第七章 回溯算法 part04
491.递增子序列
本题和大家刚做过的 90.子集II 非常像,但又很不一样,很容易掉坑里。
https://programmercarl.com/0491.%E9%80%92%E5%A2%9E%E5%AD%90%E5%BA%8F%E5%88%97.html
视频讲解:https://www.bilibili.com/video/BV1EG4y1h78v
46.全排列
本题重点感受一下,排列问题 与 组合问题,组合总和,子集问题的区别。 为什么排列问题不用 startIndex
https://programmercarl.com/0046.%E5%85%A8%E6%8E%92%E5%88%97.html
视频讲解:https://www.bilibili.com/video/BV19v4y1S79W
47.全排列 II
本题 就是我们讲过的 40.组合总和II 去重逻辑 和 46.全排列 的结合,可以先自己做一下,然后重点看一下 文章中 我讲的拓展内容: used[i - 1] == true 也行,used[i - 1] == false 也行
https://programmercarl.com/0047.%E5%85%A8%E6%8E%92%E5%88%97II.html
视频讲解:https://www.bilibili.com/video/BV1R84y1i7Tm
**下面这三道题都非常难,建议大家一刷的时候 可以适当选择跳过。 **
因为 一刷 也不求大家能把这么难的问题解决,大家目前能了解一下题目的要求,了解一下解题思路,不求能直接写出代码,先大概熟悉一下这些题,二刷的时候,随着对回溯算法的深入理解,再去解决如下三题。
332. 重新安排行程(可跳过)
本题很难,一刷的录友刷起来 比较费力,可以留给二刷的时候再去解决。
本题没有录制视频,当初录视频是按照 《代码随想录》出版的目录来的,当时没有这道题所以就没有录制。
https://programmercarl.com/0332.%E9%87%8D%E6%96%B0%E5%AE%89%E6%8E%92%E8%A1%8C%E7%A8%8B.html
51. N皇后(适当跳过)
N皇后这道题目还是很经典的,一刷的录友们建议看看视频了解了解大体思路 就可以 (如果没时间本次就直接跳过) ,先有个印象,二刷的时候重点解决。
https://programmercarl.com/0051.N%E7%9A%87%E5%90%8E.html
视频讲解:https://www.bilibili.com/video/BV1Rd4y1c7Bq
37. 解数独(适当跳过)
同样,一刷的录友们建议看看视频了解了解大体思路(如果没时间本次就直接跳过),先有个印象,二刷的时候重点解决。
。
https://programmercarl.com/0037.%E8%A7%A3%E6%95%B0%E7%8B%AC.html
视频讲解:https://www.bilibili.com/video/BV1TW4y1471V
**总结 **
刷了这么多回溯算法的题目,可以做一做总结了!
https://programmercarl.com/%E5%9B%9E%E6%BA%AF%E6%80%BB%E7%BB%93.html
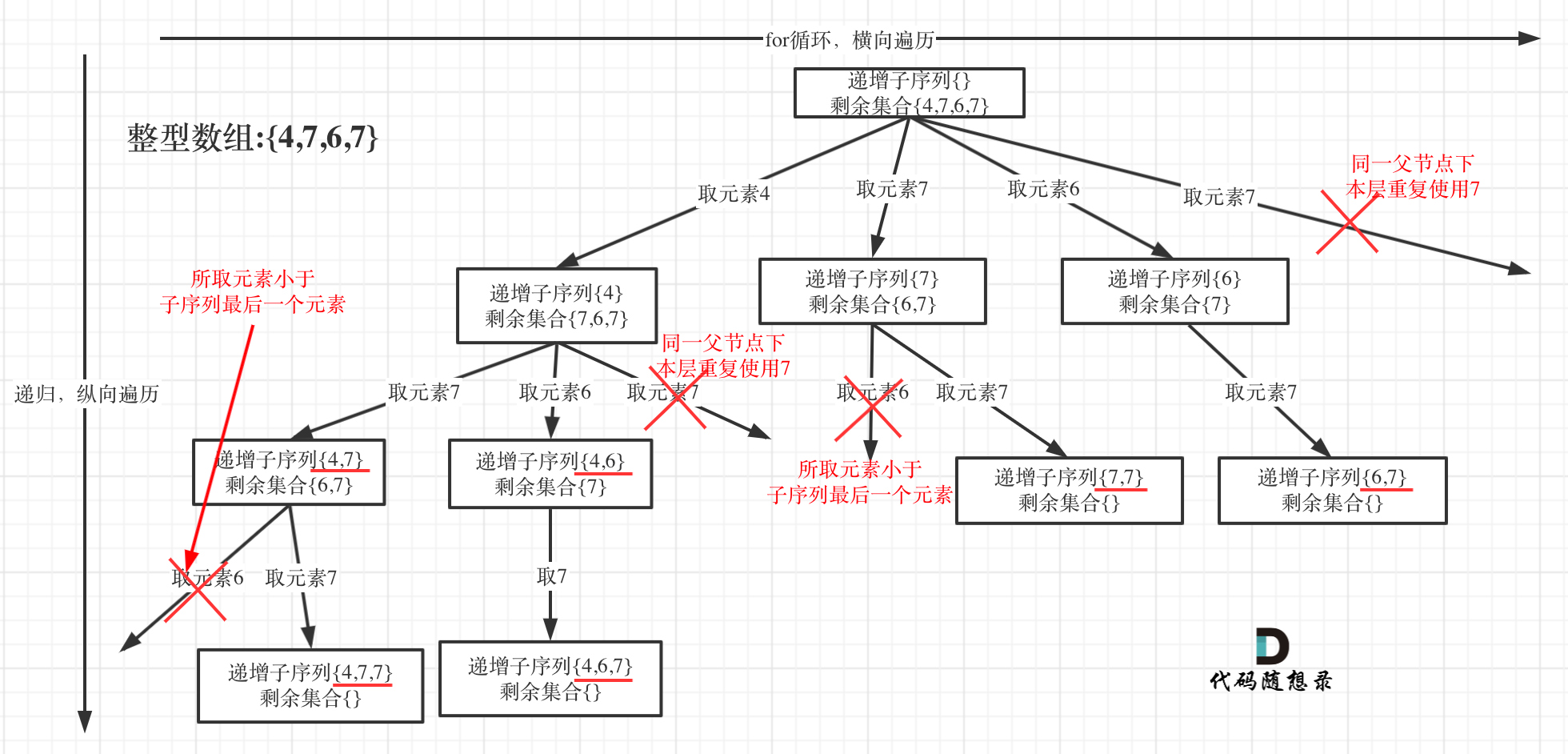
491. 非递减子序列
题目链接
https://leetcode.cn/problems/non-decreasing-subsequences/description/
解题思路
注意点 1.集合至少是2个元素,并要求集合是非递减(递增或者元素都一样) 2.返回所有该数组中不同的递增子序列 2.1 首先要startIndex = i+1 **保证相同元素不能重复选取** 2.2 由于数组中有重复元素,**记录本层元素是否重复使用** 之前是排序 和 使用 nums[i]==nums[i-1] 跳过重复元素 本题不能排序,就要使用 哈希数组 或 HashSet集合,保证使用过的元素不再用。 用数组来做hash效率比较高
code
class Solution {
List<List<Integer>> res =new ArrayList<>();
List<Integer> path=new ArrayList<>();
public List<List<Integer>> findSubsequences(int[] nums) {
backtracking(nums,0);
return res;
}
//注意点
//1.集合至少是2个元素,并要求集合是非递减(递增或者元素都一样)
//2.返回所有该数组中不同的递增子序列
//2.1 首先要startIndex = i+1 保证相同元素不能重复选取
//2.2 由于数组中有重复元素,之前是排序 和 使用 nums[i]==nums[i-1] 跳过重复元素
//本题不能排序,就要使用 哈希数组 或 HashSet集合,保证使用过的元素不再用。
public void backtracking(int[] nums,int startIndex){
if(path.size()>1){
res.add(new ArrayList<>(path));
}
//HashSet<Integer> hash=new HashSet<>(); //1.使用hashset
int[] used=new int[201];//2.使用数组来进行去重操作,题目说数值范围[-100, 100]
for(int i=startIndex;i<nums.length;i++){
if(path.size()>0 && nums[i]<path.get(path.size()-1)){
continue;
}
//1.hashset方式
// if(hash.contains(nums[i])){
// continue;
// }
// hash.add(nums[i]);
//2.hash数组方式
if(used[nums[i]+100]==1){
continue;
}
used[nums[i]+100]=1;
path.add(nums[i]);
backtracking(nums,i+1);
path.remove(path.size()-1);
}
}
}
在图中可以看出,同一父节点下的同层上使用过的元素就不能再使用了
46.全排列
题目链接
https://leetcode.cn/problems/permutations/description/
解题思路
和组合问题 切割问题 子集问题 最大的不同就是for循环里不用startIndex了。
因为排列问题,每次都要从头开始搜索,例如元素1在[1,2]中已经使用过了,但是在[2,1]中还要再使用一次1。
排列问题关键在于used数组
used数组,其实就是记录此时path里都有哪些元素使用了,一个排列里一个元素只能使用一次。
code
class Solution {
private List<List<Integer>> res=new ArrayList<>();
private List<Integer> path=new ArrayList<>();
private boolean[] used;
public List<List<Integer>> permute(int[] nums) {
used=new boolean[nums.length];
backtracking(nums);
return res;
}
//1.确定回溯函数的参数和返回值
public void backtracking(int[] nums){
//2.数组path的大小达到和nums数组一样大的时候,说明找到了一个全排列,也表示到达了叶子节点。可以看出叶子节点,就是收割结果的地方
if(path.size()==nums.length){
res.add(new ArrayList<>(path));
}
for (int i = 0; i < nums.length; i++) {
if(used[i]){
continue;
}
used[i]=true;
path.add(nums[i]);
backtracking(nums);
used[i]=false;
path.remove(path.size()-1);
}
}
}
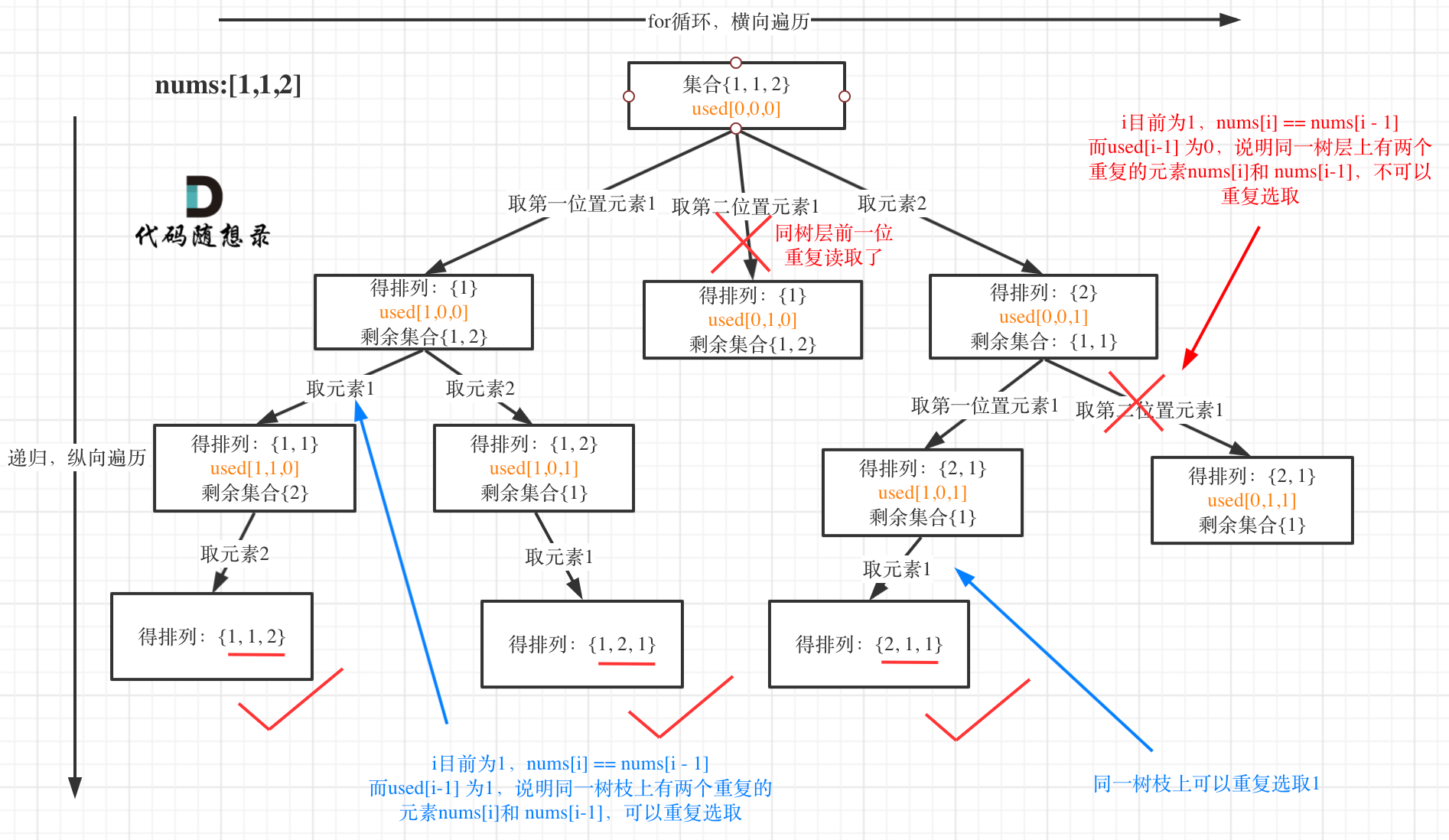
47.全排列 II
题目链接
https://leetcode.cn/problems/permutations-ii/description/
解题思路
1.used 数组 避免树枝上取过的元素位置重复使用,不同位置的相同元素可取
2.数层上重复取过的元素不可取再取
2.1 使用set树层去重
2.2 排序后相邻元素去重 nums[i]==nums[i-1] 且 used[i-1] ==false 这样才是代表树层重复
used[i-1] ==false (同层一定会回溯 used[i-1] 前一个一定是false used[i] 即将变为true 这才是同层)不加这个条件 会导致树枝上不同位置的相邻元素取不到 例如used[i] 是true 递归下一层 used[i]==used[i-1] 但是这是不同位置的相邻元素是可以取的,导致解题出错。
code
class Solution {
private List<List<Integer>> res=new ArrayList<>();
private List<Integer> path=new ArrayList<>();
public List<List<Integer>> permuteUnique(int[] nums) {
Arrays.sort(nums);
backtracking(nums,new boolean[nums.length]);
return res;
}
//1.确定回溯函数的参数和返回值
public void backtracking(int[] nums,boolean[] used){
//2.数组path的大小达到和nums数组一样大的时候,说明找到了一个全排列,也表示到达了叶子节点。可以看出叶子节点,就是收割结果的地方
if(path.size()==nums.length){
res.add(new ArrayList<>(path));
}
for (int i = 0; i < nums.length; i++) {
if(i>0&&used[i-1]==false&&nums[i]==nums[i-1]){
continue;
}
if(used[i]){
continue;
}
used[i]=true;
path.add(nums[i]);
backtracking(nums,used);
used[i]=false;
path.remove(path.size()-1);
}
}
}
class Solution {
private List<List<Integer>> res=new ArrayList<>();
private List<Integer> path=new ArrayList<>();
private boolean[] used;
public List<List<Integer>> permuteUnique(int[] nums) {
used=new boolean[nums.length];
backtracking(nums,0);
return res;
}
//1.确定回溯函数的参数和返回值
public void backtracking(int[] nums,int count){
//2.数组path的大小达到和nums数组一样大的时候,说明找到了一个全排列,也表示到达了叶子节点。可以看出叶子节点,就是收割结果的地方
if(path.size()==nums.length){
res.add(new ArrayList<>(path));
return;
}
Set<Integer> set=new HashSet<>();//set去重
for (int i = 0; i < nums.length; i++) {
if(set.contains(nums[i])){
continue;
}
if(used[i]){
continue;
}
used[i]=true;
//这里一定要if(used[i])判断完之后在放进set集合,避免used[i] 位置是跳过的位置,而你放进去,导致取不到不同位置但值相同的元素
set.add(nums[i]);
path.add(nums[i]);
backtracking(nums,i+1);
used[i]=false;
path.remove(path.size()-1);
}
}
}