文章目录
- 机器环境配置
- 安装 JDK 8
- 安装 zookeeper
- Clickhouse 集群安装
- rpm 包离线安装
- 修改全局配置
- zookeeper配置
- Shard和Replica设置
- image.png添加macros配置
- 启动 clickhouse
- 启动 10.82.46.135 clickhouse server
- 启动 10.82.46.163 clickhouse server
- 启动 10.82.46.218 clickhouse server
- 验证
- 创建集群数据库
- 创建表并写入数据
- 验证集群高可用
机器环境配置
三台 centos 机器, 部署 1分片3副本 clickhouse 集群
10.82.46.135
10.82.46.163
10.82.46.218
每一台都要配置
1. 关闭selinux
sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
setenforce 0
2. 关闭防火墙
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
systemctl mask firewalld
systemctl stop firewalld
yum remove firewalld
3. 配置系统打开文件数限制
vi /etc/security/limits.conf #文件句柄数量的配置
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
vi /etc/security/limits.d/20-nproc.conf
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
安装 JDK 8
每一台都要安装 JDK
yum install java-1.8.0-openjdk.x86_64 java-1.8.0-openjdk-devel.x86_64
vi /etc/profile
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.412.b08-1.el7_9.x86_64
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile
echo $JAVA_HOME
echo $CLASSPATH
echo $PATH
安装 zookeeper
zookeeper默认使用2181端口,集群模式还会用到2888、3888端口,建议zookeeper部署在内网环境中,服务器上关闭防火墙,分别在三台服务器上操作。
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.7.1/apache-zookeeper-3.7.1-bin.tar.gz
tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz -C /usr/local/
cd /usr/local/apache-zookeeper-3.7.1-bin/
cp conf/zoo_sample.cfg conf/zoo.cfg
mkdir -p /data/zookeeper
vim conf/zoo.cfg
# 默认端口 8080 可能被占用
admin.serverPort=8888
# zookeeper 数据存储地址
dataDir=/data/zookeeper
# zookeeper 集群地址
server.1=10.82.46.135:2888:3888
server.2=10.82.46.163:2888:3888
server.3=10.82.46.218:2888:3888
# 三台机 id
touch /data/zookeeper/myid
echo 1 > /data/zookeeper/myid
echo 2 > /data/zookeeper/myid
echo 3 > /data/zookeeper/myid
export ZK_HOME=/usr/local/apache-zookeeper-3.7.1-bin
# 启动
./bin/zkServer.sh start
# 查看日志
tail -f logs/zookeeper-root-server-iov-bigdata-autodrive-prod01.out
# 停止
./bin/zkServer.sh stop
# 查看状态
./bin/zkServer.sh status
Clickhouse 集群安装
rpm 包离线安装
1. 安装依赖包
yum install -y libtool *unixODBC*
2. 分别下载client,static,static-dbg,keeper-dbg和server五个安装包,五个包的版本要一致,这里以23.3.2.37版本为例,把下载的五个包放到/usr/local/src 目录下。
wget https://packages.clickhouse.com/rpm/stable/clickhouse-client-23.3.2.37.x86_64.rpm
wget https://packages.clickhouse.com/rpm/stable/clickhouse-common-static-23.3.2.37.x86_64.rpm
wget https://packages.clickhouse.com/rpm/stable/clickhouse-server-23.3.2.37.x86_64.rpm
3. 执行安装,如果说我们的机器上有旧版本的 clickhouse,
该命令会将旧版本升级为我们当前安装的版本,期间会为我们创建一个 default 用户,我们需要输入default 密码
rpm -Uvh --replacepkgs clickhouse-common-static-23.3.2.37.x86_64.rpm clickhouse-client-23.3.2.37.x86_64.rpm clickhouse-server-23.3.2.37.x86_64.rpm
目录说明
/etc/clickhouse-server:服务端的配置文件目录,包括全局配置config.xml和用户配置users.xml等/etc/clickhouse-client:客户端配置,包括conf.d文件夹和config.xml文件/var/lib/clickhouse:默认的数据存储目录,建议修改路径到大容量磁盘/var/log/clickhouse-server:默认保存日志的目录,建议修改路径到大容量磁盘
新建存储目录
mkdir -p /data/clickhouse #数据存储目录
mkdir -p /data/clickhouse/log #日志存放目录
修改目录权限:
chown clickhouse:clickhouse /data/clickhouse -R
chown clickhouse:clickhouse /data/clickhouse/log -R
chmod 755 /data/clickhouse -R
chmod 755 /data/clickhouse/log -R
设置数据库密码,默认用户名是:default
cp /etc/clickhouse-server/users.xml /etc/clickhouse-server/users.xml.bak
vi /etc/clickhouse-server/users.xml
<password>123456</password>
:wq! #保存退出
修改全局配置
修改3台服务器ClickHouse配置文件 /etc/clickhouse-server/config.xml
cp /etc/clickhouse-server/config.xml /etc/clickhouse-server/config.xml.bak #备份
修改全局配置信息vi /etc/clickhouse-server/config.xml
<timezone>Asia/Shanghai</timezone> <!-- #修改时区 -->
<listen_host>::</listen_host> <!-- #开启外部访问 -->
<path>/data/clickhouse/</path> <!-- #修改数据存放路径,默认是<path>/var/lib/clickhouse</path> -->
<level>information</level> <!-- # 默认 trace -->
<log>/data/clickhouse/log/clickhouse-server.log</log>
<errorlog>/data/clickhouse/log/clickhouse-server.err.log</errorlog>
<size>1000M</size>
<count>10</count>
<!-- <max_open_files>1048576</max_open_files> #文件句柄数量的配置 -->
<http_port>8123</http_port> <!-- #http默认端口 -->
<tcp_port>9000</tcp_port> <!-- #tcp默认端口 -->
<max_concurrent_queries>4096</max_concurrent_queries> <!-- #限制的是活跃查询的数量,是对正在执行或排队等待执行的查询进行限制 -->
<max_connections>4096</max_connections> <!-- #限制的是客户端连接的数量,是对同时与 ClickHouse 建立的连接进行限制 -->
:wq! #保存退出
zookeeper配置
zookeeper 不一定要和ck的节点安装在同一台机器上,只要ck的节点能够访问zk即可。
<zookeeper>
<node>
<host>10.82.46.135</host>
<port>2181</port>
</node>
<node>
<host>10.82.46.163</host>
<port>2181</port>
</node>
<node>
<host>10.82.46.218</host>
<port>2181</port>
</node>
</zookeeper>
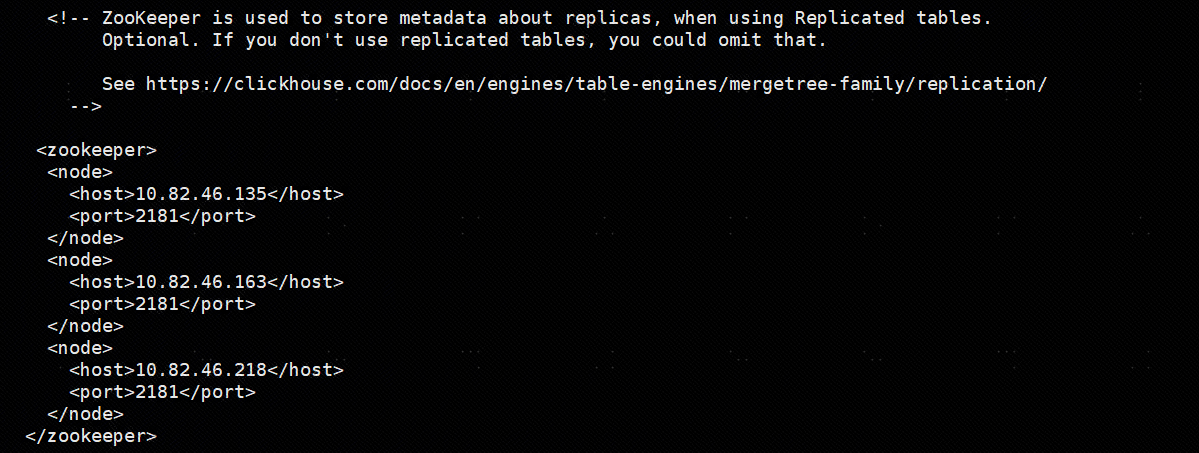
Shard和Replica设置
这里使用 1分片3副本演示
<perftest_1shards_3replicas> <!-- #分片名称,自定义 -->
<shard>
<internal_replication>true</internal_replication> <!--#只写一个副本,其他副本通过zookeeper进行同步,保证数据一致性 -->
<replica>
<host>10.82.46.135</host>
<port>9000</port>
</replica>
<replica>
<host>10.82.46.163</host>
<port>9000</port>
</replica>
<replica>
<host>10.82.46.218</host>
<port>9000</port>
</replica>
</shard>
</perftest_1shards_3replicas>
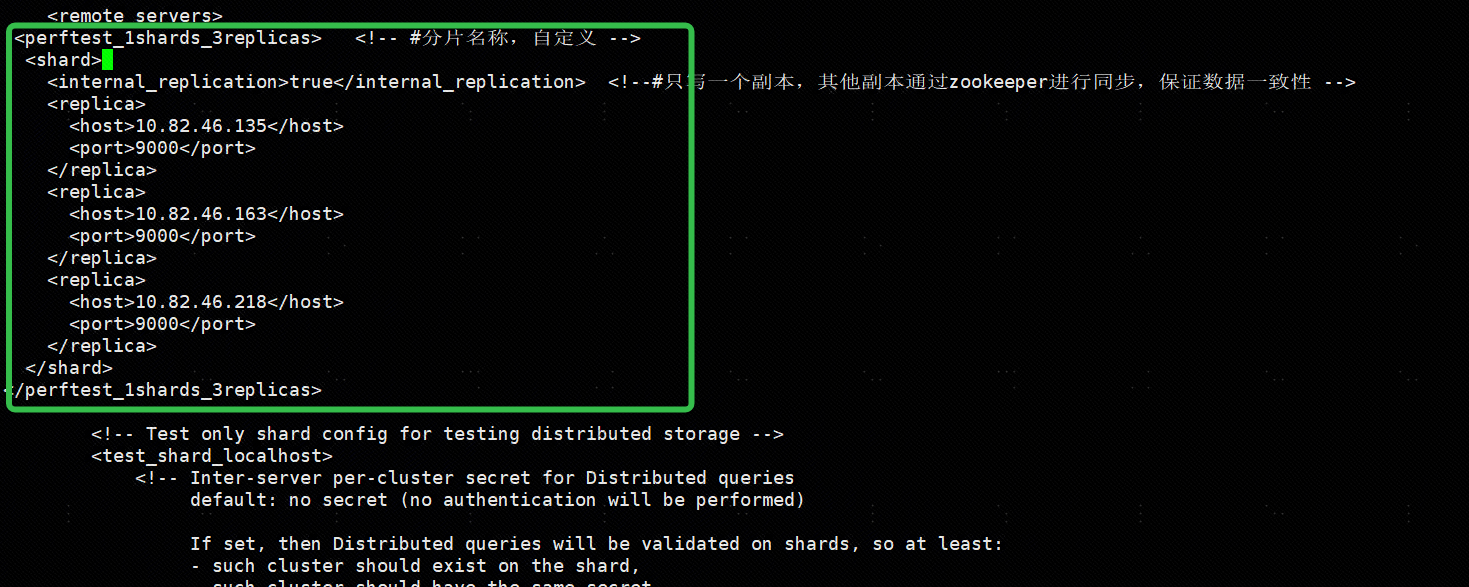 添加macros配置
添加macros配置
<macros>
<!-- #分片号3个节点都一样 -->
<shard>01</shard>
<!-- #副本名称,3个节点不能相同,填写各自的ip地址 -->
<replica>10.82.46.135</replica>
<!-- <replica>10.82.46.163</replica> -->
<!-- <replica>10.82.46.218</replica> -->
</macros>
启动 clickhouse
启动命令
systemctl start clickhouse-server
systemctl status clickhouse-server
systemctl stop clickhouse-server
systemctl restart clickhouse-server
systemctl enable clickhouse-server
启动 10.82.46.135 clickhouse server
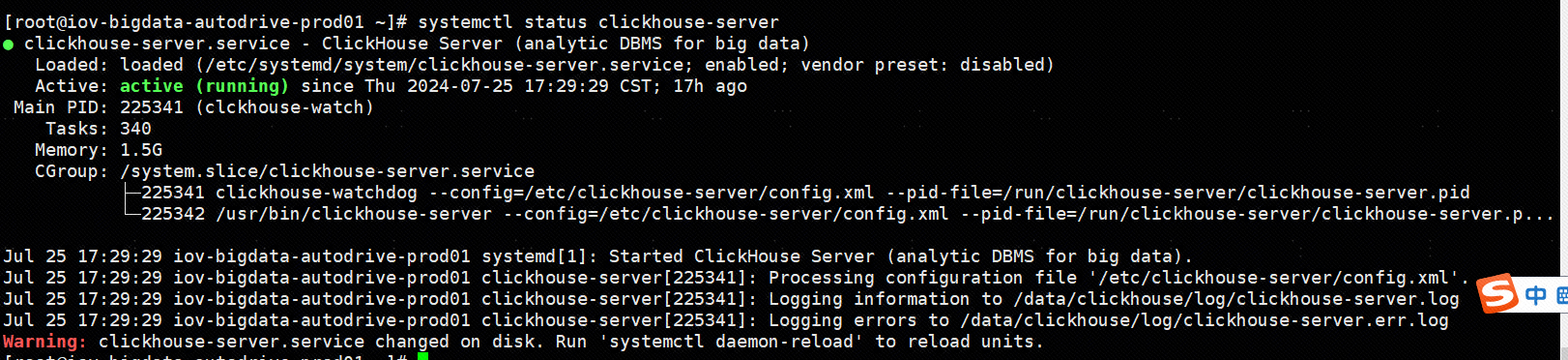
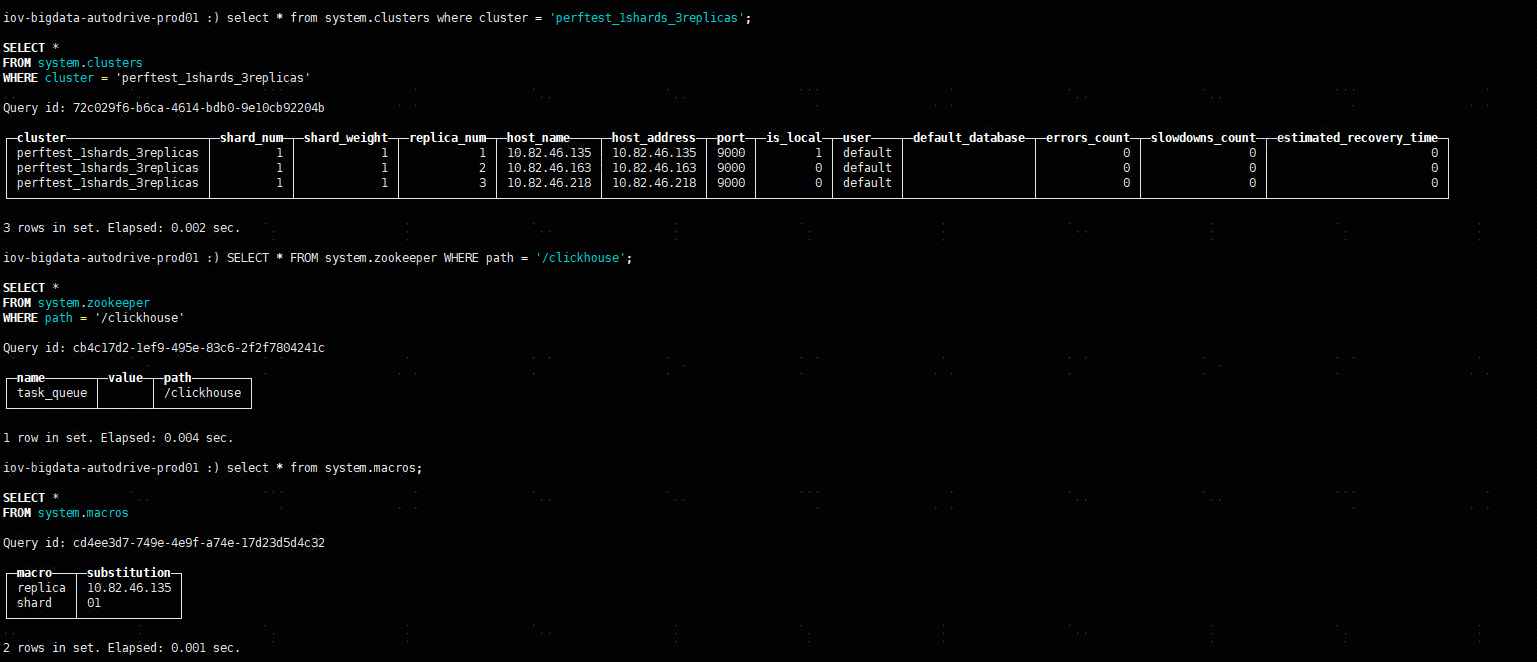
进入 local 数据库控制台,查看集群(perftest_1shards_3replicas)信息,密码就是 rpm 安装的时候输入的密码:
clickhouse-client --host 10.82.46.135 --port=9000
select * from system.clusters where cluster = 'perftest_1shards_3replicas';
SELECT * FROM system.zookeeper WHERE path = '/clickhouse';
select * from system.macros;
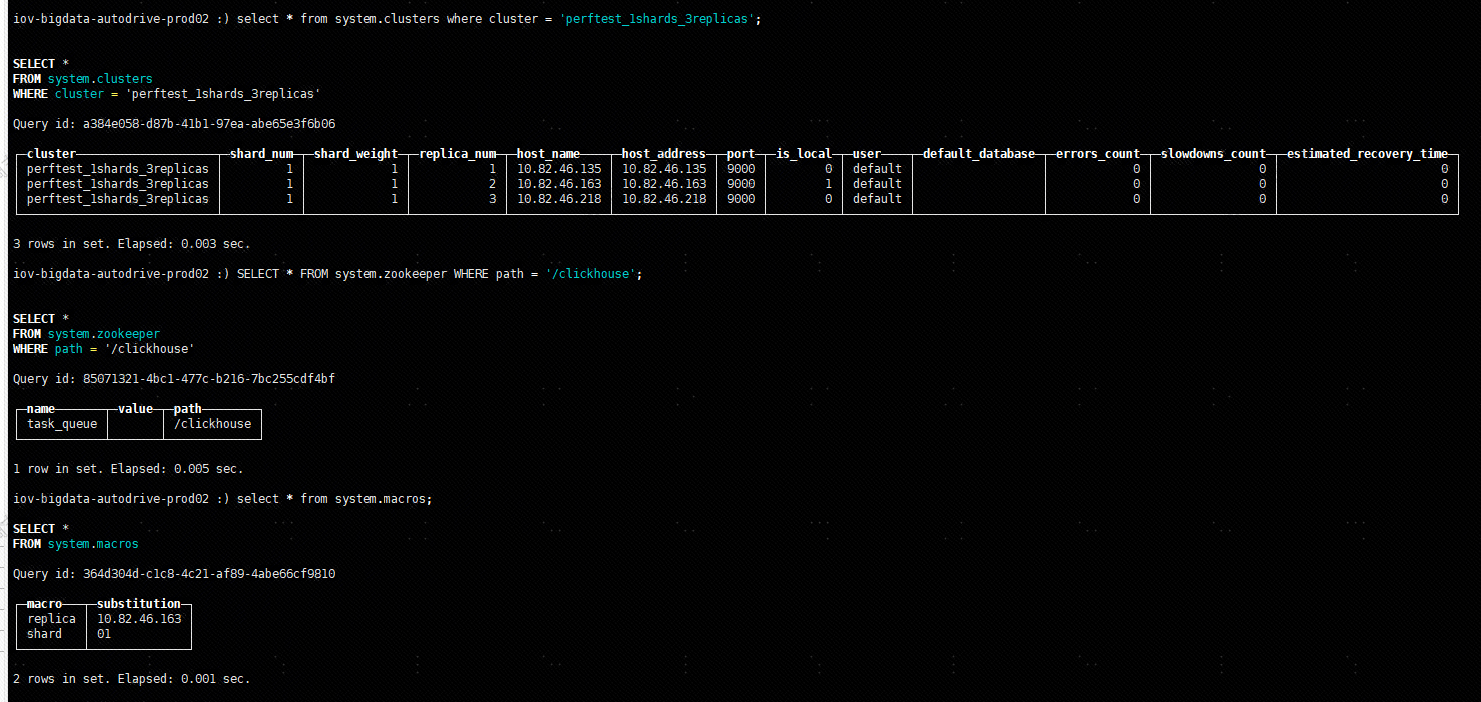
启动 10.82.46.163 clickhouse server
进入 local 数据库控制台,查看集群(perftest_1shards_3replicas)信息,密码就是 rpm 安装的时候输入的密码:
clickhouse-client --host 10.82.46.163 --port=9000
select * from system.clusters where cluster = 'perftest_1shards_3replicas';
SELECT * FROM system.zookeeper WHERE path = '/clickhouse';
select * from system.macros;
启动 10.82.46.218 clickhouse server
进入 local 数据库控制台,查看集群(perftest_1shards_3replicas)信息,密码就是 rpm 安装的时候输入的密码:
clickhouse-client --host 10.82.46.218 --port=9000
select * from system.clusters where cluster = 'perftest_1shards_3replicas';
SELECT * FROM system.zookeeper WHERE path = '/clickhouse';
select * from system.macros;
验证
创建集群数据库
在一台机器上执行创建命令:
CREATE DATABASE db_test_01 ON CLUSTER perftest_1shards_3replicas;
集群安装正常的话,在其他两台机器上 show databases;应该也可以看到这个数据库: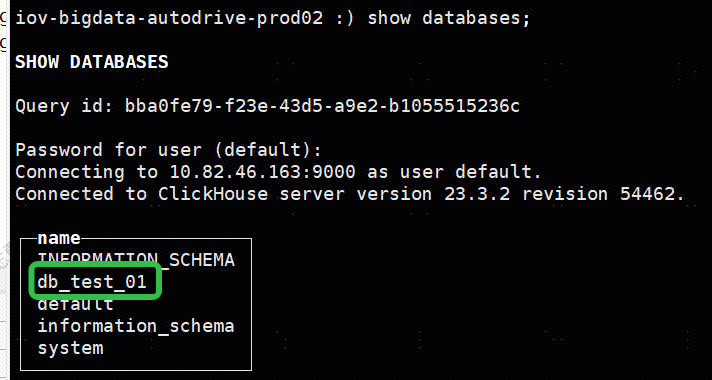
创建表并写入数据
在其中一台机器上执行:
# 创建集群表
CREATE TABLE db_test_01.tb_test_01 ON CLUSTER 'perftest_1shards_3replicas'
(
`id` Int64,
`p` Int16
)
ENGINE = ReplicatedMergeTree( '/clickhouse/tables/{shard}/tb_test_01', '{replica}')
PARTITION BY p
ORDER BY id;
# 写入数据
INSERT INTO db_test_01.tb_test_01 VALUES(111,111);
INSERT INTO db_test_01.tb_test_01 VALUES(222,222);
INSERT INTO db_test_01.tb_test_01 VALUES(333,333);
INSERT INTO db_test_01.tb_test_01 VALUES(444,444);
在其他节点上查看数据:
select * from db_test_01.tb_test_01;
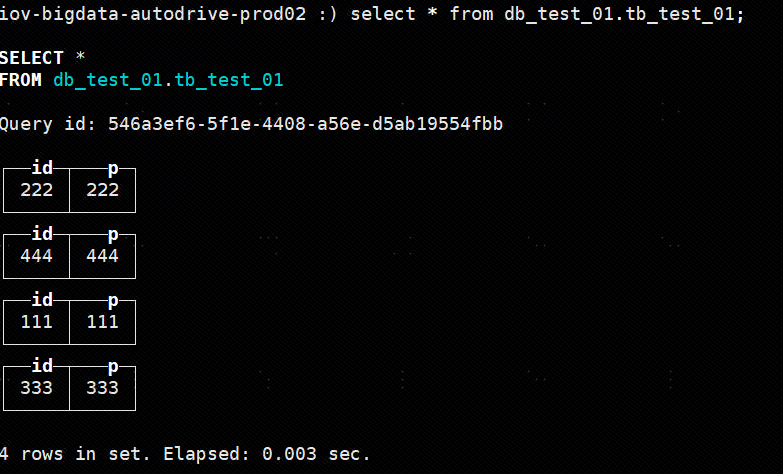
验证集群高可用
关闭其中一个节点(10.82.46.135),模拟节点宕机,在另外的节点上写入数据:systemctl stop clickhouse-server
在另外的节点上写入数据:
INSERT INTO db_test_01.tb_test_01 VALUES(555,555);
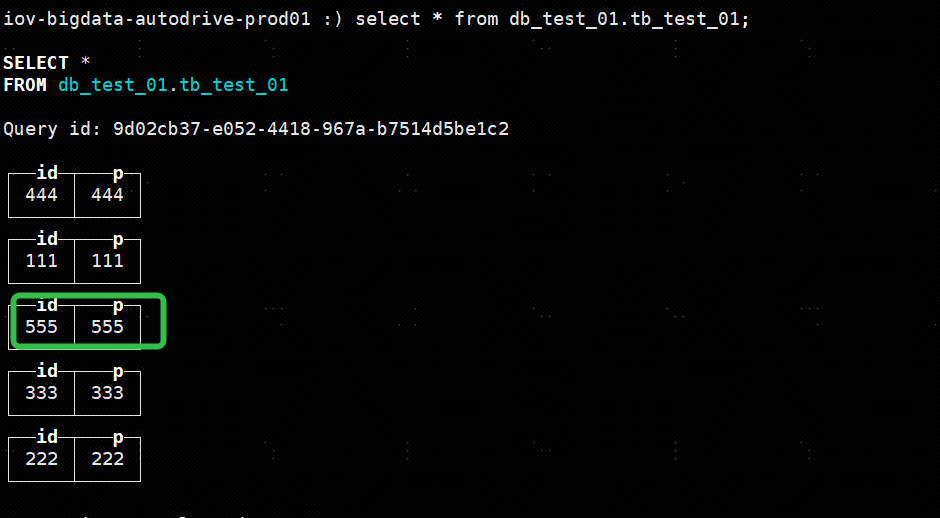
重新启动节点(10.82.46.135),查看数据表,发现数据已经同步过来,验证成功:
systemctl start clickhouse-server
clickhouse-client --host 10.82.46.135 --port=9000
select * from db_test_01.tb_test_01;
删库跑路
drop database db_test_01 on cluster perftest_1shards_3replicas;