feature_index]} >= {node.threshold:.2f}")
recurse(node.right, depth + 1)
else:
dot_data.append(f"{indent}class = {node.predicted_class}")
recurse(tree.tree, 0)
return "\n".join(dot_data)
dot_data = export_graphviz(tree, iris.feature_names)
print(dot_data)
四、总结
在本文中,我们详细探讨了决策树节点分裂的不同标准与方法,包括信息增益、信息增益比、基尼指数和方差减少,并通过具体的代码示例展示了如何实现和应用这些标准。希望这些内容能帮助您更好地理解和使用决策树算法,为您的数据分析和机器学习任务提供支持。
如果您有任何问题或需要进一步的帮助,请随时与我联系。











![[ARC105E] Keep Graph Disconnected题解](https://i-blog.csdnimg.cn/direct/9cdc3fb031af4399944008bc7435defe.png#pic_center)